


Estamos en 2019 e aínda non temos unha solución estándar para a agregación de rexistros en Kubernetes. Neste artigo gustaríanos, utilizando exemplos da práctica real, compartir as nosas buscas, os problemas atopados e as súas solucións.
Non obstante, primeiro, farei unha reserva para que os distintos clientes comprendan cousas moi diferentes ao recoller rexistros:
- alguén quere ver rexistros de seguridade e auditoría;
- alguén - rexistro centralizado de toda a infraestrutura;
- e para algúns, abonda con recoller só rexistros de aplicacións, excluíndo, por exemplo, os equilibradores.
A continuación móstrase o corte a continuación sobre como implementamos varias "listas de desexos" e as dificultades que atopamos.
Teoría: sobre ferramentas de rexistro
Antecedentes sobre os compoñentes dun sistema de rexistro
A explotación forestal percorreu un longo camiño, como resultado do cal se desenvolveron metodoloxías de recollida e análise de rexistros, que é o que utilizamos na actualidade. Na década de 1950, Fortran introduciu un análogo de fluxos de entrada/saída estándar, que axudou ao programador a depurar o seu programa. Estes foron os primeiros rexistros informáticos que facilitaron a vida aos programadores daqueles tempos. Hoxe vemos neles o primeiro compoñente do sistema de rexistro: fonte ou "produtor" de rexistros.
A informática non se detivo: apareceron as redes informáticas, os primeiros clusters... Comezaron a funcionar sistemas complexos formados por varios ordenadores. Agora os administradores do sistema víronse obrigados a recoller rexistros de varias máquinas e, en casos especiais, podían engadir mensaxes do núcleo do sistema operativo no caso de que necesitasen investigar un fallo do sistema. Para describir sistemas de recollida de rexistros centralizados, a principios dos anos 2000 publicouse , que normalizou remote_syslog. Así apareceu outro compoñente importante: colector de rexistros e o seu almacenamento.
Co aumento do volume de rexistros e a introdución xeneralizada de tecnoloxías web, xurdiu a pregunta de que rexistros deben mostrarse convenientemente aos usuarios. As ferramentas de consola sinxelas (awk/sed/grep) foron substituídas por outras máis avanzadas visores de rexistro - terceiro compoñente.
Debido ao aumento do volume de rexistros, quedou clara outra cousa: os rexistros son necesarios, pero non todos. E os diferentes rexistros requiren diferentes niveis de conservación: algúns pódense perder nun día, mentres que outros hai que almacenalos durante 5 anos. Entón, engadiuse ao sistema de rexistro un compoñente para filtrar e enrutar os fluxos de datos; chamémolo filtro.
O almacenamento tamén deu un gran salto: desde ficheiros normais a bases de datos relacionais e despois ao almacenamento orientado a documentos (por exemplo, Elasticsearch). Así, o almacenamento foi separado do colector.
En definitiva, o propio concepto de rexistro expandiuse a unha especie de fluxo abstracto de eventos que queremos preservar para a historia. Ou mellor dito, no caso de que necesites realizar unha investigación ou elaborar un informe analítico...
Como resultado, nun período de tempo relativamente curto, a recollida de rexistros converteuse nun subsistema importante, que se pode chamar xustamente unha das subseccións de Big Data.
Se noutrora as impresións ordinarias podían ser suficientes para un "sistema de rexistro", agora a situación cambiou moito.
Kubernetes e rexistros
Cando Kubernetes chegou á infraestrutura, o problema xa existente de recoller rexistros tampouco o superou. Nalgúns aspectos, fíxose aínda máis doloroso: a xestión da plataforma de infraestruturas non só foi simplificada, senón que tamén se complicou ao mesmo tempo. Moitos servizos antigos comezaron a migrar a microservizos. No contexto dos rexistros, isto reflíctese no crecente número de fontes de rexistro, o seu ciclo de vida especial e a necesidade de rastrexar as relacións de todos os compoñentes do sistema a través de rexistros...
De cara ao futuro, podo afirmar que agora, por desgraza, non hai unha opción de rexistro estandarizada para Kubernetes que se compare favorablemente con todos os demais. Os esquemas máis populares na comunidade son os seguintes:
- alguén desenrola a pila EFK (Elasticsearch, Fluentd, Kibana);
- alguén está a probar o recentemente lanzado ou usos ;
- nós (e quizais non só nós?..) Estou moi satisfeito co meu propio desenvolvemento - ...
Como regra xeral, usamos os seguintes paquetes en clústeres K8s (para solucións autoaloxadas):
- ;
- .
Non obstante, non vou determe nas instrucións para a súa instalación e configuración. Pola contra, centrareime nas súas deficiencias e nas conclusións máis globais sobre a situación dos rexistros en xeral.
Practica cos rexistros en K8s

"Rexistros diarios", cantos estades alí?...
A recollida centralizada de rexistros dunha infraestrutura bastante grande require recursos considerables, que se gastarán en recoller, almacenar e procesar rexistros. Durante o funcionamento de varios proxectos, atopámonos con diversos requisitos e problemas operativos derivados deles.
Imos probar ClickHouse
Vexamos un almacenamento centralizado nun proxecto cunha aplicación que xera rexistros de forma bastante activa: máis de 5000 liñas por segundo. Comecemos a traballar cos seus rexistros, engadíndoos a ClickHouse.
En canto se requira o máximo tempo real, o servidor de catro núcleos con ClickHouse xa se sobrecargará no subsistema de discos:
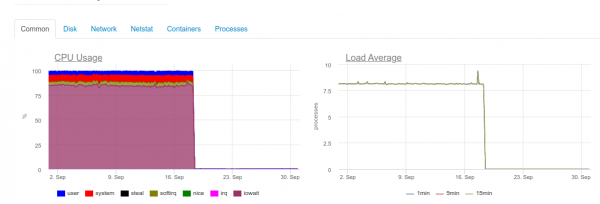
Este tipo de carga débese a que estamos tentando escribir en ClickHouse o máis rápido posible. E a base de datos reacciona a isto aumentando a carga do disco, o que pode provocar os seguintes erros:
DB::Exception: Too many parts (300). Merges are processing significantly slower than inserts
Feito é que en ClickHouse (conteñen datos de rexistro) teñen as súas propias dificultades durante as operacións de escritura. Os datos inseridos neles xeran unha partición temporal, que despois se fusiona coa táboa principal. Como resultado, a gravación resulta ser moi esixente no disco e tamén está suxeita á limitación que recibimos o aviso anterior: non se poden combinar máis de 1 subparticións en 300 segundo (de feito, son 300 insercións). por segundo).
Para evitar este comportamento, en pezas o máis grandes posibles e non máis de 1 vez cada 2 segundos. Non obstante, escribir en grandes ráfagas suxire que debemos escribir con menos frecuencia en ClickHouse. Isto, á súa vez, pode provocar un desbordamento do búfer e a perda de rexistros. A solución é aumentar o búfer de Fluentd, pero despois tamén aumentará o consumo de memoria.
Nota: Outro aspecto problemático da nosa solución con ClickHouse estivo relacionado co feito de que a partición no noso caso (loghouse) se implementa a través de táboas externas conectadas. . Isto leva ao feito de que cando se mostran grandes intervalos de tempo, é necesaria unha RAM excesiva, xa que a metatáboa itera a través de todas as particións, incluso aquelas que obviamente non conteñen os datos necesarios. Non obstante, agora este enfoque pódese declarar obsoleto con seguridade para as versións actuais de ClickHouse (c ).
Como resultado, queda claro que non todos os proxectos teñen recursos suficientes para recoller rexistros en tempo real en ClickHouse (máis precisamente, a súa distribución non será axeitada). Ademais, terás que usar аккумулятор, ao que volveremos máis adiante. O caso descrito anteriormente é real. E nese momento non puidemos ofrecer unha solución fiable e estable que se adaptase ao cliente e que nos permitise recoller rexistros cun mínimo atraso...
Que pasa con Elasticsearch?
Sábese que Elasticsearch manexa grandes cargas de traballo. Probámolo no mesmo proxecto. Agora a carga ten o seguinte aspecto:
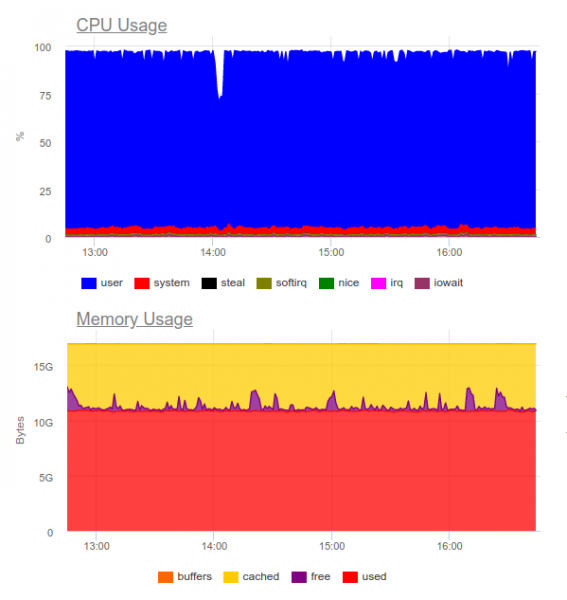
Elasticsearch puido dixerir o fluxo de datos, non obstante, escribir tales volumes utiliza moito a CPU. Isto decídese organizando un clúster. Tecnicamente, isto non é un problema, pero resulta que só para operar o sistema de recollida de rexistros xa usamos uns 8 núcleos e temos un compoñente adicional moi cargado no sistema...
En definitiva: esta opción pódese xustificar, pero só se o proxecto é grande e a súa xestión está preparada para gastar recursos importantes nun sistema de rexistro centralizado.
Entón xorde unha pregunta natural:
Que rexistros son realmente necesarios?
 Tentemos cambiar o enfoque en si: os rexistros deben ser informativos e non cubrir cada un evento no sistema.
Tentemos cambiar o enfoque en si: os rexistros deben ser informativos e non cubrir cada un evento no sistema.
Digamos que temos unha tenda en liña exitosa. Que rexistros son importantes? Recoller tanta información como sexa posible, por exemplo, desde unha pasarela de pago, é unha gran idea. Pero non todos os rexistros do servizo de corte de imaxes do catálogo de produtos son críticos para nós: só os erros e o seguimento avanzado son suficientes (por exemplo, a porcentaxe de 500 erros que xera este compoñente).
Entón chegamos á conclusión de que o rexistro centralizado non sempre está xustificado. Moitas veces o cliente quere recoller todos os rexistros nun só lugar, aínda que de feito, de todo o rexistro, só se require un 5% condicional das mensaxes que son críticas para a empresa:
- Ás veces abonda con configurar, por exemplo, só o tamaño do rexistro do contedor e o colector de erros (por exemplo, Sentry).
- Unha notificación de erro e un rexistro local grande poden ser suficientes para investigar incidentes.
- Tiñamos proxectos que se conformaban exclusivamente con probas funcionais e sistemas de recollida de erros. O programador non necesitaba rexistros como tal: viron todo, desde os rastros de erros.
Ilustración da vida
Outra historia pode servir de bo exemplo. Recibimos unha solicitude do equipo de seguridade dun dos nosos clientes que xa utilizaba unha solución comercial que se desenvolveu moito antes da introdución de Kubernetes.
Era necesario "facer amigos" do sistema centralizado de recollida de rexistros co sensor de detección de problemas corporativos - QRadar. Este sistema pode recibir rexistros a través do protocolo syslog e recuperalos de FTP. Non obstante, non foi posible inmediatamente integralo co complemento remote_syslog para fluentd (como resultou, ). Os problemas coa configuración de QRadar resultaron ser do equipo de seguridade do cliente.
Como resultado, parte dos rexistros críticos para a empresa cargouse a FTP QRadar e a outra parte foi redirixida a través do syslog remoto directamente desde os nodos. Para iso mesmo escribimos - quizais axude a alguén a resolver un problema similar... Grazas ao esquema resultante, o propio cliente recibiu e analizou rexistros críticos (usando as súas ferramentas favoritas), e puidemos reducir o custo do sistema de rexistro, aforrando só o último mes.
Outro exemplo é bastante indicativo do que non hai que facer. Un dos nosos clientes para o procesamento de cada un eventos procedentes do usuario, feito multiliña saída non estruturada información no rexistro. Como podes adiviñar, estes rexistros eran moi inconvenientes tanto para ler como para almacenar.
Criterios para rexistros
Tales exemplos levan á conclusión de que, ademais de escoller un sistema de recollida de rexistros, cómpre facelo tamén deseñar os propios rexistros! Cales son os requisitos aquí?
- Os rexistros deben estar en formato lexible pola máquina (por exemplo, JSON).
- Os rexistros deben ser compactos e con capacidade para cambiar o grao de rexistro para depurar posibles problemas. Ao mesmo tempo, en ambientes de produción deberías executar sistemas cun nivel de rexistro como aviso ou erro.
- Os rexistros deben estar normalizados, é dicir, nun obxecto de rexistro, todas as liñas deben ter o mesmo tipo de campo.
Os rexistros non estruturados poden provocar problemas coa carga de rexistros no almacenamento e unha parada completa no seu procesamento. Como ilustración, aquí tes un exemplo co erro 400, que moitos atoparon definitivamente nos rexistros fluentd:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"
O erro significa que está a enviar un campo cuxo tipo é inestable ao índice cunha asignación preparada. O exemplo máis sinxelo é un campo no rexistro de nginx cunha variable $upstream_status. Pode conter un número ou unha cadea. Por exemplo:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}
Os rexistros mostran que o servidor 10.100.0.10 respondeu cun erro 404 e a solicitude foi enviada a outro almacenamento de contido. Como resultado, o valor dos rexistros quedou así:
"upstream_response_time": "0.001, 0.007"
Esta situación é tan común que mesmo merece unha separación .
Que pasa coa fiabilidade?
Hai momentos nos que todos os rexistros sen excepción son vitais. E con isto, os esquemas típicos de recollida de rexistros para os K8 propostos/discutidos anteriormente teñen problemas.
Por exemplo, fluentd non pode recoller rexistros de contedores de curta duración. Nun dos nosos proxectos, o contedor de migración da base de datos viviu menos de 4 segundos e despois eliminouse, segundo a anotación correspondente:
"helm.sh/hook-delete-policy": hook-succeeded
Debido a isto, o rexistro de execución da migración non se incluíu no almacenamento. A política pode axudar neste caso. before-hook-creation.
Outro exemplo é a rotación do rexistro de Docker. Digamos que hai unha aplicación que escribe activamente nos rexistros. En condicións normais, conseguimos procesar todos os rexistros, pero en canto aparece un problema, por exemplo, como se describe anteriormente cun formato incorrecto, o procesamento detense e Docker xira o ficheiro. O resultado é que se poden perder rexistros críticos para a empresa.
É por iso é importante separar os fluxos de rexistro, incorporando o envío dos máis valiosos directamente na aplicación para garantir a súa seguridade. Ademais, non sería superfluo crear algún "acumulador" de rexistros, que pode sobrevivir a unha breve non dispoñibilidade de almacenamento mentres garda mensaxes críticas.
Finalmente, non debemos esquecer iso É importante supervisar correctamente calquera subsistema. En caso contrario, é fácil atoparse cunha situación na que fluentd está nun estado CrashLoopBackOff e non envía nada, e isto promete a perda de información importante.
Descubrimentos
Neste artigo, non estamos a ver solucións SaaS como Datadog. Moitos dos problemas aquí descritos xa foron resoltos dunha ou outra forma por empresas comerciais especializadas na recollida de rexistros, pero non todos poden usar SaaS por diversos motivos (os principais son o custo e o cumprimento da 152-FZ).
A recollida centralizada de rexistros ao principio parece unha tarefa sinxela, pero non o é en absoluto. É importante lembrar que:
- Só se deben rexistrar detalladamente os compoñentes críticos, mentres que o seguimento e a recollida de erros poden configurarse para outros sistemas.
- Os rexistros na produción deben ser mínimos para non engadir carga innecesaria.
- Os rexistros deben ser lexibles por máquina, normalizados e ter un formato estrito.
- Os rexistros realmente críticos deberían enviarse nun fluxo separado, que debería estar separado dos principais.
- Paga a pena considerar un acumulador de rexistro, que pode salvarche de ráfagas de alta carga e facer que a carga no almacenamento sexa máis uniforme.

Estas regras simples, se se aplican en todas partes, permitirían que os circuítos descritos anteriormente funcionen, aínda que lles falten compoñentes importantes (a batería). Se non cumpre con tales principios, a tarefa levará facilmente a vostede e á infraestrutura a outro compoñente do sistema moi cargado (e ao mesmo tempo ineficaz).
PS
Lea tamén no noso blog:
- «»;
- «»;
- «».
Fonte: www.habr.com
