

A próxima conferencia HighLoad++ celebrarase os días 6 e 7 de abril de 2020 en San Petersburgo. Xa hai máis información e entradas dispoñibles. HighLoad++ Moscova 2018. Pavillón de Moscova. 9 de novembro, 15:00. Resumos e .

* Monitorización: en liña e analítica.
* Principais limitacións da plataforma ZABBIX.
* Solución para escalar o almacenamento de análises.
* Optimización do servidor ZABBIX.
* Optimización da interface de usuario.
* Experiencia operando o sistema baixo cargas superiores a 40 000 NVPS.
* Breves conclusións.
Mikhail Makurov (en diante – MM): - Ola a todos!
Maxim Chernetsov (en diante – MCH): - Boas tardes!
MM: "Permíteme presentarche a Maxim. Max é un enxeñeiro talentoso, o mellor experto en redes que coñezo. Maxim traballa con redes e servizos, o seu desenvolvemento e operación."

MC: "Gustaríame falarvos de Mikhail. Mikhail é un desenvolvedor de C. Escribiu varias solucións de procesamento de tráfico de alta carga para a nosa empresa. Vivimos e traballamos nos Urais, na cidade dura de Chelyabinsk, en Intersvyaz. Ofrecemos servizos de internet e televisión por cable a un millón de persoas en 16 cidades."
MM: "E paga a pena sinalar que Intersvyaz é moito máis que un simple provedor; é unha empresa de TI. A maioría das nosas solucións son desenvolvidas internamente polo noso departamento de TI."
R: Desde os servidores de procesamento de tráfico ata o centro de chamadas e a aplicación móbil, o departamento de TI conta actualmente con arredor de 80 persoas cunha ampla gama de habilidades.
Sobre Zabbix e a súa arquitectura
MC: – Agora tentarei establecer un récord persoal e dicir nun minuto o que é Zabbix (en diante, «Zabbix»).
Zabbix posicionase como un sistema de monitorización de nivel empresarial e listo para usar. Ofrece moitas funcións que facilitan a vida: regras de escalado avanzadas, unha API de integración e agrupación e descubrimento automático de hosts e métricas. Zabbix tamén inclúe ferramentas de escalado (proxies). Zabbix é un sistema de código aberto.
Brevemente sobre a arquitectura. Pódese dicir que consta de tres compoñentes:
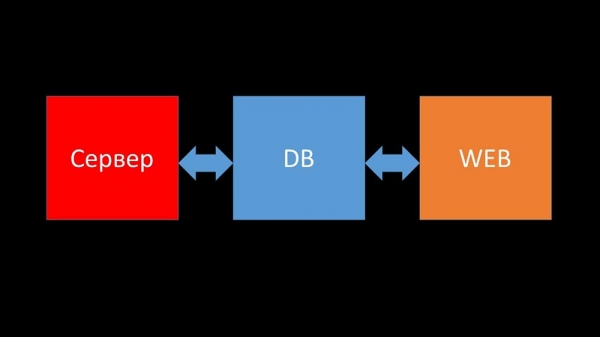
- O servidor. Escrito en C. Xestiona un procesamento bastante complexo e a transferencia de datos entre fíos. Todo o procesamento ocorre dentro del, desde a recepción ata o gardado na base de datos.
- Todos os datos almacénanse nunha base de datos. Zabbix admite MySQL, PostgreSQL e Oracle.
- A interface web está escrita en PHP. A maioría dos sistemas inclúen Apache, pero funciona de forma máis eficaz con Nginx e PHP.
Hoxe queremos compartir unha historia da vida da nosa empresa, relacionada con Zabbix...
Unha historia da vida de Intersvyaz. Que temos e que necesitamos?

Hai 5 ou 6 meses. Un día despois do traballo…
MC: "Misha, ola! Alégrome de terte atopado a tempo. Necesito falar contigo. Volvemos ter problemas de monitorización. Durante unha avaría importante, todo ía lento e non había información sobre o estado da rede. Desafortunadamente, non é a primeira vez que ocorre. Necesito a túa axuda. Asegurémonos de que a nosa monitorización funcione en calquera circunstancia!"
MM: "Pero sincronicemos primeiro. Non o miro dende hai un par de anos. Se ben recordo, deixamos Nagios e cambiamos a Zabbix hai uns oito anos. E agora temos, creo, seis servidores potentes e unha ducia de proxies. Estou a pasar algo por alto?"
MC: – Case. 15 servidores, algúns dos cales son máquinas virtuais. O máis importante é que non nos salva cando máis o necesitamos. Cando se produce un fallo, os servidores ralentizanse e non se pode ver nada. Tentamos optimizar a configuración, pero non proporcionou o aumento de rendemento óptimo.
MM: – Xa vexo. Fixácheste en algo, desenterraches algo xa nos diagnósticos?
MC: "O primeiro co que temos que lidar é coa base de datos. MySQL está constantemente baixo carga, almacenando novas métricas e, cando Zabbix comeza a xerar unha chea de eventos, a base de datos literalmente entra en bloqueo durante unhas horas. Xa vos falei da optimización da configuración, pero este mesmo ano actualizamos o hardware: os servidores teñen máis de cen gigas de memoria e matrices de discos RAID SSD; escalalo linealmente xa non ten sentido. Que imos facer?"
MM: "Xa vexo. MySQL é en realidade unha base de datos LTP. Ao parecer, xa non é axeitada para almacenar un arquivo de métricas do noso tamaño. Vexámolo."
MC: - Imos!
Integración de Zabbix e Clickhouse como resultado dun Hackathon
Despois dalgún tempo recibimos algúns datos interesantes:

A maior parte do espazo da nosa base de datos estaba ocupado polo arquivo de métricas e menos do 1 % usábase para configuración, modelos e axustes. Nese momento, xa levabamos máis dun ano executando unha solución de Big Data baseada en Clickhouse. A dirección que tomabamos estaba clara. No noso Hackathon de primavera, escribín unha integración Zabbix-Clickhouse para o servidor e o frontend. Nese momento, Zabbix xa era compatible con ElasticSearch, polo que decidimos comparar os dous.

Comparación entre Clickhouse e Elasticsearch
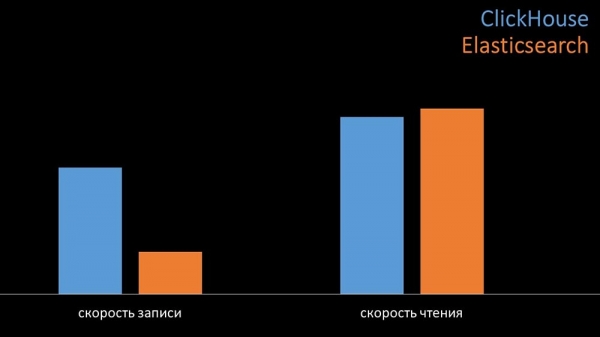
MM: En comparación, xeramos unha carga similar á proporcionada polo servidor Zabbix e observamos o rendemento dos sistemas. Escribimos datos en lotes de 1000 liñas usando CURL. Anticipamos que Clickhouse sería máis eficiente para o perfil de carga de Zabbix. Os resultados incluso superaron as nosas expectativas:
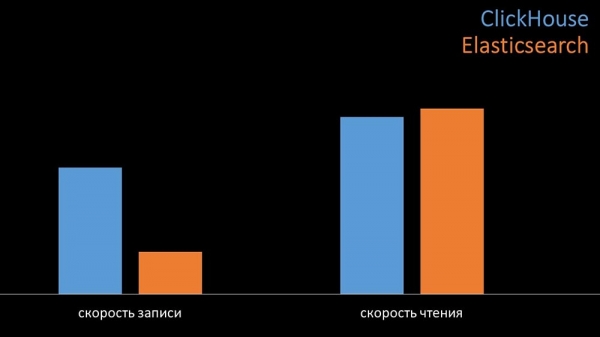
En condicións de proba idénticas, Clickhouse escribiu tres veces máis datos. Ambos os sistemas foron moi eficientes (con recursos) á hora de ler datos. Non obstante, Elasticx requiriu unha cantidade significativa de potencia da CPU á hora de escribir:
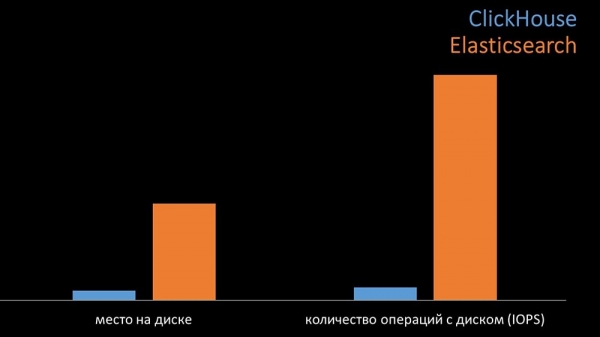
En xeral, Clickhouse superou significativamente a Elastix en consumo de CPU e velocidade. Ademais, grazas á compresión de datos, Clickhouse usa 11 veces menos espazo no disco duro e realiza aproximadamente 30 veces menos operacións no disco:
MC: Si, o subsistema de disco de Clickhouse é moi eficiente. Podes usar enormes unidades SATA para bases de datos e alcanzar velocidades de escritura de centos de miles de liñas por segundo. O sistema admite a fragmentación e a replicación de inmediato e é moi doado de configurar. Levamos un ano máis que satisfeitos co seu funcionamento.
Para optimizar os recursos, podes instalar Clickhouse xunto á túa base de datos principal existente, aforrando unha cantidade significativa de tempo de CPU e operacións de disco. Movemos o arquivo de métricas aos clústeres de Clickhouse existentes:
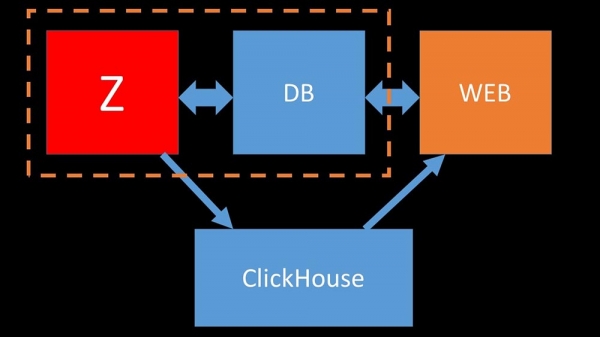
Descargamos tanto a base de datos principal de MySQL que puidemos combinala nunha máquina co servidor Zabbix e desfacernos do servidor MySQL dedicado.
Como funcionan as enquisas en Zabbix?
Hai 4 meses
MM: - Ben, podemos esquecer os problemas coa base?
MC: "Así é! Outro problema que temos que resolver é a lenta recollida de datos. Agora os nosos 15 servidores proxy están sobrecargados con procesos SNMP e de sondaxe. E non hai outra opción que seguir engadindo máis servidores."
MM: - Excelente. Pero primeiro, cóntame como funcionan as enquisas en Zabbix?
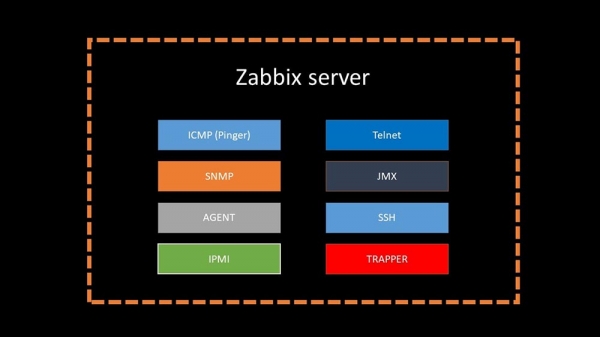
MC: En resumo, hai 20 tipos de métricas e unha ducia de xeitos de obtelas. Zabbix pode recompilar datos en modo de solicitude-resposta ou agardar por novos datos a través da interface Trapper.

Cómpre sinalar que no Zabbix orixinal este método (Trapper) é o máis rápido.
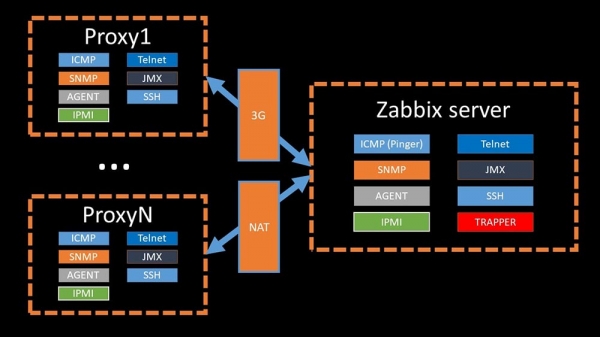
Hai servidores proxy para o balanceamento de carga:
Os proxies poden realizar as mesmas funcións de recollida que o servidor Zabbix, recibindo tarefas del e enviando métricas recollidas a través da interface Trapper. Este é o método oficialmente recomendado para o balanceo de carga. Os proxies tamén son útiles para monitorizar a infraestrutura remota que se executa detrás de NAT ou a través dunha ligazón lenta:
MM: – A arquitectura é clara. Necesitamos botar unha ollada ao código fonte…
Un par de días despois
A historia de como gañou o Fped de Nmap
MM: – Creo que atopei algo.
MC: - Dime!
MM: "Descubrín que as comprobacións de dispoñibilidade de Zabbix só comproban un máximo de 128 hosts simultaneamente. Intentei aumentar este número a 500 e eliminar o intervalo entre paquetes no seu ping; isto duplicou o rendemento. Pero gustaríame ver números máis altos."
MC: "Na miña práctica, ás veces teño que comprobar a dispoñibilidade de miles de hosts, e non vin nada máis rápido que nmap para isto. Estou seguro de que é o método máis rápido. Probémolo! Necesitamos aumentar significativamente o número de hosts nunha soa iteración."
MM: – Comprobar máis de cincocentos? Seiscentos?
MC: - Polo menos un par de miles.
MM: "De acordo. O principal que quería dicir é que descubrín que a maior parte das enquisas en Zabbix se fan de forma síncrona. Debemos convertelas absolutamente ao modo asíncrono. Entón poderemos aumentar drasticamente o número de métricas recollidas polos enquisadores, especialmente se aumentamos o número de métricas por iteración."
MC: - Xenial! E cando?
MM: - Como de costume, onte.
MC: – Comparamos as dúas versións de fping e nmap:
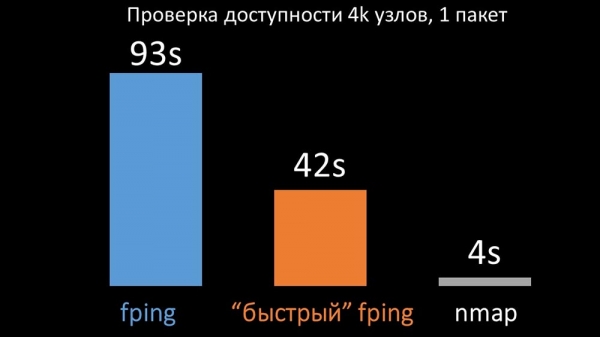
Como era de esperar, nmap foi ata cinco veces máis eficiente nun gran número de hosts. Dado que nmap só comproba a dispoñibilidade e o tempo de resposta, trasladamos os cálculos de perda a disparadores e reducimos significativamente os intervalos de comprobación de dispoñibilidade. Descubrimos que o número óptimo de hosts para nmap era duns 4 por iteración. Nmap permitiunos reducir o uso da CPU para as comprobacións de dispoñibilidade nun factor de tres e reducir o intervalo de 120 segundos a 10.
Optimización de sondaxes
MM: "Despois centrámonos nos sondeadores. Estabamos principalmente interesados nas enquisas e nos axentes SNMP. En Zabbix, a enquisa é síncrona e tómanse medidas especiais para aumentar a eficiencia do sistema. No modo síncrono, a indisponibilidade do host provoca unha degradación significativa da enquisa. Hai todo un sistema de estados, con procesos especiais, os chamados sondeadores inalcanzables, que só funcionan con hosts inalcanzables:

Este comentario demostra a matriz de estados e a complexidade do sistema de transición necesario para que o sistema siga sendo eficiente. Ademais, a propia enquisa síncrona é bastante lenta:
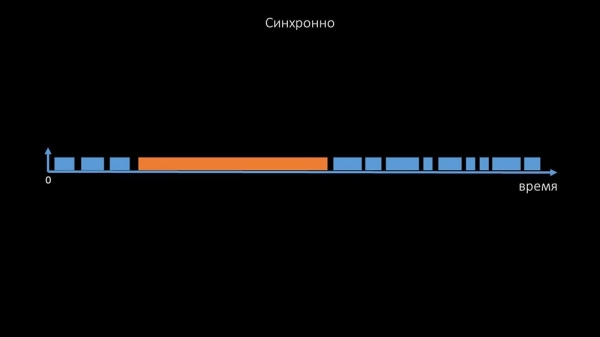
Esta é precisamente a razón pola que miles de fíos de sondeo nunha ducia de proxies non puideron recoller a cantidade de datos necesaria por nós. A implementación asíncrona non só solucionou o problema do reconto de fíos, senón que tamén simplificou significativamente o sistema de estado do host non dispoñible, porque para calquera número de hosts comprobados nunha única iteración de sondeo, o tempo de espera máximo era dun tempo de espera:
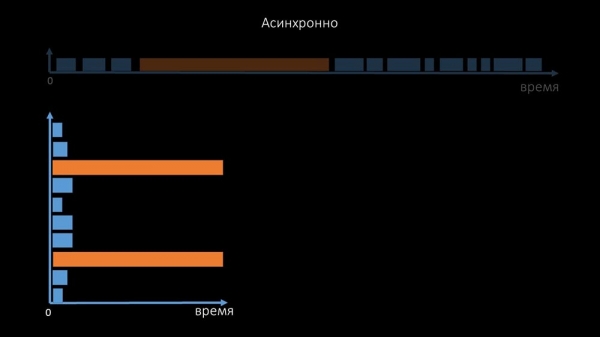
Tamén modificamos e refinamos o sistema de sondaxe SNMP. A maioría dos hosts non poden responder a varias solicitudes SNMP simultaneamente. Polo tanto, implementamos un modo híbrido, onde a sondaxe SNMP do mesmo host se realiza de forma asíncrona:
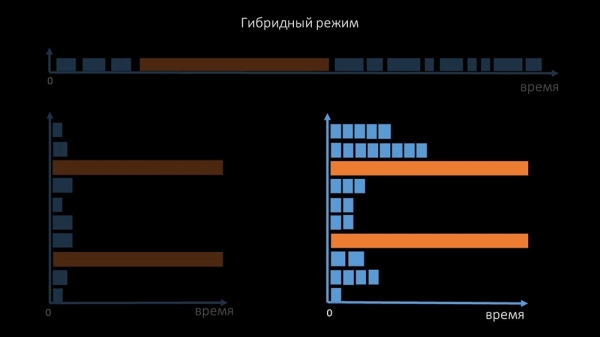
Isto faise para todo o grupo de hosts. En definitiva, este modo non é máis lento que un modo totalmente asíncrono, xa que a enquisa de 1 valores SNMP segue sendo moito máis rápida que un único tempo de espera.
Os nosos experimentos demostraron que o número óptimo de solicitudes por iteración é de aproximadamente 8 para a enquisa SNMP. En xeral, o cambio ao modo asíncrono permitiunos aumentar o rendemento da enquisa por un factor de 200, ou varios centos de veces.
MC: – As optimizacións de sondaxe resultantes demostraron que non só podiamos eliminar todos os proxies, senón tamén reducir os intervalos para moitas comprobacións, facendo que os proxies fosen innecesarios como forma de distribuír a carga.
Hai uns tres meses
Cambia a arquitectura: aumenta a carga!
MM: "Entón, Max, é hora de poñerse produtivo? Necesito un servidor potente e un bo enxeñeiro."
MC: "De acordo, xa o planificaremos. Xa é hora de que despeguemos a 5 métricas por segundo."
Mañá despois da actualización
MC: - Misha, actualizamos, pero pola mañá xa estabamos de volta... Adivina a que velocidade conseguimos?
MM: – Uns 20 mil como máximo.
MC: - Si, 25! Por desgraza, volvemos onde empezamos.
MM: - Que pasa? Fixeron algunha proba diagnóstica?
MC: – Si, por suposto! Aquí tes, por exemplo, un top interesante:
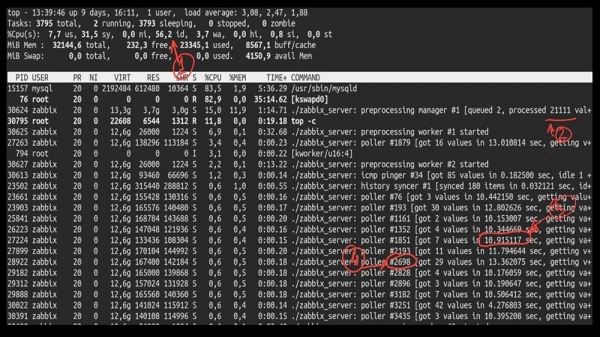
MM: – Vexamos. Vexo que probamos unha gran cantidade de fluxos de enquisas:
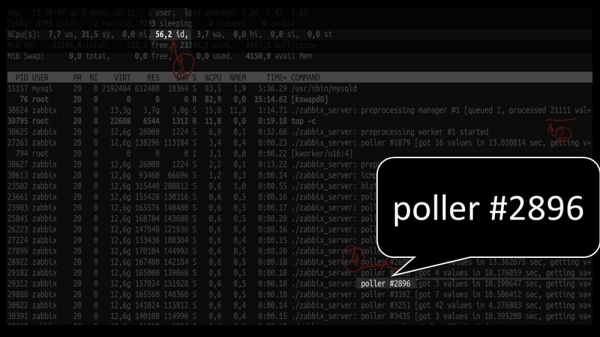
Pero non foron capaces de utilizar nin a metade do sistema:
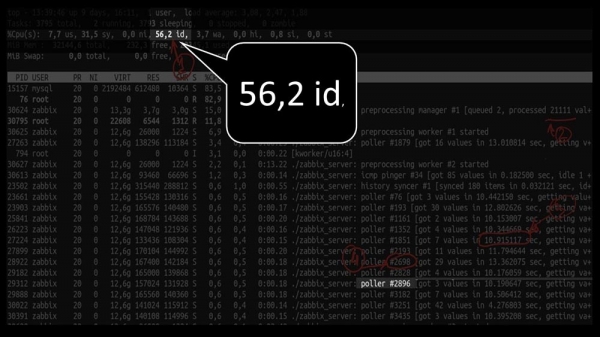
E o rendemento xeral é bastante baixo, arredor de 4 mil métricas por segundo:
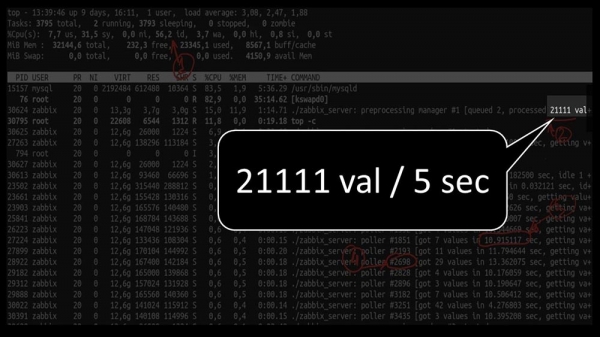
Hai algo máis?
MC: - Si, rastro dun dos enquisadores:
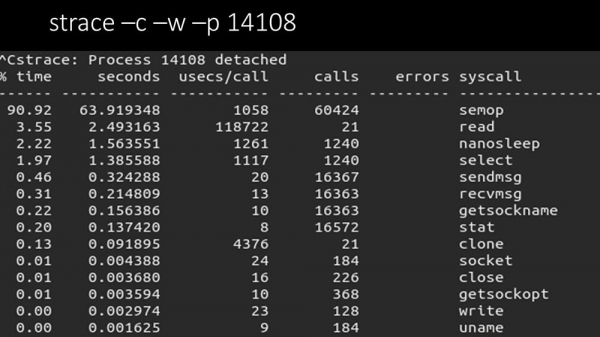
MM: – Aquí podes ver claramente que o proceso de sondaxe está á espera de "semáforos". Estes son os cadeados:
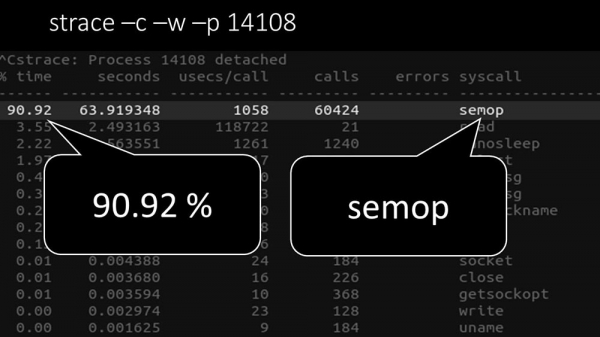
MC: - Non está claro.
MM: "Mira, é coma unha situación na que un grupo de fíos intentan traballar nun recurso no que só pode traballar un fío á vez. Entón, o único que poden facer é compartir ese recurso no tempo:"

E o rendemento xeral de traballar con tal recurso está limitado pola velocidade dun núcleo:
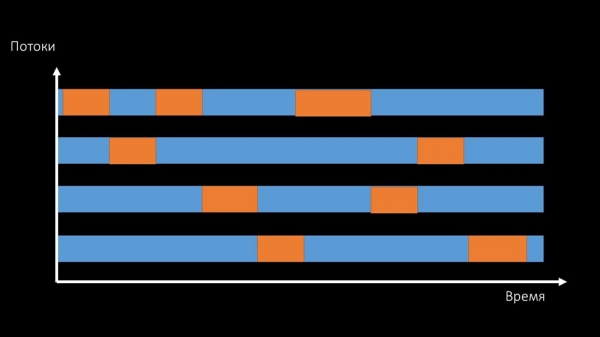
Hai dúas maneiras de resolver este problema.
Actualiza o hardware da túa máquina e cambia a núcleos máis rápidos:
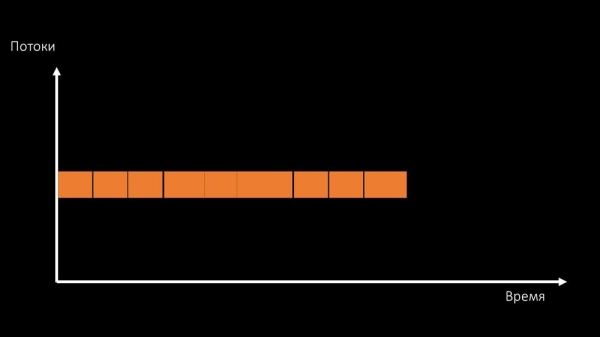
Ou cambiar a arquitectura e, en paralelo, a carga:
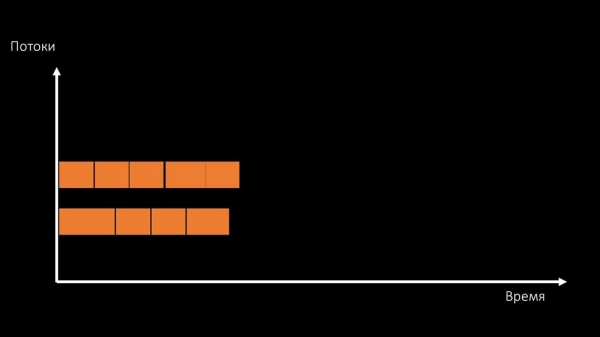
MC: – Por certo, executaremos menos núcleos na máquina de probas que na de produción, pero son 1,5 veces máis rápidos en termos de frecuencia por núcleo!
MM: - Entendido? Temos que botar unha ollada ao código do servidor.
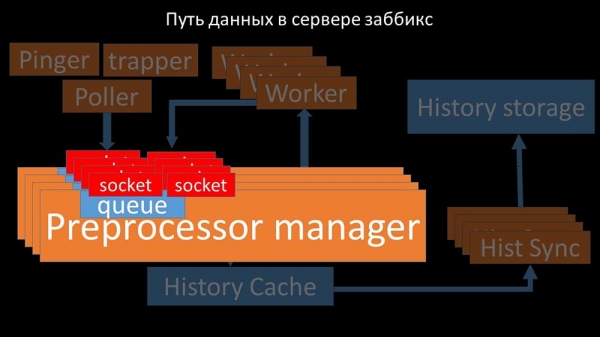
Ruta de datos no servidor Zabbix
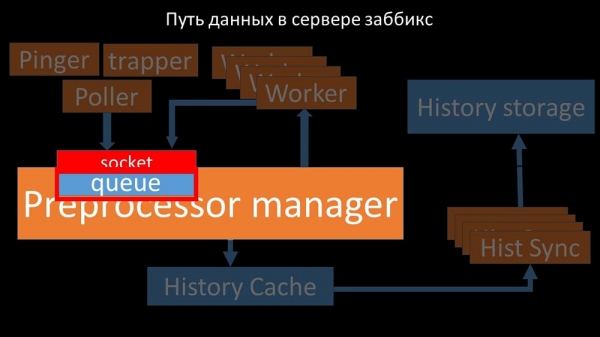
MC: – Para averiguar isto, comezamos a analizar como se transfiren os datos dentro do servidor Zabbix:
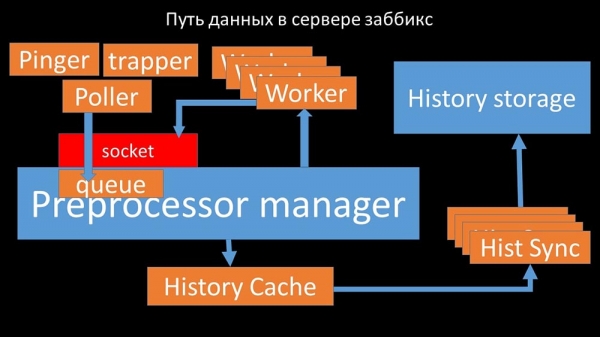
Unha imaxe bastante xenial, non si? Vexámola paso a paso para que quede un pouco máis clara. Hai fluxos e servizos responsables da recollida de datos:
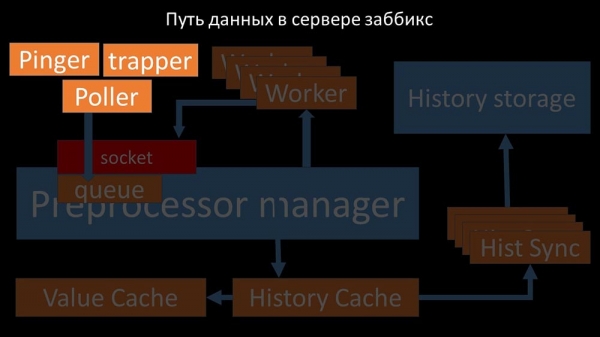
As métricas recollidas transmítense a través dun socket ao xestor de preprocesadores, onde se almacenan nunha cola:
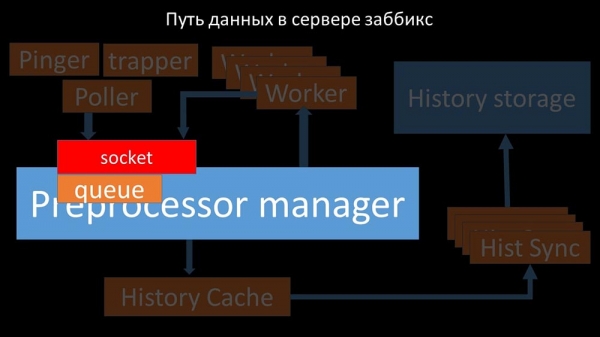
O "xestor de preprocesadores" pasa datos aos seus traballadores, que executan instrucións de preprocesamento e as devolven a través do mesmo socket:
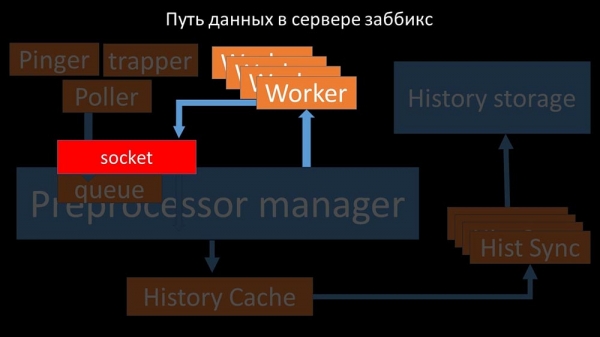
Despois disto, o xestor do preprocesador almacénaos na caché do historial:
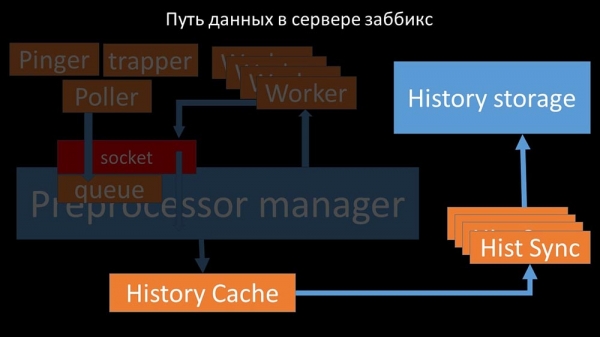
A partir de aí, recupéranse mediante sumidoiros de historial, que realizan unha ampla gama de funcións: por exemplo, calcular disparadores, poboar a caché de valores e, o máis importante, almacenar métricas no almacén de historial. En xeral, o proceso é complexo e bastante confuso.
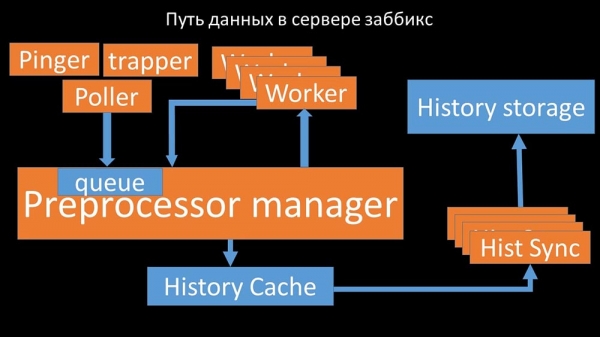
MM: – O primeiro que notamos foi que a maioría dos fíos competían pola chamada "caché de configuración" (a área de memoria onde se almacenan todas as configuracións do servidor). Os fíos responsables da recuperación de datos eran especialmente propensos a bloquearse:
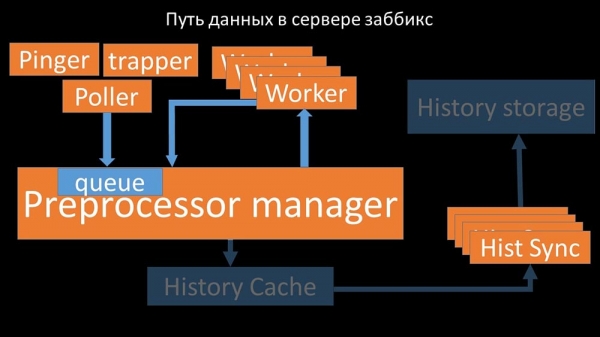
...xa que a configuración almacena non só métricas e os seus parámetros, senón tamén colas das que os sondeadores obteñen información sobre que facer a continuación. Cando hai moitos sondeadores e un bloquea a configuración, os demais agardan solicitudes:
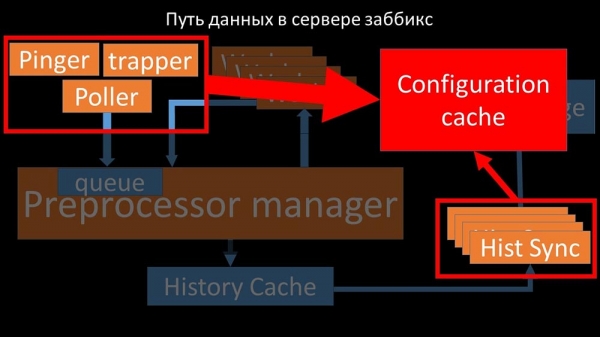
Os enquisadores non deberían entrar en conflito
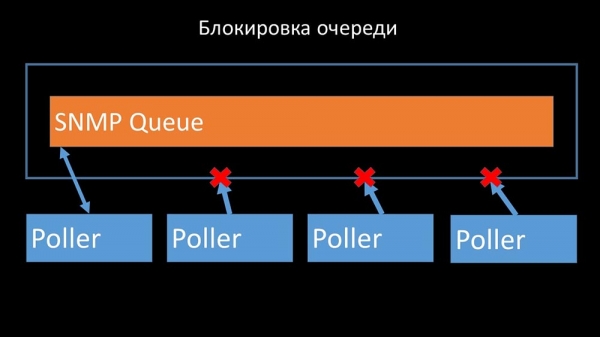
Entón, o primeiro que fixemos foi dividir a cola en catro partes e permitir que os sondeadores bloqueasen estas colas de forma segura, estas partes simultaneamente:
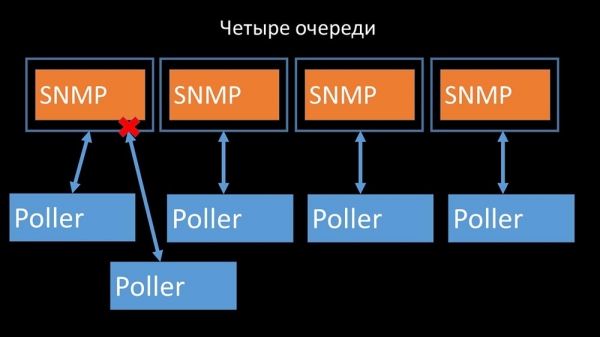
Isto eliminou a competencia pola caché de configuración e o rendemento do sondeador aumentou significativamente. Pero entón atopamos un problema co xestor de preprocesadores, que comezou a acumular unha cola de tarefas:
O xestor do preprocesador debe ser capaz de priorizar
Isto ocorreu cando se quedou sen rendemento. Entón, todo o que puido facer foi acumular solicitudes dos procesos de recollida de datos e apilar os seus búferes ata que consumiu toda a memoria e se bloqueou:
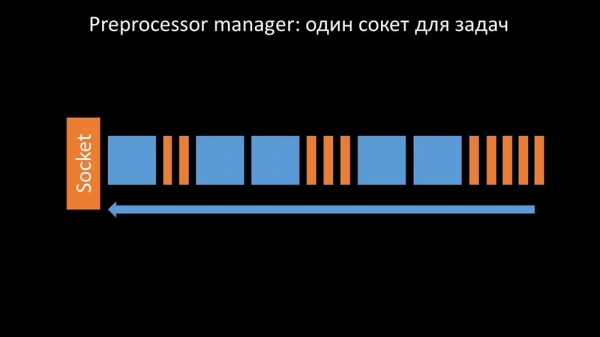
Para solucionar este problema, engadimos un segundo socket dedicado especificamente aos traballadores:
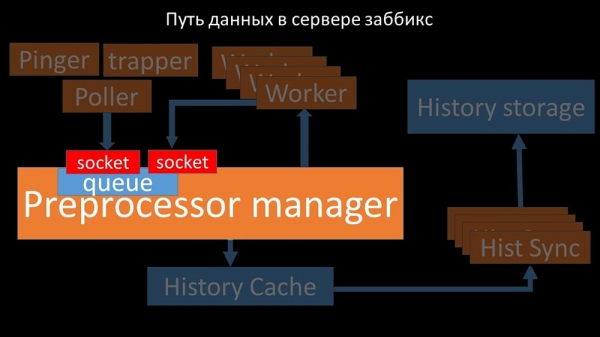
Deste xeito, o xestor do preprocesador tivo a oportunidade de priorizar o seu traballo e, se o búfer medra, ralentizar a recuperación, dándolles aos traballadores a oportunidade de aproveitar este búfer:
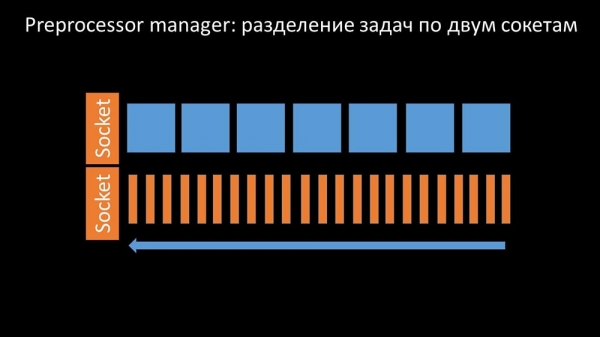
Despois descubrimos que unha das causas da desaceleración eran os propios traballadores, xa que competían por un recurso completamente irrelevante para o seu traballo. Emitimos unha corrección de erros para este problema, e xa foi resolto nas novas versións de Zabbix:
Aumentamos o número de soquetes e obtemos o resultado
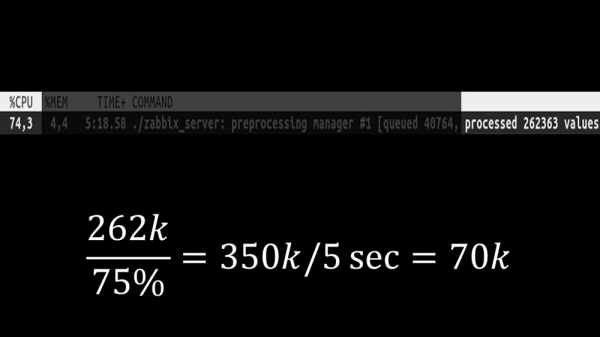
O propio xestor do preprocesador converteuse entón nun colo de botella, xa que era un único fío. Estaba limitado pola velocidade do núcleo, o que producía un rendemento máximo de aproximadamente 70 métricas por segundo:
Así que fixemos catro traballadores, con catro conxuntos de encaixes:
E isto permitiunos aumentar a velocidade a aproximadamente 130 mil métricas:
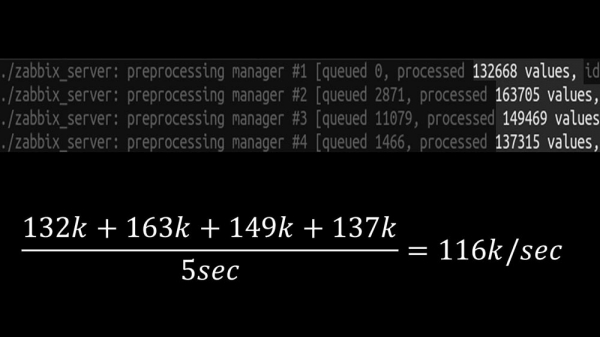
O crecemento non lineal explícase pola aparición da competencia pola caché do historial. Catro xestores de preprocesadores e sumidoiros de historial competiron por ela. Neste punto, estabamos a recibir aproximadamente 130.000 métricas por segundo na máquina de probas, utilizando aproximadamente o 95 % da CPU:
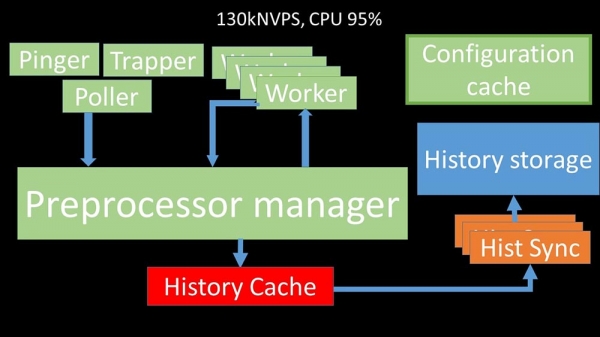
Hai uns 2,5 meses
O abandono da comunidade snmp aumentou os NVP nunha vez e media.
MM: "Max, preciso un novo vehículo de probas! Xa non cabe o actual."
MC: - Que hai agora?
MM: – Agora – 130 000 NVP e un procesador «na estantería».
MC: – Vaia! Xenial! Espera, teño dúas preguntas. Segundo os meus cálculos, as nosas necesidades son duns 15 000 ou 20 000 métricas por segundo. Por que necesitamos máis?
MM: "Quero levar isto a cabo. Quero ver canto podemos sacarlle proveito a este sistema."
MC: - Pero…
MM: - Pero non serve para os negocios.
MC: – Xa vexo. E a segunda pregunta: seremos capaces de manter o que temos agora de forma independente, sen axuda dun desenvolvedor?
MM: "Non o creo. Cambiar o funcionamento da caché de configuración é un problema. Afecta aos cambios na maioría dos fíos e é bastante difícil de manter. Probablemente será moi difícil de manter."
MC: - Entón precisamos algunha alternativa.
MM: "Hai unha opción. Podemos actualizar a núcleos máis rápidos mentres abandonamos o novo sistema de bloqueo. Seguiremos tendo un rendemento de 60-80 métricas. Podemos manter todo o resto do código. Clickhouse e as enquisas asíncronas seguirán funcionando. E serán fáciles de manter."
MC: - Marabilloso! Suxiro que paremos aquí.
Despois de optimizar o lado do servidor, finalmente puidemos lanzar o novo código a produción. Desbotamos algúns dos cambios en favor de migrar a unha máquina con núcleos máis rápidos e minimizar o número de cambios de código. Tamén simplificamos a configuración e, sempre que foi posible, eliminamos as macros nos elementos de datos, xa que eran unha fonte de bloqueos adicionais.

Por exemplo, a eliminación da macro snmp-community, que se atopa a miúdo na documentación e nos exemplos, permitiunos acelerar aínda máis os NVP aproximadamente 1,5 veces.
Despois de dous días en produción
Eliminar as ventás emerxentes do historial de incidentes
MC: "Misha, levamos dous días usando o sistema e todo funciona. Pero só cando todo funciona! Tiñamos programado un mantemento para migrar un segmento de rede bastante grande e comprobamos manualmente de novo que funcionaba e que non."
MM: "Non pode ser! Xa o comprobamos todo dez veces. O servidor xestiona incluso unha caída completa da rede ao instante."
MC: – Si, enténdoo todo: servidor, base de datos, top, austat, rexistros... todo é rápido... Pero miramos a interface web e hai un procesador "na estantería" do servidor e isto:

MM: – Entendido. Vexamos a web. Descubrimos que en situacións onde había un gran número de incidentes activos, a maioría dos widgets operativos comezaban a funcionar moi lentamente:
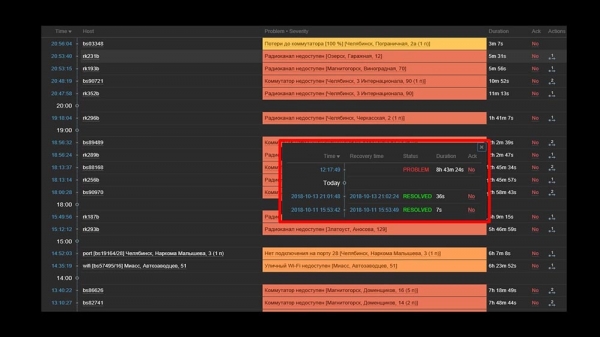
A causa disto foi a xeración de ventás emerxentes do historial de incidentes, que se xeran para cada elemento da lista. Polo tanto, desactivamos estas ventás emerxentes (comentamos cinco liñas de código) e isto solucionou os nosos problemas.
Mesmo cando non están dispoñibles por completo, os tempos de carga dos widgets reducíronse de varios minutos a uns manexables 10-15 segundos, e o historial aínda se pode ver facendo clic na hora:
Despois do traballo. Hai 2 meses
MC: - Misha, vas marchar? Teño algo do que falar.
MM: - Non o tiña planeado. Algo con Zabbix outra vez?
MC: - Non, relaxa! Só quería dicir: todo funciona, grazas! A cervexa vai por conta miña.
Zabbix é eficiente
Zabbix é un sistema bastante versátil e rico en funcionalidades. É perfectamente utilizable para instalacións pequenas listas para usar, pero a medida que as necesidades medran, é necesario optimizalo. Para almacenar un gran arquivo de métricas, use unha solución de almacenamento axeitada:
- Podes usar ferramentas integradas como a integración con Elastisearch ou a exportación do historial a ficheiros de texto (dispoñible desde a versión 4);
- Podes aproveitar a nosa experiencia e integración con Clickhouse.
Para aumentar drasticamente a velocidade de recollida de métricas, recólleas de forma asíncrona e transmíteas ao servidor Zabbix a través da interface trapper; ou podes usar un parche para facer que os sondeadores de Zabbix sexan asíncronos.
Zabbix está escrito en C e é bastante eficiente. Abordar varios colos de botella arquitectónicos permite melloras adicionais no rendemento, o que nos permite, segundo a nosa experiencia, obter máis de 100 métricas nunha máquina cun só procesador.

Ese mesmo parche de Zabbix
MM: Gustaríame engadir un par de puntos. Todo este informe, todas as probas e as cifras baséanse na configuración que estamos a usar. Actualmente estamos a recompilar aproximadamente 20 métricas por segundo. Se estás a tentar saber se isto funciona para ti, podes comparar. O que se comentou hoxe está dispoñible en GitHub como un parche:

O parche inclúe:
- integración completa con Clickhouse (tanto o servidor Zabbix como o frontend);
- resolución de problemas co xestor de preprocesadores;
- sondaxe asíncrona.
O parche é compatible con todas as versións da 4, incluída a LTS. É probable que funcione coa versión 3.4 con pequenos cambios.
Grazas pola súa atención.
preguntas
Pregunta do público (en diante, "A"): Boas tardes! Por favor, dígame, ten algún plan para unha colaboración intensiva co equipo de Zabbix, ou con eles, para garantir que isto non sexa un parche, senón o comportamento normal de Zabbix?
MM: – Si, definitivamente aplicaremos algúns dos cambios. Algúns engadiranse e outros permanecerán no parche.
R: Moitas grazas polo excelente informe! Poderías dicirme se a compatibilidade con Zabbix seguirá estando despois de aplicar o parche e como podo seguir actualizando a versións superiores? Será posible actualizar Zabbix á versión 4.2 ou 5.0 despois do teu parche?
MM: "Non podo falar do soporte técnico. Se eu fose o soporte técnico de Zabbix, probablemente diría que non, porque é código doutra persoa. En canto á base de código 4.2, a nosa posición é: 'Seguiremos adiante e actualizaremos nós mesmos coa seguinte versión'. Polo tanto, durante un tempo, lanzaremos parches para versións actualizadas. Xa o mencionei no informe: o número de cambios entre versións aínda é bastante pequeno. Creo que a transición da 3.4 á 4 levounos uns 15 minutos. Algunhas cousas cambiaron alí, pero nada importante."
R: – Entón, planeas dar soporte ao teu parche e podes instalalo con seguridade en produción, recibindo actualizacións dalgún xeito no futuro?
MM: "Recomendámolo encarecidamente. Resolve moitos problemas para nós."
MC: – Gustaríame salientar unha vez máis que os cambios que non afectan á arquitectura, aos bloqueos ou ás colas son modulares e están contidos en módulos separados. Mesmo con cambios menores, pódense manter con bastante facilidade de forma independente.
MM: Se che interesan os detalles, Clickhouse usa o que se denomina unha biblioteca histórica. Está desacoplada (é unha copia da biblioteca de soporte de Elastix, o que significa que se pode modificar a configuración). A enquisa só cambia os enquisadores. Cremos que isto funcionará durante moito tempo.
R: – Moitas grazas. Poderías dicirme se hai algunha documentación dos cambios realizados?

MM: "A documentación é un parche. Obviamente, coa introdución de Clickhouse e novos tipos de sondeadores, xorden novas opcións de configuración. A ligazón da última diapositiva contén unha breve descrición de como usalo."
Acerca da substitución de fping por nmap
R: Como acabaches implementando isto? Podes dar exemplos específicos: estás a usar strippers e un script externo? Que é capaz de comprobar en última instancia un número tan grande de hosts tan rápido? Como obtés estes hosts? Tes que alimentalos a nmap dalgún xeito, obtelos dalgún lugar, colocalos, executar algo?
MM: "Xenial. Moi boa pregunta! A esencia é esta. Modificamos a biblioteca (ICMP ping, un compoñente de Zabbix) para realizar comprobacións ICMP que especifican unha conta de paquetes de un (1), e o código intenta usar nmap. Polo tanto, esta funcionalidade interna de Zabbix converteuse na funcionalidade interna do ping. En consecuencia, non se require sincronización nin captura. Isto fíxose deliberadamente para manter o sistema consistente e evitar a molestia de sincronizar dous sistemas de bases de datos: que comprobar, a carga mediante un sondeador ou se a nosa carga está rota? É moito máis sinxelo."
R: – Funciona tamén para proxies?
MM: "Si, pero non o probamos. O código de sondaxe é o mesmo tanto en Zabbix como no servidor. Debería funcionar. Volverei a insistir: o rendemento do sistema é tal que non necesitamos un proxy."
MC: – A resposta correcta á pregunta é: «Por que necesitas un proxy con semellante sistema?» É só por mor da NAT ou para monitorizar a través dalgún canal lento...
R: – E usas Zabbix como alérxeno, se o entendín ben. Ou tes os teus gráficos (onde está a capa de arquivo) movidos a outro sistema, como Grafana? Ou non usas esa funcionalidade?
MM: "Volverei a insistir: implementamos unha integración completa. Estamos a subir o historial a Clickhouse, pero tamén modificamos o frontend de PHP. O frontend de PHP conéctase a Clickhouse e xera todos os gráficos desde alí. Ao mesmo tempo, para ser sinceros, temos un compoñente que usa os mesmos datos de Clickhouse e Zabbix para crear datos noutros sistemas de visualización gráfica."
MC: – Entre outras cousas, en «Grafan».
Como se tomou a decisión sobre a asignación de recursos?
R: – Poderías compartir un pouco de información sobre o funcionamento interno? Como se tomou a decisión de asignar recursos para un redeseño importante do produto? Isto, por suposto, conleva certos riscos. E, no contexto dos teus plans para dar soporte a novas versións, como se xustifica esta decisión desde unha perspectiva de xestión?
MM: "Ao parecer, non contamos moi ben o drama da historia. Atopámonos nunha situación na que había que facer algo e, basicamente, fomos en dous equipos paralelos:"
- Un deles foi o lanzamento dun sistema de monitorización empregando novos métodos: a monitorización como servizo, un conxunto estándar de solucións de código aberto que combinamos e despois tentamos cambiar o proceso empresarial para que funcione co novo sistema de monitorización.
- Ao mesmo tempo, tiñamos un programador entusiasta que estaba traballando nisto (sobre si mesmo). Casualmente gañou.
R: - E cal é o tamaño do equipo?
MC: - Ela está diante de ti.
R: - Entón, como sempre, necesítase unha persoa apaixonada?
MM: - Non sei o que é un apaixonado.
R: – Neste caso, parece que es ti. Moitas grazas, es incrible.
MM: - Grazas.
Acerca dos parches de Zabbix
R: – Para un sistema que usa proxies (por exemplo, nalgúns sistemas distribuídos), é posible adaptar e parchear a túa solución, por exemplo, sondeadores, proxies e parcialmente o propio preprocesador Zabbix; e as súas interaccións? É posible optimizar os desenvolvementos existentes para un sistema con varios proxies?
MM: – Sei que o servidor Zabbix está construído usando un proxy (compila e produce código). Non probamos isto en produción. Non estou seguro disto, pero non creo que o xestor de preprocesadores se use no proxy. A tarefa do proxy é coller un conxunto de métricas de Zabbix, enquisalas (tamén escribe a configuración e a base de datos local) e devolvelas ao servidor Zabbix. O propio servidor fará entón o preprocesamento cando as reciba.
O interese nos proxies é comprensible. Imos comprobalo. É un tema interesante.
R: – A idea era esta: se se poden aplicar parches aos sondadores, tamén se poden aplicar no proxy e na interacción co servidor, e o preprocesador só se pode adaptar para estes fins no servidor.
MM: "Creo que é aínda máis sinxelo. Colles o código, aplicas un parche e logo configúrao como o necesitas: creas servidores proxy (por exemplo, con ODBC) e distribúes o código parcheado entre os sistemas. Creas un proxy onde sexa necesario e un servidor onde sexa necesario."
R: – O máis probable é que non sexa necesario aplicar un parche adicional á transmisión por proxy ao servidor?
MC: - Non, é estándar.
MM: "De feito, unha das ideas nin sequera foi mencionada. Sempre tentamos atopar un equilibrio entre a explosión de ideas e o número de cambios, así como a facilidade de soporte."

Algúns anuncios 🙂
Grazas por estar connosco. Gústanche os nosos artigos? Queres ver máis contido interesante? Apóyanos facendo un pedido ou recomendando a amigos, , un análogo único de servidores de nivel de entrada, que inventamos nós para ti: (dispoñible con RAID1 e RAID10, ata 24 núcleos e ata 40 GB DDR4).
Dell R730xd 2 veces máis barato no centro de datos Equinix Tier IV en Amsterdam? Só aquí nos Países Baixos! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - desde $ 99! Ler sobre
Fonte: www.habr.com
