

Nos dous primeiros artigos plantexen a cuestión da automatización e esbocei o seu marco, no segundo fixen un retroceso na virtualización da rede, como primeiro enfoque para automatizar a configuración dos servizos.
Agora toca debuxar un diagrama da rede física.
Se non estás familiarizado coa configuración de redes de centros de datos, recoméndoche encarecidamente comezar por .
Todos os problemas:
As prácticas descritas nesta serie deberían ser aplicables a calquera tipo de rede, calquera tamaño, con calquera variedade de provedores (non). Non obstante, é imposible describir un exemplo universal da aplicación destes enfoques. Polo tanto, centrareime na arquitectura moderna da rede DC: .
Faremos DCI en MPLS L3VPN.
Unha rede de superposición execútase encima da rede física desde o host (pode ser VXLAN ou Tungsten Fabric de OpenStack ou calquera outra cousa que requira só conectividade IP básica da rede).
Neste caso, obtemos un escenario relativamente sinxelo para a automatización, porque temos moitos equipos que se configuran do mesmo xeito.
Escolleremos un DC esférico no baleiro:
- Unha versión de deseño en todas partes.
- Dous vendedores formando dous planos de rede.
- Un DC é como outro como dous chícharos nunha vaina.
Contido
- Topoloxía física
- Enrutamento
- Plan IP
- Laba
- Conclusión
- Ligazóns útiles
Permite que o noso provedor de servizos LAN_DC, por exemplo, aloxe vídeos de formación sobre sobrevivir en ascensores atascados.
Nas megacidades isto é moi popular, polo que necesitas moitas máquinas físicas.
En primeiro lugar, describirei a rede aproximadamente como me gustaría que fose. E entón simplificareino para o laboratorio.
Topoloxía física
Localizacións
LAN_DC terá 6 DC:
- Rusia (RU):
- Moscova (msk)
- Kazán (kzn)
- España (SP):
- Barcelona (BCN)
- Málaga (mlg)
- China (CN):
- Shanghai (sha)
- Xi'an (tanto)

Dentro de DC (Intra-DC)
Todos os DC teñen redes de conectividade interna idénticas baseadas na topoloxía Clos.
Que tipo de redes Clos son e por que están separadas .
Cada DC ten 10 racks con máquinas, numeraranse como A, B, C E así por diante.
Cada rack ten 30 máquinas. Non nos van interesar.
Ademais, en cada rack hai un interruptor ao que están conectadas todas as máquinas, isto é Interruptor superior do bastidor - ToR ou se non, no que se refire á fábrica de Clos, chamarémoslle Folla.

Esquema xeral da fábrica.
Chamámolos XXX- follaYonde XXX - abreviatura de tres letras DC, e Y - número de serie. Por exemplo, kzn-folla 11.
Nos meus artigos permitireime usar os termos Leaf e ToR de forma bastante frívola como sinónimos. Non obstante, debemos lembrar que non é así.
ToR é un interruptor instalado nun rack ao que están conectadas as máquinas.
Leaf é o papel dun dispositivo nunha rede física ou un interruptor de primeiro nivel en termos de topoloxía Cloes.
É dicir, Folla != ToR.
Así, Leaf pode ser un interruptor EndofRaw, por exemplo.
Non obstante, no marco deste artigo aínda os trataremos como sinónimos.
Cada interruptor ToR está conectado á súa vez a catro interruptores de agregación de nivel superior: Columna. Un rack no DC está asignado para Spines. Nomearémolo do mesmo xeito: XXX- columna vertebralY.
O mesmo rack conterá equipos de rede para a conectividade entre os enrutadores DC - 2 con MPLS a bordo. Pero en xeral, estes son os mesmos TdR. É dicir, desde o punto de vista dos interruptores Spine, o ToR habitual con máquinas conectadas ou un enrutador para DCI non importa en absoluto, só o reenvío.
Estes TdR especiais chámanse Borde-folla. Chamámolos XXX-bordoY.
Será así.
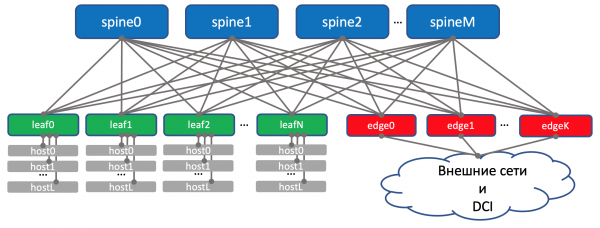
No diagrama anterior, realmente coloquei borde e folla no mesmo nivel. Ensináronnos a considerar os enlaces ascendentes (de aí o termo) como enlaces ascendentes. E aquí resulta que o "enlace ascendente" DCI volve a baixar, o que para algúns rompe lixeiramente a lóxica habitual. No caso das redes grandes, cando os centros de datos se dividen en unidades aínda máis pequenas - POD's (Punto de entrega), destacar individual Edge-POD's para DCI e acceso a redes externas.
Para facilitar a percepción no futuro, seguirei debuxando Edge sobre Spine, aínda que teremos en conta que non hai intelixencia en Spine e non hai diferenzas cando se traballa con Leaf e Edge-leaf regulares (aínda que aquí pode haber matices). , pero en xeral Isto é certo).
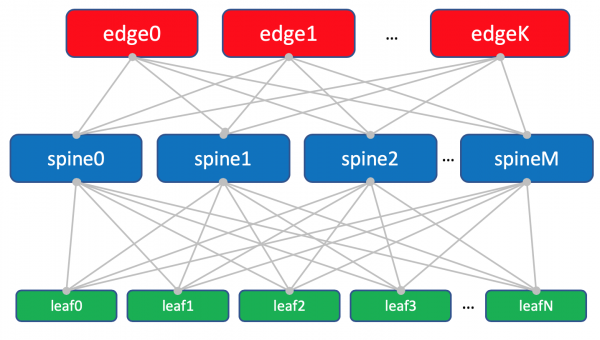
Esquema dunha fábrica con Edge-leafs.
A trinidade de Leaf, Spine e Edge forman unha rede ou fábrica de Underlay.
A tarefa dunha fábrica de rede (léase Underlay), como xa definimos en , moi, moi sinxelo: proporcionar conectividade IP entre máquinas tanto dentro do mesmo DC como entre elas.
É por iso que a rede chámase fábrica, do mesmo xeito que, por exemplo, unha fábrica de conmutación dentro de caixas de rede modulares, sobre as que podes ler máis en .
En xeral, tal topoloxía chámase fábrica, porque tecido en tradución significa tecido. E é difícil estar en desacordo:
A fábrica é completamente L3. Sen VLAN, sen Broadcast: temos programadores tan marabillosos en LAN_DC, saben como escribir aplicacións que viven no paradigma L3 e as máquinas virtuais non requiren Migración en directo con preservación do enderezo IP.
E unha vez máis: a resposta á pregunta por que a fábrica e por que L3 está separada .
DCI - Interconexión de centro de datos (Inter-DC)
O DCI organizarase mediante Edge-Leaf, é dicir, son o noso punto de saída á estrada.
Para simplificar, asumimos que os DC están conectados entre si por enlaces directos.
Imos excluír a conectividade externa da consideración.
Son consciente de que cada vez que quito un compoñente, simplifico significativamente a rede. E cando automaticemos a nosa rede abstracta, todo estará ben, pero na real haberá muletas.
É verdade. Aínda así, o obxectivo desta serie é pensar e traballar enfoques, non resolver heroicamente problemas imaxinarios.
En Edge-Leafs, a capa inferior colócase na VPN e transmítese a través da columna vertebral MPLS (a mesma ligazón directa).
Este é o diagrama de nivel superior que obtemos.

Enrutamento
Para o enrutamento dentro do DC usaremos BGP.
No tronco MPLS OSPF+LDP.
Para DCI, é dicir, organizar a conectividade no subsolo: BGP L3VPN sobre MPLS.
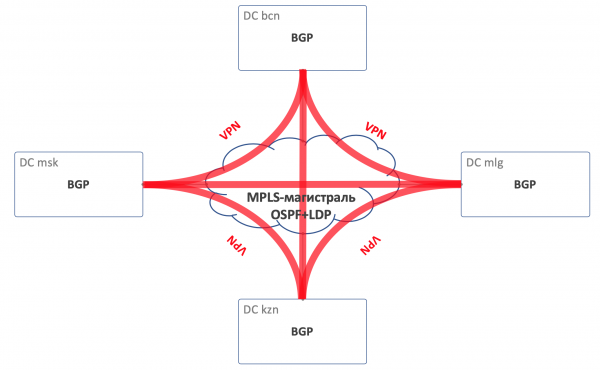
Esquema xeral de rutas
Non hai OSPF nin ISIS (protocolo de enrutamento prohibido na Federación Rusa) na fábrica.
Isto significa que non haberá detección automática nin cálculo dos camiños máis curtos; só se configura o protocolo, a veciñanza e as políticas de xeito manual (en realidade, automático, aquí estamos a falar de automatización).
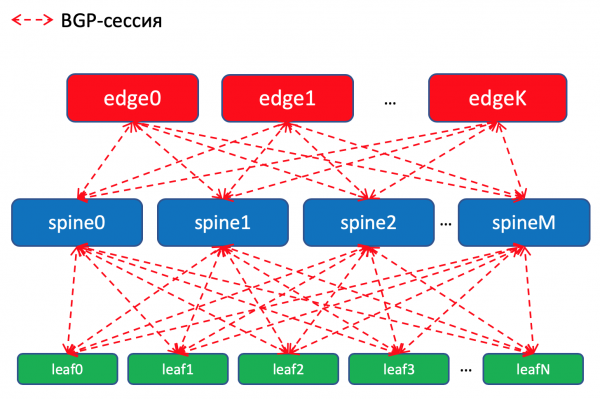
Esquema de enrutamento BGP dentro do DC
Por que BGP?
Sobre este tema hai o nome de Facebook e Arista, que conta como construír moi grande redes de centros de datos utilizando BGP. Lee case como ficción, recoméndoo encarecidamente para unha noite lánguida.
E tamén hai unha sección enteira no meu artigo dedicada a isto. Onde te levo e .
Pero aínda así, en resumo, ningún IGP é axeitado para redes de grandes centros de datos, onde o número de dispositivos de rede ascende a miles.
Ademais, usar BGP en todas partes permitirá non perder o tempo en soportar varios protocolos diferentes e sincronizar entre eles.
Co corazón, na nosa fábrica, que cun alto grao de probabilidade non crecerá rapidamente, OSPF sería suficiente para os ollos. Estes son en realidade os problemas dos megascalers e os titans das nubes. Pero imaxinemos só para algúns lanzamentos que o necesitamos, e usaremos BGP, como legou Pyotr Lapukhov.
Políticas de enrutamento
Nos interruptores Leaf, importamos prefixos das interfaces de rede Underlay a BGP.
Teremos unha sesión BGP entre cada un un par Leaf-Spine, no que estes prefixos Underlay serán anunciados pola rede aquí e alí.
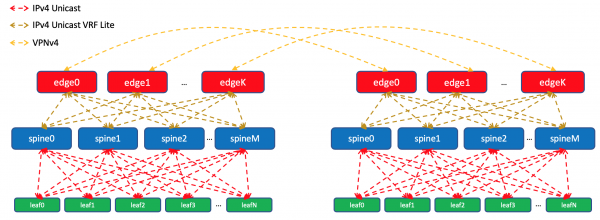
Dentro dun centro de datos, distribuiremos as especificacións que importamos a ToRe. En Edge-Leafs agregarémolos e anunciarémolos a DC remotos e enviarémolos a TOR. É dicir, cada ToR saberá exactamente como chegar a outro ToR no mesmo DC e onde é o punto de entrada para chegar ao ToR noutro DC.
En DCI, as rutas transmitiranse como VPNv4. Para iso, en Edge-Leaf, a interface cara a fábrica colocarase nun VRF, chamémoslle UNDERLAY, e o barrio con Spine on Edge-Leaf levantarase dentro do VRF, e entre Edge-Leafs na VPNv4- familia.
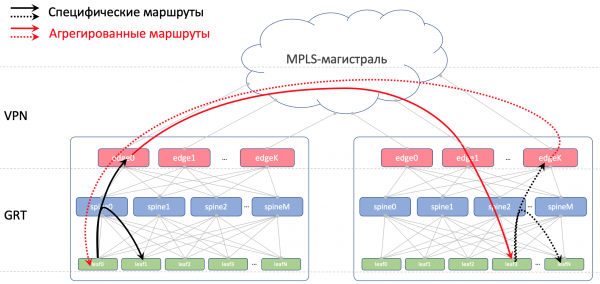
Tamén prohibiremos que se volvan anunciar as rutas recibidas de espiñas de regreso a elas.
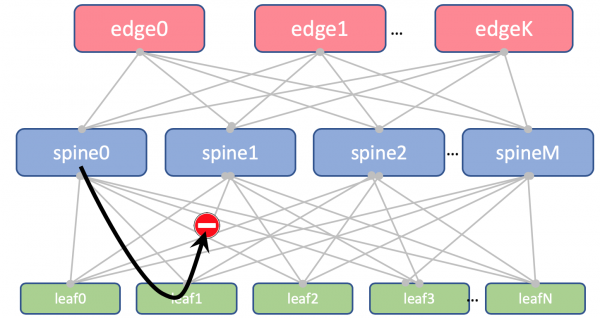
En Leaf e Spine non importaremos Loopbacks. Só os necesitamos para determinar o ID do enrutador.
Pero en Edge-Leafs importámolo a Global BGP. Entre os enderezos de Loopback, Edge-Leafs establecerá unha sesión BGP na familia VPN IPv4 entre si.
Teremos un backbone OSPF+LDP entre os dispositivos EDGE. Todo está nunha zona. Configuración extremadamente sinxela.
Esta é a imaxe coa ruta.
BGP ASN
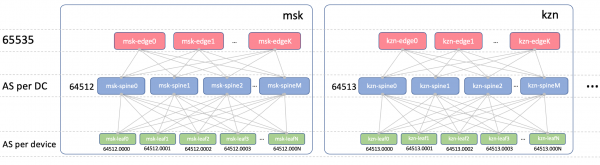
Edge-Folla ASN
En Edge-Leafs haberá un ASN en todos os DC. É importante que haxa iBGP entre Edge-Leafs, e non nos atrapamos nos matices de eBGP. Que sexa 65535. En realidade, este podería ser o número dun AS público.
Columna vertebral ASN
En Spine teremos un ASN por DC. Comecemos aquí co primeiro número da gama de AS privado - 64512, 64513 E así por diante.
Por que ASN en DC?
Imos dividir esta pregunta en dúas:
- Por que os ASN son iguais en todas as columnas dun DC?
- Por que son diferentes en diferentes DC?
Por que hai os mesmos ASN en todas as columnas dun DC?
Así será a ruta AS-Path da Underlay en Edge-Leaf:
[leafX_ASN, spine_ASN, edge_ASN]
Cando intentes anuncialo de novo en Spine, descartarao porque o seu AS (Spine_AS) xa está na lista.
Non obstante, dentro do DC estamos totalmente satisfeitos de que as rutas Underlay que ascenden ao Edge non poidan baixar. Toda comunicación entre os anfitrións dentro do DC debe producirse no nivel da columna vertebral.
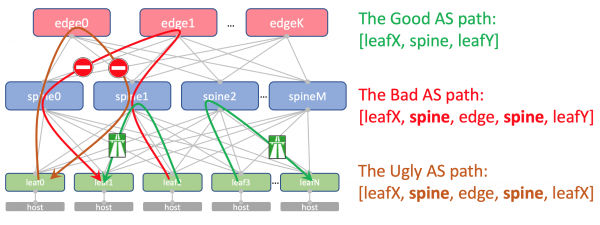
Neste caso, as rutas agregadas doutros DC chegarán en calquera caso facilmente aos ToR -o seu AS-Path só terá ASN 65535 - o número de AS Edge-Leafs, porque é aí onde se crearon.
Por que son diferentes en diferentes DC?
Teoricamente, é posible que necesitemos arrastrar Loopback e algunhas máquinas virtuais de servizo entre DC.
Por exemplo, no host executaremos Route Reflector ou (Virtual Network Gateway), que se bloqueará con TopR a través de BGP e anunciará o seu loopback, que debería ser accesible desde todos os DC.
Entón, este é o aspecto do seu AS-Path:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN]
E non debería haber ASN duplicados en ningún lado.
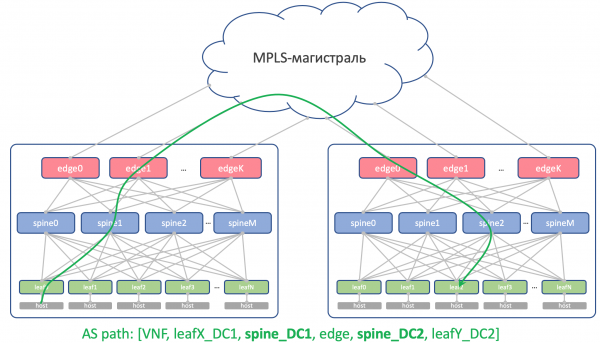
É dicir, Spine_DC1 e Spine_DC2 deben ser diferentes, igual que leafX_DC1 e leafY_DC2, que é exactamente ao que nos estamos achegando.
Como probablemente sabes, hai trucos que che permiten aceptar rutas con ASN duplicados a pesar do mecanismo de prevención de bucles (permitido en Cisco). E mesmo ten usos lexítimos. Pero esta é unha lagoa potencial na estabilidade da rede. E persoalmente caín nel un par de veces.
E se temos a oportunidade de non usar cousas perigosas, aproveitarémola.
Folla ASN
Teremos un ASN individual en cada interruptor Leaf en toda a rede.
Facemos isto polas razóns indicadas anteriormente: AS-Path sen bucles, configuración BGP sen marcadores.
Para que as rutas entre Leafs pasen sen problemas, o AS-Path debería verse así:
[leafX_ASN, spine_ASN, leafY_ASN]
onde leafX_ASN e leafY_ASN estarían ben diferentes.
Isto tamén é necesario para a situación co anuncio dun loopback VNF entre DC:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN]
Usaremos un ASN de 4 bytes e xerarémolo en función do ASN da columna vertebral e do número do interruptor Leaf, é dicir, así: Spine_ASN.0000X.
Esta é a imaxe coa ASN.
Plan IP
Fundamentalmente, necesitamos asignar enderezos para as seguintes conexións:
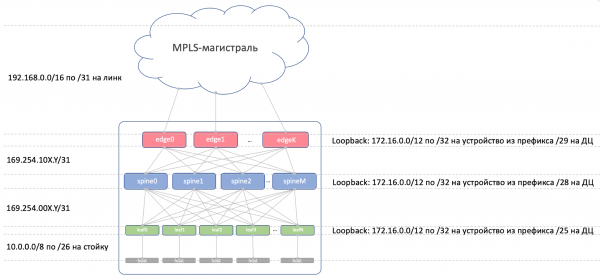
- Subxace os enderezos de rede entre o ToR e a máquina. Deben ser únicos dentro de toda a rede para que calquera máquina poida comunicarse con calquera outra. Gran axuste 10/8. Para cada rack hai /26 cunha reserva. Asignaremos /19 por DC e /17 por rexión.
- Enlazar enderezos entre Leaf/Tor e Spine.
Gustaríame asignalos algorítmicamente, é dicir, calculalos a partir dos nomes dos dispositivos que hai que conectar.
Que sexa... 169.254.0.0/16.
A saber 169.254.00X.Y/31onde X - Número de columna vertebral, Y — Rede P2P /31.
Isto permitirache lanzar ata 128 racks e ata 10 Spines no DC. Os enderezos de ligazón poden (e repetiranse) de DC a DC. - Organizamos a unión Spine-Edge-Leaf en subredes 169.254.10X.Y/31, onde exactamente o mesmo X - Número de columna vertebral, Y — Rede P2P /31.
- Ligazóns de enderezos de Edge-Leaf ao backbone MPLS. Aquí a situación é algo diferente: o lugar onde todas as pezas están conectadas nun pastel, polo que non funcionará reutilizar os mesmos enderezos, cómpre seleccionar a seguinte subrede gratuíta. Polo tanto, tomemos como base 192.168.0.0/16 e sacaremos dela os libres.
- Enderezos de loopback. Daremos toda a gama por eles 172.16.0.0/12.
- Folla - /25 por DC - os mesmos 128 racks. Asignaremos /23 por rexión.
- Spine - /28 por DC - ata 16 Spine. Asignamos /26 por rexión.
- Edge-Leaf - /29 por DC - ata 8 caixas. Asignamos /27 por rexión.
Se non temos suficientes intervalos asignados no DC (e non haberá ningún; afirmamos que somos hiperescaladores), simplemente seleccionamos o seguinte bloque.
Esta é a imaxe co enderezo IP.
Loopbacks:
Prefixo
Papel do dispositivo
Rexión
DC
172.16.0.0/23
bordo
172.16.0.0/27
ru
172.16.0.0/29
msk
172.16.0.8/29
kzn
172.16.0.32/27
sp
172.16.0.32/29
BCN
172.16.0.40/29
mlg
172.16.0.64/27
cn
172.16.0.64/29
sha
172.16.0.72/29
tanto
172.16.2.0/23
columna
172.16.2.0/26
ru
172.16.2.0/28
msk
172.16.2.16/28
kzn
172.16.2.64/26
sp
172.16.2.64/28
BCN
172.16.2.80/28
mlg
172.16.2.128/26
cn
172.16.2.128/28
sha
172.16.2.144/28
tanto
172.16.8.0/21
folla
172.16.8.0/23
ru
172.16.8.0/25
msk
172.16.8.128/25
kzn
172.16.10.0/23
sp
172.16.10.0/25
BCN
172.16.10.128/25
mlg
172.16.12.0/23
cn
172.16.12.0/25
sha
172.16.12.128/25
tanto
capa inferior:
Prefixo
Rexión
DC
10.0.0.0/17
ru
10.0.0.0/19
msk
10.0.32.0/19
kzn
10.0.128.0/17
sp
10.0.128.0/19
BCN
10.0.160.0/19
mlg
10.1.0.0/17
cn
10.1.0.0/19
sha
10.1.32.0/19
tanto
Laba
Dous vendedores. Unha rede. ADSM.
Xenibreiro + Arista. UbuntuA boa e vella Eva.
A cantidade de recursos do noso servidor virtual en Mirana aínda é limitada, polo que para a práctica empregaremos unha rede simplificada ata o límite.
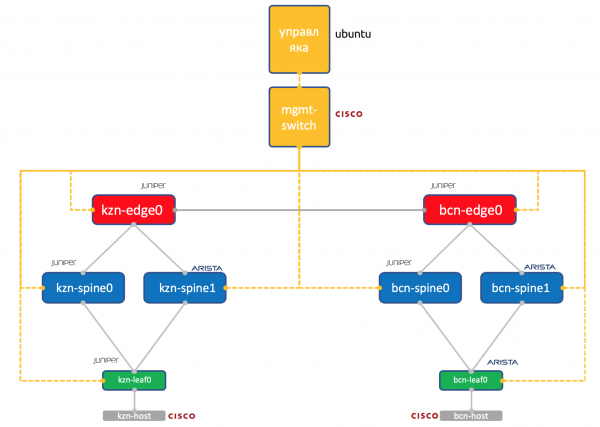
Dous centros de datos: Kazán e Barcelona.
- Dúas espiñas cada unha: Juniper e Arista.
- Un toro (Folla) en cada un: Juniper e Arista, cun host conectado (tomemos unha IOL de Cisco lixeira para iso).
- Un nodo Edge-Leaf cada un (polo momento só Juniper).
- Un interruptor de Cisco para gobernalos a todos.
- Ademais das caixas de rede, iníciase un xestor de máquinas virtuais. Baixo control Ubuntu.
Ten acceso a todos os dispositivos, executará sistemas IPAM/DCIM, un montón de scripts de Python, Ansible e calquera outra cousa que poidamos necesitar.
de todos os dispositivos da rede, que tentaremos reproducir mediante a automatización.
Conclusión
Iso tamén se acepta? Debo escribir unha pequena conclusión baixo cada artigo?
Así que escollemos Rede Clos dentro do DC, xa que esperamos moito tráfico Leste-Oeste e queremos ECMP.
A rede dividíase en física (superposición) e virtual (superposición). Ao mesmo tempo, a superposición comeza desde o host, simplificando así os requisitos para a capa inferior.
Escollemos BGP como protocolo de enrutamento para redes de rede pola súa escalabilidade e flexibilidade de políticas.
Teremos nodos separados para organizar DCI - Edge-leaf.
A columna vertebral terá OSPF+LDP.
DCI implementarase baseándose en MPLS L3VPN.
Para as ligazóns P2P, calcularemos os enderezos IP de forma algorítmica en función dos nomes dos dispositivos.
Asignaremos loopbacks segundo o papel dos dispositivos e a súa localización secuencialmente.
Prefixos subxacentes: só nos interruptores de follas secuencialmente en función da súa localización.
Supoñamos que agora mesmo aínda non temos o equipo instalado.
Polo tanto, os nosos seguintes pasos serán engadilos aos sistemas (IPAM, inventario), organizar o acceso, xerar unha configuración e implantala.
No seguinte artigo trataremos Netbox, un sistema de inventario e xestión de espazo IP nun DC.
Grazas
- Andrey Glazkov, alias @glazgoo por correccións e correccións
- Alexander Klimenko tamén coñecido como @v00lk por corrección e edicións
- Artyom Chernobay para KDPV
Fonte: www.habr.com
