


Xa o falamos , que permite desenvolver aplicacións distribuídas e empaquetalas. Todo o que queda é aprender a implementar estas aplicacións e xestionalas. Non te preocupes, temos todo cuberto! Reunimos todas as mellores prácticas para traballar con Tarantool Cartridge e escribimos , que distribuirá o paquete aos servidores, lanzará instancias, unirá-as nun clúster, configurará a autorización, iniciará o vshard, activará a conmutación automática por fallo e parcheará a configuración do clúster.
Interesante? Entón, por favor, debaixo do corte, contámoschelo e mostrámosche todo.
Comecemos cun exemplo
Só miraremos parte da funcionalidade do noso papel. Sempre podes atopar unha descrición completa de todas as súas capacidades e parámetros de entrada . Pero é mellor probalo unha vez que velo cen veces, así que imos implementar unha pequena aplicación.
O cartucho Tarantool ten para crear unha pequena aplicación Cartridge que almacene información sobre os clientes bancarios e as súas contas, e tamén proporciona unha API para a xestión de datos a través de HTTP. Para conseguilo, no apéndice descríbense dúas funcións posibles: api и storage, que se pode asignar a instancias.
O cartucho en si non di nada sobre como iniciar procesos, só ofrece a posibilidade de configurar instancias que xa están en execución. O resto debe facer el mesmo o usuario: organizar os ficheiros de configuración, iniciar servizos e configurar a topoloxía. Pero non faremos todo isto; Ansible farao por nós.
Das palabras aos feitos
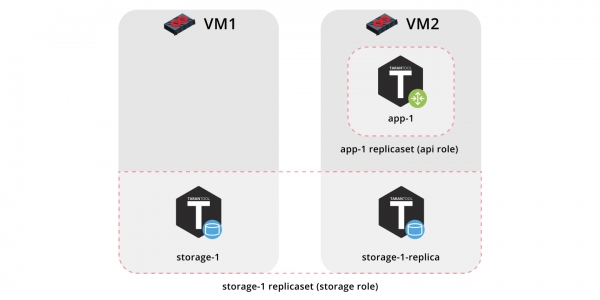
Entón, implementemos a nosa aplicación en dúas máquinas virtuais e configuremos unha topoloxía sinxela:
- Conxunto de réplicas
app-1aplicará o papelapi, que inclúe o papelvshard-router. Aquí só haberá unha instancia. - Conxunto de réplicas
storage-1implementa o papelstorage(e ao mesmo tempovshard-storage), aquí engadiremos dúas instancias de máquinas diferentes.
Para executar o exemplo que necesitamos и (versión 2.8 ou anterior).
O papel en si está en . Este é un repositorio que che permite compartir o teu traballo e usar roles preparados.
Imos clonar o repositorio cun exemplo:
$ git clone https://github.com/dokshina/deploy-tarantool-cartridge-app.git
$ cd deploy-tarantool-cartridge-app && git checkout 1.0.0Creamos máquinas virtuais:
$ vagrant upInstale a función ansible do cartucho Tarantool:
$ ansible-galaxy install tarantool.cartridge,1.0.1Inicia o rol instalado:
$ ansible-playbook -i hosts.yml playbook.ymlAgardamos a que o playbook complete a execución, vai a e goza do resultado:
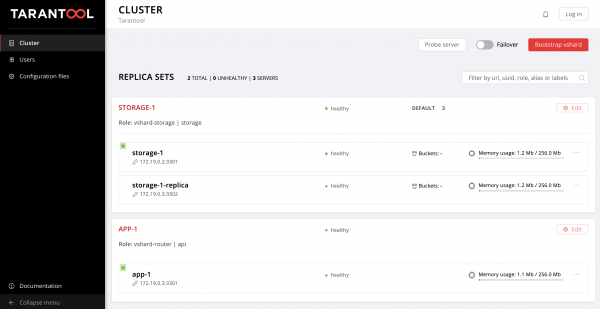
Podes cargar datos. Genial, non?
Agora imos descubrir como traballar con isto e, ao mesmo tempo, engadir outro conxunto de réplicas á topoloxía.
Comecemos a descubrilo
Entón, que pasou?
Configuramos dúas máquinas virtuais e lanzamos un manual de xogos ansible que configuraba o noso clúster. Vexamos o contido do ficheiro playbook.yml:
---
- name: Deploy my Tarantool Cartridge app
hosts: all
become: true
become_user: root
tasks:
- name: Import Tarantool Cartridge role
import_role:
name: tarantool.cartridgeAquí non pasa nada interesante, lancemos un rol ansible chamado tarantool.cartridge.
Todas as cousas máis importantes (é dicir, a configuración do clúster) están situadas - arquivo hosts.yml:
---
all:
vars:
# common cluster variables
cartridge_app_name: getting-started-app
cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # path to package
cartridge_cluster_cookie: app-default-cookie # cluster cookie
# common ssh options
ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key
ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no'
# INSTANCES
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
app-1:
config:
advertise_uri: '172.19.0.3:3301'
http_port: 8182
storage-1-replica:
config:
advertise_uri: '172.19.0.3:3302'
http_port: 8183
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
# first machine connection options
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # instances to be started on the first machine
storage-1:
host2:
vars:
# second machine connection options
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:
# GROUP INSTANCES BY REPLICA SETS
replicaset_app_1:
vars: # replica set configuration
replicaset_alias: app-1
failover_priority:
- app-1 # leader
roles:
- 'api'
hosts: # replica set instances
app-1:
replicaset_storage_1:
vars: # replica set configuration
replicaset_alias: storage-1
weight: 3
failover_priority:
- storage-1 # leader
- storage-1-replica
roles:
- 'storage'
hosts: # replica set instances
storage-1:
storage-1-replica:Todo o que necesitamos é aprender a xestionar instancias e conxuntos de réplicas cambiando o contido deste ficheiro. A continuación engadirémoslle novas seccións. Para non confundirse onde engadilos, pode consultar a versión final deste ficheiro, hosts.updated.yml, que está no repositorio de exemplo.
Xestión de instancias
En termos de Ansible, cada instancia é un host (que non debe confundirse cun servidor de hardware), é dicir. o nodo de infraestrutura que xestionará Ansible. Para cada host podemos especificar parámetros de conexión (como ansible_host и ansible_user), así como a configuración da instancia. A descrición das instancias está na sección hosts.
Vexamos a configuración da instancia storage-1:
all:
vars:
...
# INSTANCES
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
...Nunha variable config especificamos os parámetros de instancia - advertise URI и HTTP port.
Abaixo amósanse os parámetros de instancia app-1 и storage-1-replica.
Necesitamos indicarlle a Ansible os parámetros de conexión para cada instancia. Parece lóxico agrupar instancias en grupos de máquinas virtuais. Para este fin, as instancias combínanse en grupos host1 и host2, e en cada grupo da sección vars indícanse os valores ansible_host и ansible_user para unha máquina virtual. E na sección hosts — hosts (tamén coñecidos como instancias) que se inclúen neste grupo:
all:
vars:
...
hosts:
...
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
# first machine connection options
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # instances to be started on the first machine
storage-1:
host2:
vars:
# second machine connection options
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:Comezamos a cambiar hosts.yml. Engadimos dous casos máis, storage-2-replica na primeira máquina virtual e storage-2 No segundo:
all:
vars:
...
# INSTANCES
hosts:
...
storage-2: # <==
config:
advertise_uri: '172.19.0.3:3303'
http_port: 8184
storage-2-replica: # <==
config:
advertise_uri: '172.19.0.2:3302'
http_port: 8185
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
...
hosts: # instances to be started on the first machine
storage-1:
storage-2-replica: # <==
host2:
vars:
...
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:
storage-2: # <==
...Inicia o libro de xogos ansible:
$ ansible-playbook -i hosts.yml
--limit storage-2,storage-2-replica
playbook.ymlTeña en conta a opción --limit. Dado que cada instancia de clúster é un host en termos de Ansible, podemos especificar de forma explícita que instancias deben configurarse ao executar o libro de xogadas.
Volvendo á IU web e consulta as nosas novas instancias:
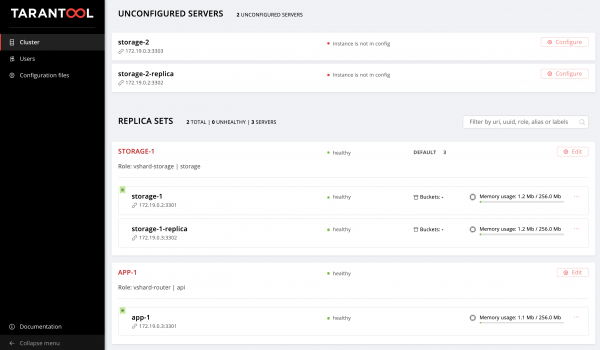
Non deixemos aí e dominamos a xestión da topoloxía.
Xestión da topoloxía
Combinemos as nosas novas instancias nun conxunto de réplicas storage-2. Engadimos un novo grupo replicaset_storage_2 e describir os parámetros replicaset nas súas variables por analoxía con replicaset_storage_1. En sección hosts Imos indicar que instancias se incluirán neste grupo (é dicir, o noso conxunto de réplicas):
---
all:
vars:
...
hosts:
...
children:
...
# GROUP INSTANCES BY REPLICA SETS
...
replicaset_storage_2: # <==
vars: # replicaset configuration
replicaset_alias: storage-2
weight: 2
failover_priority:
- storage-2
- storage-2-replica
roles:
- 'storage'
hosts: # replicaset instances
storage-2:
storage-2-replica:Comezamos de novo o libro de xogos:
$ ansible-playbook -i hosts.yml
--limit replicaset_storage_2
--tags cartridge-replicasets
playbook.ymlEn parámetro --limit Nesta ocasión pasamos o nome do grupo que corresponde ao noso replicaset.
Consideremos a opción tags.
A nosa función realiza secuencialmente varias tarefas, que están marcadas coas seguintes etiquetas:
cartridge-instances: xestión de instancias (configuración, conexión coa adhesión);cartridge-replicasets: xestión da topoloxía (xestión do conxunto de réplicas e eliminación permanente (expulsión) de instancias do clúster);cartridge-config: xestión doutros parámetros do clúster (arranque vshard, modo de failover automático, parámetros de autorización e configuración da aplicación).
Podemos especificar de forma explícita que parte do traballo queremos facer, entón o rol saltará o resto das tarefas. No noso caso, queremos traballar só coa topoloxía, polo que especificamos cartridge-replicasets.
Imos avaliar o resultado dos nosos esforzos. Atopamos un novo replicaset .
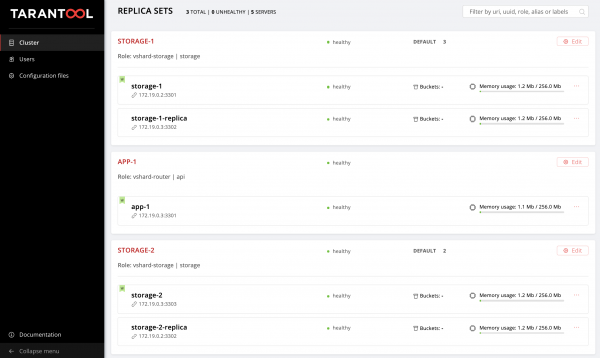
Hooray!
Experimenta con cambiar a configuración de instancias e conxuntos de réplicas e mira como cambia a topoloxía do clúster. Podes probar diferentes escenarios operativos, p. ou aumentar memtx_memory. O rol tentará facelo sen reiniciar a instancia para reducir o posible tempo de inactividade da súa aplicación.
Non esquezas correr vagrant haltpara deter as máquinas virtuais cando remate de traballar con elas.
Que hai debaixo do capó?
Aquí vos contarei máis sobre o que estaba a suceder baixo o capó do papel ansible durante os nosos experimentos.
Vexamos a implementación da aplicación Cartucho paso a paso.
Instalando o paquete e iniciando instancias
Primeiro cómpre entregar o paquete ao servidor e instalalo. Actualmente o rol pode funcionar con paquetes RPM e DEB.
A continuación lanzamos as instancias. Aquí todo é moi sinxelo: cada instancia é separada systemd-servizo. Vouche poñer un exemplo:
$ systemctl start myapp@storage-1Este comando lanzará a instancia storage-1 aplicacións myapp. A instancia iniciada buscará o seu в /etc/tarantool/conf.d/. Os rexistros de instancias pódense ver usando journald.
Ficheiro unitario /etc/systemd/system/myapp@.sevice para o servizo systemd entregarase xunto co paquete.
Ansible ten módulos integrados para instalar paquetes e xestionar servizos de sistema; non inventamos nada novo aquí.
Configurar unha topoloxía de clúster
Aquí é onde comeza a diversión. De acordo, sería estraño preocuparse cun rol especial de Ansible para instalar paquetes e executar systemd-Servizos.
Podes configurar o clúster manualmente:
- Primeira opción: abra a IU web e prema nos botóns. É moi axeitado para un inicio único de varias instancias.
- Segunda opción: podes usar a API GraphQl. Aquí xa podes automatizar algo, por exemplo, escribir un script en Python.
- Terceira opción (para os fortes de vontade): ir ao servidor, conectarse a unha das instancias usando
tarantoolctl connecte realiza todas as manipulacións necesarias co módulo Luacartridge.
A principal tarefa do noso invento é facer exactamente isto, a parte máis difícil do traballo para ti.
Ansible permítelle escribir o seu propio módulo e usalo nun rol. A nosa función utiliza estes módulos para xestionar varios compoñentes do clúster.
Cómo funciona? Describe o estado desexado do clúster nunha configuración declarativa e o rol proporciona a cada módulo a súa sección de configuración como entrada. O módulo recibe o estado actual do clúster e compárao co que se recibiu como entrada. A continuación, lánzase un código a través do socket dunha das instancias, o que leva o clúster ao estado desexado.
Resultados de
Hoxe contamos e mostramos como implementar a súa aplicación en Tarantool Cartridge e configurar unha topoloxía sinxela. Para iso, utilizamos Ansible, unha ferramenta poderosa que é fácil de usar e que permite configurar simultáneamente moitos nodos de infraestrutura (no noso caso, instancias de clúster).
Arriba analizamos unha das moitas formas de describir unha configuración de clúster usando Ansible. Unha vez que te sintas listo para seguir adiante, explora sobre escribir libros de xogo. Pode que sexa máis fácil xestionar a súa topoloxía usando group_vars и host_vars.
Moi pronto dirémosche como eliminar (expulsar) de forma permanente instancias da topoloxía, arrancar o vshard, xestionar o modo de conmutación por fallo automático, configurar a autorización e parchear a configuración do clúster. Mentres tanto, podes estudar pola túa conta e experimentar cambiando os parámetros do clúster.
Se algo non funciona, asegúrate de facelo connosco sobre o problema. Resolveremos todo rapidamente!
Fonte: www.habr.com
