

X5 opera 43 centros de distribución e 4 camións propios, o que garante a subministración ininterrompida de produtos a 029 tendas. Neste artigo compartirei a miña experiencia na creación dun sistema interactivo para supervisar os eventos do almacén desde cero. A información será útil para os loxísticos de empresas comerciais con varias ducias de centros de distribución que xestionan unha ampla gama de produtos.

Como regra xeral, a construción de sistemas de seguimento e xestión de procesos empresariais comeza co procesamento de mensaxes e incidencias. Ao mesmo tempo, bótase en falta un importante punto tecnolóxico relacionado coa posibilidade de automatizar o feito mesmo de producirse eventos empresariais e rexistrar incidencias. A maioría dos sistemas empresariais, como WMS, TMS, etc., teñen ferramentas integradas para supervisar os seus propios procesos. Pero, se se trata de sistemas de diferentes fabricantes ou a funcionalidade de vixilancia non está suficientemente desenvolvida, ten que solicitar modificacións caras ou atraer consultores especializados para axustes adicionais.
Consideremos un enfoque no que só necesitamos unha pequena parte da consulta asociada á identificación de fontes (táboas) para obter indicadores do sistema.
A especificidade dos nosos almacéns é que varios sistemas de xestión de almacén (WMS Exceed) funcionan nun complexo loxístico. Os almacéns divídense segundo categorías de almacenamento de mercadorías (seco, alcol, conxelados, etc.) non só loxicamente. Dentro dun complexo loxístico hai varios edificios de almacén separados, cada un dos cales está xestionado polo seu propio WMS.

Para formar unha imaxe xeral dos procesos que ocorren no almacén, os xestores analizan os informes de cada WMS varias veces ao día, procesan as mensaxes dos operadores do almacén (receptores, recolectores, apiladores) e resumen os indicadores operativos reais para a súa reflexión no taboleiro informativo.
Para aforrar tempo aos xestores, decidimos desenvolver un sistema económico para o control operativo dos eventos do almacén. O novo sistema, ademais de mostrar indicadores "quentes" do rendemento operativo dos procesos de almacén, tamén debería axudar aos xestores no rexistro de incidencias e o seguimento da execución das tarefas para eliminar as causas que afectan aos indicadores dados. Despois de realizar unha auditoría xeral da arquitectura informática da empresa, decatámonos de que xa existen partes individuais do sistema necesario dun xeito ou doutro no noso panorama e para elas hai tanto un exame da configuración como dos servizos de apoio necesarios. Só queda levar todo o concepto nunha única solución arquitectónica e estimar o alcance do desenvolvemento.
Despois de avaliar a cantidade de traballo que hai que facer para construír un novo sistema, decidiuse dividir o proxecto en varias etapas:
- Recollida de indicadores para procesos de almacén, visualización e control de indicadores e desviacións
- Automatización de estándares de procesos e rexistro de aplicacións no servizo de servizos empresariais por desviacións
- Seguimento proactivo con previsión de carga e creación de recomendacións para os xestores.
Na primeira fase, o sistema debe recoller porcións preparadas de datos operativos de todos os WMS do complexo. A lectura prodúcese case en tempo real (intervalos inferiores a 5 minutos). O truco é que os datos deben obterse do DBMS de varias decenas de almacéns ao despregar o sistema en toda a rede. Os datos operativos recibidos son procesados pola lóxica do núcleo do sistema para calcular as desviacións dos indicadores planificados e calcular estatísticas. Os datos tratados deste xeito deben mostrarse na tableta do xestor ou no taboleiro de información do almacén en forma de gráficos e diagramas comprensibles.

Ao elixir un sistema axeitado para a implementación piloto da primeira etapa, escollemos Zabbix. Este sistema xa se utiliza para supervisar o rendemento informático dos sistemas de almacén. Ao engadir unha instalación separada para recoller métricas comerciais do funcionamento do almacén, podes obter unha imaxe xeral do estado de saúde do almacén.
A arquitectura xeral do sistema resultou como na figura.
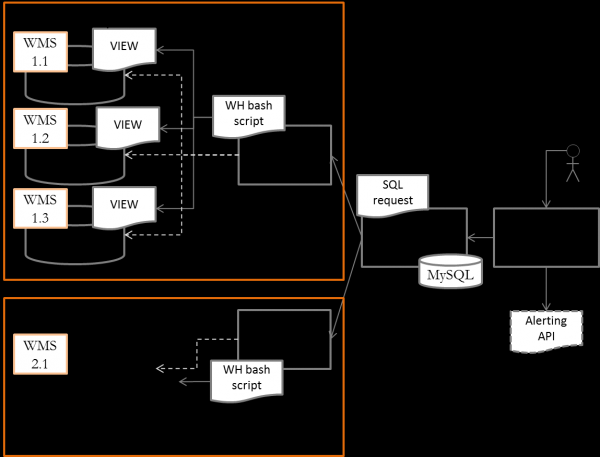
Cada instancia de WMS defínese como host para o sistema de monitorización. As métricas son recollidas por un servidor central na rede do centro de datos mediante a execución dun script cunha consulta SQL preparada. Se precisa supervisar un sistema que non recomenda o acceso directo á base de datos (por exemplo, SAP EWM), pode utilizar chamadas de script a funcións API documentadas para obter indicadores ou escribir un programa sinxelo en python/vbascript.
Implígase unha instancia de proxy Zabbix na rede do almacén para distribuír a carga desde o servidor principal. A través de Proxy, garante o traballo con todas as instancias WMS locais. A próxima vez que o servidor Zabbix solicite parámetros, execútase un script no host co proxy Zabbix para solicitar métricas da base de datos WMS.
Para mostrar gráficos e indicadores de almacén na pantalla central servidor Estamos a implementar Grafana en Zabbix. Ademais de mostrar paneis preparados con infografías de rendemento do almacén, Grafana usarase para monitorizar as desviacións métricas e enviar alertas automáticas ao sistema de servizo do almacén para a xestión de incidentes empresariais.
Como exemplo, consideremos a implementación do control de carga na zona de recepción do almacén. Elixíronse os seguintes como os principais indicadores do rendemento do proceso nesta área do almacén:
- número de vehículos na zona de recepción, tendo en conta os estados (previstos, chegados, documentos, descarga, saída;
- carga de traballo das áreas de colocación e reposición (segundo as condicións de almacenamento).
Configuración
A instalación e configuración dos compoñentes principais do sistema (SQLcl, Zabbix, Grafana) descríbese en varias fontes e non se repetirá aquí. O uso de SQLcl en lugar de SQLplus débese ao feito de que SQLcl (a interface de liña de comandos do DBMS de Oracle, escrita en java) non require instalación adicional do cliente Oracle e funciona fóra da caixa.
Describirei os puntos principais aos que se debe prestar atención ao usar Zabbix para supervisar os indicadores do proceso de negocio do almacén e unha das posibles formas de implementalos. Ademais, esta non é unha publicación sobre seguridade. A seguridade das conexións e o uso dos métodos presentados require un estudo adicional no proceso de transferencia da solución piloto á operación produtiva.
O principal é que ao implementar un sistema deste tipo, é posible prescindir da programación, utilizando a configuración proporcionada polo sistema.
O sistema de vixilancia Zabbix ofrece varias opcións para recoller métricas do sistema supervisado. Isto pódese facer tanto mediante un sondeo directo dos hosts monitorizados como mediante un método máis avanzado de envío de datos ao servidor a través do zabbix_sender do host, incluíndo métodos para configurar parámetros de descubrimento de baixo nivel. Para resolver o noso problema, o método de sondeo directo de hosts por un servidor central é bastante axeitado, porque isto permítelle obter un control total sobre a secuencia de adquisición de métricas e garante que use un conxunto de configuracións/scripts sen necesidade de distribuílos a cada host supervisado.
Como "suxeitos de proba" para depurar e configurar o sistema, usamos a folla de traballo WMS para a xestión da aceptación:
- Vehículos en recepción, todos os que chegaron: Todos os vehículos con estados para o período "- 72 horas desde a hora actual" - Identificador de consulta SQL: getCars.
- Historial de todos os estados de vehículos: estados de todos os vehículos que chegan dentro de 72 horas - Identificador de consulta SQL: Historia dos coches.
- Vehículos programados para aceptación: estados de todos os vehículos con chegada no estado "Programado", intervalo de tempo "- 24 horas" e "+24 horas" desde a hora actual - identificador de consulta SQL: cochesEn.
Entón, despois de decidir un conxunto de métricas de rendemento do almacén, prepararemos consultas SQL para a base de datos WMS. Para executar consultas, é recomendable non usar a base de datos principal, senón a súa copia "quente" - en espera.
Conectámonos ao DBMS de Oracle en espera para recibir datos. Enderezo IP para conectarse á base de datos de proba 192.168.1.106Gardamos os parámetros de conexión en servidor Zabbix en TNSNames.ORA do directorio de traballo de SQLcl:
# cat /opt/sqlcl/bin/TNSNames.ORA
WH1_1=
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.1.106)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = WH1_1)
)
)Isto permitiranos executar consultas SQL a cada host a través de EZconnect, especificando só o inicio de sesión/contrasinal e o nome da base de datos:
# sql znew/Zabmon1@WH1_1Gardamos as consultas SQL preparadas no cartafol de traballo do servidor Zabbix:
/etc/zabbix/sqle permitir o acceso ao usuario zabbix do noso servidor:
# chown zabbix:zabbix -R /etc/zabbix/sqlOs ficheiros con solicitudes reciben un nome de identificador único para acceder desde o servidor Zabbix. Cada consulta de base de datos a través de SQLcl nos devolve varios parámetros. Tendo en conta as características específicas de Zabbix, que só pode procesar unha métrica por solicitude, utilizaremos scripts adicionais para analizar os resultados da consulta en métricas individuais.
Imos preparar o script principal, chamémoslle wh_Metrics.sh, para chamar unha consulta SQL á base de datos, gardar os resultados e devolver unha métrica técnica con indicadores do éxito da recuperación de datos:
#!/bin/sh
## настройка окружения</i>
export ORACLE_HOME=/usr/lib/oracle/11.2/client64
export PATH=$PATH:$ORACLE_HOME/bin
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib64:/usr/lib:$ORACLE_HOME/bin
export TNS_ADMIN=$ORACLE_HOME/network/admin
export JAVA_HOME=/
alias sql="opt/sqlcl/bin/sql"
## задаём путь к файлу с sql-запросом и параметризованное имя файла
scriptLocation=/etc/zabbix/sql
sqlFile=$scriptLocation/sqlScript_"$2".sql
## задаём путь к файлу для хранения результатов
resultFile=/etc/zabbix/sql/mon_"$1"_main.log
## настраиваем строку подключения к БД
username="$3"
password="$4"
tnsname="$1"
## запрашиваем результат из БД
var=$(sql -s $username/$password@$tnsname < $sqlFile)
## форматируем результат запроса и записываем в файл
echo $var | cut -f5-18 -d " " > $resultFile
## проверяем наличие ошибок
if grep -q ora "$resultFile"; then
echo null > $resultFile
echo 0
else
echo 1
fiColocamos o ficheiro rematado co script no cartafol para almacenar scripts externos de acordo coa configuración de proxy de Zabbix (por defecto - /usr/local/share/zabbix/externalscripts).
A identificación da base de datos da que o script recibirá resultados pasarase como parámetro de script. O ID da base de datos debe coincidir coa liña de configuración do ficheiro TNSNames.ORA.
O resultado da chamada de consulta SQL gárdase nun ficheiro como mon_base_id_main.log onde base_id = O identificador de base de datos recibido como parámetro de script. A división do ficheiro de resultados por identificadores de base de datos ofrécese en caso de solicitudes do servidor a varias bases de datos simultaneamente. A consulta devolve unha matriz de valores bidimensional ordenada.
O seguinte script, chamémoslle getMetrica.sh, é necesario para obter unha métrica especificada dun ficheiro co resultado dunha solicitude:
#!/bin/sh
## определяем имя файла с результатом запроса
resultFile=/etc/zabbix/sql/mon_”$1”_main.log
## разбираем массив значений результата средствами скрипта:
## при работе со статусами, запрос возвращает нам двумерный массив (RSLT) в виде
## {статус1 значение1 статус2 значение2…} разделённых пробелами (значение IFS)
## параметром запроса передаём код статуса и скрипт вернёт значение
IFS=’ ‘
str=$(cat $resultFile)
status_id=null
read –ra RSLT <<< “$str”
for i in “${RSLT[@]}”; do
if [[ “$status_id” == null ]]; then
status_id=”$I"
elif [[ “$status_id” == “$2” ]]; then
echo “$i”
break
else
status_id=null
fi
doneAgora estamos preparados para configurar Zabbix e comezar a supervisar os indicadores dos procesos de aceptación do almacén.
Un axente Zabbix está instalado e configurado en cada nodo de base de datos.
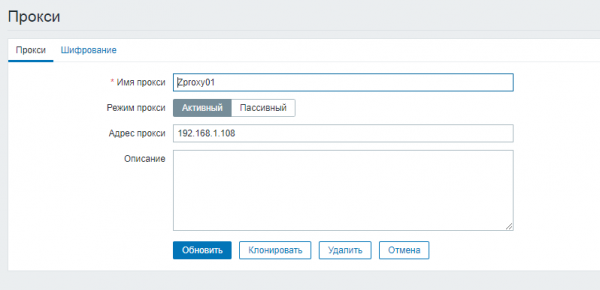
No servidor principal definimos todos os servidores con proxy Zabbix. Para a configuración, vai ao seguinte camiño:
Administración → Proxy → Crear proxy
Definimos hosts controlados:
Configuración → Anfitrións → Crear host
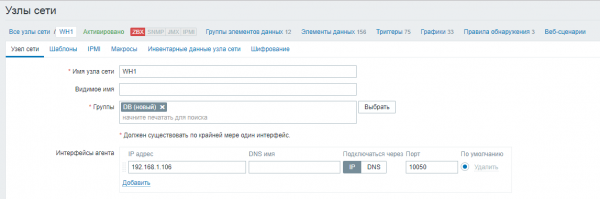
O nome de host debe coincidir co nome de host especificado no ficheiro de configuración do axente.
Especificamos o grupo para o nodo, así como o enderezo IP ou o nome DNS do nodo coa base de datos.
Creamos métricas e especificamos as súas propiedades:
Configuración → Nodos → 'nome de nodo' → Elementos de datos>Crear elemento de datos
1) Cree unha métrica principal para consultar todos os parámetros da base de datos
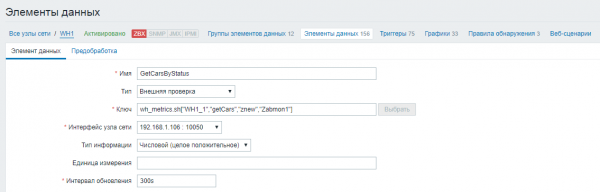
Establecemos o nome do elemento de datos, indicamos o tipo "Verificación externa". No campo “Key” definimos un script ao que pasamos como parámetros o nome da base de datos Oracle, o nome da consulta sql, o login e o contrasinal para conectarse á base de datos. Establece o intervalo de actualización da consulta en 5 minutos (300 segundos).
2) Cree as métricas restantes para cada estado do vehículo. Os valores destas métricas xeraranse en función do resultado da comprobación da métrica principal.
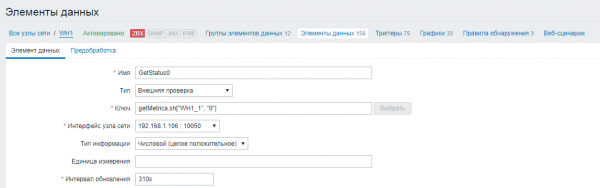
Establecemos o nome do elemento de datos, indicamos o tipo "Verificación externa". No campo "Clave", definimos un script ao que lle pasamos como parámetros o nome da base de datos Oracle e o código de estado cuxo valor queremos rastrexar. Establecemos o intervalo de actualización da consulta en 10 segundos máis que a métrica principal (310 segundos) para que os resultados teñan tempo para escribirse no ficheiro.
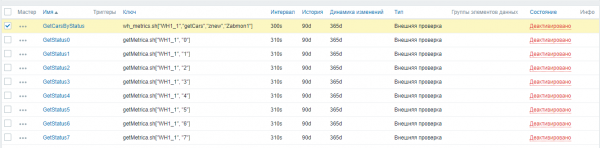
Para obter as métricas correctamente, é importante a orde na que se activan os cheques. Para evitar conflitos ao recibir datos, en primeiro lugar activamos a métrica principal GetCarsByStatus chamando ao script - wh_Metrics.sh.
Configuración → Nodos → 'nome de nodo' → Elementos de datos → Subfiltro “Comprobacións externas”. Marque a verificación necesaria e prema en "Activar".
A continuación, activamos as métricas restantes nunha soa operación, seleccionándoas todas xuntas:
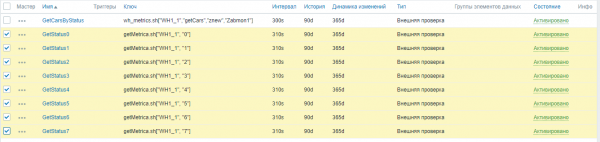
Agora Zabbix comezou a recoller métricas de negocio de almacén.
Nos artigos seguintes, analizaremos con máis detalle a conexión de Grafana e a creación de paneis de información de operacións de almacén para varias categorías de usuarios. Grafana tamén se utiliza para controlar as desviacións nas operacións do almacén e, dependendo dos límites e frecuencia das desviacións, rexistrar incidencias no sistema do centro de servizos de xestión de almacén mediante API ou simplemente enviar notificacións ao xestor por correo electrónico.

Fonte: www.habr.com
