

Ola! Chámome Alexey Pyankov e son desenvolvedor en Sportmaster. Contei como comezou o traballo na páxina web de Sportmaster en 2012, que iniciativas conseguimos levar a cabo e, pola contra, con que dificultades nos atopamos.
Hoxe gustaríame compartir as miñas reflexións sobre outro tema: a elección dun sistema de caché para o backend Java do panel de administración do sitio web. Este tema ten un significado especial para min: aínda que só tivo lugar durante dous meses, pasamos eses 60 días traballando de 12 a 16 horas ao día, sen un só día libre. Nunca pensei nin imaxinei que fose posible traballar tanto.
Polo tanto, divido o texto en dúas partes para evitar abrumarvos. De feito, a primeira parte será moi lixeira: preparación, introdución e algunhas consideracións sobre o almacenamento en caché. Se xa sodes desenvolvedores con experiencia ou traballastes con cachés, é probable que non haxa nada novo neste artigo desde un punto de vista técnico. Non obstante, para un desenvolvedor júnior, esta breve descrición xeral pode axudarvos a orientarvos na dirección correcta se vos atopades nunha encrucillada.
Cando se lanzou a produción a nova versión do sitio web de Sportmaster, o fluxo de datos era, por dicilo suavemente, inconveniente. As táboas preparadas para a versión anterior do sitio web (Bitrix) serviron de base e tiveron que ser importadas para ETL, actualizadas cun novo aspecto e enriquecidas con varias funcións doutras ducias de sistemas. Para que unha nova imaxe ou descrición dun produto aparecese no sitio web, era necesario esperar ata o día seguinte: as actualizacións só estaban dispoñibles pola noite, unha vez ao día.
Ao principio, as primeiras semanas de produción foron tan abrumadoras que tales inconvenientes para os xestores de contidos foron un asunto menor. Pero unha vez que todo se acougou, o desenvolvemento do proxecto continuou: uns meses despois, a principios de 2015, comezamos a desenvolver activamente o panel de administración. En 2015 e 2016, todo ía ben, lanzabamos regularmente, o panel de administración abarcaba cada vez máis o proceso de preparación de datos e estabamos a prepararnos para que o noso equipo recibise en breve a tarefa máis importante e complexa: o contorno do produto (a preparación e o mantemento completos dos datos de todos os produtos). Pero no verán de 2017, xusto antes do lanzamento do contorno do produto, o proxecto atopouse nunha situación moi difícil, concretamente debido a problemas de almacenamento en caché. Quero falar deste episodio na segunda parte desta publicación en dúas partes.
Pero nesta publicación, comezarei dende lonxe, compartindo algunhas reflexións e ideas sobre o almacenamento en caché que serían un bo paso a ter en conta antes de emprender un proxecto grande.
Cando xorde o problema da caché
A tarefa de almacenar en caché non xorde por casualidade. Nós, os desenvolvedores, escribimos un produto de software e queremos que teña demanda. Se o produto ten demanda e éxito, chegan usuarios. E cada vez máis. E despois hai tantos usuarios, e o produto convértese en algo moi cargado.
Nas primeiras etapas, non pensamos na optimización do código nin no rendemento. O principal é a funcionalidade, o despregamento rápido dun proxecto piloto e a proba de hipóteses. E se a carga aumenta, actualizamos o hardware. Incrementámola en dúas, tres, cinco ou incluso dez veces. Neste punto, as finanzas non permiten máis. E cantas veces crecerá o número de usuarios? Non será de 2, 5 ou 10 veces, pero se temos éxito, multiplicarase por 100 ou 1000, mesmo por 100 10. Polo tanto, tarde ou cedo, teremos que abordar a optimización.
Digamos que unha sección de código (chamémoslle función) tarda un tempo excesivamente longo en executarse e queremos reducir o seu tempo de execución. Esta función podería estar accedendo a unha base de datos ou executando algunha lóxica complexa; o importante é que tarda moito tempo. Canto podemos reducir o tempo de execución? En definitiva, podemos reducilo a cero e nada máis. Entón, como podemos reducir o tempo de execución a cero? A resposta: eliminar a execución por completo. No seu lugar, devolver o resultado inmediatamente. E como podemos atopar o resultado? A resposta é calculalo ou buscalo nalgún lugar. Calculalo leva moito tempo. E buscalo significa, por exemplo, lembrar o resultado que a función devolveu a última vez que se chamou cos mesmos parámetros.
Noutras palabras, a implementación da función non é importante para nós. Abonda con saber de que parámetros depende o resultado. Entón, se os valores dos parámetros se representan como un obxecto que se pode usar como clave nalgún almacenamento, podemos almacenar o resultado do cálculo e lelo a próxima vez que accedamos a el. Se estas escrituras e lecturas do resultado son máis rápidas que a execución da función, conseguimos unha ganancia de velocidade. A ganancia pode chegar a 100, 1000 ou incluso 100 000 veces (10^5 é unha excepción, pero é totalmente posible no caso dunha base de datos significativamente atrasada).
Requisitos básicos para un sistema de caché
O primeiro requisito para un sistema de caché é unha velocidade de lectura rápida e, en menor medida, unha velocidade de escritura. Isto é certo, pero só ata que despreguemos o sistema en produción.
Imaxinemos un caso así.
Digamos que xa proporcionamos o hardware para xestionar a carga actual e que agora estamos implementando gradualmente o almacenamento en caché. O número de usuarios medra lixeiramente, a carga aumenta, polo que engadimos un pouco de caché, axustando cousas aquí e alá. Isto continúa durante un tempo, ata que as funcións pesadas practicamente xa non se chaman: toda a carga corre a cargo da caché. O número de usuarios aumentou por un factor de N durante este tempo.
E aínda que o espazo inicial para o hardware podería ser de 2 a 5 veces maior, usando a caché poderiamos aumentar o rendemento por un factor de 10, ou na mellor das hipóteses, 100 veces, e nalgúns casos, quizais incluso 1000 veces. Noutras palabras, co mesmo hardware, estamos a procesar 100 veces máis solicitudes. Xenial, merecemos unha bonificación!
Pero entón, un bo día, por casualidade, o sistema fallou e a caché fallou. Non é para tanto: despois de todo, a caché foi escollida en función do requisito de "altas velocidades de lectura e escritura, nada máis importa".
Tiñamos de 2 a 5 veces máis espazo para o hardware en comparación coa carga inicial, pero a carga aumentou de 10 a 100 veces durante ese tempo. Usando a caché, eliminamos as chamadas a funcións pesadas e, por iso, todo funcionou ben. Pero agora, sen a caché, canto se ralentizará o noso sistema? Que pasará? O sistema fallará.
Mesmo se a nosa caché non se bloqueou, senón que só se limpou durante un tempo, terá que quentala, o que levará algún tempo. E durante este tempo, a carga principal recaerá na funcionalidade.
Conclusión: Os proxectos de produción con alta carga requiren un sistema de caché non só para proporcionar altas velocidades de lectura e escritura, senón tamén integridade dos datos e resiliencia ante fallos.
A agonía da elección
Para o proxecto co panel de administración, a elección foi a seguinte: instalamos primeiro Hazelcast, xa que xa estabamos familiarizados con el pola nosa experiencia co sitio web principal. Non obstante, esta resultou ser unha mala elección aquí: co noso perfil de carga de traballo, Hazelcast non só era lento, senón terriblemente lento. E nese momento, xa nos comprometéramos co prazo de produción.
Alerta de spoiler: Na segunda parte contareivos exactamente como se desenvolveron as circunstancias que nos permitiron perder unha oportunidade tan grande e acabar nesta situación tensa e estresante, tanto como chegamos alí como como saímos. Pero, por agora, só direi que foi incriblemente estresante, e "pensar... dalgún xeito, é simplemente axitar a botella". "Axitar a botella" tamén é un spoiler; máis sobre iso máis tarde.
O que fixemos:
- Estamos a compilar unha lista de todos os sistemas suxeridos por Google e StackOverflow. Pouco máis de 30
- Escribimos probas cunha carga de traballo típica para a produción. Para iso, rexistramos os datos que fluían polo sistema no ambiente de produción, unha especie de rastreador de datos que non estaban na rede, senón dentro do sistema. Estes datos foron exactamente os que executamos nas probas.
- Todo o equipo traballa conxuntamente, cada un seleccionando o seguinte sistema da lista, configurándoo e executando probas. Se falla a proba ou non pode xestionar a carga, descartámolo e pasamos ao seguinte da liña.
- No sistema 17, ficou claro que todo era desesperanzador. Abonda de axitar a botella; hora de pensar seriamente.
Pero esta é unha opción cando necesitas escoller un sistema que "pase a velocidade" en probas preparadas con antelación. Pero que pasa se aínda non existen tales probas e queres escoller rapidamente?
Simulemos un escenario deste tipo (é difícil imaxinar que un desenvolvedor de nivel medio ou superior viva nun baleiro e, no momento de escoller, aínda non teña formulado unha preferencia sobre que produto probar primeiro; polo tanto, o razoamento posterior é máis teórico/filosófico/sobre un júnior).
Unha vez definidos os nosos requisitos, imos comezar a escoller unha solución lista para usar. Para que reinventar a roda? Escolleremos un sistema de caché xa feito.
Se estás a comezar e só buscas en Google, a orde variará, pero en xeral, as pautas serán as seguintes. Primeiro, atoparás Redis; é amplamente coñecido. Despois aprenderás sobre EhCache, o sistema máis antigo e probado. A continuación, lerás sobre Tarantool, un desenvolvemento doméstico cun aspecto único na súa solución. E tamén Ignite, porque actualmente está a experimentar un auxe de popularidade e conta co apoio de SberTech. Finalmente, está Hazelcast, porque se menciona a miúdo no mundo empresarial entre as grandes empresas.
Esta lista non é exhaustiva; hai ducias de sistemas. Só engadiremos un. Someteremos os cinco sistemas escollidos a un "concurso de beleza" e realizaremos un proceso de selección. Quen gañará?
Redis
Leamos o que escriben na páxina web oficial.
— un proxecto de código aberto. Ofrece almacenamento de datos na memoria, persistencia en disco, particionamento automático, alta dispoñibilidade e recuperación de fallos de rede.
Parece que todo vai xenial, podes seguir adiante e deixalo pasar: fai todo o que necesitas. Pero botemos unha ollada aos outros candidatos, só por diversión.
EhCache
— "a caché máis usada para Java" (traducido do sitio web oficial). Tamén é de código aberto. E aquí decatámonos de que Redis non é para Java, senón unha caché de propósito xeral e necesítase un envoltorio para interactuar con ela. Non obstante, EhCache sería máis cómodo. Que máis promete o sistema? Fiabilidade, rendemento probado e funcionalidade completa. E tamén é a máis usada. E almacena na caché terabytes de datos.
Esquecín Redis, estou listo para escoller EhCache.
Pero un sentimento de patriotismo empúxame a ver o que ten de bo Tarantool.
Tarantool
— está etiquetado como "Plataforma de integración de datos en tempo real". Parece moi complicado, polo que lemos a páxina en detalle e atopamos unha afirmación audaz: "Almacena o 100 % dos datos na RAM". Isto debería suscitar algunhas preguntas, xa que pode haber moitos máis datos que memoria. A implicación aquí é que Tarantool non serializa os datos da memoria ao disco. En cambio, usa funcións de sistema de baixo nivel, onde a memoria simplemente se mapea ao sistema de ficheiros, o que ten un rendemento de E/S moi bo. En xeral, é unha implementación marabillosa e ben deseñada.
Vexamos as implementacións: a rede troncal corporativa de Mail.ru, Avito, Beeline, Megafon, Alfa-Bank, Gazprom...
Se tiña algunha dúbida sobre Tarantool, o caso da implementación de Mastercard é a gota que colmou o vaso. Vou optar por Tarantool.
Pero aínda así...
Inflamar
...hai máis , anunciada como unha "plataforma de computación na memoria... velocidades na memoria en petabytes de datos". Tamén conta con moitas vantaxes: unha caché distribuída na memoria, o almacenamento e a caché de clave-valor máis rápidos, escalabilidade horizontal, alta dispoñibilidade e forte integridade. En resumo, resulta que Ignite é o máis rápido.
Implementacións: Sberbank, American Airlines, Yahoo! Xapón. E entón souben que Ignite non só se implementara en Sberbank, senón que o equipo de SberTech estaba enviando á súa xente ao equipo de Ignite para refinar o produto. Isto cativoume por completo e estaba listo para encargarme de Ignite.
Non está completamente claro por que, miro o quinto punto.
avellana
Vou ao sitio web , Estou lendo. E resulta que a solución de caché distribuída máis rápida é Hazelcast. É ordes de magnitude máis rápida que todas as outras solucións e é a líder no espazo da grella de datos na memoria. Neste contexto, elixir calquera outra cousa sería unha falta de respecto. Tamén usa almacenamento de datos redundante para garantir o funcionamento continuo do clúster sen perda de datos.
De acordo, estou listo para levarme a Hazelcast.
Comparación
Pero se o observamos con atención, os cinco candidatos están tan ben merecidos que cada un deles é o mellor. Como se escolle? Podemos ver cal é o máis popular, buscar comparacións e a dor de cabeza desaparecerá.
Atopamos tales , escollemos os nosos 5 sistemas.
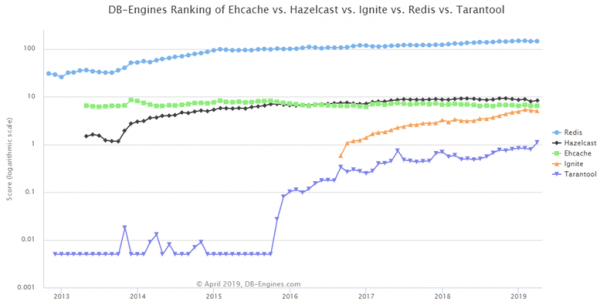
Aquí están ordenados: Redis está no primeiro posto, Hazelcast en segundo lugar, Tarantool e Ignite están a gañar popularidade, EhCache segue como estaba.
Pero vexamos : ligazóns a sitios web, interese xeral no sistema, ofertas de traballo... xenial! Entón, cando o meu sistema falla, direi: "Non, é fiable! Hai moitas ofertas de traballo...". Unha comparación tan simple non servirá.
Todos estes sistemas non son só sistemas de caché. Teñen moita máis funcionalidade, incluída a capacidade de transferir datos ao cliente para o seu procesamento en lugar de simplemente transferilos ao servidor. O código que se debe executar nos datos envíase ao servidor, execútase alí e devólvese o resultado. E non adoitan considerarse como un sistema de caché independente.
De acordo, non nos rendamos. Busquemos unha comparación directa dos sistemas. Tomemos as dúas mellores opcións: Redis e Hazelcast. Interésanos a velocidade, polo que os compararemos usando esa métrica.
Hz fronte a Redis
Atopamos isto :
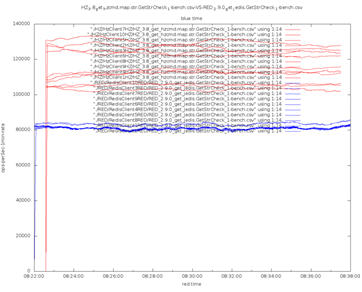
O azul é Redis, o vermello é Hazelcast. Hazelcast gaña en todos os ámbitos, e por unha boa razón: ten varios fíos e está moi optimizado, con cada fío traballando na súa propia partición, o que elimina os bloqueos. Redis, pola contra, ten un só fío e non se beneficia das CPU multinúcleo modernas. Hazelcast usa E/S asíncrona, mentres que Redis-Jedis usa sockets de bloqueo. Finalmente, Hazelcast usa un protocolo binario, mentres que Redis está orientado a texto, o que significa que é ineficiente.
Por se acaso, recorramos a outra fonte de comparación. Que nos mostrará?
Redis fronte a Hz
Unha cousa máis :
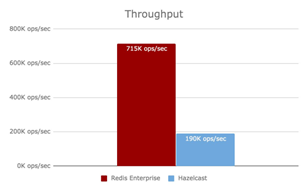
Aquí, ocorre o contrario: a cor vermella é Redis. Isto significa que Redis supera a Hazelcast en termos de rendemento. Na primeira comparación, gañou Hazelcast, mentres que na segunda, gañou Redis. Explicaron con moita precisión por que gañou Hazelcast na comparación anterior.
Resulta que o primeiro resultado estaba manipulado: Redis estaba incluído no paquete básico, mentres que Hazelcast estaba personalizado para o caso de proba. Entón, en primeiro lugar, non podemos confiar en ninguén e, en segundo lugar, unha vez que finalmente escollemos un sistema, aínda temos que configuralo correctamente. Estes axustes inclúen ducias, case centos, de parámetros.
Axita a botella
E podo explicar todo o proceso que acabamos de completar coa metáfora de "axitar unha botella". É dicir, non necesitas programar agora; o máis importante agora é ser capaz de ler Stack Overflow. E teño un profesional no meu equipo que fai exactamente iso en momentos críticos.
Que fai? Ve unha cousa rota, ve un rastrexo de pila, colle algunhas palabras dela (que son exactamente as da súa experiencia no programa), búscaa en Google e atopa Stack Overflow entre as respostas. Sen ler nin pensar, entre as respostas á pregunta, escolle algo que se asemella máis a unha suxestión para "facer isto e aquilo" (escoller tal resposta é o seu talento, xa que non sempre é a resposta con máis gústames), aplícao, comproba: se algo cambiou, entón xenial. Se nada cambiou, revertémolo. E repetimos o inicio-comprobación-busca. E desta forma intuitiva, consegue que o código funcione despois dun tempo. Non sabe por que, non sabe o que fixo, non pode explicalo. Pero! Isto funciona. E "o lume apagouse". Agora descubrimos o que fixemos. Cando o programa funciona, é unha orde de magnitude máis fácil. E aforra moito tempo.
Este método explícase moi ben co seguinte exemplo.
Noutro tempo era moi popular construír un veleiro nunha botella. Non obstante, o veleiro é grande e fráxil, e o pescozo da botella é tan estreito que non se pode espremer cara a dentro. Como se constrúe un?

Existe un método deste tipo, moi rápido e moi eficaz.
O barco está feito dun montón de cousas pequenas: paus, corda, velas, cola. Metemos todo isto na botella.
Collemos a botella coas dúas mans e comezamos a axitala. Axitámola e axitámola. E normalmente, por suposto, resulta unha completa merda. Pero ás veces. Ás veces resulta ser un barco! Ou mellor dito, algo que parece un barco.
Sinalámoslle isto a alguén: "Seryoga, vés!?" E, de feito, desde lonxe, parece un barco. Pero non podemos deixar que vaia máis lonxe.
Hai outro xeito. Os tipos máis avanzados, como os hackers, úsano.
Dáslle unha tarefa a este tipo, faina e logo marcha. E mira... está case feito. Pero despois dun tempo, cando necesitas refinar o código, comezan a suceder todo tipo de cousas por el... É bo que conseguise fuxir lonxe. Estes son o tipo de tipos que, usando unha botella como exemplo, farían isto: mira, onde está o fondo, o vidro dóbrase. E non está do todo claro se é transparente ou non. Entón, os "hackers" cortan o fondo, insiren un barco alí, logo volven pegar o fondo, e é coma se estivese destinado a ser así.
Desde unha perspectiva de resolución de problemas, todo parece correcto. Pero poñendo o exemplo dos barcos: para que construír este barco? Quen o necesita, de todos os xeitos? Non serve para nada. Estes barcos adoitan ser agasallos para persoas de moi alto rango, que os colocan nun andel enriba delas como símbolo, como sinal. Entón, que pasaría se unha persoa así, un executivo empresarial importante ou un funcionario de alto rango, tivese unha peza así, co pescozo serrado, colgada como unha bandeira? Sería mellor que nunca o soubesen. Entón, como fabrican finalmente estes barcos que se lle poden regalar a unha persoa importante?
A única parte fundamental que realmente non se pode manipular é o casco. O casco do barco encaixa perfectamente no pescozo da botella, mentres que o barco móntase fóra da botella. Pero non se trata só de montar un barco; é unha verdadeira obra mestra. Engádenselles palancas especiais ás pezas compoñentes, o que permite levantalas máis tarde. Por exemplo, as velas dóbranse, insírense coidadosamente no interior e, a continuación, con pinzas, tíranse e elévanse con gran precisión e exactitude. O resultado é unha obra de arte que se pode regalar con conciencia tranquila e orgullo.
E se queremos que un proxecto teña éxito, debe haber polo menos un xoieiro no equipo. Alguén que se preocupe pola calidade do produto e considere todos os aspectos, sen sacrificar ningún, mesmo en tempos de estrés, cando as circunstancias esixen que o urxente se faga a expensas do importante. Todos os proxectos exitosos que son sostibles e resistiron a proba do tempo baséanse neste principio. Hai algo moi preciso e único neles, algo que aproveita todas as oportunidades dispoñibles. No exemplo do barco nunha botella, o casco pasa polo pescozo da botella, xogando co feito de que o casco do barco pasa polo pescozo da botella.
Voltando á tarefa de escoller o noso servidor de caché, como se podería aplicar esta estratexia? Propoño esta estratexia para escoller entre todos os sistemas dispoñibles: en lugar de axitar a botella e escoller, deberiamos analizar o que teñen en común e que debemos buscar ao escoller un sistema.
Onde buscar un pescozo de botella
Intentemos non axitar a botella nin repasar todo un por un, senón considerar que desafíos xurdirían se deseñásemos nós mesmos un sistema deste tipo, adaptado ás nosas propias necesidades. Non montaremos unha bicicleta, por suposto, pero usaremos este diagrama para axudarnos a comprender que buscar nas descricións dos produtos. Debuxemos o seguinte diagrama.
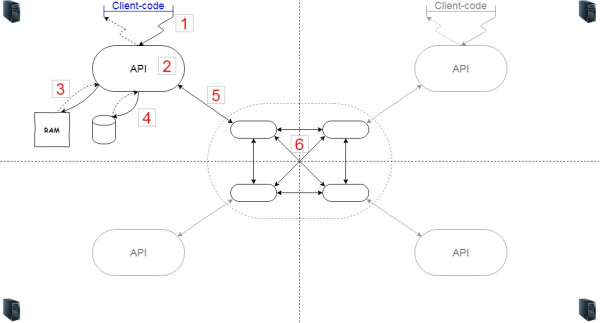
Se o sistema é distribuído, teremos varios servidores (6). Digamos catro (é conveniente colocalos na imaxe, pero por suposto, podería haber tantos como queiras). Se os servidores están en nodos diferentes, todos executan algún código que garante que estes nodos formen un clúster e, en caso de interrupción, se conecten e recoñezan entre si.
Tamén precisamos algo de lóxica de caché (2), que é a que realmente xestiona o almacenamento en caché. Os clientes interactúan con este código a través dunha API. O código do cliente (1) pode estar dentro da mesma JVM ou acceder a el a través da rede. A lóxica implementada nel decide que obxectos manter na caché e cales descartar. Usamos memoria (3) para almacenar a caché, pero se é necesario, tamén podemos almacenar algúns datos no disco (4).
Vexamos onde se producirá a carga. Esencialmente, cada frecha e cada nodo estarán suxeitos a carga. En primeiro lugar, entre o código do cliente e a API, se se trata de interacción de rede, a caída pode ser bastante notable. En segundo lugar, dentro da propia API, se nos excedemos con lóxica complexa, podemos afectar á CPU. Sería bo que a lóxica non malgastase memoria innecesariamente. E despois está a interacción do sistema de ficheiros, normalmente, serialización/restauración e escritura/lectura.
A continuación vén a interacción co clúster. O máis probable é que estea no mesmo sistema, pero podería estar separado. Aquí tamén debemos ter en conta a transferencia de datos a el, a velocidade de serialización dos datos e as interaccións dentro do clúster.
Agora, por unha banda, podemos imaxinar as rodas xirando no sistema de caché ao procesar solicitudes do noso código e, por outra banda, podemos estimar que tipo e cantas solicitudes xerará o noso código a este sistema. Isto é suficiente para tomar unha decisión máis ou menos sobria: elixir un sistema que mellor se adapte ao noso caso de uso.
avellana
Vexamos como se aplica esta descomposición á nosa lista. Por exemplo, Hazelcast.
Para introducir/obter datos de Hazelcast, o código do cliente chama (1) á API. Hz permíteche executar o servidor como integrado, nese caso a chamada á API é unha chamada a un método dentro da JVM, que é gratuíta.
Para que a lóxica de (2) funcione, Hz depende do hash da matriz de bytes da clave serializada, o que significa que a clave se serializará en calquera caso. Esta é unha sobrecarga inevitable para Hz.
As estratexias de desafiuzamento están ben implementadas, pero para casos especiais, podes engadir as túas propias. Non tes que preocuparte por esa parte.
O almacenamento (4) pódese conectar. Excelente. A interacción (5) para sistemas integrados pode considerarse instantánea. O intercambio de datos entre os nodos do clúster (6): si, existe. Isto contribúe á tolerancia a fallos en detrimento da velocidade. A función de caché próxima a Hz axuda a reducir os custos: os datos recibidos doutros nodos do clúster almacenaranse na caché.
Que se pode facer en tales condicións para aumentar a velocidade?
Por exemplo, para evitar a serialización de claves en (2), engade outra caché enriba de Hazelcast para os datos máis quentes. Sportmaster escolleu Caffeine para este propósito.
Para o axuste de nivel (6), Hz ofrece dous tipos de almacenamento: IMap e ReplicatedMap.
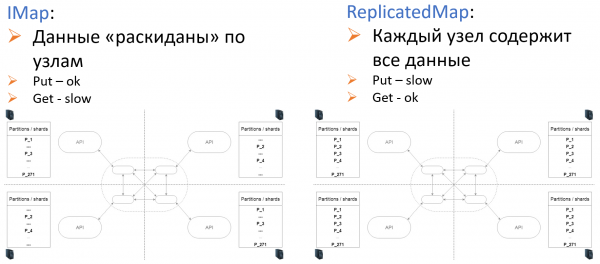
Vale a pena mencionar como Hazelcast entrou no conxunto de tecnoloxías de Sportmaster.
En 2012, cando estabamos traballando no primeiro prototipo do futuro sitio web, Hazelcast foi a primeira ligazón devolvida por un motor de busca. Conectamos inmediatamente: quedamos enganchados polo feito de que só dúas horas despois de instalar Hz no sistema, xa funcionaba. E funcionaba ben. Ao final do día, rematamos de escribir unhas cantas probas e quedamos encantados. E esta reserva de enerxía foi suficiente para superar as sorpresas que Hz nos deparou co paso do tempo. Agora o equipo de Sportmaster non ten razóns para renunciar a Hazelcast.
Pero argumentos como "a primeira ligazón no motor de busca" e "montar rapidamente HelloWorld" son, por suposto, excepcións e peculiaridades do momento en que se tomou a decisión. As probas reais para o sistema escollido comezan co lanzamento da produción, e é esta etapa á que paga a pena prestar atención ao elixir calquera sistema, incluída unha caché. De feito, no noso caso, poderiamos dicir que escollemos Hazelcast por casualidade, pero máis tarde resultou ser a elección correcta.
Para a produción, entre os factores moito máis importantes inclúense a monitorización, a conmutación por erro en nodos individuais, a replicación de datos e os custos de escalado. Isto significa que paga a pena prestar atención aos desafíos que xorden durante o mantemento do sistema: cando a carga é decenas de veces maior do previsto, cando cargamos accidentalmente algo incorrecto na localización incorrecta, cando necesitamos despregar unha nova versión do código, substituír datos e facelo sen problemas sen que os clientes se decaten.
Para todos estes requisitos, Hazelcast certamente cumpre os requisitos.
Continuará
Pero Hazelcast non é a panacea. En 2017, escollemos Hazelcast para a caché do noso panel de administración simplemente baseándonos nunha impresión positiva da experiencia previa. Isto xogou un papel fundamental nunha broma moi cruel, que nos meteu nunha situación difícil e da que "heroicamente" tardamos 60 días en recuperarnos. Pero máis sobre iso na seguinte parte.
Ata entón… Feliz Novo Código!
Fonte: www.habr.com
