

O 26 de febreiro, celebramos unha reunión de Apache Ignite GreenSource, onde os colaboradores do proxecto de código aberto falaron . Un acontecemento importante na vida desta comunidade foi a reestruturación do compoñente , que che permite implementar microservizos personalizados directamente nun clúster Ignite. Falou deste difícil proceso na reunión , enxeñeiro de software e colaborador de Apache Ignite durante máis de dous anos.
Comecemos polo que é Apache Ignite en xeral. Esta é unha base de datos que é un almacenamento de clave/valor distribuído con soporte para SQL, transaccionalidade e caché. Ademais, Ignite permítelle implementar servizos personalizados directamente nun clúster de Ignite. O programador ten acceso a todas as ferramentas que proporciona Ignite: estruturas de datos distribuídas, mensaxería, transmisión en tempo real, computación e reixa de datos. Por exemplo, ao usar Data Grid, o problema de administrar unha infraestrutura separada para o almacenamento de datos e, como consecuencia, os custos xerais resultantes desaparecen.
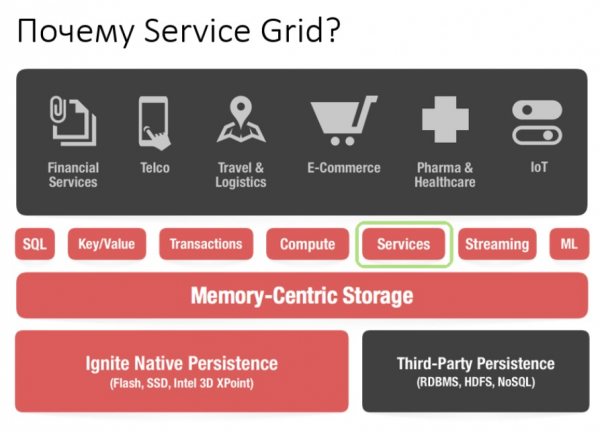
Usando a API de Service Grid, pode implementar un servizo simplemente especificando o esquema de implantación e, en consecuencia, o propio servizo na configuración.
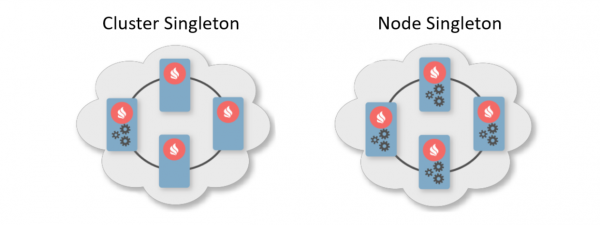
Normalmente, un esquema de despregamento é unha indicación do número de instancias que se deben despregar nos nodos do clúster. Hai dous esquemas de implantación típicos. O primeiro é Cluster Singleton: en calquera momento, unha instancia dun servizo de usuario está garantida para estar dispoñible no clúster. O segundo é Node Singleton: unha instancia do servizo está implantada en cada nodo do clúster.
O usuario tamén pode especificar o número de instancias de servizo en todo o clúster e definir un predicado para filtrar os nós axeitados. Neste escenario, o propio Service Grid calculará a distribución óptima para a implantación dos servizos.
Ademais, hai unha función como Affinity Service. A afinidade é unha función que define a relación das claves coas particións e a relación das partes cos nodos da topoloxía. Usando a chave, pode determinar o nodo principal no que se almacenan os datos. Deste xeito, pode asociar o seu propio servizo cunha caché de funcións de clave e afinidade. Se a función de afinidade cambia, producirase a redistribución automática. Deste xeito, o servizo estará sempre situado preto dos datos que precisa manipular e, en consecuencia, reducirase a sobrecarga de acceso á información. Este esquema pódese chamar unha especie de computación colocada.
Agora que descubrimos cal é a beleza de Service Grid, imos falar do seu historial de desenvolvemento.
O que pasou antes
A implementación anterior de Service Grid baseouse na caché do sistema replicado transaccional de Ignite. A palabra "caché" en Ignite refírese ao almacenamento. É dicir, isto non é algo temporal, como podería pensar. A pesar de que a caché é replicada e cada nodo contén todo o conxunto de datos, dentro da caché ten unha representación particionada. Isto débese á optimización do almacenamento.
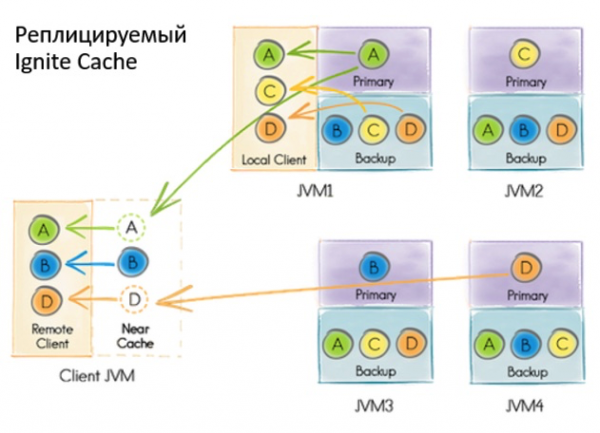
Que pasou cando o usuario quería implementar o servizo?
- Todos os nodos do clúster subscribíronse para actualizar os datos no almacenamento mediante o mecanismo de consulta continua incorporado.
- O nodo iniciador, baixo unha transacción de lectura comprometida, fixo un rexistro na base de datos que contiña a configuración do servizo, incluída a instancia serializada.
- Cando se lle notificou unha nova entrada, o coordinador calculou a distribución en función da configuración. O obxecto resultante foi escrito de novo na base de datos.
- Se un nodo formaba parte da distribución, o coordinador tiña que implantalo.
O que non nos conviña
Nalgún momento chegamos á conclusión: esta non é a forma de traballar cos servizos. Houbo varias razóns.
Se se produciu algún erro durante a implantación, só se podería descubrir a partir dos rexistros do nodo onde pasou todo. Só houbo implantación asíncrona, polo que despois de devolverlle o control ao usuario desde o método de implantación, necesitou un tempo adicional para iniciar o servizo, e durante este tempo o usuario non puido controlar nada. Para desenvolver aínda máis a rede de servizos, crear novas funcións, atraer novos usuarios e facilitar a vida de todos, algo ten que cambiar.
Á hora de deseñar a nova Service Grid, queriamos en primeiro lugar ofrecer unha garantía de implantación sincrónica: en canto o usuario devolvese o control da API, podía utilizar inmediatamente os servizos. Tamén quería darlle ao iniciador a capacidade de xestionar os erros de despregamento.
Ademais, quería simplificar a implementación, é dicir, fuxir das transaccións e do reequilibrio. A pesar de que a caché está replicada e non hai equilibrio, xurdiron problemas durante unha gran implantación con moitos nodos. Cando a topoloxía cambia, os nós necesitan intercambiar información e, cun gran despregamento, estes datos poden pesar moito.
Cando a topoloxía era inestable, o coordinador necesitaba recalcular a distribución dos servizos. E, en xeral, cando tes que traballar con transaccións nunha topoloxía inestable, isto pode levar a erros difíciles de predicir.
Problemas
Cales son os cambios globais sen problemas asociados? O primeiro deles foi un cambio de topoloxía. Debe entender que en calquera momento, mesmo no momento da implantación do servizo, un nodo pode entrar ou saír do clúster. Ademais, se no momento da implantación o nodo se une ao clúster, será necesario transferir de forma consistente toda a información sobre os servizos ao novo nodo. E non só falamos do que xa foi despregado, senón tamén dos despregamentos actuais e futuros.
Este é só un dos problemas que se poden recoller nunha lista separada:
- Como implementar servizos configurados estáticamente no inicio do nodo?
- Deixar un nodo do clúster: que facer se o nodo alberga servizos?
- Que facer se cambiou o coordinador?
- Que facer se o cliente volve conectarse ao clúster?
- Hai que procesar as solicitudes de activación/desactivación e como?
- E se pedisen a destrución da caché e temos servizos de afinidade vinculados a ela?
E iso non é todo.
decisión
Como obxectivo, escollemos o enfoque impulsado por eventos coa implementación da comunicación de procesos mediante mensaxes. Ignite xa implementa dous compoñentes que permiten aos nodos reenviar mensaxes entre si: comunicación-spi e descubrimento-spi.
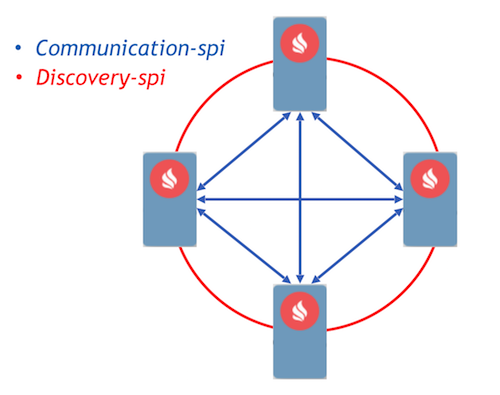
Communication-spi permite aos nodos comunicarse directamente e reenviar mensaxes. É moi axeitado para enviar grandes cantidades de datos. Discovery-spi permítelle enviar unha mensaxe a todos os nodos do clúster. Na implementación estándar, isto faise usando unha topoloxía en anel. Tamén hai integración con Zookeeper, neste caso utilízase unha topoloxía en estrela. Outro punto importante a destacar é que discovery-spi ofrece garantías de que a mensaxe será entregada definitivamente na orde correcta a todos os nodos.
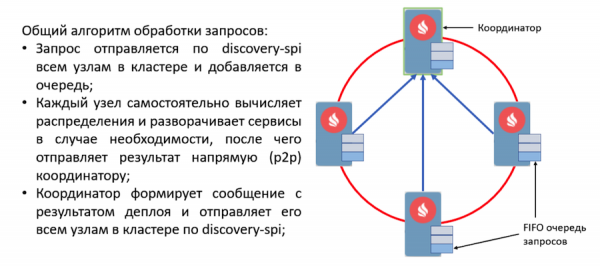
Vexamos o protocolo de implantación. Todas as solicitudes dos usuarios para a implantación e a retirada envíanse a través de discovery-spi. Isto dá o seguinte garantías:
- A solicitude será recibida por todos os nodos do clúster. Isto permitirá que a solicitude continúe a tramitación cando cambie o coordinador. Isto tamén significa que nunha mensaxe, cada nodo terá todos os metadatos necesarios, como a configuración do servizo e a súa instancia serializada.
- A ordenación estrita da entrega de mensaxes axuda a resolver os conflitos de configuración e as solicitudes en competencia.
- Dado que a entrada do nodo na topoloxía tamén se procesa mediante discovery-spi, o novo nodo recibirá todos os datos necesarios para traballar cos servizos.
Cando se recibe unha solicitude, os nodos do clúster validan e crean tarefas de procesamento. Estas tarefas son postas en fila e despois procesadas noutro fío por un traballador independente. Implícase deste xeito porque a implantación pode levar moito tempo e atrasar o custoso fluxo de descubrimento de forma intolerable.
Todas as solicitudes da cola son procesadas polo xestor de implantación. Ten un traballador especial que extrae unha tarefa desta cola e inicialízaa para comezar a implantación. Despois diso, ocorren as seguintes accións:
- Cada nodo calcula de forma independente a distribución grazas a unha nova función de asignación determinista.
- Os nodos xeran unha mensaxe cos resultados do despregamento e envíano ao coordinador.
- O coordinador agrega todas as mensaxes e xera o resultado de todo o proceso de implantación, que se envía a través de discovery-spi a todos os nodos do clúster.
- Cando se recibe o resultado, o proceso de implantación remata, despois de que a tarefa elimínase da cola.
Novo deseño dirixido por eventos: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.java
Se se produce un erro durante a implantación, o nodo inclúe inmediatamente este erro nunha mensaxe que envía ao coordinador. Despois da agregación da mensaxe, o coordinador terá información sobre todos os erros durante a implantación e enviará esta mensaxe a través de discovery-spi. A información de erros estará dispoñible en calquera nodo do clúster.
Todos os eventos importantes da rede de servizos procesanse mediante este algoritmo operativo. Por exemplo, cambiar a topoloxía tamén é unha mensaxe a través de discovery-spi. E en xeral, en comparación co que era antes, o protocolo resultou ser bastante lixeiro e fiable. O suficiente para xestionar calquera situación durante a implantación.
Que pasará despois
Agora sobre os plans. Calquera cambio importante no proxecto Ignite complétase como unha iniciativa de mellora de Ignite, chamada IEP. O redeseño da rede de servizos tamén ten un IEP: co título burlón "Cambio de aceite na rede de servizos". Pero de feito, non cambiamos o aceite do motor, senón todo o motor.
Dividimos as tarefas do IEP en 2 fases. A primeira é unha fase importante, que consiste na reelaboración do protocolo de implantación. Xa está incluído no mestre, podes probar a nova Service Grid, que aparecerá na versión 2.8. A segunda fase inclúe moitas outras tarefas:
- Redistribución en quente
- Versionado do servizo
- Aumento da tolerancia a fallos
- Cliente lixeiro
- Ferramentas de seguimento e cálculo de varias métricas
Por último, podemos asesorarte sobre Service Grid para construír sistemas tolerantes a fallos e de alta dispoñibilidade. Tamén vos invitamos a visitarnos en и comparte a túa experiencia. A túa experiencia é realmente importante para a comunidade; axudarache a comprender cara a onde te queres mover e como desenvolver o compoñente no futuro.
Fonte: www.habr.com
