

Baseado nun debate de chat
Recentemente, xurdiron verdadeiras batallas sobre a definición de DevOps e SRE.
A pesar de que en moitos aspectos as discusións sobre este tema xa me puxeron os dentes, incluída eu, decidín achegar a miña opinión sobre este tema ao tribunal da comunidade Habra. Para os que estean interesados, benvidos a cat. E que todo comece de novo!
prehistoria
Entón, na antigüidade, un equipo de desenvolvedores de software e administradores de servidores vivían por separado. O primeiro escribiu con éxito o código, o segundo, usando varias palabras cálidas e afectuosas dirixidas ao primeiro, configurou os servidores, chegando periodicamente aos desenvolvedores e recibindo como resposta un completo "todo funciona na miña máquina". O negocio estaba esperando polo software, todo estaba inactivo, rompíase periodicamente, todos estaban nerviosos. Sobre todo o que pagou toda esta lea. Era da lámpada gloriosa. Ben, xa sabes de onde vén DevOps.
O nacemento das prácticas DevOps
Entón viñeron rapaces serios e dixeron: esta non é unha industria, non se pode traballar así. E trouxeron modelos de ciclo de vida. Aquí, por exemplo, está o modelo V.
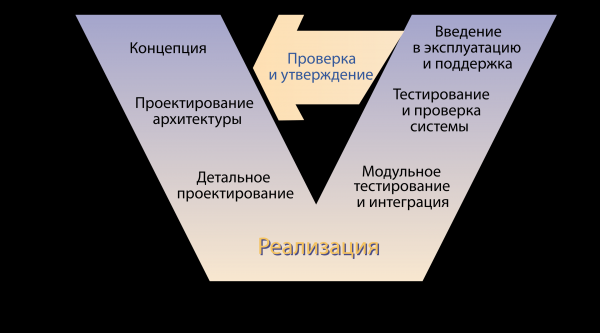
Entón, que vemos? Unha empresa vén cun concepto, os arquitectos deseñan solucións, os desenvolvedores escriben código e despois falla. Alguén proba o produto dalgún xeito, alguén entrégao ao usuario final e nalgún lugar da saída deste modelo milagre senta un cliente empresarial solitario esperando o clima prometido á beira do mar. Chegamos á conclusión de que necesitamos métodos que nos permitan establecer este proceso. E decidimos crear prácticas que as implementasen.
Unha digresión lírica sobre o que é a práctica
Por práctica refírome a unha combinación de tecnoloxía e disciplina. Un exemplo é a práctica de describir a infraestrutura usando código terraform. A disciplina é como describir a infraestrutura con código, está na cabeza do desenvolvedor e a tecnoloxía é a propia terraforma.
E decidiron chamarlles prácticas DevOps, creo que querían dicir desde Desenvolvemento ata Operacións. Ocorréronnos varias cousas intelixentes: prácticas de CI/CD, prácticas baseadas no principio IaC, miles delas. E listo, os desenvolvedores escriben código, os enxeñeiros de DevOps transforman a descrición do sistema en forma de código en sistemas de traballo (si, o código é, por desgraza, só unha descrición, pero non a incorporación do sistema), a entrega continúa, etcétera. Os administradores de onte, despois de dominar novas prácticas, se reciclaron con orgullo como enxeñeiros de DevOps, e todo foi a partir de aí. E houbo noite, e houbo mañá... perdón, non de alí.
Non todo está ben de novo, grazas a Deus
Axiña que todo se calmou e varios "metodólogos" astutos comezaron a escribir libros grosos sobre as prácticas de DevOps, xurdiron silenciosamente as disputas sobre quen era o famoso enxeñeiro de DevOps e que DevOps é unha cultura de produción, o descontento xurdiu de novo. De súpeto, descubriuse que a entrega de software é unha tarefa absolutamente non trivial. Cada infraestrutura de desenvolvemento ten a súa propia pila, nalgún lugar necesitas montala, nalgún lugar necesitas implantar o ambiente, aquí necesitas Tomcat, aquí necesitas un xeito astuto e complicado de lanzalo; en xeral, a túa cabeza está a bater. E o problema, curiosamente, resultou estar principalmente na organización dos procesos: esta función de entrega, como un pescozo de botella, comezou a bloquear os procesos. Ademais, ninguén cancelou Operacións. Non é visible no modelo V, pero aínda hai todo o ciclo de vida á dereita. En consecuencia, cómpre manter dalgún xeito a infraestrutura, supervisar a vixilancia, resolver incidencias e tamén xestionar a entrega. Eses. séntese cun pé tanto no desenvolvemento como no funcionamento e, de súpeto, resultou ser Desenvolvemento e operacións. E despois houbo o bombo xeral dos microservizos. E con eles, o desenvolvemento das máquinas locais comezou a moverse á nube: tenta depurar algo localmente, se hai decenas e centos de microservizos, a entrega constante convértese nun medio de supervivencia. Para unha "pequena empresa modesta" estaba ben, pero aínda así? Que pasa con Google?
SRE de Google
Google chegou, comeu os cactos máis grandes e decidiu: non necesitamos isto, necesitamos fiabilidade. E hai que xestionar a fiabilidade. E decidín que necesitamos especialistas que xestionen a fiabilidade. Chameinos enxeñeiros de SR e díxenlles: iso é para ti, faino ben como de costume. Aquí está SLI, aquí está SLO, aquí está o seguimento. E meteu o nariz nas operacións. E chamou ao seu "DevOps fiable" SRE. Todo parece estar ben, pero hai un truco sucio que Google podería permitirse: para o posto de enxeñeiros de SR, contratar persoas que fosen desenvolvedores cualificados e tamén fixesen un pouco de deberes e entendesen o funcionamento dos sistemas de traballo. Ademais, o propio Google ten problemas para contratar a este tipo de persoas -principalmente porque aquí compite consigo mesmo- é necesario describir a lóxica empresarial a alguén. A entrega foi asignada aos enxeñeiros de liberación, SR: os enxeñeiros xestionan a fiabilidade (por suposto, non directamente, senón influíndo na infraestrutura, cambiando a arquitectura, rastrexando cambios e indicadores, xestionando incidentes). Ben, podes . Pero que pasa se non es Google, pero a fiabilidade aínda é unha preocupación?
Desenvolvemento de ideas DevOps
Xusto entón chegou Docker, que xurdiu a partir de lxc, e despois varios sistemas de orquestración como Docker Swarm e Kubernetes, e os enxeñeiros de DevOps exhalaron: a unificación de prácticas simplificou a entrega. Simplificouno ata tal punto que se fixo posible incluso terceirizar a entrega aos desenvolvedores: o que é deployment.yaml. A contenerización resolve o problema. E a madurez dos sistemas CI/CD xa está no nivel de escribir un ficheiro e xa estamos: os desenvolvedores poden xestionalo eles mesmos. E despois comezamos a falar de como podemos facer o noso propio SRE, con... ou polo menos con alguén.
SRE non está en Google
Ben, ok, entregamos a entrega, parece que podemos exhalar, volver aos bos vellos tempos, cando os administradores observaban a carga do procesador, axustaban os sistemas e tomaban tranquilamente algo incomprensible de cuncas en paz e tranquilidade... Para. Non por iso comezamos todo (que é unha mágoa!). De súpeto, resulta que no enfoque de Google podemos adoptar facilmente prácticas excelentes: non é importante a carga do procesador nin a frecuencia con que cambiamos os discos alí nin optimizamos o custo na nube, pero as métricas comerciais son as mesmas notorias. SLx. E ninguén lles quitou a xestión de infraestruturas, e necesitan resolver incidencias, estar de servizo periodicamente e, en xeral, estar ao tanto dos procesos empresariais. E rapaces, comezade a programar pouco a pouco a bo nivel, xa vos está esperando Google.
Para resumir. De súpeto, pero xa estás canso de ler e non podes esperar a cuspir e escribirlle ao autor nun comentario sobre o artigo. DevOps como práctica de entrega sempre foi e será. E non vai a ningures. SRE como conxunto de prácticas operativas fai que esta entrega sexa exitosa.
Fonte: www.habr.com
