

Suxiro que lea a transcrición do informe de finais de 2019 de Alexander Valyalkin "Go optimizations in VictoriaMetrics"
— un DBMS rápido e escalable para almacenar e procesar datos en forma de serie temporal (o rexistro forma o tempo e un conxunto de valores correspondentes a este tempo, por exemplo, obtidos mediante sondaxes periódicas do estado dos sensores ou recollida de métricas).

Aquí tedes unha ligazón ao vídeo deste informe:

Fálanos de ti. Son Alexander Valyalkin. Aquí . Encántame Go e a optimización do rendemento. Escribín moitas bibliotecas útiles e non tan útiles. Comezan por calquera dos dous fast, ou con quick prefixo.
Actualmente estou traballando en VictoriaMetrics. Que é e que estou facendo alí? Disto falarei nesta presentación.

O esquema do informe é o seguinte:
- En primeiro lugar, vouche dicir o que é VictoriaMetrics.
- Despois vouche dicir cales son as series temporais.
- Despois contarei como funciona unha base de datos de series temporais.
- A continuación, falarei sobre a arquitectura da base de datos: en que consiste.
- E despois pasemos ás optimizacións que ten VictoriaMetrics. Esta é unha optimización para o índice invertido e unha optimización para a implementación do conxunto de bits en Go.

Alguén do público sabe o que é VictoriaMetrics? Vaia, moita xente xa o sabe. É unha boa noticia. Para quen non o saiba, esta é unha base de datos de series temporais. Está baseado na arquitectura ClickHouse, nalgúns detalles da implementación de ClickHouse. Por exemplo, como: MergeTree, cálculo paralelo en todos os núcleos de procesadores dispoñibles e optimización do rendemento traballando en bloques de datos que se colocan na caché do procesador.
VictoriaMetrics ofrece unha mellor compresión de datos que outras bases de datos de series temporais.
Escala verticalmente, é dicir, pode engadir máis procesadores, máis memoria RAM nun ordenador. VictoriaMetrics utilizará con éxito estes recursos dispoñibles e mellorará a produtividade lineal.
VictoriaMetrics tamén escala horizontalmente, é dicir, pode engadir nodos adicionais ao clúster VictoriaMetrics, e o seu rendemento aumentará de forma case lineal.
Como adiviñaches, VictoriaMetrics é unha base de datos rápida, porque non podo escribir outras. E está escrito en Go, así que falo diso nesta reunión.

Quen sabe o que é unha serie temporal? Tamén coñece a moita xente. Unha serie temporal é unha serie de pares (timestamp, значение), onde estes pares están ordenados por tempo. O valor é un número de coma flotante: float64.
Cada serie temporal é identificada de forma única mediante unha clave. En que consiste esta chave? Consiste nun conxunto non baleiro de pares clave-valor.
Aquí tes un exemplo dunha serie temporal. A clave desta serie é unha lista de pares: __name__="cpu_usage" é o nome da métrica, instance="my-server" - este é o ordenador no que se recolle esta métrica, datacenter="us-east" - Este é o centro de datos onde se atopa este ordenador.
Rematamos cun nome de serie temporal formado por tres pares clave-valor. Esta chave corresponde a unha lista de pares (timestamp, value). t1, t3, t3, ..., tN - son marcas de tempo, 10, 20, 12, ..., 15 - Os valores correspondentes. Este é o uso da CPU nun momento determinado para unha serie determinada.

Onde se poden usar series temporais? Alguén ten algunha idea?
- En DevOps, pode medir CPU, RAM, rede, rps, número de erros, etc.
- IoT: podemos medir temperatura, presión, coordenadas xeográficas e outra cousa.
- Tamén finanzas: podemos controlar os prezos de todo tipo de accións e moedas.
- Ademais, as series cronolóxicas pódense utilizar no seguimento dos procesos produtivos nas fábricas. Temos usuarios que usan VictoriaMetrics para monitorizar aeroxeradores, para robots.
- As series temporais tamén son útiles para recoller información dos sensores de varios dispositivos. Por exemplo, para un motor; para medir a presión dos pneumáticos; para medir velocidade, distancia; para medir o consumo de gasolina, etc.
- As series temporais tamén se poden usar para controlar aeronaves. Cada avión ten unha caixa negra que recolle series temporais de varios parámetros da saúde da aeronave. As series temporais tamén se utilizan na industria aeroespacial.
- A saúde é presión arterial, pulso, etc.
Pode haber máis aplicacións das que esquecín, pero espero que entendas que as series temporais úsanse activamente no mundo moderno. E o volume do seu uso crece cada ano.

Por que necesitas unha base de datos de series temporais? Por que non pode usar unha base de datos relacional normal para almacenar series temporais?
Porque as series temporais adoitan conter unha gran cantidade de información, que é difícil de almacenar e procesar nas bases de datos convencionais. Por iso, apareceron bases de datos especializadas para series temporais. Estas bases almacenan puntos de forma efectiva (timestamp, value) coa chave dada. Ofrecen unha API para ler os datos almacenados por chave, por un único par clave-valor ou por varios pares clave-valor ou por expresión regular. Por exemplo, quere atopar a carga da CPU de todos os seus servizos nun centro de datos en América, entón cómpre utilizar esta pseudo-consulta.
Normalmente as bases de datos de series temporais ofrecen linguaxes de consulta especializadas porque o SQL de series temporais non é moi axeitado. Aínda que hai bases de datos que admiten SQL, non é moi axeitado. Linguaxes de consulta como , , , . Espero que alguén escoitou polo menos un destes idiomas. Moita xente probablemente xa escoitou falar de PromQL. Esta é a linguaxe de consulta de Prometheus.
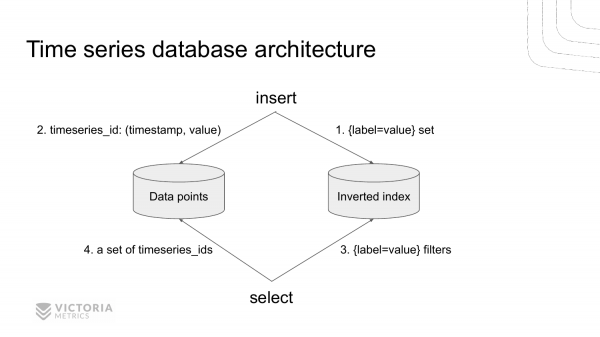
Así se ve unha arquitectura moderna de bases de datos de series temporais usando VictoriaMetrics como exemplo.
Consta de dúas partes. Trátase de almacenamento para o índice invertido e almacenamento de valores de series temporais. Estes repositorios están separados.
Cando chega un novo rexistro á base de datos, primeiro accedemos ao índice invertido para atopar o identificador da serie temporal dun conxunto determinado. label=value para unha métrica dada. Atopamos este identificador e gardamos o valor no almacén de datos.
Cando chega unha solicitude para recuperar datos de TSDB, primeiro imos ao índice invertido. Consigamos todo timeseries_ids rexistros que coinciden con este conxunto label=value. E despois obtemos todos os datos necesarios do almacén de datos, indexados por timeseries_ids.

Vexamos un exemplo de como unha base de datos de series temporais procesa unha consulta de selección entrante.
- En primeiro lugar, ela recibe todo
timeseries_idsa partir dun índice invertido que conteñen os pares dadoslabel=value, ou satisfacer unha expresión regular dada. - A continuación, recupera todos os puntos de datos do almacenamento de datos nun intervalo de tempo determinado para os atopados
timeseries_ids. - Despois diso, a base de datos realiza algúns cálculos sobre estes puntos de datos, segundo a solicitude do usuario. E despois diso devolve a resposta.
Nesta presentación falareivos da primeira parte. Esta é unha busca timeseries_ids por índice invertido. Podes ver a segunda parte e a terceira máis tarde , ou agarde ata que prepare outros informes :)

Pasemos ao índice invertido. Moitos poden pensar que isto é sinxelo. Quen sabe o que é un índice invertido e como funciona? Ah, xa non hai tanta xente. Intentemos entender o que é.
En realidade é sinxelo. É simplemente un dicionario que asigna unha clave a un valor. Que é unha chave? Esta parella label=valueonde label и value - Son liñas. E os valores son un conxunto timeseries_ids, que inclúe o par indicado label=value.
O índice invertido permítelle atopar todo rapidamente timeseries_ids, que deron label=value.
Tamén che permite atopar rapidamente timeseries_ids series temporais para varios pares label=value, ou para parellas label=regexp. Como ocorre isto? Ao atopar a intersección do conxunto timeseries_ids para cada parella label=value.

Vexamos varias implementacións do índice invertido. Comecemos coa implementación máis sinxela e inxenua. Ela parece así.
Función getMetricIDs obtén unha lista de cadeas. Cada liña contén label=value. Esta función devolve unha lista metricIDs.
Cómo funciona? Aquí temos unha variable global chamada invertedIndex. Este é un dicionario normal (map), que mapeará a cadea para cortar int. A liña contén label=value.
Implementación da función: get metricIDs para o primeiro label=value, despois pasamos por todo o demais label=value, conseguimos metricIDs para eles. E chamar á función intersectInts, que se comentará a continuación. E esta función devolve a intersección destas listas.

Como podes ver, implementar un índice invertido non é moi complicado. Pero esta é unha implementación inxenua. Que inconvenientes ten? A principal desvantaxe da implementación inxenua é que ese índice invertido se almacena na RAM. Despois de reiniciar a aplicación perdemos este índice. Non se gardou este índice no disco. É improbable que un índice invertido deste tipo sexa adecuado para unha base de datos.
O segundo inconveniente tamén está relacionado coa memoria. O índice invertido debe caber na memoria RAM. Se supera o tamaño da memoria RAM, obviamente conseguiremos un erro de memoria. E o programa non funcionará.

Este problema pódese resolver utilizando solucións xa preparadas como Ou .
En definitiva, necesitamos unha base de datos que nos permita facer tres operacións rapidamente.
- A primeira operación é a gravación
ключ-значениеa esta base de datos. Ela fai isto moi rapidamente, ondeключ-значениеson cadeas arbitrarias. - A segunda operación é unha busca rápida dun valor usando unha clave determinada.
- E a terceira operación é unha busca rápida de todos os valores por un prefixo dado.
LevelDB e RocksDB: estas bases de datos foron desenvolvidas por Google e Facebook. Primeiro chegou LevelDB. Entón os rapaces de Facebook tomaron LevelDB e comezaron a melloralo, fixeron RocksDB. Agora case todas as bases de datos internas funcionan en RocksDB dentro de Facebook, incluídas as que foron transferidas a RocksDB e MySQL. Puxéronlle o nome .
Pódese implementar un índice invertido usando LevelDB. Como facelo? Gardamos como chave label=value. E o valor é o identificador da serie temporal onde está presente o par label=value.
Se temos moitas series temporais cun par determinado label=value, entón haberá moitas filas nesta base de datos coa mesma clave e diferente timeseries_ids. Para obter unha lista de todos timeseries_ids, que comezan con isto label=prefix, facemos un escaneo de rango para o que esta base de datos está optimizada. É dicir, seleccionamos todas as liñas que comezan por label=prefix e conseguir o necesario timeseries_ids.

Aquí tes unha implementación de mostra de como sería en Go. Temos un índice invertido. Este é LevelDB.
A función é a mesma que para a implementación inxenua. Repite a implementación inxenua case liña por liña. O único punto é que en vez de recorrer map accedemos ao índice invertido. Recibimos todos os valores para o primeiro label=value. Despois pasamos por todos os pares restantes label=value e obtén os correspondentes conxuntos de metricIDs para eles. Despois atopamos a intersección.
Todo parece estar ben, pero esta solución ten inconvenientes. VictoriaMetrics implementou inicialmente un índice invertido baseado en LevelDB. Pero ao final tiven que renunciar.
Por que? Porque LevelDB é máis lento que a implementación inxenua. Nunha implementación inxenua, dada unha clave determinada, recuperamos inmediatamente a porción completa metricIDs. Esta é unha operación moi rápida: toda a porción está lista para o seu uso.
En LevelDB, cada vez que se chama unha función GetValues cómpre pasar por todas as liñas que comezan label=value. E obtén o valor de cada liña timeseries_ids. De tal timeseries_ids recolle unha porción destes timeseries_ids. Obviamente, isto é moito máis lento que simplemente acceder a un mapa normal por tecla.
O segundo inconveniente é que LevelDB está escrito en C. Chamar funcións C desde Go non é moi rápido. Leva centos de nanosegundos. Isto non é moi rápido, porque en comparación cunha chamada de función normal escrita en go, que leva entre 1 e 5 nanosegundos, a diferenza de rendemento é de decenas de veces. Para VictoriaMetrics este foi un fallo fatal :)

Entón escribín a miña propia implementación do índice invertido. E chamouna .
Mergeset baséase na estrutura de datos MergeTree. Esta estrutura de datos está tomada de ClickHouse. Obviamente, mergeset debería optimizarse para a busca rápida timeseries_ids segundo a clave dada. Mergeset está escrito enteiramente en Go. Podes ver . A implementación de mergeset está no cartafol . Podes tentar descubrir o que está pasando alí.
A API mergeset é moi semellante a LevelDB e RocksDB. É dicir, permítelle gardar alí novos rexistros rapidamente e seleccionar rapidamente rexistros por un prefixo determinado.

Máis adiante falaremos das desvantaxes de mergeset. Agora imos falar de que problemas xurdiron con VictoriaMetrics na produción ao implementar un índice invertido.
Por que xurdiron?
A primeira razón é a alta taxa de abandono. Traducido ao ruso, este é un cambio frecuente na serie temporal. Isto é cando remata unha serie temporal e comeza unha nova, ou comezan moitas series temporais novas. E isto ocorre a miúdo.
A segunda razón é a gran cantidade de series temporais. Ao principio, cando o seguimento gañaba popularidade, o número de series temporais era pequeno. Por exemplo, para cada ordenador cómpre supervisar a CPU, a memoria, a rede e a carga do disco. 4 series temporales por ordenador. Digamos que tes 100 ordenadores e 400 series temporais. Isto é moi pouco.
Co paso do tempo, a xente descubriu que podía medir información máis granular. Por exemplo, mida a carga non de todo o procesador, senón por separado de cada núcleo de procesador. Se tes 40 núcleos de procesador, tes 40 veces máis series de tempo para medir a carga do procesador.
Pero iso non é todo. Cada núcleo de procesador pode ter varios estados, como inactivo, cando está inactivo. E tamén traballar no espazo de usuario, traballar no espazo do núcleo e outros estados. E cada un destes estados tamén se pode medir como unha serie temporal separada. Isto tamén aumenta o número de filas en 7-8 veces.
A partir dunha métrica obtivemos 40 x 8 = 320 métricas para un só ordenador. Multiplicando por 100, obtemos 32 en lugar de 000.
Despois veu Kubernetes. E empeorou porque Kubernetes pode albergar moitos servizos diferentes. Cada servizo en Kubernetes consta de moitos pods. E todo isto hai que vixiar. Ademais, temos un despregue constante de novas versións dos teus servizos. Para cada nova versión, hai que crear novas series temporais. Como resultado, o número de series temporais crece exponencialmente e atopámonos ante o problema dunha gran cantidade de series temporais, que se denomina de alta cardinalidade. VictoriaMetrics afronta con éxito en comparación con outras bases de datos de series temporais.

Vexamos máis de cerca a alta taxa de abandono. Que causa unha alta taxa de abandono na produción? Porque algúns significados das etiquetas e etiquetas están cambiando constantemente.
Por exemplo, tome Kubernetes, que ten o concepto deployment, é dicir, cando se lanza unha nova versión da túa aplicación. Por algún motivo, os desenvolvedores de Kubernetes decidiron engadir o ID de implementación á etiqueta.
A que levou isto? Ademais, con cada nova implantación, interrompen todas as series de tempo antigas e, no canto delas, comezan as novas series de tempo cun novo valor de etiqueta deployment_id. Pode haber centos de miles e mesmo millóns de filas deste tipo.
O importante de todo isto é que o número total de series temporais crece, pero o número de series temporais que están actualmente activas e que reciben datos permanece constante. Este estado chámase taxa de abandono alta.
O principal problema da alta taxa de abandono é garantir unha velocidade de busca constante para todas as series de tempo para un determinado conxunto de etiquetas durante un determinado intervalo de tempo. Normalmente este é o intervalo de tempo para a última hora ou o último día.
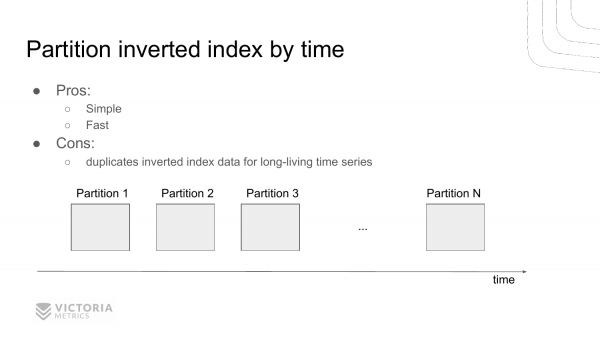
Como resolver este problema? Aquí está a primeira opción. Trátase de dividir o índice invertido en partes independentes ao longo do tempo. É dicir, que pasa algún intervalo de tempo, rematamos de traballar co índice invertido actual. E crea un novo índice invertido. Pasa outro intervalo de tempo, creamos outro e outro.
E ao facer a mostra a partir destes índices invertidos, atopamos un conxunto de índices invertidos que se atopan dentro do intervalo dado. E, en consecuencia, seleccionamos a identificación da serie temporal a partir de aí.
Isto aforra recursos porque non temos que mirar as pezas que non están dentro do intervalo indicado. É dicir, normalmente, se seleccionamos datos da última hora, para intervalos de tempo anteriores omitimos solicitudes.

Hai outra opción para resolver este problema. Isto é para almacenar para cada día unha lista separada de ID de series de tempo que ocorreron ese día.
A vantaxe desta solución sobre a solución anterior é que non duplicamos información de series temporais que non desaparece co paso do tempo. Están constantemente presentes e non cambian.
A desvantaxe é que tal solución é máis difícil de implementar e máis difícil de depurar. E VictoriaMetrics escolleu esta solución. Así aconteceu historicamente. Esta solución tamén funciona ben en comparación coa anterior. Porque esta solución non se implementou debido a que é necesario duplicar datos en cada partición para series temporais que non cambian, é dicir, que non desaparecen co paso do tempo. VictoriaMetrics optimizouse principalmente para o consumo de espazo en disco, e a implementación anterior empeorou o consumo de espazo en disco. Pero esta implementación é máis axeitada para minimizar o consumo de espazo en disco, polo que se escolleu.
Tiven que loitar contra ela. A loita foi que nesta implementación aínda cómpre escoller un número moito maior timeseries_ids para os datos que cando o índice invertido está particionado por tempo.

Como resolvemos este problema? Resolvemos-o dun xeito orixinal: almacenando varios identificadores de series temporais en cada entrada de índice invertido en lugar dun identificador. É dicir, temos unha chave label=value, que ocorre en todas as series temporais. E agora gardamos varios timeseries_ids nunha entrada.
Aquí tes un exemplo. Antes tiñamos N entradas, pero agora temos unha entrada cuxo prefixo é o mesmo que todos os demais. Para a entrada anterior, o valor contén todos os ID de series temporais.
Isto permitiu aumentar a velocidade de dixitalización dese índice invertido ata 10 veces. E permitiunos reducir o consumo de memoria para a caché, porque agora almacenamos a cadea label=value só unha vez na caché xuntos N veces. E esta liña pode ser grande se almacenas liñas longas nas túas etiquetas e etiquetas, que a Kubernetes lle gusta meter alí.
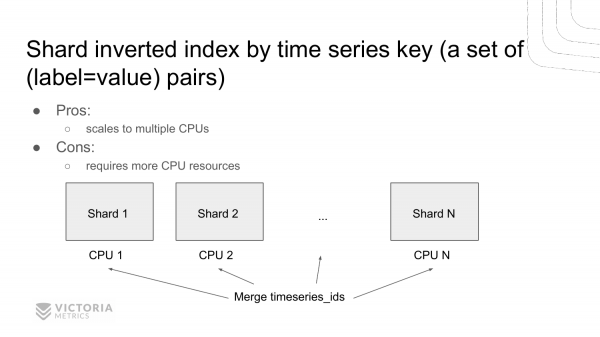
Outra opción para acelerar a busca nun índice invertido é a fragmentación. Creando varios índices invertidos en lugar dun e repartindo datos entre eles por clave. Este é un conxunto key=value vapor. É dicir, obtemos varios índices invertidos independentes, que podemos consultar en paralelo en varios procesadores. As implementacións anteriores só permitían o funcionamento en modo dun só procesador, é dicir, escanear datos nun só núcleo. Esta solución permítelle escanear datos en varios núcleos á vez, como lle gusta facer a ClickHouse. Isto é o que pensamos poñer en práctica.

Agora volvamos ás nosas ovellas - á función de intersección timeseries_ids. Consideremos que implementacións pode haber. Esta función permítelle atopar timeseries_ids para un conxunto dado label=value.

A primeira opción é unha implementación inxenua. Dous bucles aniñados. Aquí temos a entrada da función intersectInts dúas porcións - a и b. Na saída, debería devolvernos a intersección destas porcións.
Unha implementación inxenua ten este aspecto. Iteramos sobre todos os valores de slice a, dentro deste bucle pasamos por todos os valores de slice b. E comparámolos. Se coinciden, entón atopamos unha intersección. E gárdao result.

Cales son as desvantaxes? A complexidade cuadrática é o seu principal inconveniente. Por exemplo, se as súas dimensións son porción a и b un millón á vez, entón esta función nunca che devolverá unha resposta. Porque terá que facer un billón de iteracións, o que é moito incluso para os ordenadores modernos.

A segunda implementación baséase no mapa. Creamos mapa. Poñemos todos os valores de slice neste mapa a. Despois pasamos por porción nun bucle separado b. E comprobamos se este valor é de slice b no mapa. Se existe, engádeo ao resultado.

Cales son os beneficios? A vantaxe é que só hai complexidade lineal. É dicir, a función executarase moito máis rápido para porcións máis grandes. Para unha porción de un millón de tamaños, esta función executarase en 2 millóns de iteracións, ao contrario dos billóns de iteracións da función anterior.
A desvantaxe é que esta función require máis memoria para crear este mapa.
O segundo inconveniente é a gran sobrecarga para o hash. Este inconveniente non é moi evidente. E para nós tampouco era moi obvio, polo que nun principio en VictoriaMetrics a implementación da intersección era a través dun mapa. Pero despois a elaboración de perfiles mostrou que o tempo do procesador principal se gasta escribindo no mapa e comprobando a presenza dun valor neste mapa.
Por que se perde o tempo da CPU nestes lugares? Porque Go realiza unha operación hash nestas liñas. É dicir, calcula o hash da clave para despois acceder a ela nun índice determinado no HashMap. A operación de cálculo de hash complétase en decenas de nanosegundos. Isto é lento para VictoriaMetrics.

Decidín implementar un conxunto de bits optimizado especificamente para este caso. Así se ve agora a intersección de dúas franxas. Aquí creamos un bitset. Engadímoslle elementos desde a primeira porción. Despois comprobamos a presenza destes elementos na segunda porción. E engádeos ao resultado. É dicir, case non é diferente do exemplo anterior. O único aquí é que substituímos o acceso ao mapa por funcións personalizadas add и has.

A primeira vista, parece que isto debería funcionar máis lento, se antes se usaba alí un mapa estándar, e logo se chaman outras funcións, pero o perfil mostra que isto funciona 10 veces máis rápido que o mapa estándar no caso de VictoriaMetrics.
Ademais, usa moita menos memoria en comparación coa implementación do mapa. Porque estamos almacenando bits aquí en lugar de valores de oito bytes.
A desvantaxe desta implementación é que non é tan obvia, nin trivial.
Outro inconveniente que moitos poden non notar é que esta implementación pode non funcionar ben nalgúns casos. É dicir, está optimizado para un caso concreto, para este caso de intersección de identificadores de series temporais de VictoriaMetrics. Isto non significa que sexa adecuado para todos os casos. Se se usa incorrectamente, non obteremos un aumento de rendemento, senón un erro de memoria sen memoria e unha diminución do rendemento.

Consideremos a implementación desta estrutura. Se queres buscar, atópase nas fontes de VictoriaMetrics, no cartafol . Está optimizado especificamente para o caso VictoriaMetrics, onde timeseries_id é un valor de 64 bits, onde os primeiros 32 bits son basicamente constantes e só cambian os últimos 32 bits.
Esta estrutura de datos non se almacena no disco, só funciona na memoria.

Aquí está a súa API. Non é moi complicado. A API está adaptada específicamente a un exemplo específico de uso de VictoriaMetrics. É dicir, aquí non hai funcións innecesarias. Aquí están as funcións que son utilizadas explícitamente por VictoriaMetrics.
Hai funcións add, que engade novos valores. Hai unha función has, que busca novos valores. E hai unha función del, que elimina valores. Hai unha función auxiliar len, que devolve o tamaño do conxunto. Función clone clona moito. E función appendto converte este conxunto en slice timeseries_ids.

Así se ve a implementación desta estrutura de datos. O conxunto ten dous elementos:
ItemsCounté un campo auxiliar para devolver rapidamente o número de elementos dun conxunto. Sería posible prescindir deste campo auxiliar, pero tivo que engadirse aquí porque VictoriaMetrics adoita consultar a lonxitude do conxunto de bits nos seus algoritmos.O segundo campo é
buckets. Esta é unha porción da estruturabucket32. Cada estrutura almacenahicampo. Estes son os 32 bits superiores. E dúas porcións -b16hisиbucketsdebucket16estruturas.
Aquí gárdanse os 16 bits superiores da segunda parte da estrutura de 64 bits. E aquí almacénanse conxuntos de bits para os 16 bits inferiores de cada byte.
Bucket64 consiste nunha matriz uint64. A lonxitude calcúlase usando estas constantes. Nunha bucket16 máximo pódese almacenar 2^16=65536 pouco. Se o divides por 8, son 8 kilobytes. Se volves dividir por 8, é 1000 uint64 significado. É dicir Bucket16 – esta é a nosa estrutura de 8 kilobytes.

Vexamos como se implementa un dos métodos desta estrutura para engadir un novo valor.
Todo comeza con uint64 significados. Calculamos os 32 bits superiores, calculamos os 32 bits inferiores. Imos pasar por todo buckets. Comparamos os 32 bits principais de cada balde co valor engadido. E se coinciden, chamamos á función add na estrutura b32 buckets. E engade alí os 32 bits inferiores. E se volveu true, entón isto significa que alí engadimos tal valor e non tiñamos tal valor. Se volve false, entón tal significado xa existía. Despois aumentamos o número de elementos na estrutura.
Se non atopamos o que necesitas bucket co alto valor necesario, entón chamamos á función addAlloc, que producirá un novo bucket, engadíndoo á estrutura do cubo.

Esta é a implementación da función b32.add. É similar á implementación anterior. Calculamos os 16 bits máis significativos, os 16 bits menos significativos.
Despois pasamos por todos os 16 bits superiores. Atopamos coincidencias. E se hai unha coincidencia, chamamos ao método add, que consideraremos na páxina seguinte bucket16.

E aquí está o nivel máis baixo, que debería optimizarse na medida do posible. Calculamos para uint64 valor de id en slice bit e tamén bitmask. Esta é unha máscara para un determinado valor de 64 bits, que se pode usar para comprobar a presenza deste bit ou configuralo. Comprobamos se este bit está configurado e configuralo, e devolvemos presenza. Esta é a nosa implementación, que nos permitiu acelerar 10 veces a operación de intersección de identificadores de series temporais en comparación cos mapas convencionais.

Ademais desta optimización, VictoriaMetrics ten moitas outras optimizacións. A maioría destas optimizacións engadíronse por algún motivo, pero despois de perfilar o código en produción.
Esta é a principal regra de optimización: non engada optimización asumindo que haberá un pescozo de botella aquí, porque pode resultar que non o haxa alí. A optimización adoita degradar a calidade do código. Polo tanto, paga a pena optimizar só despois do perfil e preferiblemente na produción, para que estes sexan datos reais. Se alguén está interesado, pode mirar o código fonte de VictoriaMetrics e explorar outras optimizacións que hai.

Teño unha pregunta sobre o bitset. Moi semellante á implementación bool vectorial C++, conxunto de bits optimizado. Tomaches a implantación dende alí?
Non, non desde alí. Ao implementar este conxunto de bits, guiábame polo coñecemento da estrutura destas series temporales de identificacións, que se usan en VictoriaMetrics. E a súa estrutura é tal que os 32 bits superiores son basicamente constantes. Os 32 bits inferiores están suxeitos a cambios. Canto máis baixo sexa o bit, máis veces pode cambiar. Polo tanto, esta implementación está optimizada especificamente para esta estrutura de datos. A implementación de C++, polo que eu sei, está optimizada para o caso xeral. Se optimiza para o caso xeral, isto significa que non será o máis óptimo para un caso específico.
Tamén che aconsello que vexas a reportaxe de Alexey Milovid. Hai aproximadamente un mes, falou sobre a optimización en ClickHouse para especializacións específicas. Só di que, no caso xeral, unha implementación de C++ ou algunha outra implementación está adaptada para funcionar ben de media nun hospital. Pode ter un rendemento peor que unha implementación específica de coñecemento como a nosa, onde sabemos que os 32 bits principais son na súa maioría constantes.
Teño unha segunda pregunta. Cal é a diferenza fundamental con InfluxDB?
Hai moitas diferenzas fundamentais. En termos de rendemento e consumo de memoria, InfluxDB nas probas mostra un consumo de memoria 10 veces maior para series de tempo de alta cardinalidade, cando tes moitas delas, por exemplo, millóns. Por exemplo, VictoriaMetrics consome 1 GB por millón de filas activas, mentres que InfluxDB consome 10 GB. E iso é unha gran diferenza.
A segunda diferenza fundamental é que InfluxDB ten linguaxes de consulta estrañas: Flux e InfluxQL. Non son moi cómodos para traballar con series temporais en comparación con , que é compatible con VictoriaMetrics. PromQL é unha linguaxe de consulta de Prometheus.
E unha diferenza máis é que InfluxDB ten un modelo de datos un pouco estraño, onde cada liña pode almacenar varios campos cun conxunto diferente de etiquetas. Estas liñas divídense ademais en varias táboas. Estas complicacións adicionais complican o traballo posterior con esta base de datos. É difícil de apoiar e comprender.
En VictoriaMetrics todo é moito máis sinxelo. Alí, cada serie temporal é un valor clave. O valor é un conxunto de puntos - (timestamp, value), e a clave é o conxunto label=value. Non hai separación entre campos e medidas. Permítelle seleccionar calquera dato e, a continuación, combinar, sumar, restar, multiplicar, dividir, a diferenza de InfluxDB, onde os cálculos entre diferentes filas aínda non están implementados polo que eu sei. Aínda que estean implementados, é difícil, hai que escribir moito código.
Teño unha pregunta aclaradora. Entendín ben que houbo algún tipo de problema do que falaches, que este índice invertido non cabe na memoria, polo que hai partición alí?
En primeiro lugar, mostrei unha implementación inxenua dun índice invertido nun mapa Go estándar. Esta implementación non é adecuada para bases de datos porque este índice invertido non se garda no disco, e a base de datos debe gardar no disco para que estes datos permanezan dispoñibles ao reiniciar. Nesta implementación, cando reinicie a aplicación, o seu índice invertido desaparecerá. E perderás o acceso a todos os datos porque non poderás atopalos.
Ola! Grazas polo informe! Chámome Pavel. Eu son de Wildberries. Teño algunhas preguntas para ti. Pregunta un. Pensas que se escolleu un principio diferente ao construír a arquitectura da súa aplicación e particionara os datos ao longo do tempo, quizais puidese cruzar os datos ao buscar, baseándose só no feito de que unha partición contén datos para unha período de tempo, é dicir, nun intervalo de tempo e non tería que preocuparse polo feito de que as súas pezas estean espalladas de forma diferente? Pregunta número 2: xa que está a implementar un algoritmo similar con bitset e todo o demais, quizais intentou usar instrucións do procesador? Quizais probaches este tipo de optimizacións?
Responderei ao segundo inmediatamente. Aínda non chegamos a ese punto. Pero se é necesario, chegaremos alí. E a primeira, cal era a pregunta?
Discutiches dous escenarios. E dixeron que escolleron a segunda cunha implantación máis complexa. E non preferiron o primeiro, onde os datos están divididos por tempo.
Si. No primeiro caso, o volume total do índice sería maior, porque en cada partición teríamos que almacenar datos duplicados para aquelas series temporais que continúan por todas estas particións. E se a súa taxa de abandono de series temporais é pequena, é dicir, as mesmas series úsanse constantemente, entón no primeiro caso perderiamos moito máis na cantidade de espazo en disco ocupado en comparación co segundo caso.
E así, si, a partición horaria é unha boa opción. Prometeo utilízao. Pero Prometeo ten outro inconveniente. Ao fusionar estes datos, debe manter na memoria a metainformación de todas as etiquetas e series temporales. Polo tanto, se os datos que fusiona son grandes, o consumo de memoria aumenta moito durante a fusión, a diferenza de VictoriaMetrics. Cando se fusiona, VictoriaMetrics non consume memoria en absoluto; só consomen un par de kilobytes, independentemente do tamaño dos datos combinados.
O algoritmo que está a usar usa memoria. Marca etiquetas de series temporales que conteñen valores. E deste xeito comproba a presenza emparellada nunha matriz de datos e noutra. E entendes se a intersección ocorreu ou non. Normalmente, as bases de datos implementan cursores e iteradores que almacenan o seu contido actual e percorren os datos ordenados debido á simple complexidade destas operacións.
Por que non usamos os cursores para percorrer os datos?
Si
Almacenamos filas ordenadas en LevelDB ou mergeset. Podemos mover o cursor e atopar a intersección. Por que non o usamos? Porque é lento. Porque os cursores significan que cómpre chamar a unha función para cada liña. Unha chamada de función é de 5 nanosegundos. E se tes 100 de liñas, entón resulta que pasamos medio segundo só chamando á función.
Hai tal cousa, si. E a miña última pregunta. A pregunta pode soar un pouco estraña. Por que non é posible ler todos os agregados necesarios no momento en que chegan os datos e gardalos na forma requirida? Por que gardar volumes enormes nalgúns sistemas como VictoriaMetrics, ClickHouse, etc., e despois dedicarlles moito tempo?
Vou poñer un exemplo para que quede máis claro. Digamos como funciona un pequeno velocímetro de xoguete? Rexistra a distancia que percorreu, engadíndoa todo o tempo a un valor e o segundo tempo. E divide. E obtén velocidade media. Podes facer o mesmo. Suma todos os feitos necesarios sobre a marcha.
Vale, entendo a pregunta. O teu exemplo ten o seu lugar. Se sabes que agregados necesitas, esta é a mellor implementación. Pero o problema é que a xente garda estas métricas, algúns datos en ClickHouse e aínda non saben como os van agregar e filtrar no futuro, polo que teñen que gardar todos os datos en bruto. Pero se sabes que necesitas calcular algo en media, entón por que non o calculas en lugar de almacenar alí un montón de valores brutos? Pero isto só se sabe exactamente o que precisa.
Por certo, as bases de datos para almacenar series temporais admiten o reconto de agregados. Por exemplo, Prometheus apoia . É dicir, pódese facer se sabe que unidades necesitará. VictoriaMetrics aínda non ten isto, pero adoita ir precedido de Prometheus, no que se pode facer nas regras de codificación.
Por exemplo, no meu traballo anterior necesitaba contar o número de eventos nunha xanela deslizante durante a última hora. O problema é que tiven que facer unha implementación personalizada en Go, é dicir, un servizo para contar esta cousa. Este servizo foi finalmente non trivial, porque é difícil de calcular. A implementación pode ser sinxela se precisa contar algúns agregados a intervalos de tempo fixos. Se queres contar eventos nunha xanela deslizante, non é tan sinxelo como parece. Creo que isto aínda non se implementou en ClickHouse nin en bases de datos de series temporais, porque é difícil de implementar.
E unha pregunta máis. Só estabamos a falar de promediar, e lembrei que había unha vez algo como o grafito cun backend de carbono. E soubo diminuír os datos antigos, é dicir, deixar un punto por minuto, un punto por hora, etc. En principio, isto é bastante conveniente se necesitamos datos brutos, relativamente falando, durante un mes, e todo o demais pode ser diluido. Pero Prometheus e VictoriaMetrics non admiten esta funcionalidade. Está previsto apoialo? Se non, por que non?
Grazas pola pregunta. Os nosos usuarios fan esta pregunta periodicamente. Preguntan cando engadiremos soporte para a redución de mostras. Aquí hai varios problemas. En primeiro lugar, todos os usuarios entenden downsampling algo diferente: alguén quere obter calquera punto arbitrario nun intervalo determinado, alguén quere valores máximos, mínimos e medios. Se moitos sistemas escriben datos na súa base de datos, entón non pode agrupalos todos. Pode ser que cada sistema requira un aclareo diferente. E isto é difícil de implementar.
E o segundo é que VictoriaMetrics, como ClickHouse, está optimizado para traballar con grandes volumes de datos en bruto, polo que pode sacar mil millóns de liñas en menos dun segundo se tes moitos núcleos no teu sistema. Escaneando puntos de series temporales en VictoriaMetrics: 50 de puntos por segundo por núcleo. E este rendemento escala aos núcleos existentes. É dicir, se tes 000 núcleos, por exemplo, escanearás mil millóns de puntos por segundo. E esta propiedade de VictoriaMetrics e ClickHouse reduce a necesidade de reducir a mostra.
Outra característica é que VictoriaMetrics comprime estes datos de forma efectiva. A compresión media na produción é de 0,4 a 0,8 bytes por punto. Cada punto é unha marca de tempo + valor. E está comprimido en menos dun byte de media.
Sergey. Teño unha pregunta. Cal é o quantum de tempo mínimo de gravación?
Un milisegundo. Hai pouco tivemos unha conversa con outros desenvolvedores de bases de datos de series temporais. O seu intervalo de tempo mínimo é dun segundo. E en Graphite, por exemplo, tamén é un segundo. En OpenTSDB tamén é dun segundo. InfluxDB ten precisión de nanosegundos. En VictoriaMetrics é un milisegundo, porque en Prometheus é un milisegundo. E VictoriaMetrics desenvolveuse orixinalmente como almacenamento remoto para Prometheus. Pero agora pode gardar datos doutros sistemas.
A persoa coa que falei di que ten precisión segundo a segundo; iso é suficiente para eles porque depende do tipo de datos que se almacenan na base de datos de series temporais. Se se trata de datos de DevOps ou da infraestrutura, onde os recolles a intervalos de 30 segundos por minuto, entón a precisión de segundo é suficiente, non necesitas nada menos. E se recompilas estes datos de sistemas de negociación de alta frecuencia, necesitas precisión de nanosegundos.
A precisión de milisegundos en VictoriaMetrics tamén é adecuada para o caso de DevOps e pode ser adecuada para a maioría dos casos que mencionei ao comezo do informe. O único para o que pode non ser axeitado son os sistemas de negociación de alta frecuencia.
Grazas! E outra pregunta. Que é a compatibilidade en PromQL?
Compatibilidade total con versións anteriores. VictoriaMetrics admite totalmente PromQL. Ademais, engade unha funcionalidade avanzada adicional en PromQL, que se chama . Hai unha charla en YouTube sobre esta funcionalidade estendida. Falei na reunión de seguimento na primavera en San Petersburgo.
Canle de telegrama .
Só os usuarios rexistrados poden participar na enquisa. , por favor.
Que é o que che impide cambiar a VictoriaMetrics como almacenamento a longo prazo para Prometheus? (Escribe nos comentarios, engadireino á enquisa))
71,4%Non uso Prometheus5
28,6%Non sabía sobre VictoriaMetrics2
Votaron 7 usuarios. 12 usuarios abstivéronse.
Fonte: www.habr.com
