

Isto nin sequera é unha broma, parece que esta imaxe en particular reflicte con máis precisión a esencia destas bases de datos e, ao final, quedará claro por que:

Segundo o DB-Engines Ranking, as dúas bases de datos columnares NoSQL máis populares son Cassandra (en diante CS) e HBase (HB).
Por vontade do destino, o noso equipo de xestión de carga de datos en Sberbank xa o fixo e traballa en estreita colaboración con HB. Durante este tempo, estudamos bastante ben os seus puntos fortes e débiles e aprendemos a cociñalo. Porén, a presenza dunha alternativa en forma de CS sempre nos obrigou a atormentarnos un pouco con dúbidas: fixemos a elección correcta? Ademais, os resultados , realizado por DataStax, dixeron que CS vence facilmente a HB con case unha puntuación aplastante. Por outra banda, DataStax é unha parte interesada, e non debes crer na súa palabra. Tamén nos confundiu a cantidade bastante pequena de información sobre as condicións das probas, polo que decidimos descubrir por nós mesmos quen é o rei de BigData NoSql, e os resultados obtidos resultaron moi interesantes.
Non obstante, antes de pasar aos resultados das probas realizadas, é necesario describir os aspectos significativos das configuracións do contorno. O feito é que CS pódese usar nun modo que permite a perda de datos. Eses. é cando só un servidor (nodo) é responsable dos datos dunha determinada chave, e se por algún motivo falla, perderase o valor desta chave. Para moitas tarefas isto non é crítico, pero para o sector bancario esta é a excepción máis que a regra. No noso caso, é importante ter varias copias de datos para un almacenamento fiable.
Polo tanto, só se considerou o modo operativo CS en modo de triple replicación, é dicir. A creación do espazo de casos realizouse cos seguintes parámetros:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}; A continuación, hai dúas formas de garantir o nivel de coherencia necesario. Norma xeral:
NO + NR > RF
O que significa que o número de confirmacións dos nodos ao escribir (NW) máis o número de confirmacións dos nodos ao ler (NR) debe ser maior que o factor de replicación. No noso caso, RF = 3, o que significa que as seguintes opcións son adecuadas:
2 + 2 > 3
3 + 1 > 3
Dado que é fundamental para nós almacenar os datos da forma máis fiable posible, escolleuse o esquema 3+1. Ademais, HB traballa nun principio similar, é dicir. tal comparación será máis xusta.
Nótese que DataStax fixo o contrario no seu estudo, estableceron RF = 1 tanto para CS como para HB (para este último cambiando a configuración de HDFS). Este é un aspecto moi importante porque o impacto no rendemento de CS neste caso é enorme. Por exemplo, a seguinte imaxe mostra o aumento do tempo necesario para cargar datos en CS:
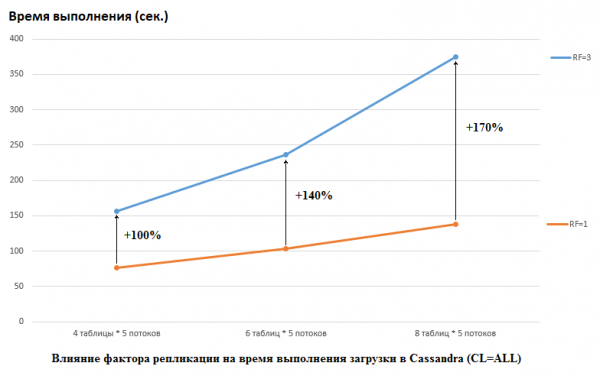
Aquí vemos o seguinte: cantos máis fíos competidores escriban datos, máis tempo leva. Isto é natural, pero é importante que a degradación do rendemento para RF=3 sexa significativamente maior. Noutras palabras, se escribimos 4 fíos en 5 táboas cada unha (20 en total), entón RF=3 perde unhas 2 veces (150 segundos para RF=3 fronte a 75 para RF=1). Pero se aumentamos a carga cargando datos en 8 táboas con 5 fíos cada unha (40 en total), entón a perda de RF=3 xa é de 2,7 veces (375 segundos fronte a 138).
Quizais este sexa en parte o segredo da proba de carga exitosa realizada por DataStax para CS, porque para HB no noso stand cambiar o factor de replicación de 2 a 3 non tivo ningún efecto. Eses. os discos non son o pescozo de botella de HB para a nosa configuración. Non obstante, hai moitas outras trampas aquí, porque hai que ter en conta que a nosa versión de HB foi lixeiramente modificada e modificada, os ambientes son completamente diferentes, etc. Tamén vale a pena sinalar que quizais non sei como preparar CS correctamente e hai algunhas formas máis eficaces de traballar con el, e espero que o descubramos nos comentarios. Pero primeiro o primeiro.
Todas as probas realizáronse nun clúster de hardware composto por 4 servidores, cada un coa seguinte configuración:
CPU: Xeon E5-2680 v4 @ 2.40GHz 64 subprocesos.
Discos: 12 unidades SATA HDD
Versión de java: 1.8.0_111
Versión CS: 3.11.5
parámetros cassandra.ymlNúmero de fichas: 256
hinted_handoff_enabled: verdadeiro
hinted_handoff_throttle_in_kb: 1024
max_hints_delivery_threads: 2
directorio_suxestións: /data10/cassandra/hints
hints_flush_period_in_ms: 10000
max_hints_file_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
autenticador: AllowAllAuthenticator
autorizador: AllowAllAuthorizer
role_manager: CassandraRoleManager
validez_de_funcións_en_ms: 2000
validez_de_permisos_en_ms: 2000
credentials_validity_in_ms: 2000
particionador: org.apache.cassandra.dht.Murmur3Partitioner
directorios_arquivos_datos:
- /data1/cassandra/data # cada directorio dataN é un disco separado
- /data2/cassandra/data
- /data3/cassandra/data
- /data4/cassandra/data
- /data5/cassandra/data
- /data6/cassandra/data
- /data7/cassandra/data
- /data8/cassandra/data
directorio_commitlog: /data9/cassandra/commitlog
cdc_enabled: false
disk_failure_policy: parar
commit_failure_policy: parar
prepared_statements_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
key_cache_save_period: 14400
row_cache_size_in_mb: 0
row_cache_save_period: 0
counter_cache_size_in_mb:
counter_cache_save_period: 7200
directorio_saved_caches: /data10/cassandra/saved_caches
commitlog_sync: periódico
commitlog_sync_period_in_ms: 10000
Commitlog_segment_size_in_mb: 32
provedor_semente:
- nome_clase: org.apache.cassandra.locator.SimpleSeedProvider
parámetros:
- sementes: "*,*"
concurrent_reads: 256 # intentou 64 - non se notou ningunha diferenza
concurrent_writes: 256 # intentou 64 - non se notou ningunha diferenza
concurrent_counter_writes: 256 # intentou 64 - non se notou ningunha diferenza
Escrituras_vistas_materializadas_concurrentes: 32
memtable_heap_space_in_mb: 2048 # intentou 16 GB - foi máis lento
memtable_allocation_type: heap_buffers
index_summary_capacity_in_mb:
index_summary_resize_interval_in_minutes: 60
trickle_fsync: falso
trickle_fsync_interval_in_kb: 10240
porto_almacenamento: 7000
ssl_storage_port: 7001
enderezo_escoita: *
enderezo_difusión: *
listen_on_broadcast_address: verdadeiro
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: verdadeiro
porto_de_transporte_nativo: 9042
start_rpc: verdadeiro
enderezo_rpc: *
porto_rpc: 9160
rpc_keepalive: verdadeiro
rpc_server_type: sincronización
thrift_framed_transport_size_in_mb: 15
incremental_backups: falso
snapshot_before_compaction: falso
auto_snapshot: verdadeiro
tamaño_índice_columna_en_kb: 64
column_index_cache_size_in_kb: 2
compactadores_concurrentes: 4
Rendimiento_de_compactación_mb_por_s: 1600
sstable_preemptive_open_interval_in_mb: 50
read_request_timeout_in_ms: 100000
range_request_timeout_in_ms: 200000
write_request_timeout_in_ms: 40000
counter_write_request_timeout_in_ms: 100000
cas_contention_timeout_in_ms: 20000
truncate_request_timeout_in_ms: 60000
request_timeout_in_ms: 200000
slow_query_log_timeout_in_ms: 500
cross_node_timeout: falso
endpoint_snitch: GossipingPropertyFileSnitch
dynamic_snitch_update_interval_in_ms: 100
dynamic_snitch_reset_interval_in_ms: 600000
dynamic_snitch_badness_threshold: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
server_encryption_options:
cifrado_internodo: ningún
client_encryption_options:
activado: falso
compresión_entrenudo: dc
inter_dc_tcp_nodelay: falso
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: false
enable_scripted_user_defined_functions: false
windows_timer_interval: 1
opcións_de_cifrado_de_datos_transparentes:
activado: falso
tombstone_warn_threshold: 1000
tombstone_failure_threshold: 100000
batch_size_warn_threshold_in_kb: 200
Umbral_de_tamaño_de_lote_en_kb: 250
unlogged_batch_across_partitions_warn_threshold: 10
compactation_large_partition_warning_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
back_pressure_enabled: falso
enable_materialized_views: verdadeiro
enable_sasi_indexes: verdadeiro
Configuración do GC:
### Configuración do CMS-XX:+UsarParNewGC
-XX:+UsarConcMarkSweepGC
-XX:+CMSParallelRemarkActivado
-XX:SurvivorRatio=8
-XX:MaxTenuriingThreshold=1
-XX:CMSInitiatingOccupancyFraction=75
-XX:+Use CMSInitiatingOccupancyOnly
-XX:CMSWaitDuration=10000
-XX:+CMSParallelInitialMarkActivado
-XX:+CMSEdenChunksRecordAlways
-XX:+CMSClassUnloadingEnabled
A memoria jvm.options asignáronlle 16 Gb (tamén probamos 32 Gb, non se notou ningunha diferenza).
As táboas creáronse co comando:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};Versión HB: 1.2.0-cdh5.14.2 (na clase org.apache.hadoop.hbase.regionserver.HRegion excluímos MetricsRegion o que levou a GC cando o número de rexións era superior a 1000 en RegionServer)
Parámetros de HBase non predeterminadoszookeeper.session.timeout: 120000
hbase.rpc.timeout: 2 minuto(s)
hbase.client.scanner.timeout.period: 2 minuto(s)
hbase.master.handler.count: 10
hbase.regionserver.lease.period, hbase.client.scanner.timeout.period: 2 minuto(s)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.period: 4 hora(s)
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 GiB
hbase.hregion.memstore.block.multiplicador: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompaction: 1 día(s)
Fragmento de configuración avanzada do servizo HBase (válvula de seguridade) para hbase-site.xml:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compacción.grande12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Opcións de configuración de Java para HBase RegionServer:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:ReservedCodeCacheSize=256m
hbase.snapshot.master.timeoutMillis: 2 minuto(s)
hbase.snapshot.region.timeout: 2 minuto(s)
hbase.snapshot.master.timeout.millis: 2 minuto(s)
Tamaño máximo de rexistro do servidor REST HBase: 100 MiB
Copia de seguranza máxima de ficheiros de rexistro do servidor REST de HBase: 5
Tamaño máximo de rexistro do servidor HBase Thrift: 100 MiB
Copia de seguranza máxima dos ficheiros de rexistro do servidor HBase Thrift: 5
Tamaño máximo do rexistro mestre: 100 MiB
Copia de seguranza máxima de ficheiros de rexistro mestres: 5
Tamaño máximo de rexistro de RegionServer: 100 MiB
Copia de seguranza máxima de ficheiros de rexistro de RegionServer: 5
Ventá de detección principal activa de HBase: 4 minuto(s)
dfs.client.hedged.read.threadpool.tamaño: 40
dfs.client.hedged.read.threshold.millis: 10 milisegundos
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Descritores de ficheiros de proceso máximos: 180000
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.tamaño: 20
Fíos de movemento de rexións: 6
Tamaño do montón Java do cliente en bytes: 1 GiB
Grupo predeterminado do servidor REST HBase: 3 GiB
Grupo predeterminado do servidor HBase Thrift: 3 GiB
Tamaño do montón de Java do mestre HBase en bytes: 16 GiB
Tamaño do montón de Java do servidor de rexións HBase en bytes: 32 GiB
+ ZooKeeper
maxClientCnxns: 601
maxSessionTimeout: 120000
Creación de táboas:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
alterar 'ns:t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}
Hai un punto importante aquí: a descrición de DataStax non di cantas rexións se usaron para crear as táboas HB, aínda que isto é fundamental para grandes volumes. Polo tanto, para as probas escolleuse cantidade = 64, que permite almacenar ata 640 GB, é dicir. mesa de tamaño medio.
No momento da proba, HBase tiña 22 mil táboas e 67 mil rexións (isto sería letal para a versión 1.2.0 se non fose polo parche mencionado anteriormente).
Agora para o código. Dado que non estaba claro cales eran as configuracións máis vantaxosas para unha determinada base de datos, realizáronse probas en varias combinacións. Eses. nalgunhas probas, cargáronse simultáneamente 4 táboas (usáronse os 4 nodos para a conexión). Noutras probas traballamos con 8 táboas diferentes. Nalgúns casos, o tamaño do lote era 100, noutros 200 (parámetro do lote - consulte o código a continuación). O tamaño dos datos para o valor é de 10 bytes ou 100 bytes (dataSize). En total, 5 millóns de rexistros foron escritos e lidos en cada táboa cada vez. Ao mesmo tempo, escribíronse/leron 5 fíos en cada táboa (número de fíos - thNum), cada un dos cales utilizou o seu propio rango de claves (conto = 1 millón):
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("BEGIN BATCH ");
for (int i = 0; i < batch; i++) {
String value = RandomStringUtils.random(dataSize, true, true);
sb.append("INSERT INTO ")
.append(tableName)
.append("(id, title) ")
.append("VALUES (")
.append(key)
.append(", '")
.append(value)
.append("');");
key++;
}
sb.append("APPLY BATCH;");
final String query = sb.toString();
session.execute(query);
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN (");
for (int i = 0; i < batch; i++) {
sb = sb.append(key);
if (i+1 < batch)
sb.append(",");
key++;
}
sb = sb.append(");");
final String query = sb.toString();
ResultSet rs = session.execute(query);
}
}
En consecuencia, proporcionouse unha funcionalidade similar para HB:
Configuration conf = getConf();
HTable table = new HTable(conf, keyspace + ":" + tableName);
table.setAutoFlush(false, false);
List<Get> lGet = new ArrayList<>();
List<Put> lPut = new ArrayList<>();
byte[] cf = Bytes.toBytes("cf");
byte[] qf = Bytes.toBytes("value");
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lPut.clear();
for (int i = 0; i < batch; i++) {
Put p = new Put(makeHbaseRowKey(key));
String value = RandomStringUtils.random(dataSize, true, true);
p.addColumn(cf, qf, value.getBytes());
lPut.add(p);
key++;
}
table.put(lPut);
table.flushCommits();
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lGet.clear();
for (int i = 0; i < batch; i++) {
Get g = new Get(makeHbaseRowKey(key));
lGet.add(g);
key++;
}
Result[] rs = table.get(lGet);
}
}
Dado que en HB o cliente debe encargarse da distribución uniforme dos datos, a función de salgado clave era o seguinte:
public static byte[] makeHbaseRowKey(long key) {
byte[] nonSaltedRowKey = Bytes.toBytes(key);
CRC32 crc32 = new CRC32();
crc32.update(nonSaltedRowKey);
long crc32Value = crc32.getValue();
byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7);
return ArrayUtils.addAll(salt, nonSaltedRowKey);
}
Agora a parte máis interesante - os resultados:
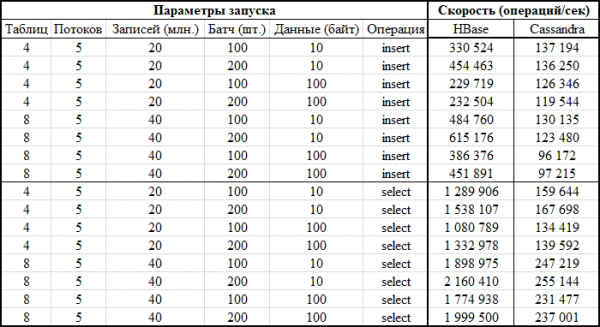
O mesmo en forma gráfica:
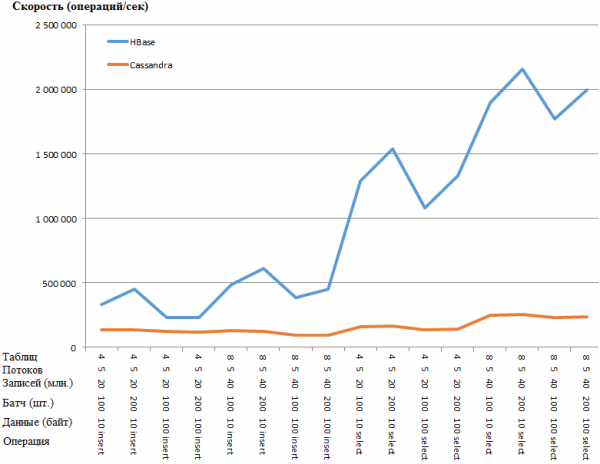
A vantaxe de HB é tan sorprendente que existe a sospeita de que hai algún tipo de pescozo de botella na configuración de CS. Non obstante, buscar en Google e buscar os parámetros máis obvios (como concurrent_writes ou memtable_heap_space_in_mb) non acelerou as cousas. Ao mesmo tempo, os rexistros están limpos e non xuran nada.
Os datos distribuíronse uniformemente entre os nodos, as estatísticas de todos os nodos eran aproximadamente as mesmas.
Así se ven as estatísticas da táboa dun dos nodosEspazo de teclas: ks
Número de lecturas: 9383707
Latencia de lectura: 0.04287025042448576 ms
Número de escrituras: 15462012
Latencia de escritura: 0.1350068438699957 ms
Fluxes pendentes: 0
Táboa: t1
Número de táboas SST: 16
Espazo utilizado (en directo): 148.59 MiB
Espazo utilizado (total): 148.59 MiB
Espazo utilizado polas instantáneas (total): 0 bytes
Usada memoria fóra do montón (total): 5.17 MiB
Relación de compresión SSTable: 0.5720989576459437
Número de particións (estimación): 3970323
Recuento de células memorables: 0
Tamaño de datos memorables: 0 bytes
Utilización de memoria memorable fóra do montón: 0 bytes
Número de interruptores memorables: 5
Número de lecturas locais: 2346045
Latencia de lectura local: NaN ms
Número de escritura local: 3865503
Latencia de escritura local: NaN ms
Fluxos pendentes: 0
Porcentaxe reparada: 0.0
Filtro de floración falsos positivos: 25
Relación de falso filtro de floración: 0.00000
Espazo de filtro Bloom utilizado: 4.57 MiB
Filtro Bloom fóra da memoria heap utilizada: 4.57 MiB
Resumo do índice fóra da memoria heap utilizada: 590.02 KiB
Metadatos de compresión fóra da memoria heap utilizada: 19.45 KiB
Bytes mínimos de partición compactada: 36
Bytes máximos de partición compactada: 42
Bytes medios de partición compactada: 42
Media de células vivas por porción (últimos cinco minutos): NaN
Máximo de células vivas por porción (últimos cinco minutos): 0
Media de lápidas por corte (últimos cinco minutos): NaN
Máximo de lápidas por corte (últimos cinco minutos): 0
Mutacións eliminadas: 0 bytes
Un intento de reducir o tamaño do lote (mesmo envialo individualmente) non tivo efecto, só empeorou. É posible que de feito este sexa realmente o máximo rendemento para CS, xa que os resultados obtidos para CS son similares aos obtidos para DataStax: uns centos de miles de operacións por segundo. Ademais, se observamos a utilización dos recursos, veremos que CS usa moito máis CPU e discos:
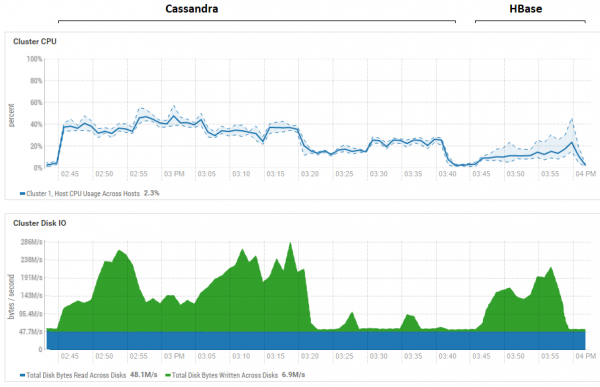
A figura mostra a utilización durante a execución de todas as probas seguidas para ambas as bases de datos.
Respecto da poderosa vantaxe lectora de HB. Aquí podes ver que para ambas as bases de datos, a utilización do disco durante a lectura é extremadamente baixa (as probas de lectura son a parte final do ciclo de probas para cada base de datos, por exemplo, para CS é de 15:20 a 15:40). No caso de HB, a razón é clara: a maioría dos datos colócanse na memoria, no memstore, e algúns están almacenados na caché na caché de bloques. En canto a CS, non está moi claro como funciona, pero a reciclaxe do disco tampouco é visible, pero por se acaso, intentouse activar a caché row_cache_size_in_mb = 2048 e establecer a caché = {'keys': 'ALL', 'rows_per_partition': '2000000'}, pero iso empeorou aínda un pouco.
Tamén cabe mencionar unha vez máis un punto importante sobre o número de rexións en HB. No noso caso, o valor especificouse como 64. Se o reduces e fai que sexa igual, por exemplo, a 4, entón ao ler, a velocidade cae 2 veces. O motivo é que o memstore encherase máis rápido e os ficheiros lavaranse con máis frecuencia e, ao ler, haberá que procesar máis ficheiros, o que é unha operación bastante complicada para HB. En condicións reais, isto pódese tratar pensando nunha estratexia de separación previa e compactación; en particular, usamos unha utilidade autoescrita que recolle o lixo e comprime os ficheiros HF constantemente en segundo plano. É moi posible que para as probas de DataStax asignasen só 1 rexión por táboa (o que non é correcto) e isto aclararía un pouco por que HB era tan inferior nas súas probas de lectura.
Diso extráense as seguintes conclusións preliminares. Asumindo que non se cometeron grandes erros durante as probas, Cassandra parece un coloso con pés de barro. Máis precisamente, mentres se balancea nunha soa perna, como na imaxe do comezo do artigo, mostra relativamente bos resultados, pero nunha loita nas mesmas condicións perde por completo. Ao mesmo tempo, tendo en conta a baixa utilización da CPU no noso hardware, aprendemos a plantar dous RegionServer HB por host e, así, duplicamos o rendemento. Eses. Tendo en conta a utilización dos recursos, a situación de CS é aínda máis deplorable.
Por suposto, estas probas son bastante sintéticas e a cantidade de datos que se utilizou aquí é relativamente modesta. É posible que se cambiamos a terabytes, a situación sería diferente, pero mentres que para HB podemos cargar terabytes, para CS isto resultou ser problemático. Moitas veces lanzou unha OperationTimedOutException mesmo con estes volumes, aínda que os parámetros para esperar unha resposta xa se incrementaron varias veces en comparación cos predeterminados.
Espero que mediante esforzos conxuntos atopemos os pescozos de botella de CS e, se podemos aceleralo, ao final da publicación definitivamente engadirei información sobre os resultados finais.
UPD: Grazas aos consellos dos compañeiros conseguín acelerar a lectura. Foi:
159 operacións (644 táboas, 4 emisións, lote 5).
Engadido:
.withLoadBalancingPolicy(nova política TokenAware(DCAwareRoundRobinPolicy.builder().build()))
E xoguei coa cantidade de fíos. O resultado é o seguinte:
4 táboas, 100 fíos, lote = 1 (unidade por peza): 301 operacións
4 táboas, 100 fíos, lote = 10: 447 operacións
4 táboas, 100 fíos, lote = 100: 625 operacións
Máis tarde aplicarei outros consellos de axuste, realizarei un ciclo de proba completo e engadirei os resultados ao final da publicación.
Fonte: www.habr.com
