

Exploraremos o funcionamento de Zabbix cunha base de datos TimescaleDB como backend. Mostrarémosche como poñelo en funcionamento desde cero e como migrar desde PostgreSQL. Tamén proporcionaremos probas de rendemento comparativas das dúas configuracións.

HighLoad++ Siberia 2019. Pavillón de Tomsk. 24 de xuño, 16:00. Resumos e A próxima conferencia HighLoad++ celebrarase os días 6 e 7 de abril de 2020 en San Petersburgo. Xa hai máis información e entradas dispoñibles. .
Andrey Gushchin (en diante - AG): Son enxeñeiro/a de soporte técnico e formador/a en ZABBIX (en diante, "Zabbix"). Levo máis de seis anos traballando en soporte técnico e teño experiencia de primeira man co rendemento. Hoxe, vou falar das vantaxes de rendemento de TimescaleDB en comparación co PostgreSQL 10 estándar. Tamén darei unha breve introdución a como funciona.
Desafíos clave de rendemento: desde a recollida de datos ata a limpeza de datos
Comecemos co feito de que todo sistema de monitorización enfróntase a certos desafíos de rendemento. O primeiro desafío de rendemento é a rápida recollida e procesamento de datos.

Un bo sistema de monitorización debería recibir todos os datos de forma rápida e puntual, procesalos segundo as expresións de activación, é dicir, procesalos segundo certos criterios (isto varía dun sistema a outro) e gardalos nunha base de datos para uso futuro.

O segundo desafío de rendemento é o almacenamento de datos históricos. Estes datos, a miúdo almacenados nunha base de datos, deben ser accesibles de forma rápida e sinxela despois de seren recollidos durante un período de tempo. O máis importante é que estes datos deben ser facilmente accesibles e utilizarse en informes, gráficos, activadores, limiares, alertas, etc.

O terceiro desafío de rendemento é a limpeza do historial, é dicir, cando chegas a un punto no que xa non necesitas almacenar métricas detalladas recollidas durante cinco anos (ou mesmo só uns meses ou dous). Algúns nodos de rede foron eliminados ou algúns hosts xa non son necesarios porque as métricas están desactualizadas e xa non se recollen. Todo isto debe limparse para evitar que a base de datos medre demasiado. En xeral, a limpeza do historial adoita ser un desafío importante para o almacenamento, que a miúdo afecta significativamente o rendemento.
Como resolver os problemas de caché?
Agora falarei especificamente sobre Zabbix. En Zabbix, a primeira e a segunda chamada resólvense mediante o almacenamento en caché.

Recompilación e procesamento de datos: empregamos a memoria RAM para almacenar todos estes datos. Falaremos destes datos con máis detalle en breve.
Tamén hai algo de almacenamento en caché no lado da base de datos para as seleccións principais, para gráficos e outras cousas.
Caché no servidor de Zabbix: temos ConfigurationCache, ValueCache, HistoryCache e TrendsCache. Que son?

ConfigurationCache é a caché principal onde almacenamos métricas, hosts, elementos de datos, disparadores (todo o necesario para o preprocesamento, a recollida de datos, os hosts dos que recoller datos e a frecuencia). Todo isto almacénase en ConfigurationCache para evitar o acceso á base de datos e as consultas innecesarias. Despois de que se inicie o servidor, actualizamos (creamos) esta caché e actualizámola periodicamente (dependendo dos axustes de configuración).
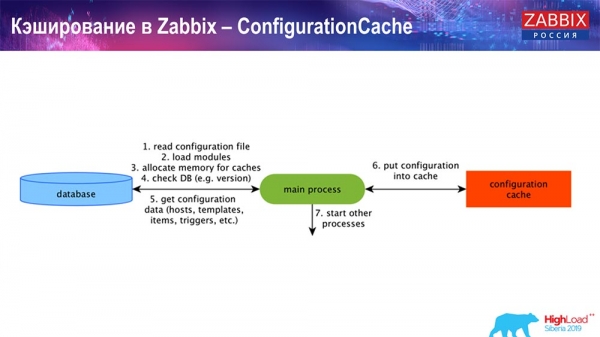
Caché en Zabbix. Recollida de datos
Aquí tes un diagrama bastante grande:
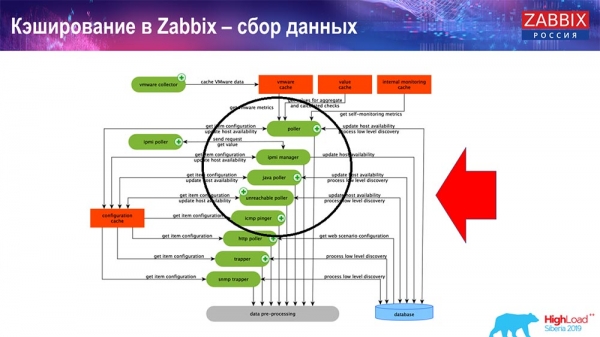
Os principais do esquema son estes ensambladores:
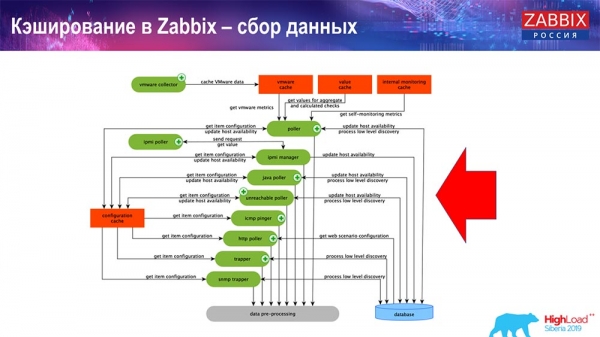
Estes son os propios procesos de compilación, varios "enquisadores" responsables de diferentes tipos de compilacións. Recollen datos a través de ICMP, IPMI e varios protocolos e pásaos todos ao preprocesamento.
Caché do historial de preprocesamento
Ademais, se temos elementos de datos calculados (quen estea familiarizado con Zabbix sabe isto), é dicir, elementos de datos de agregación calculados, recuperámolos directamente da ValueCache. Explicarei como se enche máis adiante. Todos estes colectores usan a ConfigurationCache para recibir as súas tarefas e despois pasalas para o seu preprocesamento.
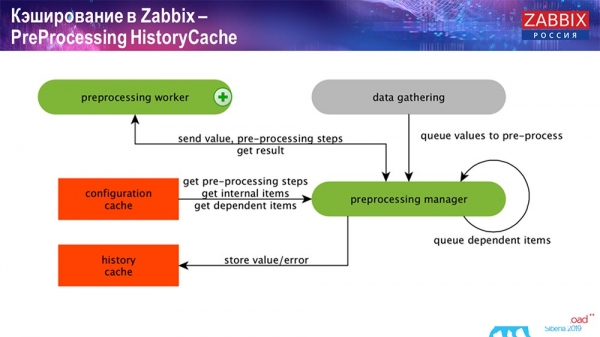
O preprocesamento tamén usa ConfigurationCache para recuperar os pasos de preprocesamento e procesa estes datos de varias maneiras. A partir da versión 4.2, trasladamos isto a un proxy. Isto é moi cómodo, xa que o preprocesamento en si é unha operación bastante pesada. E se tes un sistema Zabbix moi grande, cun gran número de elementos de datos e unha alta frecuencia de recollida, isto simplifica moito o traballo.
En consecuencia, despois de procesar estes datos mediante preprocesamento, gardámolos en HistoryCache para o seu posterior procesamento. Isto completa a recollida de datos. Pasamos ao proceso principal.
Traballo de sincronización do historial
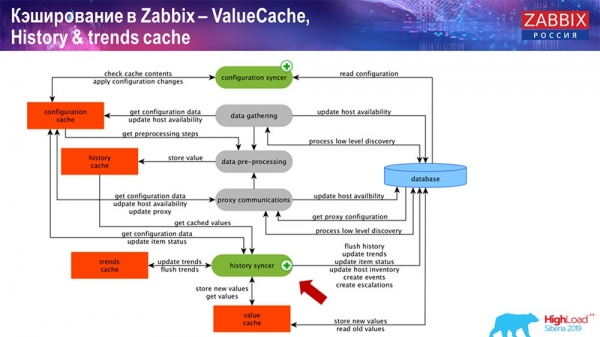
O proceso principal en Zabbix (xa que é unha arquitectura monolítica) é o sincronizador do historial. Este é o proceso principal que xestiona o procesamento atómico de cada elemento de datos, é dicir, cada valor:
- chega o valor (tómao de HistoryCache);
- comprobacións en Configuration syncer: hai algún desencadeante para o cálculo? calcúlaos;
se houber algún, crea eventos, crea unha escalación para crear unha alerta, se a configuración o require; - rexistra os desencadeantes para o seu procesamento posterior, agregación; se se agrega a última hora e así sucesivamente, ValueCache lembra este valor para non acceder á táboa do historial; así, ValueCache énchese cos datos necesarios para calcular os desencadeantes, os elementos calculados, etc.;
- entón, o sincronizador de historial escribe todos os datos na base de datos;
- A base de datos escríbeos no disco; aquí é onde remata o procesamento.
Bases de datos. Almacenamento en caché
No lado da base de datos, cando queres ver gráficos ou informes de eventos, hai varias cachés. Pero non as abordarei nesta charla.
Para MySQL, existe Innodb_buffer_pool e un feixe doutras cachés diferentes que tamén se poden configurar.
Pero estes son os principais:
- búferes_compartidos;
- tamaño_efectivo_da_caché;
- grupo_compartido.

Para todas as bases de datos, mostrei que existen certas cachés que lles permiten almacenar datos necesarios con frecuencia na RAM para consultas. Teñen as súas propias tecnoloxías para iso.
Acerca do rendemento da base de datos
En consecuencia, existe un ambiente simultáneo, o que significa que o servidor Zabbix recompila e rexistra datos. Cando se reinicia, tamén le do historial para poboar ValueCache, etc. Tamén podes ter scripts e informes que usen a API de Zabbix, que está construída sobre unha interface web. A API de Zabbix accede á base de datos e recupera os datos necesarios para xerar gráficos, informes ou unha lista de eventos ou problemas recentes.
Outra solución de visualización moi popular é Grafana, que empregan os nosos usuarios. Pode acceder aos datos directamente a través tanto da API de Zabbix como da base de datos. Tamén crea certa competencia pola recuperación de datos: requírese unha base de datos máis refinada e ben axustada para axustar a entrega rápida de resultados e probas.

Limpando o historial. Zabbix ten unha asistenta.
A terceira chamada empregada en Zabbix é a limpeza do historial mediante Housekeeper. Housekeeper respecta todos os axustes, o que significa que especificamos nos elementos de datos a duración do almacenamento (en días), a duración das tendencias e a dinámica dos cambios.
Non mencionei TrendCash, que calculamos sobre a marcha: chegan os datos, agregámolos durante unha hora (principalmente a última hora), calculamos os valores medios/mínimos e escribímolos cada hora na táboa Trends. Housekeeper executa e elimina datos da base de datos usando seleccións normais, o que non sempre é efectivo.
Como podes saber se isto é ineficaz? Podes ver esta imaxe nos gráficos de rendemento dos procesos internos:
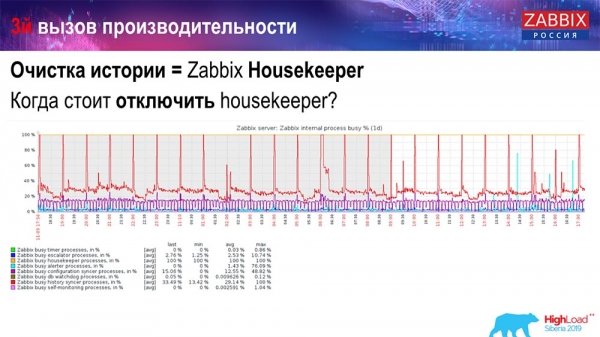
O teu sincronizador de historial está constantemente ocupado (gráfico vermello). E o gráfico "laranxa" que está enriba del é o xestor de recursos, que se inicia e agarda a que a base de datos elimine todas as filas que especificou.
Tomemos algúns ID de elemento: precisamos eliminar os últimos 5; por índice, por suposto. Pero o conxunto de datos adoita ser bastante grande: a base de datos aínda o le do disco e cárgao na caché, o que é unha operación moi custosa para a base de datos. Dependendo do seu tamaño, isto pode levar a certos problemas de rendemento.
Podes desactivar o mantemento interno facilmente: temos unha interface web familiar. Na Administración xeral (configuración do mantemento), desactivamos o mantemento interno para o historial e as tendencias internas. En consecuencia, o mantemento xa non xestiona estas funcións:

Que podo facer agora? Desactiváchelo, os teus gráficos niveláronse... Que outros problemas poderían xurdir neste caso? Que pode axudar?
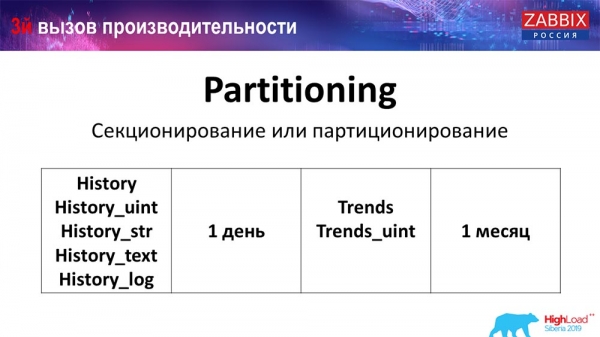
Partición (seccionamento)
Isto normalmente configúrase de forma diferente para cada base de datos relacional que listei. MySQL ten a súa propia tecnoloxía. Pero en xeral, son moi semellantes, especialmente no que respecta a PostgreSQL 10 e MySQL. Por suposto, hai moitas diferenzas internas en como se implementa todo e como todo isto afecta ao rendemento. Pero en xeral, crear unha nova partición adoita levar a certos problemas.

Dependendo da túa configuración (cantidade de datos que crees por día), o mínimo adoita establecerse en 1 día por partición, mentres que para as "tendencias" ou a dinámica de cambios, é 1 mes por nova partición. Isto pode cambiar se tes unha configuración moi grande.
Falemos agora mesmo dos tamaños das configuracións: ata 5000 novos valores por segundo (os chamados NVPS) considéranse unha configuración pequena. Unha configuración media oscila entre os 5000 e os 25 000 valores por segundo. Calquera valor superior a esa cifra considérase unha instalación grande ou moi grande, o que require unha configuración moi coidadosa da base de datos.
Para instalacións moi grandes, pode que 1 día non sexa o ideal. Persoalmente, vin particións MySQL consumir 40 gigabytes ao día (e ás veces máis). Este é un volume de datos moi grande que pode causar problemas. É necesario reducilo.
Por que é necesaria a partición?
Creo que todo o mundo sabe o que fai o particionamento: particionamento en táboas. A miúdo son ficheiros separados no disco e consultas de extensión. Selecciona de forma máis óptima unha partición se esta forma parte do particionamento normal.
Para Zabbix, en particular, usamos partición por rango, o que significa que usamos unha marca de tempo (un número normal, o tempo desde o comezo da época). Especificas o inicio/fin do día, e esta é a partición. Polo tanto, se accedes a datos de hai dous días, recupéranse da base de datos máis rápido porque só necesitas cargar un único ficheiro na caché e devolvelo (en lugar dunha táboa grande).

Moitas bases de datos tamén aceleran as insercións (inserción nunha única táboa filla). Estou a falar de xeito abstracto, pero isto tamén é posible. O particionamento adoita axudar.
Elasticsearch para NoSQL
Recentemente, na versión 3.4, implementamos unha solución NoSQL. Engadimos a capacidade de escribir en Elasticsearch. Podes escribir tipos específicos: escolle entre números ou símbolos; temos texto de cadea, podes escribir rexistros en Elasticsearch... En consecuencia, a interface web tamén accederá a Elasticsearch. Isto funciona moi ben nalgúns casos, pero por agora, é utilizable.

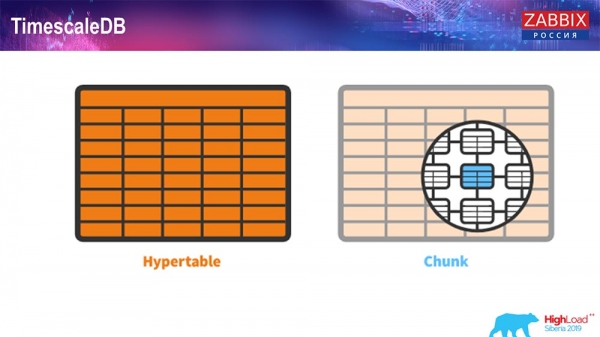
TimescaleDB. Hipertáboas
Para a versión 4.4.2, destacamos unha funcionalidade: TimescaleDB. Que é? É unha extensión de PostgreSQL, o que significa que ten unha interface nativa de PostgreSQL. Ademais, esta extensión permite un traballo moito máis eficiente con datos de series temporais e particionamento automático. Así é como se ve:

É unha hipertáboa (existe un concepto semellante en Escala de tempo). É unha hipertáboa que creas e contén fragmentos. Os fragmentos son particións, táboas fillas, se non me equivoco. É moi eficiente.
TimescaleDB e PostgreSQL
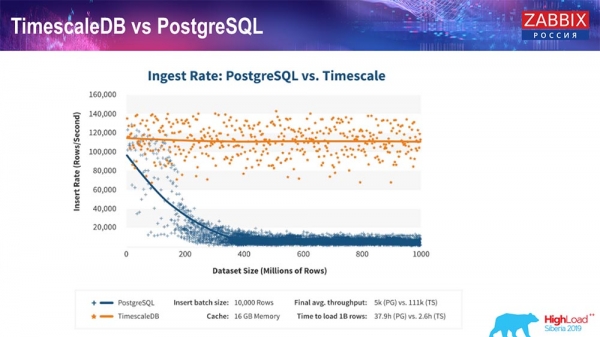
Segundo os provedores de TimescaleDB, empregan un algoritmo de procesamento de consultas máis eficiente, especialmente para as insercións, o que permite un rendemento aproximadamente constante a medida que aumenta o tamaño do conxunto de datos de inserción. É dicir, despois de 200 millóns de filas, o PostgreSQL estándar comeza a degradarse significativamente e, literalmente, degrada o rendemento a cero, mentres que TimescaleDB permite que as insercións se realicen da forma máis eficiente posible con calquera tamaño de datos.
Como instalar TimescaleDB? É doado!
Está na documentación, está descrito: podes instalalo desde paquetes para calquera... Depende dos paquetes oficiais de Postgres. Podes compilalo manualmente. Casualmente tiven que compilalo para a base de datos.
En Zabbix, simplemente activamos a Extensión. Creo que aqueles que usaron a Extensión en PostgreSQL... Simplemente activas a Extensión e créaa para a base de datos Zabbix que estás a usar.
E o último paso…
TimescaleDB: Migración de táboas de historial
Necesitas crear unha hipertáboa. Hai unha función especial para isto: Create hypertable. O seu primeiro parámetro especifica a táboa que necesitas nesta base de datos (aquela para a que queres crear unha hipertáboa).

O campo desde o que se vai crear e chunk_time_interval (este é o intervalo de fragmentos (particións) que se van usar). 86.400 é un día.
parámetro migrate_data: se o defines como verdadeiro, migra todos os datos actuais a fragmentos precreados.
Eu mesmo usei migrate_data; leva bastante tempo, dependendo do tamaño da base de datos. A miña ocupaba máis dun terabyte, polo que a creación tardou máis dunha hora. Nalgúns casos, durante as probas, eliminei os datos históricos de texto (history_text) e cadea (history_str) para evitar migralos; non me interesaban realmente.
E a actualización final que facemos é na nosa db_extension: instalamos timescaledb para que a base de datos, e especificamente o noso Zabbix, entenda a existencia de db_extension. Actívaa e usa a sintaxe e as consultas correctas para a base de datos, aproveitando as funcionalidades necesarias para TimescaleDB.
Configuración do servidor
Usei dous servidores. O primeiro servidor é unha máquina virtual bastante pequena con 20 procesadores e 16 gigabytes de RAM. Configureino con PostgreSQL 10.8:

O sistema operativo era Debian, sistema de ficheiros – xfs. Fixen unha configuración mínima para usar esta base de datos especificamente, menos o que usará o propio Zabbix. O servidor Zabbix, PostgreSQL e os axentes de carga tamén foron instalados nesta máquina.

Usei 50 axentes activos que empregan LoadableModule para xerar rapidamente varios resultados. Xeraron cadeas de texto, números, etc. Enchei a base de datos cunha gran cantidade de datos. A configuración inicial contiña 5 elementos de datos por host e aproximadamente cada elemento de datos contiña un disparador para que fose unha configuración realista. Ás veces, incluso se require máis dun disparador para o seu uso.

Regulei o intervalo de actualización e a propia carga non só usando 50 axentes (engadindo máis), senón tamén usando elementos de datos dinámicos e reducindo o intervalo de actualización a 4 segundos.
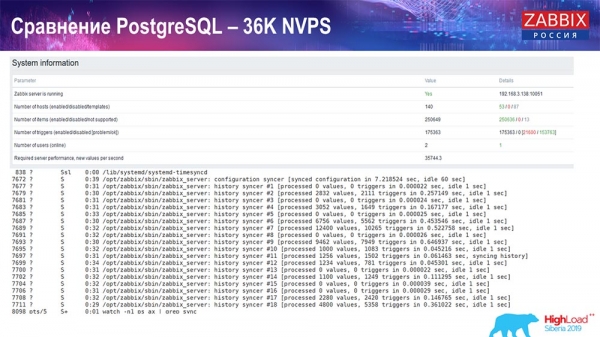
Proba de rendemento de PostgreSQL: 36 NVP
O meu primeiro lanzamento, a miña primeira configuración, foi nun PostgreSQL 10 limpo con este hardware (35 valores por segundo). En xeral, como podes ver na pantalla, a inserción de datos leva unha fracción de segundo: todo é bo e rápido, grazas ás unidades SSD (200 GB). O único é que as unidades de 20 GB énchense bastante rápido.
Haberá bastantes gráficos coma este máis adiante. Este é o panel de rendemento estándar do servidor Zabbix.
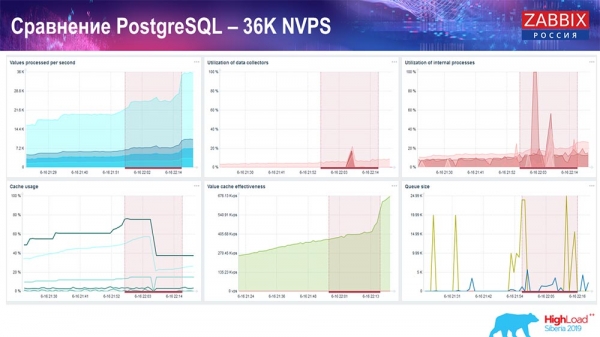
O primeiro gráfico mostra o número de valores por segundo (azul, arriba á esquerda), 35 valores neste caso. Este (arriba ao centro) mostra a carga dos procesos de compilación e este (arriba á dereita) mostra a carga dos procesos internos: sincronizadores de historial e o housekeeper, que aquí (abaixo ao centro) leva funcionando bastante tempo.
Este gráfico (na parte inferior central) mostra o uso de ValueCache: cantos acertos de ValueCache xeran os activadores (varios miles de valores por segundo). Outro gráfico importante é o cuarto (na parte inferior esquerda), que mostra o uso do HistoryCache que mencionei antes, que é un búfer antes de inserir datos na base de datos.
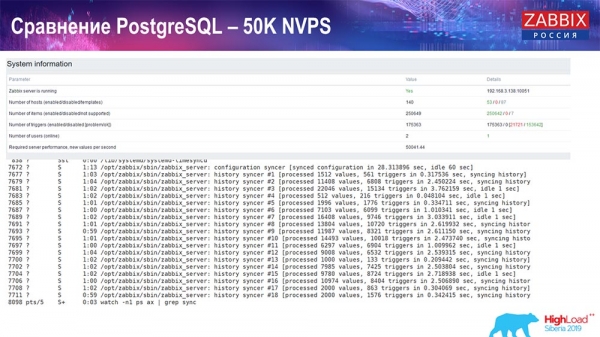
Proba de rendemento de PostgreSQL: 50 NVP
A continuación, aumentei a carga a 50 valores por segundo no mesmo hardware. Cando se cargaba con Housekeeper, escribíanse 10 valores en 2-3 segundos, incluíndo os cálculos. Isto móstrase na seguinte captura de pantalla:
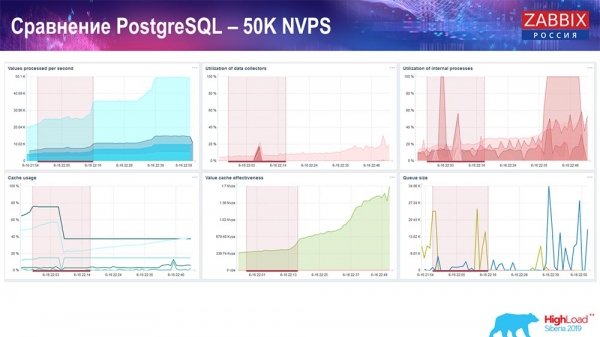
O administrador xa está a comezar a interferir co traballo, pero en xeral, a carga do receptor do historial aínda está no 60 % (terceiro gráfico, arriba á dereita). O historial caché xa comeza a encherse rapidamente mentres o administrador está a executarse (abaixo á esquerda). Era aproximadamente medio xigabyte e enchíase ata o 20 %.
Proba de rendemento de PostgreSQL: 80 NVP
Despois aumenteino a 80 mil valores por segundo:
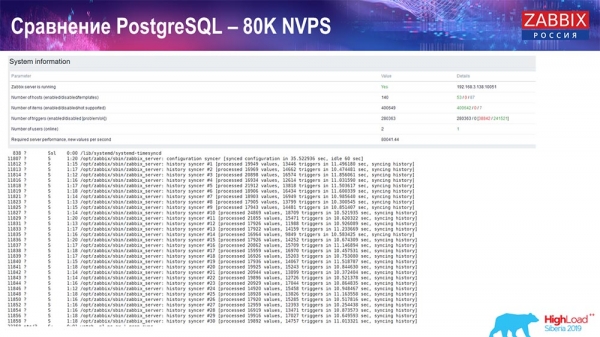
Isto foron aproximadamente 400 elementos de datos e 280 disparadores. Como podes ver, a taxa de inserción, baseada na carga do sumidoiro de historial (había 30 deles), xa era bastante alta. Despois aumentei varios parámetros: sumidoiros de historial, caché... Neste hardware, a carga do sumidoiro de historial comezou a aumentar ao máximo, practicamente "ata o límite"; en consecuencia, o HistoryCache comezou a experimentar unha carga moi alta:
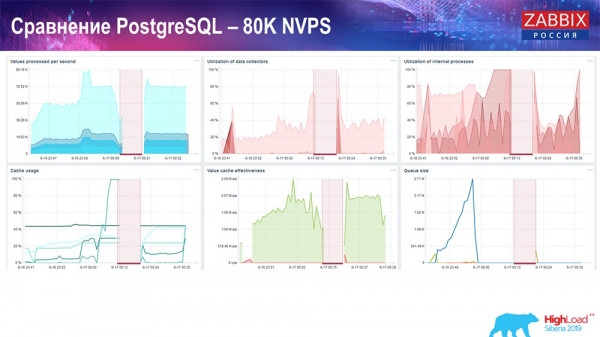
Durante todo este tempo, estiven monitorizando todos os parámetros do sistema (uso do procesador, RAM) e descubrín que a utilización do disco estaba ao máximo: alcanzara a capacidade máxima deste disco neste hardware, nesta máquina virtual. A este ritmo, PostgreSQL comezou a descargar datos de forma bastante agresiva e o disco non podía seguir o ritmo das escrituras, lecturas e outras tarefas.
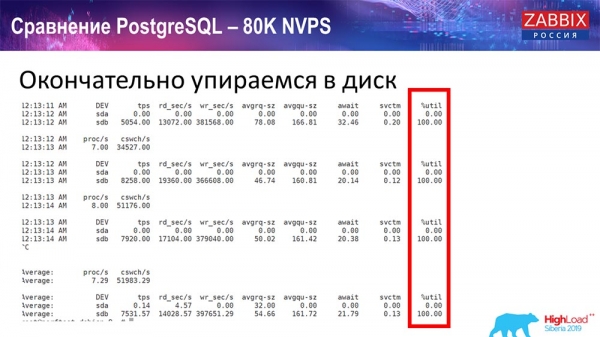
Collín outro servidor, que xa tiña 48 procesadores e 128 gigabytes de RAM:
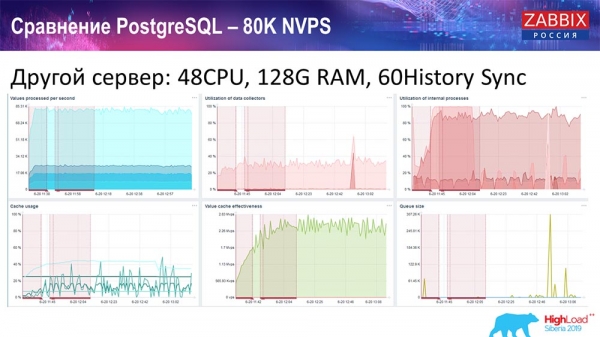
Tamén o axustei: instalei o Sincronizador de Historial (60 deles) e acadei un rendemento aceptable. Aínda non chegamos a ese punto, pero probablemente esteamos no límite de rendemento onde hai que facer algo.
Proba de rendemento. TimescaleDB: 80 NVP
O meu obxectivo principal era usar TimescaleDB. Cada gráfico mostra unha caída:
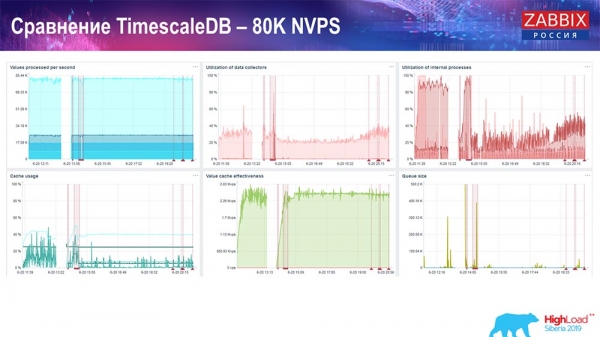
Estas caídas débense precisamente á migración de datos. Despois disto, o perfil de carga do historial de entrada no servidor Zabbix, como podes ver, cambiou significativamente. Permite a inserción de datos case tres veces máis rápido e usa menos HistoryCache, o que significa que recibirás datos de maneira oportuna. De novo, 80.000 valores por segundo é unha taxa bastante alta (certamente non para Yandex). En xeral, trátase dunha configuración bastante grande, cun só servidor.
Proba de rendemento de PostgreSQL: 120 NVP
A continuación, aumentei o número de elementos de datos a medio millón e obtiven un valor estimado de 125 mil por segundo:
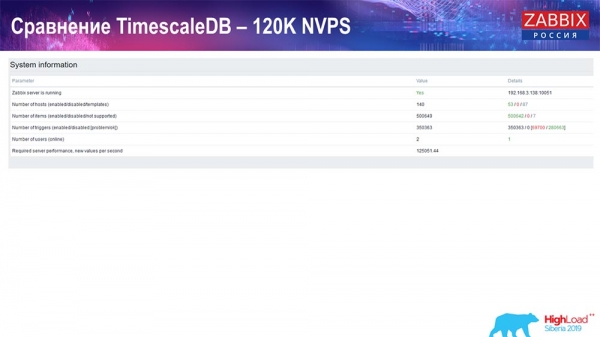
E obtiven estes gráficos:
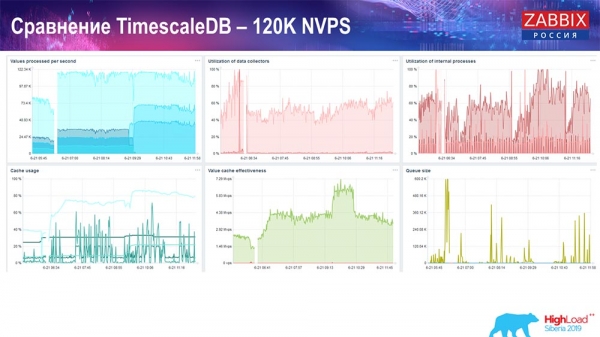
En principio, esta é unha configuración que funciona; pode funcionar durante bastante tempo. Pero como só tiña 1,5 terabytes de espazo en disco, useino en poucos días. O máis importante é que se crearon novas particións en TimescaleDB ao mesmo tempo, e isto foi completamente imperceptible para o rendemento, o que non ocorre con MySQL.
As particións créanse normalmente pola noite porque isto bloquea as insercións e a manipulación de táboas por completo, o que pode levar á degradación do servizo. Este non é o caso aquí! O obxectivo principal era probar as capacidades de TimescaleDB. O resultado foron 120 valores por segundo.
Tamén hai exemplos na "comunidade":
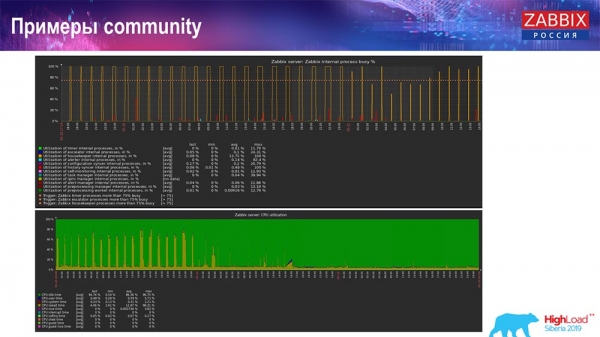
Alguén tamén activou TimescaleDB, e a carga da CPU para o uso de io.weight diminuíu; o uso de elementos de proceso internos tamén diminuíu grazas a TimescaleDB. E estes eran discos normais, é dicir, unha máquina virtual normal executándose en discos normais (non SSD)!
Para configuracións pequenas que están limitadas polo rendemento do disco, TimescaleDB semella unha moi boa solución. Permitirache seguir traballando ben antes de migrar a hardware de base de datos máis rápido.
Convídovos a todos aos nosos eventos: Conferencia en Moscova, Cumio en Riga. Usade as nosas canles: Telegram, foro, IRC. Se tedes algunha dúbida, vide ao noso stand; podemos falar de todo.
Preguntas do público
Pregunta do público (en diante, denominada A): Se TimescaleDB é tan doado de configurar e ofrece unha mellora do rendemento tan grande, quizais debería empregarse como práctica recomendada para configurar Zabbix con Postgres? Hai algunha desvantaxe ou inconveniente nesta solución ou é certo que se decido compilar Zabbix, podo instalar Timescale directamente en Postgres, usalo e non preocuparme por ningún problema?

AG: – Si, eu diría que é unha boa recomendación usar PostgreSQL coa extensión TimescaleDB. Como dixen, hai moitas boas críticas, aínda que esta funcionalidade é experimental. Pero, de feito, as probas amosan que é unha solución excelente (con TimescaleDB) e creo que seguirá evolucionando! Estamos a vixiar como se desenvolve esta extensión e faremos os axustes necesarios.
Incluso confiamos nunha das súas características coñecidas durante o desenvolvemento: permitíanos traballar con fragmentos dun xeito un pouco diferente. Pero despois eliminárona na seguinte versión e tivemos que deixar de depender dese código. Recomendaría usar esta solución para moitas configuracións. Se usas MySQL... Para configuracións normais, calquera solución funciona ben.
R: – Os últimos gráficos da comunidade incluían un gráfico con Housekeeper:
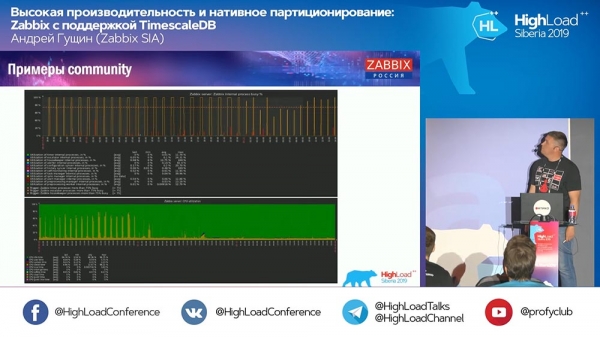
Continuou traballando. Que fai Housekeeper con TimescaleDB?
AG: "Non o podo asegurar agora mesmo. Mirarei o código e dareiche máis detalles. Usa consultas de TimescaleDB especificamente, non para eliminar fragmentos, senón para algún tipo de agregación. Aínda non estou preparado para responder a esa pregunta técnica. Confirmarémolo no stand hoxe ou mañá."
R: – Teño unha pregunta semellante sobre o rendemento da operación de eliminación en Escala de tempo.
A (resposta do público): "Cando eliminas datos dunha táboa, se o fas con delete, necesitas iterar pola táboa: eliminar, limpar e marcar todo para uso futuro. En Timescala, como tes fragmentos, podes descartalos. En termos xerais, simplemente lle dis ao ficheiro en Big Data: "Eliminar!""
Timescale simplemente entende que o fragmento xa non existe. E como está integrado no planificador de consultas, conéctase ás túas condicións en instrucións de selección ou outras operacións e entende inmediatamente que o fragmento xa non existe: "Non volverei aí!" (sen datos). Iso é todo! Polo tanto, unha análise de táboa substitúese eliminando o ficheiro binario, polo que é rápido.
R: Xa falamos do tema das cousas que non son SQL. Polo que eu entendo, Zabbix non precisa modificar datos; é unha especie de rexistro. É posible usar bases de datos especializadas que non poidan modificar os seus datos pero que sexan moito máis rápidas á hora de almacenalos, acumulalos e recuperalos (como Clickhouse ou algo semellante a Kafka? Kafka tamén é un rexistro! É posible integralos dalgún xeito?
AG: – Podes facer unha exportación. Temos unha funcionalidade específica desde a versión 3.4: podes escribir todos os datos históricos, eventos e todo o demais en ficheiros; e despois usar algún controlador para envialos a calquera outra base de datos. De feito, moita xente reelabora os datos e escribe directamente na base de datos. Os sumidoiros de historial escríbeno todo en ficheiros sobre a marcha, rotan estes ficheiros, etc., e podes transferilo a Clickhouse. Non podo falar dos nosos plans, pero quizais continúe o soporte para solucións NoSQL (como Clickhouse).
R: – Entón, é posible desfacerse completamente de Postgres?
AG: "Por suposto, a parte máis complexa de Zabbix son as táboas históricas, que crean a maior parte dos problemas, e os eventos. Neste caso, se non almacenas eventos durante moito tempo e almacenas o historial e as tendencias noutro almacenamento rápido, entón, en xeral, creo que non haberá ningún problema."
R: – Podes estimar canto máis rápido funcionará todo se cambias a Clickhouse, por exemplo?
AG: "Non o probei. Creo que sería bastante doado conseguir polo menos as mesmas cifras, dado que Clickhouse ten a súa propia interface, pero non podo dicilo con certeza. É mellor probalo. Todo depende da configuración: cantos hosts teñas, etc. Inserir é unha cousa, pero tamén necesitas recompilar estes datos, con Grafana ou algo máis."
R: – Entón, estamos a falar dunha loita en igualdade de condicións, e non da gran vantaxe destes BD rápidos?
AG: – Creo que cando nos integremos, haberá probas máis precisas.
R: – Onde foi parar o bo e vello RRD? Que che levou a cambiar ás bases de datos SQL? Inicialmente, todas as métricas recollíanse en RRD.
AG: "Pode que Zabbix tivese unha versión moi antiga de RRD. Sempre tivemos bases de datos SQL (o enfoque clásico). O enfoque clásico é MySQL e PostgreSQL (existen desde hai moito tempo). Case nunca empregamos unha interface común para as bases de datos SQL e RRD."


Algúns anuncios 🙂
Grazas por estar connosco. Gústanche os nosos artigos? Queres ver máis contido interesante? Apóyanos facendo un pedido ou recomendando a amigos, , un análogo único de servidores de nivel de entrada, que inventamos nós para ti: (dispoñible con RAID1 e RAID10, ata 24 núcleos e ata 40 GB DDR4).
Dell R730xd 2 veces máis barato no centro de datos Equinix Tier IV en Amsterdam? Só aquí nos Países Baixos! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - desde $ 99! Ler sobre
Fonte: www.habr.com
