

Ao buscar R ou Python en Internet, atoparás millóns de artigos e quilómetros de discusións sobre o tema de cal é mellor, máis rápido e máis cómodo para traballar con datos. Pero, por desgraza, todos estes artigos e disputas non son especialmente útiles.

O propósito deste artigo é comparar as técnicas básicas de procesamento de datos nos paquetes máis populares de ambos os idiomas. E axuda aos lectores a dominar rapidamente algo que aínda non saben. Para os que escriben en Python, descobre como facer o mesmo en R e viceversa.
Durante o artigo analizaremos a sintaxe dos paquetes máis populares en R. Estes son os paquetes incluídos na biblioteca tidyversee tamén o paquete data.table. E compara a súa sintaxe con pandas, o paquete de análise de datos máis popular en Python.
Iremos paso a paso por todo o camiño da análise de datos desde a súa carga ata a realización de funcións de xanela analítica usando Python e R.
Contido
Este artigo pódese usar como unha folla de trampas se esqueceu como realizar algunha operación de procesamento de datos nun dos paquetes en consideración.

1.1.
1.2.
1.3.
1.4.
1.5.
1.6.
2.1.
2.2.
2.3.
Se estás interesado na análise de datos, podes atopar o meu и canles. A maior parte do contido está dedicado á linguaxe R.
Principais diferenzas de sintaxe entre R e Python
Para facilitarche o cambio de Python a R, ou viceversa, darei algúns puntos principais aos que debes prestar atención.
Acceso ás funcións do paquete
Unha vez que se carga un paquete en R, non precisa especificar o nome do paquete para acceder ás súas funcións. Na maioría dos casos isto non é común en R, pero é aceptable. Non tes que importar un paquete en absoluto se necesitas unha das súas funcións no teu código, senón que simplemente chamalo especificando o nome do paquete e o nome da función. O separador entre os nomes de paquetes e funcións en R é dous dous puntos. package_name::function_name().
En Python, pola contra, considérase clásico chamar ás funcións dun paquete especificando explícitamente o seu nome. Cando se descarga un paquete, normalmente recibe un nome abreviado, p. pandas normalmente úsase un pseudónimo pd. Accédese a unha función de paquete a través dun punto package_name.function_name().
Asignación
En R, é común usar unha frecha para asignar un valor a un obxecto. obj_name <- value, aínda que se permite un único signo de igual, o único signo de igual en R úsase principalmente para pasar valores aos argumentos das funcións.
En Python, a asignación realízase exclusivamente cun único signo de igual obj_name = value.
Indexación
Aquí tamén hai diferenzas bastante significativas. En R, a indexación comeza en un e inclúe todos os elementos especificados no intervalo resultante,
En Python, a indexación comeza desde cero e o intervalo seleccionado non inclúe o último elemento especificado no índice. Así que deseño x[i:j] en Python non incluirá o elemento j.
Tamén hai diferenzas na indexación negativa, en notación R x[-1] devolverá todos os elementos do vector excepto o último. En Python, unha notación similar devolverá só o último elemento.
Métodos e POO
R implementa OOP ao seu xeito, escribín sobre isto no artigo . En xeral, R é unha linguaxe funcional e todo o que nel está construído sobre funcións. Polo tanto, por exemplo, para os usuarios de Excel, vaia a tydiverse será máis doado que pandas. Aínda que esta pode ser a miña opinión subxectiva.
En resumo, os obxectos en R non teñen métodos (se falamos de clases S3, pero hai outras implementacións de POO que son moito menos habituais). Só hai funcións xeneralizadas que as procesan de forma diferente dependendo da clase do obxecto.
Canalizacións
Quizais este sexa o nome pandas Non será do todo correcto, pero tentarei explicar o significado.
Para non gardar cálculos intermedios e non producir obxectos innecesarios no ambiente de traballo, pode usar unha especie de canalización. Eses. pasar o resultado dun cálculo dunha función a outra e non gardar os resultados intermedios.
Tomemos o seguinte exemplo de código, onde almacenamos cálculos intermedios en obxectos separados:
temp_object <- func1()
temp_object2 <- func2(temp_object )
obj <- func3(temp_object2 )Realizamos 3 operacións secuencialmente e o resultado de cada unha gardouse nun obxecto separado. Pero de feito, non necesitamos estes obxectos intermedios.
Ou aínda peor, pero máis familiar para os usuarios de Excel.
obj <- func3(func2(func1()))Neste caso, non gardamos os resultados do cálculo intermedio, pero ler código con funcións aniñadas é moi inconveniente.
Observaremos varias aproximacións ao procesamento de datos en R, e realizan operacións similares de diferentes xeitos.
Canalizacións na biblioteca tidyverse implementado polo operador %>%.
obj <- func1() %>%
func2() %>%
func3()Así tomamos o resultado do traballo func1() e pásao como primeiro argumento a func2(), entón pasamos o resultado deste cálculo como primeiro argumento func3(). E ao final, escribimos todos os cálculos realizados no obxecto obj <-.
Todo o anterior está mellor ilustrado que as palabras por este meme:

В data.table as cadeas utilízanse de xeito similar.
newDT <- DT[where, select|update|do, by][where, select|update|do, by][where, select|update|do, by]En cada un dos corchetes pódese utilizar o resultado da operación anterior.
В pandas tales operacións están separadas por un punto.
obj = df.fun1().fun2().fun3()Eses. collemos a nosa mesa df e usa o seu método fun1(), despois aplicamos o método ao resultado obtido fun2()despois fun3(). O resultado resultante gárdase nun obxecto obx .
Estruturas de datos
As estruturas de datos en R e Python son similares, pero teñen nomes diferentes.
Descrición
Nome en R
Nome en Python/pandas
Estrutura da táboa
data.frame, data.table, tibble
DataFrame
Lista unidimensional de valores
Vector
Serie en pandas ou lista en puro Python
Estrutura non tabular multinivel
Lista
dicionario (dict)
Veremos algunhas outras características e diferenzas na sintaxe a continuación.
Algunhas palabras sobre os paquetes que usaremos
En primeiro lugar, falarei un pouco sobre os paquetes cos que se familiarizará durante este artigo.
ordenado
Официальный сайт:
biblioteca tidyverse escrito por Hedley Wickham, científico investigador sénior en RStudio. tidyverse consiste nun impresionante conxunto de paquetes que simplifican o procesamento de datos, 5 dos cales están incluídos nas 10 descargas principais do repositorio CRAN.
O núcleo da biblioteca está formado polos seguintes paquetes: ggplot2, dplyr, tidyr, readr, purrr, tibble, stringr, forcats. Cada un destes paquetes está dirixido a resolver un problema específico. Por exemplo dplyr creado para manipulación de datos, tidyr para levar os datos a unha forma ordenada, stringr simplifica o traballo con cordas, e ggplot2 é unha das ferramentas de visualización de datos máis populares.
A vantaxe tidyverse é a sintaxe sinxela e fácil de ler, que en moitos aspectos é similar á linguaxe de consulta SQL.
datos.táboa
Официальный сайт:
Por data.table é Matt Dole de H2O.ai.
A primeira edición da biblioteca tivo lugar en 2006.
A sintaxe do paquete non é tan conveniente como en tidyverse e recorda máis aos marcos de datos clásicos en R, pero ao mesmo tempo expandiu significativamente a súa funcionalidade.
Todas as manipulacións coa táboa deste paquete descríbense entre corchetes, e se traduce a sintaxe data.table en SQL, obtén algo así: data.table[ WHERE, SELECT, GROUP BY ]
O punto forte deste paquete é a velocidade de procesamento de grandes cantidades de datos.
pandas
Официальный сайт:
O nome da biblioteca provén do termo econométrico "panel data", usado para describir conxuntos estruturados multidimensionais de información.
Por pandas é o estadounidense Wes McKinney.
Cando se trata de análise de datos en Python, igual pandas Non. Un paquete moi multifuncional e de alto nivel que permite realizar calquera manipulación con datos, desde cargar datos desde calquera fonte ata visualizalos.
Instalación de paquetes adicionais
Os paquetes que se comentan neste artigo non están incluídos nas distribucións básicas de R e Python. Aínda que hai unha pequena advertencia, se instalou a distribución Anaconda, instale adicionalmente pandas non é necesario.
Instalación de paquetes en R
Se abriu o ambiente de desenvolvemento RStudio polo menos unha vez, probablemente xa saiba como instalar o paquete necesario en R. Para instalar paquetes, use o comando estándar install.packages() executándoo directamente no propio R.
# установка пакетов
install.packages("vroom")
install.packages("readr")
install.packages("dplyr")
install.packages("data.table")Despois da instalación, os paquetes deben estar conectados, para o que na maioría dos casos úsase o comando library().
# подключение или импорт пакетов в рабочее окружение
library(vroom)
library(readr)
library(dplyr)
library(data.table)Instalación de paquetes en Python
Entón, se tes Python puro instalado, entón pandas necesitas instalalo manualmente. Abre unha liña de comandos ou terminal, dependendo do teu sistema operativo e introduce o seguinte comando.
pip install pandasDespois volvemos a Python e importamos o paquete instalado co comando import.
import pandas as pdCargando datos
A minería de datos é un dos pasos máis importantes na análise de datos. Tanto Python como R, se o desexa, ofrécenche amplas oportunidades para obter datos de calquera fonte: ficheiros locais, ficheiros de Internet, sitios web, todo tipo de bases de datos.

Ao longo do artigo utilizaremos varios conxuntos de datos:
- Dúas descargas de Google Analytics.
- Conjunto de datos de pasaxeiros do Titanic.
Todos os datos están no meu en forma de ficheiros csv e tsv. De onde os solicitaremos?
Cargando datos en R: tidyverse, vroom, readr
Para cargar datos nunha biblioteca tidyverse Hai dous paquetes: vroom, readr. vroom máis moderno, pero no futuro os paquetes poden combinarse.
Cita de vroom.
vroom vs lector
Que significa o lanzamentovroomsignificar parareadr? Polo momento pensamos deixar que os dous paquetes evolucionen por separado, pero é probable que uniremos os paquetes no futuro. Unha desvantaxe da lectura preguiceira de vroom é que certos problemas de datos non se poden informar por adiantado, polo que a mellor forma de unificalos require un pouco de reflexión.vroom vs readr
Que significa liberar?vroomparareadr? Polo momento pensamos desenvolver ambos paquetes por separado, pero probablemente os combinaremos no futuro. Unha das desvantaxes da lectura preguiceiravroomé que algúns problemas cos datos non se poden informar con antelación, polo que hai que pensar na mellor forma de combinalos.
Neste artigo veremos os dous paquetes de carga de datos:
Cargando datos no paquete R: vroom
# install.packages("vroom")
library(vroom)
# Чтение данных
## vroom
ga_nov <- vroom("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_nowember.csv")
ga_dec <- vroom("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_december.csv")
titanic <- vroom("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/titanic.csv")Cargando datos en R: readr
# install.packages("readr")
library(readr)
# Чтение данных
## readr
ga_nov <- read_tsv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_nowember.csv")
ga_dec <- read_tsv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_december.csv")
titanic <- read_csv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/titanic.csv")No paquete vroom, independentemente do formato de datos csv / tsv, a carga realízase pola función do mesmo nome vroom(), no paquete readr usamos unha función diferente para cada formato read_tsv() и read_csv().
Cargando datos en R: data.table
В data.table hai unha función para cargar datos fread().
Cargando datos no paquete R: data.table
# install.packages("data.table")
library(data.table)
## data.table
ga_nov <- fread("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_nowember.csv")
ga_dec <- fread("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_december.csv")
titanic <- fread("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/titanic.csv")Cargando datos en Python: pandas
Se comparamos cos paquetes R, entón neste caso a sintaxe é a máis próxima pandas vontade readr, porque pandas pode solicitar datos desde calquera lugar, e hai toda unha familia de funcións neste paquete read_*().
read_csv()read_excel()read_sql()read_json()read_html()
E moitas outras funcións deseñadas para ler datos de varios formatos. Pero para os nosos propósitos é suficiente read_table() ou read_csv() usando argumentos setembro para especificar o separador de columnas.
Cargando datos en Python: pandas
import pandas as pd
ga_nov = pd.read_csv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/russian_text_in_r/ga_nowember.csv", sep = "t")
ga_dec = pd.read_csv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/russian_text_in_r/ga_december.csv", sep = "t")
titanic = pd.read_csv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/russian_text_in_r/titanic.csv")Creación de marcos de datos
Táboa titânico, que cargamos, hai un campo Sexo, que almacena o identificador de xénero do pasaxeiro.
Pero para unha presentación máis cómoda dos datos en termos de xénero do pasaxeiro, debes usar o nome en lugar do código de xénero.
Para iso, imos crear un pequeno directorio, unha táboa na que só haberá 2 columnas (código e nome de xénero) e 2 filas, respectivamente.
Creando un marco de datos en R: tidyverse, dplyr
No exemplo de código a continuación, creamos o marco de datos desexado mediante a función tibble() .
Creando un marco de datos en R: dplyr
## dplyr
### создаём справочник
gender <- tibble(id = c(1, 2),
gender = c("female", "male"))Creación dun marco de datos en R: data.table
Creación dun marco de datos en R: data.table
## data.table
### создаём справочник
gender <- data.table(id = c(1, 2),
gender = c("female", "male"))
Creando un marco de datos en Python: pandas
В pandas A creación de marcos realízase en varias etapas, primeiro creamos un dicionario e despois convertémolo nun marco de datos.
Creando un marco de datos en Python: pandas
# создаём дата фрейм
gender_dict = {'id': [1, 2],
'gender': ["female", "male"]}
# преобразуем словарь в датафрейм
gender = pd.DataFrame.from_dict(gender_dict)Selección de columnas
As táboas coas que traballas poden conter decenas ou mesmo centos de columnas de datos. Pero para realizar a análise, por regra xeral, non precisa de todas as columnas que están dispoñibles na táboa de orixe.
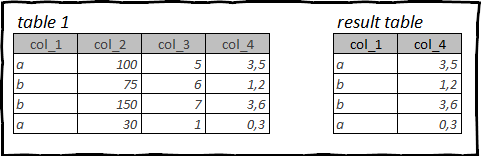
Polo tanto, unha das primeiras operacións que realizará coa táboa fonte é borrala de información innecesaria e liberar a memoria que ocupa esta información.
Seleccionando columnas en R: tidyverse, dplyr
sintaxe dplyr é moi semellante á linguaxe de consulta SQL, se estás familiarizado con el dominarás rapidamente este paquete.
Para seleccionar columnas, use a función select().
A continuación móstranse exemplos de código cos que pode seleccionar columnas das seguintes formas:
- Lista dos nomes das columnas necesarias
- Consulte os nomes das columnas usando expresións regulares
- Por tipo de datos ou calquera outra propiedade dos datos contidos na columna
Selección de columnas en R: dplyr
# Выбор нужных столбцов
## dplyr
### выбрать по названию столбцов
select(ga_nov, date, source, sessions)
### исключь по названию столбцов
select(ga_nov, -medium, -bounces)
### выбрать по регулярному выражению, стобцы имена которых заканчиваются на s
select(ga_nov, matches("s$"))
### выбрать по условию, выбираем только целочисленные столбцы
select_if(ga_nov, is.integer)Selección de columnas en R: datos.táboa
As mesmas operacións en data.table realízanse de forma lixeiramente diferente, ao comezo do artigo proporcionei unha descrición dos argumentos que hai entre corchetes en data.table.
DT[i,j,by]
En que:
i - onde, é dicir. filtrado por filas
j - seleccionar|actualizar|facer, é dicir. seleccionando columnas e converténdoas
por - agrupación de datos
Selección de columnas en R: datos.táboa
## data.table
### выбрать по названию столбцов
ga_nov[ , .(date, source, sessions) ]
### исключь по названию столбцов
ga_nov[ , .SD, .SDcols = ! names(ga_nov) %like% "medium|bounces" ]
### выбрать по регулярному выражению
ga_nov[, .SD, .SDcols = patterns("s$")]Variable .SD permítelle acceder a todas as columnas e .SDcols filtra as columnas necesarias mediante expresións regulares ou outras funcións para filtrar os nomes das columnas que necesites.
Seleccionando columnas en Python, pandas
Para seleccionar columnas polo nome pandas abonda con proporcionar unha lista dos seus nomes. E para seleccionar ou excluír columnas polo nome mediante expresións regulares, cómpre utilizar as funcións drop() и filter(), e argumento eixe = 1, co que indicas que é necesario procesar columnas en lugar de filas.
Para seleccionar un campo por tipo de datos, use a función select_dtypes(), e en argumentos incluír ou eliminar pase unha lista de tipos de datos correspondentes aos campos que cómpre seleccionar.
Selección de columnas en Python: pandas
# Выбор полей по названию
ga_nov[['date', 'source', 'sessions']]
# Исключить по названию
ga_nov.drop(['medium', 'bounces'], axis=1)
# Выбрать по регулярному выражению
ga_nov.filter(regex="s$", axis=1)
# Выбрать числовые поля
ga_nov.select_dtypes(include=['number'])
# Выбрать текстовые поля
ga_nov.select_dtypes(include=['object'])Filtrando filas
Por exemplo, a táboa de orixe pode conter varios anos de datos, pero só precisa analizar o último mes. De novo, as liñas adicionais ralentizarán o proceso de procesamento de datos e atascarán a memoria do PC.
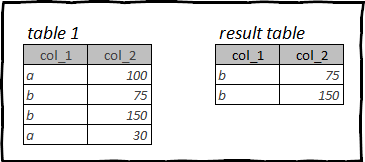
Filtrando filas en R: tydyverse, dplyr
В dplyr a función úsase para filtrar filas filter(). Leva un marco de datos como primeiro argumento e, a continuación, enumera as condicións de filtrado.
Ao escribir expresións lóxicas para filtrar unha táboa, neste caso, especifique os nomes das columnas sen comiñas e sen declarar o nome da táboa.
Cando use varias expresións lóxicas para filtrar, use os seguintes operadores:
- & ou coma - AND lóxico
- | - OU lóxico
Filtrando filas en R: dplyr
# фильтрация строк
## dplyr
### фильтрация строк по одному условию
filter(ga_nov, source == "google")
### фильтр по двум условиям соединённым логическим и
filter(ga_nov, source == "google" & sessions >= 10)
### фильтр по двум условиям соединённым логическим или
filter(ga_nov, source == "google" | sessions >= 10)Filtrando filas en R: datos.táboa
Como xa escribín arriba, en data.table A sintaxe de conversión de datos encóntrase entre corchetes.
DT[i,j,by]
En que:
i - onde, é dicir. filtrado por filas
j - seleccionar|actualizar|facer, é dicir. seleccionando columnas e converténdoas
por - agrupación de datos
O argumento úsase para filtrar filas i, que ten a primeira posición entre corchetes.
Accédese ás columnas en expresións lóxicas sen comiñas e sen especificar o nome da táboa.
As expresións lóxicas están relacionadas entre si do mesmo xeito que en dplyr a través dos operadores & e |.
Filtrando filas en R: datos.táboa
## data.table
### фильтрация строк по одному условию
ga_nov[source == "google"]
### фильтр по двум условиям соединённым логическим и
ga_nov[source == "google" & sessions >= 10]
### фильтр по двум условиям соединённым логическим или
ga_nov[source == "google" | sessions >= 10]Filtrado de cadeas en Python: pandas
Filtrar por filas pandas semellante ao filtrado data.table, e faise entre corchetes.
Neste caso, o acceso ás columnas realízase necesariamente indicando o nome do marco de datos; entón o nome da columna tamén se pode indicar entre comiñas entre corchetes (exemplo df['col_name']), ou sen comiñas despois do punto (exemplo df.col_name).
Se precisa filtrar un marco de datos por varias condicións, cada condición debe colocarse entre parénteses. As condicións lóxicas están conectadas entre si por operadores & и |.
Filtrado de cadeas en Python: pandas
# Фильтрация строк таблицы
### фильтрация строк по одному условию
ga_nov[ ga_nov['source'] == "google" ]
### фильтр по двум условиям соединённым логическим и
ga_nov[(ga_nov['source'] == "google") & (ga_nov['sessions'] >= 10)]
### фильтр по двум условиям соединённым логическим или
ga_nov[(ga_nov['source'] == "google") | (ga_nov['sessions'] >= 10)]Agrupación e agregación de datos
Unha das operacións máis utilizadas na análise de datos é a agrupación e a agregación.
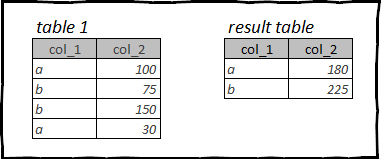
A sintaxe para realizar estas operacións está espallada por todos os paquetes que revisamos.
Neste caso, tomaremos un marco de datos como exemplo titânico, e calcula o número e o custo medio dos billetes en función da clase de cabina.
Agrupación e agregación de datos en R: tidyverse, dplyr
В dplyr a función úsase para agrupar group_by(), e para a agregación summarise(). De feito, dplyr hai toda unha familia de funcións summarise_*(), pero o propósito deste artigo é comparar a sintaxe básica, polo que non imos entrar en tal selva.
Funcións básicas de agregación:
sum()- sumatoriamin()/max()- Valor mínimo e máximomean()- mediamedian()- medianalength()- cantidade
Agrupación e agregación en R: dplyr
## dplyr
### группировка и агрегация строк
group_by(titanic, Pclass) %>%
summarise(passangers = length(PassengerId),
avg_price = mean(Fare))Para funcionar group_by() pasamos a táboa como primeiro argumento titânico, e despois indicou o campo Clase P, polo que agruparemos a nosa mesa. O resultado desta operación usando o operador %>% pasou como primeiro argumento á función summarise(), e engadiu 2 campos máis: pasaxeiros и prezo_medio. No primeiro, empregando a función length() calculou o número de billetes, e no segundo usando a función mean() recibiu o prezo medio do billete.
Agrupación e agregación de datos en R: datos.táboa
В data.table o argumento úsase para a agregación j que ten unha segunda posición entre corchetes, e para agrupar by ou keyby, que ocupan a terceira posición.
A lista de funcións de agregación neste caso é idéntica á descrita en dplyr, porque estas son funcións da sintaxe R básica.
Agrupación e agregación en R: datos.táboa
## data.table
### фильтрация строк по одному условию
titanic[, .(passangers = length(PassengerId),
avg_price = mean(Fare)),
by = Pclass]Agrupación e agregación de datos en Python: pandas
Agrupación en pandas semellante a dplyr, pero a agregación non é semellante a dplyr non encendido data.table.
Para agrupar, utiliza o método groupby(), no que cómpre pasar unha lista de columnas polas que se agrupará o marco de datos.
Para a agregación pode usar o método agg()que acepta un dicionario. As claves do dicionario son as columnas nas que aplicará as funcións de agregación e os valores son os nomes das funcións de agregación.
Funcións de agregación:
sum()- sumatoriamin()/max()- Valor mínimo e máximomean()- mediamedian()- medianacount()- cantidade
Función reset_index() no seguinte exemplo úsase para restablecer índices anidados que pandas predeterminado despois da agregación de datos.
Símbolo permítelle pasar á seguinte liña.
Agrupación e agregación en Python: pandas
# группировка и агрегация данных
titanic.groupby(["Pclass"]).
agg({'PassengerId': 'count', 'Fare': 'mean'}).
reset_index()Unión vertical de táboas
Operación na que se une dúas ou máis táboas da mesma estrutura. Os datos que cargamos conteñen táboas ga_nov и ga_dec. Estas táboas teñen unha estrutura idéntica, é dicir. teñen as mesmas columnas e os tipos de datos nestas columnas.
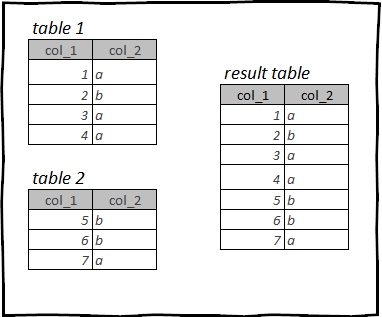
Esta é unha carga de Google Analytics para o mes de novembro e decembro, nesta sección combinaremos estes datos nunha soa táboa.
Unir táboas verticalmente en R: tidyverse, dplyr
В dplyr Podes combinar 2 táboas nunha única usando a función bind_rows(), pasando táboas como argumentos.
Filtrando filas en R: dplyr
# Вертикальное объединение таблиц
## dplyr
bind_rows(ga_nov, ga_dec)Unir táboas verticalmente en R: data.table
Tampouco é nada complicado, usemos rbind().
Filtrando filas en R: datos.táboa
## data.table
rbind(ga_nov, ga_dec)Unir táboas verticalmente en Python: pandas
В pandas a función úsase para unir táboas concat(), no que cómpre pasar unha lista de fotogramas para combinalos.
Filtrado de cadeas en Python: pandas
# вертикальное объединение таблиц
pd.concat([ga_nov, ga_dec])Unión horizontal de táboas
Unha operación na que as columnas da segunda se engaden á primeira táboa por clave. Adoita utilizarse cando se enriquece unha táboa de feitos (por exemplo, unha táboa con datos de vendas) con algúns datos de referencia (por exemplo, o custo dun produto).
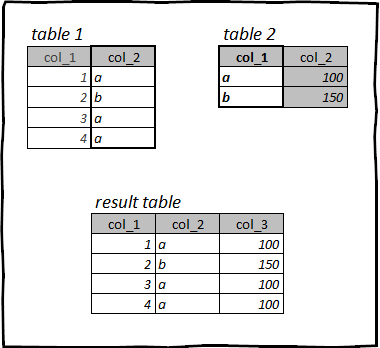
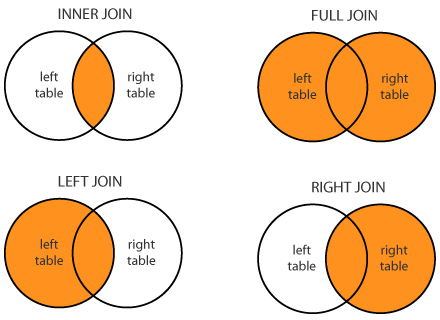
Hai varios tipos de unións:
Na táboa cargada anteriormente titânico temos unha columna Sexo, que corresponde ao código de xénero do pasaxeiro:
1 - feminino
2 - masculino
Ademais, creamos unha táboa: un libro de consulta sexo. Para unha presentación máis cómoda dos datos sobre o sexo dos pasaxeiros, necesitamos engadir o nome do xénero desde o directorio sexo á mesa titânico.
Unión de táboa horizontal en R: tidyverse, dplyr
В dplyr Hai toda unha familia de funcións para a unión horizontal:
inner_join()left_join()right_join()full_join()semi_join()nest_join()anti_join()
O máis usado na miña práctica é left_join().
Como os dous primeiros argumentos, as funcións listadas arriba levan dúas táboas para unirse e como terceiro argumento by debes especificar as columnas para unir.
Unión de táboa horizontal en R: dplyr
# объединяем таблицы
left_join(titanic, gender,
by = c("Sex" = "id"))Unión horizontal de táboas en R: datos.táboa
В data.table Necesitas unir táboas por tecla usando a función merge().
Argumentos para a función merge() en data.table
- x, y — Táboas para unir
- by — Columna que é a clave para unir se ten o mesmo nome nas dúas táboas
- by.x, by.y — Os nomes das columnas que se van combinar, se teñen nomes diferentes nas táboas
- all, all.x, all.y — Tipo de unión, all devolverá todas as filas das dúas táboas, all.x corresponde á operación LEFT JOIN (deixará todas as filas da primeira táboa), all.y — corresponde ao Operación RIGHT JOIN (deixará todas as filas da segunda táboa).
Unión horizontal de táboas en R: datos.táboa
# объединяем таблицы
merge(titanic, gender, by.x = "Sex", by.y = "id", all.x = T)Unión de táboas horizontales en Python: pandas
Así como en data.tableEn pandas a función úsase para unir táboas merge().
Argumentos da función merge() en pandas
- como — Tipo de conexión: esquerda, dereita, exterior, interior
- on — Columna que é unha chave se ten o mesmo nome en ambas as táboas
- left_on, right_on — Nomes das columnas clave, se teñen nomes diferentes nas táboas
Unión de táboas horizontales en Python: pandas
# объединяем по ключу
titanic.merge(gender, how = "left", left_on = "Sex", right_on = "id")Funcións básicas da xanela e columnas calculadas
As funcións de fiestra teñen un significado semellante ás funcións de agregación e tamén se usan a miúdo na análise de datos. Pero a diferenza das funcións de agregación, as funcións de xanela non cambian o número de filas do marco de datos de saída.
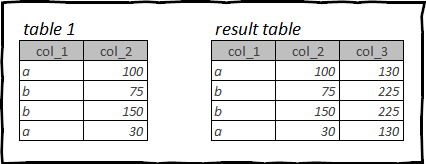
Esencialmente, usando a función de xanela, dividimos o marco de datos entrante en partes segundo algún criterio, é dicir. polo valor dun campo ou varios campos. E realizamos operacións aritméticas en cada xanela. O resultado destas operacións devolverase en cada liña, é dicir. sen cambiar o número total de filas da táboa.
Por exemplo, tomemos a mesa titânico. Podemos calcular que porcentaxe foi o custo de cada billete dentro da súa clase de cabina.
Para iso, necesitamos obter en cada liña o custo total dun billete para a clase de cabina actual á que pertence o billete desta liña e, a continuación, dividir o custo de cada billete polo custo total de todos os billetes da mesma clase de cabina. .
Funcións da fiestra en R: tidyverse, dplyr
Para engadir novas columnas, sen utilizar a agrupación de filas, en dplyr serve a función mutate().
Podes resolver o problema descrito anteriormente agrupando os datos por campo Clase P e sumando o campo nunha nova columna Tarifa. A continuación, desagrupe a táboa e divida os valores dos campos Tarifa ao que pasou no paso anterior.
Funcións da fiestra en R: dplyr
group_by(titanic, Pclass) %>%
mutate(Pclass_cost = sum(Fare)) %>%
ungroup() %>%
mutate(ticket_fare_rate = Fare / Pclass_cost)Funcións da fiestra en R: datos.táboa
O algoritmo de solución segue sendo o mesmo que en dplyr, necesitamos dividir a táboa en ventás por campo Clase P. Sae nunha nova columna o importe do grupo correspondente a cada fila, e engade unha columna na que calculamos a parte do custo de cada ticket do seu grupo.
Para engadir novas columnas a data.table operador presente :=. A continuación móstrase un exemplo de resolución dun problema usando o paquete data.table
Funcións da fiestra en R: datos.táboa
titanic[,c("Pclass_cost","ticket_fare_rate") := .(sum(Fare), Fare / Pclass_cost),
by = Pclass]Funcións da fiestra en Python: pandas
Unha forma de engadir unha nova columna a pandas - utilizar a función assign(). Para resumir o custo dos billetes por clase de cabina, sen agrupar filas, utilizaremos a función transform().
A continuación móstrase un exemplo de solución na que engadimos á táboa titânico as mesmas 2 columnas.
Funcións da fiestra en Python: pandas
titanic.assign(Pclass_cost = titanic.groupby('Pclass').Fare.transform(sum),
ticket_fare_rate = lambda x: x['Fare'] / x['Pclass_cost'])Táboa de correspondencia de funcións e métodos
A continuación móstrase unha táboa de correspondencia entre métodos para realizar diversas operacións con datos dos paquetes que consideramos.
Descrición
ordenado
datos.táboa
pandas
Cargando datos
vroom()/ readr::read_csv() / readr::read_tsv()
fread()
read_csv()
Creación de marcos de datos
tibble()
data.table()
dict() + from_dict()
Selección de columnas
select()
argumento j, segunda posición entre corchetes
pasamos a lista de columnas obrigatorias entre corchetes / drop() / filter() / select_dtypes()
Filtrando filas
filter()
argumento i, primeira posición entre corchetes
Enumeramos as condicións de filtrado entre corchetes / filter()
Agrupación e Agregación
group_by() + summarise()
argumentos j + by
groupby() + agg()
Unión vertical de mesas (UNION)
bind_rows()
rbind()
concat()
Unión horizontal de táboas (JOIN)
left_join() / *_join()
merge()
merge()
Funcións básicas da xanela e engadindo columnas calculadas
group_by() + mutate()
argumento j utilizando o operador := + argumento by
transform() + assign()
Conclusión
Quizais no artigo que describín non sexan as implementacións máis óptimas de procesamento de datos, polo que estarei encantado de corrixir os meus erros nos comentarios ou simplemente complementar a información que se ofrece no artigo con outras técnicas para traballar con datos en R / Python.
Como escribín anteriormente, a finalidade do artigo non era impoñer a propia opinión sobre que lingua é mellor, senón simplificar a oportunidade de aprender as dúas linguas ou, se é necesario, migrar entre elas.
Se che gustou o artigo, estarei encantado de ter novos subscritores ao meu и canles.
Опрос
Cal dos seguintes paquetes utilizas no teu traballo?
Nos comentarios podes escribir o motivo da túa elección.
Só os usuarios rexistrados poden participar na enquisa. , por favor.
Que paquete de procesamento de datos usas (podes seleccionar varias opcións)
-
45,2%ordenado 19
-
33,3%datos.táboa14
-
54,8%pandas23
Votaron 42 usuarios. 9 usuarios abstivéronse.
Fonte: www.habr.com
