


Ola, Habr! Son Artem Karamyshev, xefe do equipo de administración do sistema . O ano pasado tivemos moitos lanzamentos de produtos novos. Queriamos garantir que os servizos API fosen facilmente escalables, tolerantes a fallos e preparados para un rápido crecemento da carga de usuarios. A nosa plataforma está implementada en OpenStack e quero dicirche que problemas de tolerancia a fallos de compoñentes tivemos que resolver para conseguir un sistema tolerante a fallos. Creo que isto será interesante para aqueles que tamén desenvolven produtos en OpenStack.
A tolerancia global a fallos dunha plataforma consiste na resistencia dos seus compoñentes. Así, pouco a pouco iremos percorrendo todos os niveis nos que identificamos os riscos e os pechamos.
Versión en vídeo desta historia, cuxa fonte principal foi un informe na conferencia Uptime day 4, organizada por , podes ver .
Resiliencia da arquitectura física
A parte pública da nube MCS está baseada agora en dous centros de datos Tier III, entre eles existe a súa propia fibra escura, reservada a nivel físico por diferentes vías, cun rendemento de 200 Gbit/s. O nivel III proporciona o nivel necesario de tolerancia a fallos para a infraestrutura física.
A fibra escura está reservada tanto a nivel físico como lóxico. O proceso de reserva de canles foi iterativo, xurdiron problemas e melloramos constantemente a comunicación entre os centros de datos.
Por exemplo, non hai moito tempo, mentres traballaba nun pozo preto dun dos centros de datos, unha escavadora rompeu un tubo, e dentro deste tubo había tanto un cable óptico principal como outro de respaldo. A nosa canle de comunicación tolerante a fallos co centro de datos resultou ser vulnerable nun momento, no pozo. En consecuencia, perdemos parte da infraestrutura. Tiramos conclusións e tomamos unha serie de accións, incluída a instalación de ópticas adicionais no pozo adxacente.
Nos centros de datos hai puntos de presenza de provedores de comunicación aos que transmitimos os nosos prefixos vía BGP. Para cada dirección de rede, selecciónase a mellor métrica, o que permite proporcionar a diferentes clientes a mellor calidade de conexión. Se a comunicación a través dun provedor falla, reconstruímos o noso enrutamento a través dos provedores dispoñibles.
Se un provedor falla, cambiamos automaticamente ao seguinte. No caso de producirse un fallo nun dos centros de datos, dispoñemos dunha copia espellada dos nosos servizos no segundo centro de datos, que asumen toda a carga.
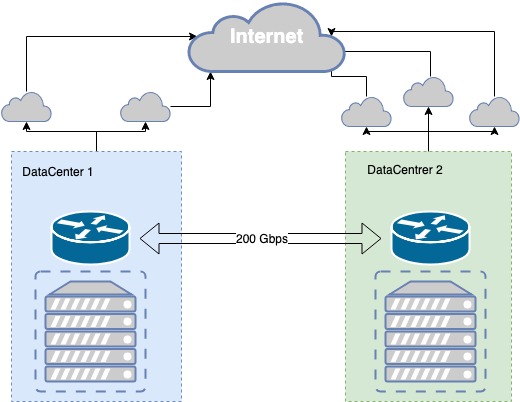
Resiliencia da infraestrutura física
O que usamos para a tolerancia a fallos a nivel de aplicación
O noso servizo está construído sobre unha serie de compoñentes de código aberto.
ExaBGP é un servizo que implementa unha serie de funcións utilizando o protocolo de enrutamento dinámico baseado en BGP. Usámolo activamente para anunciar os nosos enderezos IP na lista branca a través dos cales os usuarios acceden á API.
HAProxy é un equilibrador de alta carga que permite configurar regras de equilibrio de tráfico moi flexibles en diferentes niveis do modelo OSI. Usámolo para equilibrar todos os servizos: bases de datos, corredores de mensaxes, servizos API, servizos web, os nosos proxectos internos: todo está detrás de HAProxy.
Aplicación API — unha aplicación web escrita en python, coa que o usuario xestiona a súa infraestrutura e o seu servizo.
Solicitude do traballador (en diante, simplemente traballador): nos servizos OpenStack, este é un daemon de infraestrutura que che permite transmitir comandos da API á infraestrutura. Por exemplo, a creación do disco prodúcese no traballador e a solicitude de creación prodúcese na API da aplicación.
Arquitectura de aplicación estándar OpenStack
A maioría dos servizos que se desenvolven para OpenStack intentan seguir un único paradigma. Un servizo normalmente consta de 2 partes: API e traballadores (executores de backend). Como regra xeral, unha API é unha aplicación WSGI en python, que se lanza como un proceso independente (daemon) ou ben usando un servidor web Nginx ou Apache preparado. A API procesa a solicitude do usuario e pasa instrucións adicionais á aplicación do traballador para a súa execución. A transferencia realízase mediante un intermediario de mensaxes, normalmente RabbitMQ, os demais son pouco compatibles. Cando as mensaxes chegan ao corredor, son procesadas polos traballadores e, se é necesario, devolven unha resposta.
Este paradigma implica puntos comúns illados de falla: RabbitMQ e a base de datos. Pero RabbitMQ está illado nun servizo e, en teoría, pode ser individual para cada servizo. Polo tanto, en MCS separamos estes servizos o máximo posible; para cada proxecto individual creamos unha base de datos separada, un RabbitMQ separado. Este enfoque é bo porque en caso de accidente nalgúns puntos vulnerables non se avaria todo o servizo, senón só unha parte.
O número de aplicacións dos traballadores é ilimitado, polo que a API pode escalar facilmente horizontalmente detrás dos equilibradores para aumentar o rendemento e a tolerancia a fallos.
Algúns servizos requiren coordinación dentro do servizo cando se producen operacións secuenciais complexas entre as API e os traballadores. Neste caso, utilízase un único centro de coordinación, un sistema de clúster como Redis, Memcache, etcd, que permite que un traballador lle diga a outro que se lle asigna esta tarefa (“por favor, non a tome”). Usamos etcd. Como regra xeral, os traballadores comunícanse activamente coa base de datos, escriben e len información desde alí. Usamos mariadb como base de datos, que está situada nun clúster multimaster.
Este servizo único clásico está organizado dun xeito xeralmente aceptado para OpenStack. Pódese considerar como un sistema pechado, para o que os métodos de escalado e tolerancia a fallos son bastante obvios. Por exemplo, para a tolerancia a fallos da API, abonda con poñer un equilibrador diante deles. A escala de traballadores conséguese aumentando o seu número.
O punto débil de todo o esquema é RabbitMQ e MariaDB. A súa arquitectura merece un artigo aparte. Neste artigo quero centrarme na tolerancia a fallos da API.
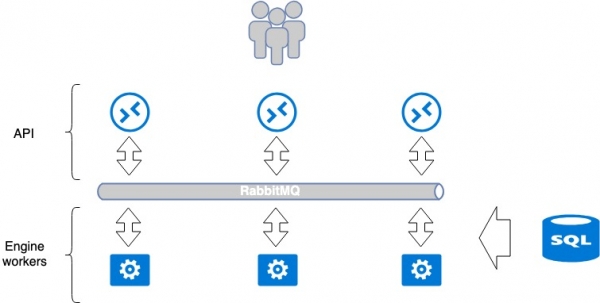
Arquitectura de aplicacións Openstack. Equilibrio e tolerancia a fallos da plataforma cloud
Facendo que o equilibrador HAProxy sexa tolerante a fallos usando ExaBGP
Para que as nosas API sexan escalables, rápidas e tolerantes a fallos, poñemos un equilibrador de carga diante delas. Escollemos HAProxy. Na miña opinión, ten todas as características necesarias para a nosa tarefa: equilibrio en varios niveis OSI, unha interface de xestión, flexibilidade e escalabilidade, gran cantidade de métodos de equilibrio, soporte para táboas de sesións.
O primeiro problema que había que resolver era a tolerancia a fallos do propio equilibrador. Simplemente instalar un equilibrador tamén crea un punto de falla: o equilibrador rompe e o servizo falla. Para evitar que isto suceda, usamos HAProxy xunto con ExaBGP.
ExaBGP permítelle implementar un mecanismo para comprobar o estado dun servizo. Usamos este mecanismo para comprobar a funcionalidade de HAProxy e, en caso de problemas, desactivar o servizo HAProxy de BGP.
Esquema ExaBGP+HAProxy
- Instalamos o software necesario, ExaBGP e HAProxy, en tres servidores.
- Creamos unha interface de loopback en cada servidor.
- Nos tres servidores asignamos o mesmo enderezo IP branco a esta interface.
- Un enderezo IP branco anúnciase a Internet a través de ExaBGP.
A tolerancia a fallos conséguese anunciando o mesmo enderezo IP dos tres servidores. Desde o punto de vista da rede, o mesmo enderezo é accesible desde tres saltos seguintes diferentes. O router ve tres rutas idénticas, selecciona a maior prioridade delas en función da súa propia métrica (esta é normalmente a mesma opción) e o tráfico vai só a un dos servidores.
En caso de problemas co funcionamento de HAProxy ou un fallo do servidor, ExaBGP deixa de anunciar a ruta e o tráfico cambia sen problemas a outro servidor.
Así, conseguimos a tolerancia a fallos do equilibrador.
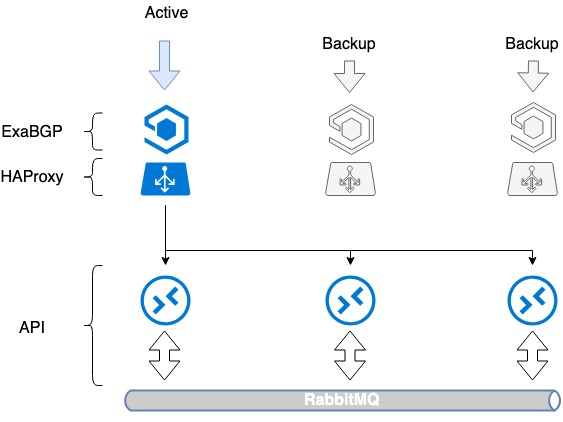
Tolerancia a fallos dos equilibradores HAProxy
O esquema resultou ser imperfecto: aprendemos a reservar HAProxy, pero non aprendemos a distribuír a carga dentro dos servizos. Polo tanto, ampliamos un pouco este esquema: pasamos ao equilibrio entre varios enderezos IP brancos.
Equilibrio baseado en DNS máis BGP
O problema do equilibrio de carga para o noso HAProxy segue sen resolverse. Non obstante, pódese resolver de forma sinxela, como fixemos aquí.
Para equilibrar tres servidores necesitarás 3 enderezos IP brancos e un bo DNS antigo. Cada un destes enderezos determínase na interface de loopback de cada HAProxy e anúnciase en Internet.
En OpenStack, para xestionar os recursos, utilízase un directorio de servizos, que especifica a API do punto final dun servizo concreto. Neste directorio rexistramos un nome de dominio - public.infra.mail.ru, que se resolve mediante DNS mediante tres enderezos IP diferentes. Como resultado, obtemos a distribución de carga entre tres enderezos a través de DNS.
Pero dado que ao anunciar enderezos IP brancos non controlamos as prioridades de selección do servidor, isto aínda non está equilibrado. Normalmente, só se seleccionará un servidor en función da antigüidade do enderezo IP e os outros dous estarán inactivos porque non se especifican métricas en BGP.
Comezamos a enviar rutas a través de ExaBGP con diferentes métricas. Cada equilibrador anuncia os tres enderezos IP brancos, pero un deles, o principal deste equilibrador, anúnciase coa métrica mínima. Así, mentres os tres equilibradores están en funcionamento, as chamadas ao primeiro enderezo IP van ao primeiro equilibrador, as chamadas ao segundo ao segundo e as chamadas ao terceiro ao terceiro.
Que pasa cando un dos equilibradores cae? Se algún equilibrador falla, o seu enderezo principal aínda se anuncia desde os outros dous e o tráfico redistribuíuse entre eles. Así, dámoslle ao usuario varios enderezos IP á vez a través de DNS. Ao equilibrar por DNS e diferentes métricas, obtemos unha distribución uniforme da carga nos tres equilibradores. E ao mesmo tempo non perdemos a tolerancia ás culpas.
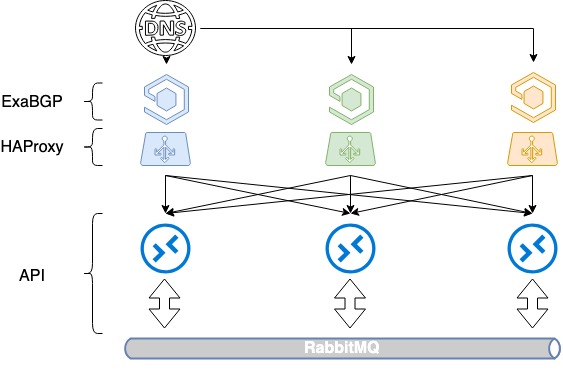
Equilibrio de HAProxy baseado en DNS + BGP
Interacción entre ExaBGP e HAProxy
Entón, implementamos tolerancia a fallos no caso de que o servidor se marche, baseándose en deter o anuncio de rutas. Pero HAProxy pode apagarse por outros motivos distintos dos fallos do servidor: erros de administración, fallos dentro do servizo. Nestes casos tamén queremos eliminar o equilibrador roto debaixo da carga e necesitamos un mecanismo diferente.
Polo tanto, ampliando o esquema anterior, implementamos o latido do corazón entre ExaBGP e HAProxy. Esta é unha implementación de software da interacción entre ExaBGP e HAProxy, cando ExaBGP usa scripts personalizados para comprobar o estado das aplicacións.
Para iso, cómpre configurar un comprobador de saúde na configuración de ExaBGP, que pode comprobar o estado de HAProxy. No noso caso, configuramos o backend de saúde en HAProxy e desde o lado de ExaBGP comprobamos cunha simple solicitude GET. Se o anuncio deixa de producirse, é probable que HAProxy non funcione e non sexa necesario anuncialo.
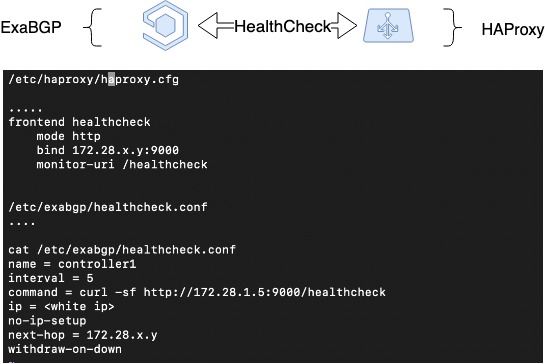
Comprobación de saúde HAProxy
HAProxy Peers: sincronización de sesións
O seguinte foi sincronizar as sesións. Cando se traballa a través de equilibradores distribuídos, é difícil organizar o almacenamento de información sobre as sesións do cliente. Pero HAProxy é un dos poucos equilibradores que pode facelo debido á funcionalidade Peers: a capacidade de transferir táboas de sesión entre diferentes procesos HAProxy.
Existen diferentes métodos de equilibrio: simples como , e estendida, cando se lembra a sesión do cliente, e cada vez que acaba no mesmo servidor que antes. Queriamos implementar a segunda opción.
HAProxy usa stick-tables para gardar sesións do cliente deste mecanismo. Gardan o enderezo IP orixinal do cliente, o enderezo de destino seleccionado (backend) e algunha información de servizo. Normalmente, as táboas de stick úsanse para almacenar un par de IP de orixe + IP de destino, o que é especialmente útil para aplicacións que non poden transferir o contexto da sesión do usuario ao cambiar a outro equilibrador, por exemplo, no modo de equilibrio RoundRobin.
Se se ensina a unha táboa stick a moverse entre diferentes procesos HAProxy (entre os cales se produce o equilibrio), os nosos equilibradores poderán traballar cun grupo de táboas stick. Isto permitirá cambiar a rede do cliente sen problemas se un dos equilibradores falla; o traballo coas sesións do cliente continuará nos mesmos backends que se seleccionaron anteriormente.
Para un correcto funcionamento, debe resolverse o problema do enderezo IP de orixe do equilibrador desde o que se estableceu a sesión. No noso caso, este é un enderezo dinámico na interface de loopback.
O traballo correcto dos compañeiros só se consegue baixo certas condicións. É dicir, os tempos de espera TCP deben ser o suficientemente grandes ou a conmutación debe ser o suficientemente rápida para que a sesión TCP non teña tempo para finalizar. Non obstante, permite unha conmutación sen problemas.
En IaaS temos un servizo construído coa mesma tecnoloxía. Isto , que se chama Octavia. Está baseado en dous procesos HAProxy e inicialmente inclúe soporte para compañeiros. Demostraron ser excelentes neste servizo.
A imaxe mostra esquemáticamente o movemento das táboas de pares entre tres instancias de HAProxy, proponse unha configuración sobre como se pode configurar:
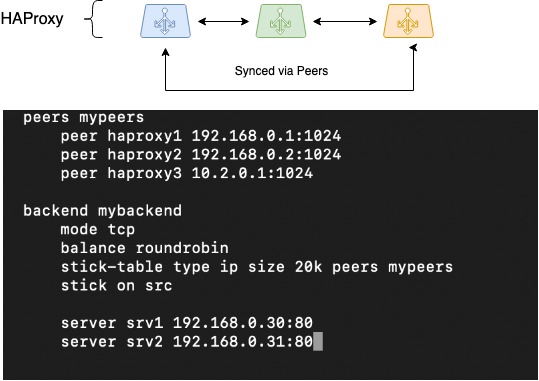
HAProxy Peers (sincronización de sesión)
Se implementas o mesmo esquema, o seu funcionamento debe ser probado coidadosamente. Non é un feito que funcione do mesmo xeito o 100% das veces. Pero polo menos non perderás as táboas stick cando necesites lembrar a IP de orixe do cliente.
Limitar o número de solicitudes simultáneas do mesmo cliente
Calquera servizo que estea dispoñible publicamente, incluídas as nosas API, pode estar suxeito a avalanchas de solicitudes. Os motivos dos mesmos poden ser completamente diferentes, desde erros dos usuarios ata ataques dirixidos. Periódicamente somos DDoSed por enderezos IP. Os clientes adoitan cometer erros nos seus guións e dannos mini-DDoS.
Dun xeito ou doutro, débese proporcionar protección adicional. A solución obvia é limitar o número de solicitudes de API e non perder o tempo da CPU procesando solicitudes maliciosas.
Para implementar tales restricións, utilizamos límites de taxas, organizados en base a HAProxy, utilizando as mesmas táboas de pautas. Configurar límites é bastante sinxelo e permítelle limitar o usuario polo número de solicitudes á API. O algoritmo lembra a IP de orixe desde a que se realizan as solicitudes e limita o número de solicitudes simultáneas dun usuario. Por suposto, calculamos o perfil de carga medio da API para cada servizo e establecemos un límite de ≈ 10 veces este valor. Seguimos vixiando de preto a situación e mantendo o dedo no pulso.
Como se ve isto na práctica? Temos clientes que usan as nosas API de escalado automático todo o tempo. Crean aproximadamente entre dúascentas e trescentas máquinas virtuais pola mañá e elimínanse pola noite. Para OpenStack, a creación dunha máquina virtual, tamén con servizos PaaS, require polo menos 1000 solicitudes de API, xa que a interacción entre servizos tamén se produce a través da API.
Tal transferencia de tarefas provoca unha carga bastante grande. Avaliamos esta carga, recollemos picos diarios, multiplicámolos por dez e este converteuse no noso límite de tarifas. Mantemos o dedo no pulso. Moitas veces vemos bots e escáneres que intentan mirarnos para ver se temos algún script CGA que se poida executar, cortámolos activamente.
Como actualizar o teu código base sen que os usuarios se dean conta
Tamén implementamos tolerancia a fallos a nivel de procesos de implantación de código. É posible que haxa fallos durante os lanzamentos, pero o seu impacto na dispoñibilidade do servizo pódese minimizar.
Actualizamos constantemente os nosos servizos e debemos asegurarnos de que a base de código se actualice sen afectar aos usuarios. Conseguimos resolver este problema utilizando as capacidades de xestión de HAProxy e a implementación de Graceful Shutdown nos nosos servizos.
Para resolver este problema, era necesario garantir o control do equilibrador e a parada "correcta" dos servizos:
- No caso de HAProxy, o control realízase a través dun ficheiro de estatísticas, que é esencialmente un socket e está definido na configuración de HAProxy. Podes enviarlle comandos a través de stdio. Pero a nosa principal ferramenta de control de configuración é ansible, polo que ten un módulo integrado para xestionar HAProxy. Que usamos activamente.
- A maioría dos nosos servizos de API e Engine admiten tecnoloxías de apagado elegantes: cando se apagan, esperan a que se complete a tarefa actual, xa sexa unha solicitude http ou algunha tarefa de servizo. O mesmo acontece co traballador. Coñece todas as tarefas que está a realizar e remata cando o completou con éxito.
Grazas a estes dous puntos, o algoritmo seguro para a nosa implantación ten este aspecto.
- O desenvolvedor ensambla un novo paquete de código (para nós isto é RPM), probano no ambiente de desenvolvemento, probano na fase e déixao no repositorio da fase.
- O desenvolvedor establece a tarefa para a implantación coa descrición máis detallada dos "artefactos": a versión do novo paquete, unha descrición da nova funcionalidade e outros detalles sobre a implantación se é necesario.
- O administrador do sistema comeza a actualización. Lanza o manual de xogos Ansible, que á súa vez fai o seguinte:
- Colle un paquete do repositorio de fase e utilízao para actualizar a versión do paquete no repositorio de produtos.
- Compila unha lista de backends do servizo actualizado.
- Pecha o primeiro servizo que se actualiza en HAProxy e agarda a que rematen de executarse os seus procesos. Grazas ao apagado elegante, estamos seguros de que todas as solicitudes actuais dos clientes se completarán con éxito.
- Despois de que a API e os traballadores estean completamente detidos e HAProxy se desactive, o código actualízase.
- Ansible executa servizos.
- Para cada servizo, tíranse certos "controladores", que realizan probas unitarias nunha serie de probas clave predefinidas. Prodúcese unha comprobación básica do novo código.
- Se non se atoparon erros no paso anterior, o backend está activado.
- Pasemos ao seguinte backend.
- Despois de actualizar todos os backends, lánzanse as probas funcionais. Se faltan, o programador analiza calquera nova funcionalidade que creou.
Isto completa o despregamento.
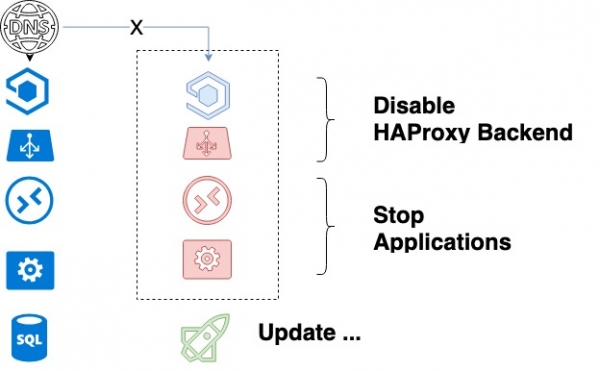
Ciclo de actualización do servizo
Este esquema non funcionaría se non tivésemos unha regra. Apoiamos as versións antigas e novas na batalla. Con antelación, na fase de desenvolvemento do software, establécese que aínda que haxa cambios na base de datos do servizo, non romperán o código anterior. Como resultado, a base de código actualízase gradualmente.
Conclusión
Compartindo os meus propios pensamentos sobre unha arquitectura WEB tolerante a fallos, gustaríame destacar unha vez máis os seus puntos clave:
- tolerancia a fallos físicos;
- tolerancia a fallos de rede (equilibradores, BGP);
- tolerancia a fallos do software utilizado e desenvolvido.
Tempo de actividade estable para todos!
Fonte: www.habr.com
