


Variti desenvolve protección contra ataques de bots e DDoS, e tamén realiza probas de tensión e carga. Na conferencia HighLoad++ 2018 falamos sobre como protexer os recursos de varios tipos de ataques. En resumo: illar partes do sistema, usar servizos na nube e CDN e actualizar regularmente. Pero aínda non poderás xestionar a protección sen empresas especializadas :)
Antes de ler o texto, podes ler os breves resumos .
E se non che gusta ler ou só queres ver o vídeo, a gravación do noso informe está a continuación baixo o spoiler.
Gravación en vídeo do informe

Moitas empresas xa saben como facer probas de carga, pero non todas fan probas de esforzo. Algúns dos nosos clientes pensan que o seu sitio é invulnerable porque teñen un sistema de alta carga e protexe ben dos ataques. Demostramos que isto non é totalmente certo.
Por suposto, antes de realizar probas, obtemos o permiso do cliente, asinado e selado, e coa nosa axuda non se pode levar a cabo un ataque DDoS a ninguén. As probas realízanse no momento elixido polo cliente, cando o tráfico para o seu recurso é mínimo e os problemas de acceso non afectarán aos clientes. Ademais, dado que sempre pode saír mal durante o proceso de proba, temos un contacto constante co cliente. Isto permítelle non só informar dos resultados acadados, senón tamén cambiar algo durante a proba. Ao rematar as probas, elaboramos sempre un informe no que sinalamos as deficiencias atopadas e damos recomendacións para eliminar as debilidades do sitio.
Como estamos traballando
Ao probar, emulamos unha botnet. Dado que traballamos con clientes que non están localizados nas nosas redes, para garantir que a proba non remate no primeiro minuto debido a que se activan límites ou protección, fornecemos a carga non desde unha IP, senón desde a nosa propia subrede. Ademais, para crear unha carga significativa, temos o noso propio servidor de probas bastante potente.
Postulados
Demasiado non significa bo
Canto menos carga poidamos levar un recurso ao fracaso, mellor. Se podes facer que o sitio deixe de funcionar cunha solicitude por segundo, ou incluso cunha solicitude por minuto, é xenial. Porque segundo a lei da mesquindade, os usuarios ou atacantes caerán accidentalmente nesta vulnerabilidade en particular.
O fracaso parcial é mellor que o fracaso total
Sempre aconsellamos facer sistemas heteroxéneos. Ademais, paga a pena separalos a nivel físico, e non só por contenerización. No caso de separación física, aínda que algo falle no sitio, hai unha alta probabilidade de que non deixe de funcionar completamente e os usuarios seguirán tendo acceso a, polo menos, parte da funcionalidade.
A boa arquitectura é a base da sustentabilidade
A tolerancia a fallos dun recurso e a súa capacidade para soportar ataques e cargas deberían establecerse na fase de deseño, de feito, na fase de debuxo dos primeiros diagramas de fluxo nun caderno. Porque se se meten erros mortais, é posible corrixilos no futuro, pero é moi difícil.
Non só o código debe ser bo, senón tamén a configuración
Moita xente pensa que un bo equipo de desenvolvemento garante a resiliencia do servizo. Un bo equipo de desenvolvemento é esencial, pero tamén é necesario que haxa boas operacións, bo DevOps. Isto significa que se necesitan especialistas que poidan configuralo correctamente. Linux e a rede, escribir correctamente os ficheiros de configuración de NGINX, establecer límites, etc. Se non, o recurso só funcionará ben nas probas, pero nalgún momento da produción, todo fallará.
Diferenzas entre probas de carga e esforzo
A proba de carga permítelle identificar os límites do funcionamento do sistema. As probas de tensión están dirixidas a atopar debilidades nun sistema e úsanse para romper este sistema e ver como se comportará no proceso de falla de determinadas pezas. Neste caso, a natureza da carga adoita ser descoñecida para o cliente antes de que comecen as probas de esforzo.
Características distintivas dos ataques L7
Normalmente dividimos os tipos de carga en cargas nos niveis L7 e L3&4. L7 é unha carga a nivel de aplicación, a maioría das veces significa só HTTP, pero queremos dicir calquera carga a nivel de protocolo TCP.
Os ataques L7 teñen certas características distintivas. En primeiro lugar, chegan directamente á aplicación, é dicir, é improbable que se reflictan a través de medios de rede. Estes ataques utilizan a lóxica e, por iso, consomen CPU, memoria, disco, base de datos e outros recursos de forma moi eficiente e con pouco tráfico.
HTTP Flood
No caso de calquera ataque, a carga é máis fácil de crear que de manexar, e no caso de L7 isto tamén é certo. Non sempre é doado distinguir o tráfico de ataque do tráfico lexítimo, e a maioría das veces pódese facer pola frecuencia, pero se todo está planificado correctamente, entón é imposible comprender a partir dos rexistros onde está o ataque e onde están as solicitudes lexítimas.
Como primeiro exemplo, considere un ataque HTTP Flood. O gráfico mostra que estes ataques adoitan ser moi poderosos; no exemplo seguinte, o número máximo de solicitudes superou os 600 mil por minuto.
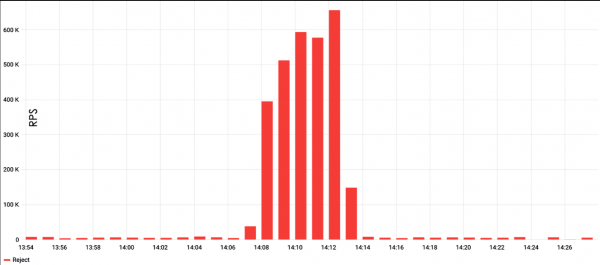
HTTP Flood é a forma máis sinxela de crear carga. Normalmente, necesita algún tipo de ferramenta de proba de carga, como ApacheBench, e establece unha solicitude e un obxectivo. Con un enfoque tan sinxelo, hai unha alta probabilidade de executar o caché do servidor, pero é fácil evitalo. Por exemplo, engadindo cadeas aleatorias á solicitude, o que obrigará ao servidor a servir constantemente unha páxina nova.
Ademais, non te esquezas do axente de usuario no proceso de creación dunha carga. Moitos axentes de usuario das ferramentas de proba populares son filtrados polos administradores do sistema e, neste caso, é posible que a carga simplemente non chegue ao backend. Pode mellorar significativamente o resultado inserindo unha cabeceira máis ou menos válida do navegador na solicitude.
Tan sinxelos como son os ataques HTTP Flood, tamén teñen os seus inconvenientes. En primeiro lugar, son necesarias grandes cantidades de enerxía para crear a carga. En segundo lugar, estes ataques son moi fáciles de detectar, especialmente se proceden dun só enderezo. Como resultado, as solicitudes comezan a ser filtradas inmediatamente polos administradores do sistema ou mesmo a nivel de provedor.
Que hai que buscar
Para reducir o número de solicitudes por segundo sen perder eficacia, cómpre mostrar un pouco de imaxinación e explorar o sitio. Así, pode cargar non só a canle ou o servidor, senón tamén partes individuais da aplicación, por exemplo, bases de datos ou sistemas de ficheiros. Tamén podes buscar no sitio lugares que fagan grandes cálculos: calculadoras, páxinas de selección de produtos, etc. Finalmente, adoita ocorrer que o sitio ten algún tipo de script PHP que xera unha páxina de varios centos de miles de liñas. Este script tamén carga significativamente o servidor e pode converterse nun obxectivo dun ataque.
Onde buscar
Cando analizamos un recurso antes de probalo, primeiro miramos, por suposto, no propio sitio. Buscamos todo tipo de campos de entrada, ficheiros pesados; en xeral, todo o que poida crear problemas para o recurso e ralentizar o seu funcionamento. As ferramentas de desenvolvemento banais en Google Chrome e Firefox axudan aquí, mostrando os tempos de resposta das páxinas.
Tamén analizamos subdominios. Por exemplo, hai unha determinada tenda en liña, abc.com, e ten un subdominio admin.abc.com. O máis probable é que este sexa un panel de administración con autorización, pero se lle cargas, pode crear problemas para o recurso principal.
O sitio pode ter un subdominio api.abc.com. O máis probable é que este sexa un recurso para aplicacións móbiles. A aplicación pódese atopar na App Store ou Google Play, instalar un punto de acceso especial, analizar a API e rexistrar contas de proba. O problema é que a xente adoita pensar que todo o que estea protexido por autorización é inmune aos ataques de denegación de servizo. Supostamente, a autorización é o mellor CAPTCHA, pero non o é. É fácil crear de 10 a 20 contas de proba, pero ao crealas, accedemos a unha funcionalidade complexa e sen disimular.
Por suposto, miramos a historia, en robots.txt e WebArchive, ViewDNS, e buscamos versións antigas do recurso. Ás veces ocorre que os desenvolvedores lanzaron, por exemplo, mail2.yandex.net, pero a versión antiga, mail.yandex.net, permanece. Este mail.yandex.net xa non é compatible, non se lle asignan recursos de desenvolvemento, pero segue consumindo a base de datos. En consecuencia, usando a versión antiga, pode usar eficazmente os recursos do backend e todo o que hai detrás do deseño. Por suposto, isto non sempre ocorre, pero aínda así atopámolo con bastante frecuencia.
Por suposto, analizamos todos os parámetros da solicitude e a estrutura das cookies. Podes, por exemplo, verter algún valor nunha matriz JSON dentro dunha cookie, crear moitos anidamentos e facer que o recurso funcione durante un tempo razoablemente longo.
Carga de busca
O primeiro que se nos ocorre á hora de investigar un sitio é cargar a base de datos, xa que case todo o mundo ten unha busca, e para case todos, por desgraza, está mal protexida. Por algún motivo, os desenvolvedores non prestan a suficiente atención á procura. Pero aquí hai unha recomendación: non debes facer solicitudes do mesmo tipo, porque podes atopar o caché, como é o caso de HTTP flood.
Facer consultas aleatorias á base de datos tampouco sempre é eficaz. É moito mellor crear unha lista de palabras clave que sexan relevantes para a busca. Se volvemos ao exemplo dunha tenda en liña: digamos que o sitio vende pneumáticos de coche e permite configurar o raio dos pneumáticos, o tipo de coche e outros parámetros. En consecuencia, as combinacións de palabras relevantes obrigarán á base de datos a funcionar en condicións moito máis complexas.
Ademais, paga a pena empregar a paxinación: é moito máis difícil que unha busca devolva a penúltima páxina dos resultados da busca que a primeira. É dicir, coa axuda da paxinación podes diversificar lixeiramente a carga.
O seguinte exemplo mostra a carga de busca. Pódese ver que desde o primeiro segundo da proba a unha velocidade de dez solicitudes por segundo, o sitio caeu e non respondeu.
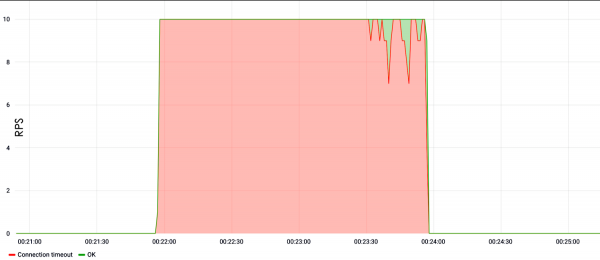
Se non hai busca?
Se non hai busca, isto non significa que o sitio non conteña outros campos de entrada vulnerables. Este campo pode ser autorización. Hoxe en día, aos desenvolvedores gústalles facer hash complexos para protexer a base de datos de inicio de sesión dun ataque de táboa arco da vella. Isto é bo, pero estes hash consomen moitos recursos da CPU. Un gran fluxo de autorizacións falsas leva a un fallo do procesador e, como resultado, o sitio deixa de funcionar.
A presenza no sitio de todo tipo de formularios para comentarios e comentarios é un motivo para enviar textos moi grandes alí ou simplemente crear unha inundación masiva. Ás veces os sitios aceptan ficheiros adxuntos, incluso en formato gzip. Neste caso, collemos un ficheiro de 1 TB, comprimimos a varios bytes ou kilobytes mediante gzip e enviámolo ao sitio. Despois descomprime e obtense un efecto moi interesante.
API Rest
Gustaríame prestar un pouco de atención a servizos tan populares como a API Rest. Asegurar unha API Rest é moito máis difícil que un sitio web normal. Mesmo os métodos triviais de protección contra a forza bruta de contrasinais e outras actividades ilexítimas non funcionan para a API Rest.
A API Rest é moi fácil de romper porque accede directamente á base de datos. Ao mesmo tempo, o fracaso deste servizo implica consecuencias bastante graves para as empresas. O caso é que a API Rest adoita usarse non só para o sitio web principal, senón tamén para a aplicación móbil e algúns recursos comerciais internos. E se todo isto cae, entón o efecto é moito máis forte que no caso dun simple fallo do sitio web.
Cargando contido pesado
Se se nos ofrece probar algunha aplicación ordinaria dunha páxina, páxina de destino ou sitio web de tarxetas de visita que non teña unha funcionalidade complexa, buscamos contido pesado. Por exemplo, imaxes grandes que envía o servidor, ficheiros binarios, documentación en pdf - intentamos descargar todo isto. Tales probas cargan ben o sistema de ficheiros e obstruyen as canles, polo que son eficaces. É dicir, aínda que non coloque o servidor, descargando un ficheiro grande a baixas velocidades, simplemente obstruirá a canle do servidor de destino e entón producirase unha denegación de servizo.
Un exemplo desta proba mostra que a unha velocidade de 30 RPS o sitio deixou de responder ou produciu erros no servidor 500.
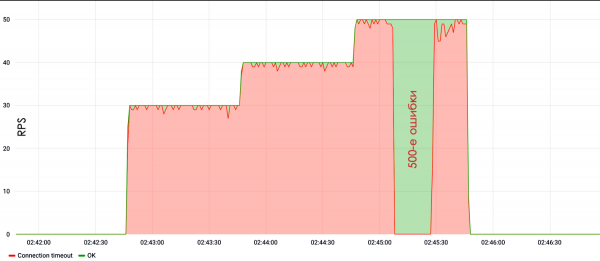
Non te esquezas de configurar servidores. Moitas veces podes atopar que unha persoa comprou unha máquina virtual, instalou alí Apache, configurou todo por defecto, instalou unha aplicación PHP e a continuación podes ver o resultado.
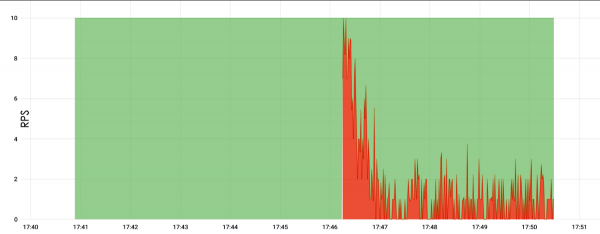
Aquí a carga foi á raíz e ascendeu a só 10 RPS. Agardamos 5 minutos e o servidor fallou. É certo que non se sabe completamente por que caeu, pero hai unha suposición de que simplemente tiña demasiada memoria e, polo tanto, deixou de responder.
Baseado en ondas
No último ou dous anos, os ataques de ondas fixéronse bastante populares. Isto débese ao feito de que moitas organizacións compran determinadas pezas de hardware para a protección DDoS, que requiren un certo tempo para acumular estatísticas para comezar a filtrar o ataque. É dicir, non filtran o ataque nos primeiros 30-40 segundos, porque acumulan datos e aprenden. En consecuencia, nestes 30-40 segundos pode lanzar tanto no sitio que o recurso permanecerá durante moito tempo ata que todas as solicitudes estean aclaradas.
No caso do ataque inferior, houbo un intervalo de 10 minutos, despois do cal chegou unha nova parte modificada do ataque.
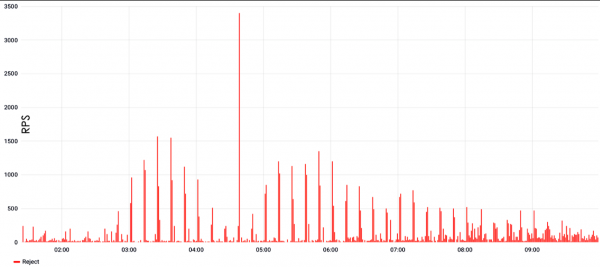
É dicir, a defensa aprendeu, comezou a filtrarse, pero chegou unha nova parte do ataque, completamente diferente, e a defensa comezou a aprender de novo. De feito, o filtrado deixa de funcionar, a protección faise ineficaz e o sitio non está dispoñible.
Os ataques de ondas caracterízanse por valores moi altos no pico, podendo chegar a cen mil ou un millón de solicitudes por segundo, no caso de L7. Se falamos de L3 e 4, entón pode haber centos de gigabits de tráfico ou, en consecuencia, centos de mpps, se contas en paquetes.
O problema deste tipo de ataques é a sincronización. Os ataques proveñen dunha botnet e requiren un alto grao de sincronización para crear un pico puntual moi grande. E esta coordinación non sempre funciona: ás veces a saída é unha especie de pico parabólico, que parece bastante patético.
Non só HTTP
Ademais de HTTP en L7, gústanos explotar outros protocolos. Como regra xeral, un sitio web normal, especialmente un hospedaxe normal, ten protocolos de correo electrónico e MySQL sobresaíndo. Os protocolos de correo están suxeitos a menos carga que as bases de datos, pero tamén se poden cargar de forma bastante eficiente e terminar cunha CPU sobrecargada no servidor.
Tivemos bastante éxito usando a vulnerabilidade SSH de 2016. Agora esta vulnerabilidade foi solucionada para case todos, pero isto non significa que non se poida enviar carga a SSH. Pode. Simplemente hai unha enorme carga de autorizacións, SSH consume case toda a CPU do servidor e, a continuación, o sitio web colapsa cunha ou dúas solicitudes por segundo. En consecuencia, estas unha ou dúas solicitudes baseadas nos rexistros non se poden distinguir dunha carga lexítima.
Moitas conexións que abrimos en servidores tamén seguen sendo relevantes. Anteriormente, Apache era culpable diso, agora nginx é realmente culpable diso, xa que a miúdo está configurado por defecto. O número de conexións que nginx pode manter aberta é limitado, polo que abrimos este número de conexións, nginx xa non acepta unha nova conexión e, como resultado, o sitio non funciona.
O noso clúster de proba ten CPU suficiente para atacar o enlace SSL. En principio, como mostra a práctica, ás veces ás botnets tamén lles gusta facer isto. Por unha banda, está claro que non se pode prescindir de SSL, porque os resultados de Google, a clasificación, a seguridade. Por outra banda, SSL, desafortunadamente, ten un problema de CPU.
L3 e 4
Cando falamos dun ataque nos niveis L3 e 4, adoitamos falar dun ataque a nivel de ligazón. Tal carga case sempre é distinguible dunha lexítima, a non ser que se trate dun ataque SYN-flood. O problema dos ataques SYN-flood para ferramentas de seguridade é o seu gran volume. O valor máximo de L3 e 4 foi de 1,5-2 Tbit/s. Este tipo de tráfico é moi difícil de procesar incluso para grandes empresas, como Oracle e Google.
SYN e SYN-ACK son paquetes que se usan ao establecer unha conexión. Polo tanto, SYN-flood é difícil de distinguir dunha carga lexítima: non está claro se se trata dun SYN que chegou a establecer unha conexión ou parte dunha inundación.
UDP-inundación
Normalmente, os atacantes non teñen as capacidades que temos, polo que a amplificación pódese usar para organizar ataques. É dicir, o atacante explora Internet e atopa servidores vulnerables ou configurados incorrectamente que, por exemplo, en resposta a un paquete SYN, responden con tres SYN-ACK. Ao falsificar o enderezo de orixe desde o enderezo do servidor de destino, é posible aumentar a potencia, por exemplo, tres veces cun só paquete e redirixir o tráfico á vítima.
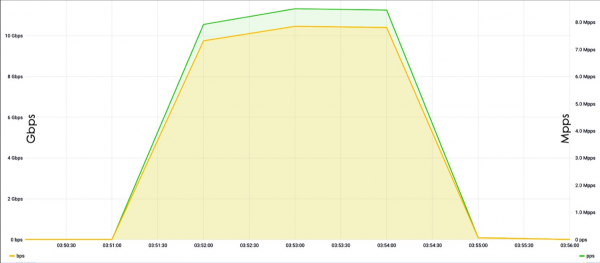
O problema das amplificacións é que son difíciles de detectar. Exemplos recentes inclúen o caso sensacional do vulnerable memcached. Ademais, agora hai moitos dispositivos IoT, cámaras IP, que tamén se configuran na súa maioría por defecto, e por defecto están configurados incorrectamente, polo que os atacantes a miúdo realizan ataques a través destes dispositivos.
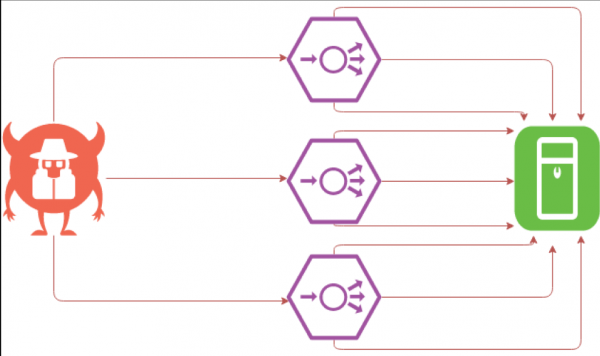
SYN-flood difícil
SYN-flood é probablemente o tipo de ataque máis interesante dende o punto de vista dun programador. O problema é que os administradores do sistema adoitan usar o bloqueo de IP para protexerse. Ademais, o bloqueo de IP afecta non só aos administradores do sistema que actúan mediante scripts, senón tamén, por desgraza, a algúns sistemas de seguridade que se compran por moito diñeiro.
Este método pode converterse nun desastre, porque se os atacantes substitúen enderezos IP, a empresa bloqueará a súa propia subrede. Cando o cortafuegos bloquea o seu propio clúster, as comunicacións externas interromperanse e o recurso fallará.
Ademais, non é difícil bloquear a túa propia rede. Se a oficina do cliente dispón dunha rede wifi ou se o rendemento dos recursos se mide mediante varios sistemas de monitorización, tomamos o enderezo IP deste sistema de monitorización ou a wifi da oficina do cliente e usámolo como fonte. Ao final, o recurso parece estar dispoñible, pero os enderezos IP de destino están bloqueados. Así, a rede Wi-Fi da conferencia HighLoad, onde se presenta o novo produto da compañía, pode quedar bloqueada, o que supón certos custos comerciais e económicos.
Durante a proba, non podemos usar a amplificación mediante memcached con ningún recurso externo, porque hai acordos para enviar tráfico só aos enderezos IP permitidos. En consecuencia, utilizamos a amplificación a través de SYN e SYN-ACK, cando o sistema responde ao envío dun SYN con dous ou tres SYN-ACK, e na saída o ataque multiplícase por dúas ou tres veces.
Ferramentas
Unha das principais ferramentas que usamos para a carga de traballo L7 é Yandex-tank. En particular, unha pantasma úsase como arma, ademais de que hai varios scripts para xerar cartuchos e para analizar os resultados.
Tcpdump úsase para analizar o tráfico de rede e Nmap para a análise do servidor. OpenSSL e un pouco de maxia personalizada coa biblioteca DPDK úsanse para xerar carga nos niveis L3 e L4. DPDK é unha biblioteca de Intel que che permite traballar coa interface de rede sen pasar pola pila. Linux, aumentando así a eficiencia. Naturalmente, empregamos DPDK non só en L3 e L4, senón tamén en L7, porque nos permite xerar cargas moi elevadas, de ata varios millóns de solicitudes por segundo desde unha única máquina.
Tamén usamos certos xeradores de tráfico e ferramentas especiais que escribimos para probas específicas. Se lembramos a vulnerabilidade baixo SSH, entón o conxunto anterior non se pode explotar. Se atacamos o protocolo de correo, tomamos utilidades de correo ou simplemente escribimos scripts nelas.
Descubrimentos
Como conclusión gustaríame dicir:
- Ademais das probas de carga clásicas, é necesario realizar probas de esforzo. Temos un exemplo real onde o subcontratista dun socio só realizou probas de carga. Mostrou que o recurso pode soportar a carga normal. Pero entón apareceu unha carga anormal, os visitantes do sitio comezaron a usar o recurso un pouco diferente e, como resultado, o subcontratista deitouse. Así, paga a pena buscar vulnerabilidades aínda que xa estea protexido contra ataques DDoS.
- É necesario illar algunhas partes do sistema doutras. Se tes unha busca, tes que movela a máquinas separadas, é dicir, nin sequera a Docker. Porque se falla a busca ou a autorización, polo menos algo seguirá funcionando. No caso dunha tenda en liña, os usuarios seguirán atopando produtos no catálogo, saíndo do agregador, comprando se xa están autorizados ou autorizando a través de OAuth2.
- Non descoides todo tipo de servizos na nube.
- Use CDN non só para optimizar os atrasos da rede, senón tamén como medio de protección contra ataques ao esgotamento da canle e simplemente inundando o tráfico estático.
- É necesario utilizar servizos de protección especializados. Non pode protexerse dos ataques L3 e 4 a nivel de canle, porque o máis probable é que simplemente non teña unha canle suficiente. Tamén é pouco probable que combatas os ataques L7, xa que poden ser moi grandes. Ademais, a busca de pequenos ataques segue sendo prerrogativa de servizos especiais, algoritmos especiais.
- Actualizar regularmente. Isto aplícase non só ao núcleo, senón tamén ao daemon SSH, especialmente se os tes abertos ao exterior. En principio, hai que actualizar todo, porque é improbable que poidas rastrexar certas vulnerabilidades por ti mesmo.
Fonte: www.habr.com
