

Hoxe, ademais do código monolítico, o noso proxecto inclúe ducias de microservizos. Cada un deles require un seguimento. Facer isto a tal escala usando enxeñeiros de DevOps é problemático. Desenvolvemos un sistema de monitorización que funciona como servizo para desenvolvedores. Poden escribir de forma independente métricas no sistema de seguimento, usalas, crear paneis baseados neles e engadirlles alertas que se activarán cando se alcancen os valores límite. Para os enxeñeiros de DevOps, só infraestrutura e documentación.
Esta publicación é unha transcrición do meu discurso co noso en RIT++. Moita xente nos pediu que fixeramos versións de texto dos informes a partir de aí. Se estiveches na conferencia ou miraches o vídeo, non atoparás nada novo. E todos os demais: benvidos ao gato. Vouche contar como chegamos a un sistema deste tipo, como funciona e como pensamos actualizalo.

O pasado: esquemas e plans
Como chegamos ao actual sistema de vixilancia? Para responder a esta pregunta, cómpre ir ao 2015. Este é o que parecía entón:
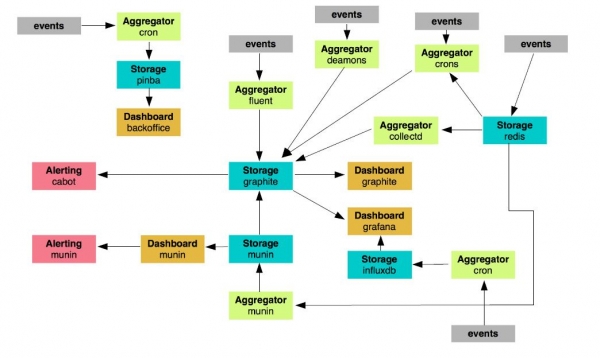
Tiñamos uns 24 nodos que se encargaban do seguimento. Hai todo un paquete de diferentes coroas, scripts, daemons que dalgún xeito supervisan algo, envían mensaxes e realizan funcións. Pensabamos que canto máis avanzamos, menos viable sería un sistema así. De nada serve desenvolvelo: é demasiado engorroso.
Decidimos escoller aqueles elementos de vixilancia que manteremos e desenvolveremos, e aqueles que abandonaremos. Eran 19. Só quedaron grafitos, agregadores e Grafana como cadro de mandos. Pero como será o novo sistema? Como isto:
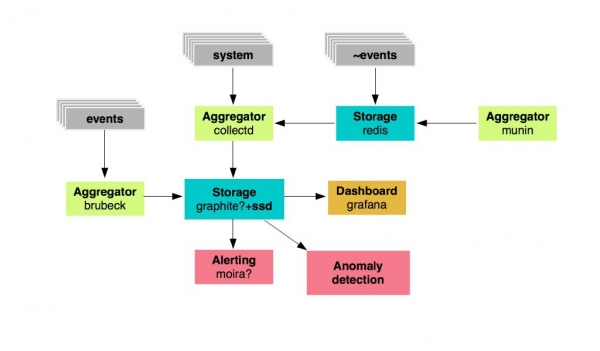
Temos un almacenamento de métricas: estes son grafitos, que estarán baseados en unidades SSD rápidas, estes son certos agregadores de métricas. Seguinte - Grafana para mostrar paneis e Moira para alertar. Tamén queriamos desenvolver un sistema de busca de anomalías.
Estándar: Seguimento 2.0
Así eran os plans en 2015. Pero tivemos que preparar non só a infraestrutura e o propio servizo, senón tamén a documentación para iso. Desenvolvemos un estándar corporativo para nós, que chamamos monitoring 2.0. Cales eran os requisitos para o sistema?
- dispoñibilidade constante;
- intervalo de almacenamento de métricas = 10 segundos;
- almacenamento estruturado de métricas e paneis;
- SLA > 99,99 %
- colección de métricas de eventos a través de UDP (!).
Necesitabamos UDP porque temos un gran fluxo de tráfico e eventos que xeran métricas. Se os escribes todos en grafito á vez, o almacenamento colapsarase. Tamén escollemos prefixos de primeiro nivel para todas as métricas.
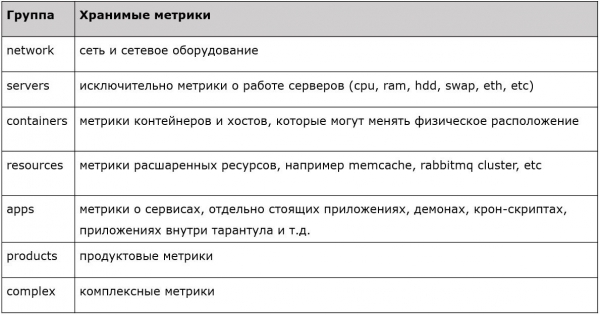
Cada un dos prefixos ten algunha propiedade. Hai métricas para servidores, redes, contedores, recursos, aplicacións, etc. Implementouse un filtrado claro, estrito e escrito, onde aceptamos métricas de primeiro nivel e simplemente deixamos o resto. Así planificamos este sistema en 2015. Que hai no presente?
Presente: diagrama de interacción dos compoñentes de vixilancia
En primeiro lugar, monitorizamos as aplicacións: o noso código PHP, aplicacións e microservizos; en definitiva, todo o que escriben os nosos desenvolvedores. Todas as aplicacións envían métricas a través de UDP ao agregador Brubeck (statsd, reescrito en C). Resultou ser o máis rápido en probas sintéticas. E envía as métricas xa agregadas a Graphite a través de TCP.
Ten un tipo de métricas chamadas temporizadores. Isto é unha cousa moi conveniente. Por exemplo, para cada conexión de usuario ao servizo, envías unha métrica co tempo de resposta a Brubeck. Chegou un millón de respostas, pero o agregador devolveu só 10 métricas. Tes o número de persoas que acudiron, o tempo de resposta máximo, mínimo e medio, a mediana e os 4 percentiles. Despois, os datos transfírense a Graphite e vémolo todo en directo.
Tamén temos agregación de métricas sobre hardware, software, métricas do sistema e o noso antigo sistema de monitorización Munin (funcionou para nós ata 2015). Todo isto recollemos a través do daemon C CollectD (ten un montón de complementos diferentes incorporados, pode sondear todos os recursos do sistema host no que está instalado, só tes que especificar na configuración onde escribir os datos) e escriba os datos a Graphite a través del. Tamén admite complementos de Python e scripts de shell, polo que podes escribir as túas propias solucións personalizadas: CollectD recollerá estes datos dun host local ou remoto (asumindo Curl) e enviaraos a Graphite.
Despois enviamos todas as métricas que recollemos a Carbon-c-relay. Esta é a solución Carbon Relay de Graphite, modificada en C. Este é un enrutador que recolle todas as métricas que enviamos dos nosos agregadores e as envía aos nodos. Tamén na fase de enrutamento, comproba a validez das métricas. En primeiro lugar, deben corresponder ao esquema de prefixos que mostrei anteriormente e, en segundo lugar, son válidos para o grafito. En caso contrario caerán.
A continuación, o relé Carbon-c envía as métricas ao clúster de grafito. Usamos Carbon-cache, reescrito en Go, como principal almacenamento de métricas. Go-carbon, debido ao seu multithreading, supera con moito a Carbon-cache. Recibe datos e escríbeos en discos usando o paquete whisper (estándar, escrito en Python). Para ler os datos dos nosos almacenamentos, usamos a API de Graphite. É moito máis rápido que o estándar Graphite WEB. Que pasa cos datos a continuación?
Van a Grafana. Usamos os nosos clústeres de grafito como fonte principal de datos, ademais de contar con Grafana como interface web para mostrar métricas e construír paneis de control. Para cada un dos seus servizos, os desenvolvedores crean o seu propio panel. Despois constrúen gráficos baseados neles, que mostran as métricas que escriben desde as súas aplicacións. Ademais de Grafana, tamén temos SLAM. Este é un demo python que calcula o SLA baseándose en datos de grafito. Como xa dixen, temos varias ducias de microservizos, cada un dos cales ten os seus propios requisitos. Usando SLAM, imos á documentación e comparámola co que hai en Graphite e comparamos o ben que os requisitos se axustan á dispoñibilidade dos nosos servizos.
Imos máis aló: alertando. Organízase mediante un sistema forte - Moira. É independente porque ten o seu propio Grafito debaixo do capó. Desenvolvido polos rapaces de SKB "Kontur", escrito en python e Go, completamente de código aberto. Moira recibe o mesmo caudal que vai nos grafitos. Se por algún motivo o teu almacenamento morre, a túa alerta seguirá funcionando.
Implementamos Moira en Kubernetes; usa un clúster de servidores Redis como base de datos principal. O resultado foi un sistema tolerante a fallos. Compara o fluxo de métricas coa lista de disparadores: se non hai mencións nela, elimina a métrica. Polo tanto, é capaz de dixerir gigabytes de métricas por minuto.
Tamén lle adxuntamos un LDAP corporativo, coa axuda do cal cada usuario do sistema corporativo pode crear notificacións por si mesmo en función dos disparadores existentes (ou recentemente creados). Como Moira contén Grafito, admite todas as súas características. Entón, primeiro tomas a liña e cópiaa en Grafana. Vexa como se mostran os datos nos gráficos. E despois colles a mesma liña e cópiaa en Moira. Cólgase con límites e recibe unha alerta na saída. Para facer todo isto, non precisa ningún coñecemento específico. Moira pode alertar por SMS, correo electrónico, Jira, Slack... Tamén admite a execución de scripts personalizados. Cando se lle ocorre un disparador e está subscrita a un script ou binario personalizado, execútao e envía JSON a stdin para este binario. En consecuencia, o seu programa debe analizalo. O que farás con este JSON depende de ti. Se queres, envíao a Telegram, se queres, abre tarefas en Jira, fai o que sexa.
Tamén usamos o noso propio desenvolvemento para alertar: Imagotag. Adaptamos o panel, que se usa habitualmente para as etiquetas electrónicas de prezos nas tendas, ás nosas necesidades. Trouxémoslle disparadores de Moira. Indica en que estado se atopan e cando ocorreron. Algúns dos mozos de desenvolvemento abandonaron as notificacións en Slack e o correo electrónico a favor deste panel.

Ben, xa que somos unha empresa progresista, tamén supervisamos Kubernetes neste sistema. Incluímolo no sistema mediante Heapster, que instalamos no clúster, recolle datos e envíanos a Graphite. Como resultado, o diagrama ten o seguinte aspecto:
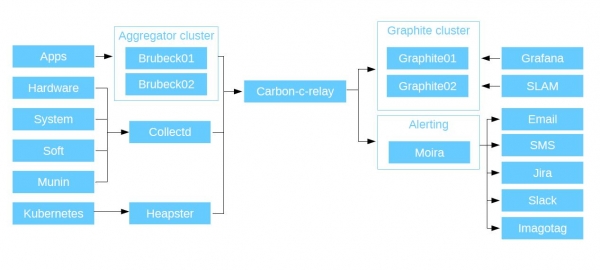
Compoñentes de vixilancia
Aquí tes unha lista de ligazóns aos compoñentes que utilizamos para esta tarefa. Todos eles son de código aberto.
Grafito:
- go-carbon:
- murmurar:
- grafito-api:
Relé de carbono-c:
Brubeck:
Recollido:
Moira:
Grafana:
Heapster:
estatística
E aquí tes algúns números sobre como funciona o sistema para nós.
Agregador (brubeck)
Número de métricas: ~300/s
Intervalo de envío de métricas a Graphite: 30 seg
Uso de recursos do servidor: ~ 6% CPU (estamos falando de servidores completos); ~ 1 Gb de RAM; ~3 Mbps LAN
Grafito (go-carbono)
Número de métricas: ~ 1/min
Intervalo de actualización de métricas: 30 seg
Esquema de almacenamento de métricas: 30 segundos, 35 días, 5 minutos, 90 días, 10 minutos, 365 días (permíteche entender o que acontece co servizo durante un longo período de tempo)
Uso de recursos do servidor: ~10% CPU; ~ 20 Gb de RAM; ~30 Mbps LAN
Flexibilidade
En Avito valoramos moito a flexibilidade no noso servizo de vixilancia. Por que realmente resultou así? En primeiro lugar, os seus compoñentes son intercambiables: tanto os propios compoñentes como as súas versións. En segundo lugar, a compatibilidade. Dado que todo o proxecto é de código aberto, pode editar o código vostede mesmo, facer cambios e implementar funcións que non están dispoñibles. Utilízanse pilas bastante comúns, principalmente Go e Python, polo que isto faise de forma sinxela.
Aquí tes un exemplo dun problema real. Unha métrica en Graphite é un ficheiro. Ten un nome. O nome do ficheiro é o nome da métrica. E hai unha ruta cara a ela. Os nomes de ficheiro en Linux Están limitados a 255 caracteres. E temos (como "clientes internos") aos rapaces do departamento de bases de datos. Dinnos: "Queremos monitorizar as nosas consultas SQL. E non teñen 255 caracteres, senón 8 MB cada unha. Queremos mostralas en Grafana, ver os parámetros desta consulta e, mellor aínda, queremos ver as consultas máis comúns. Sería xenial que se mostrasen en tempo real. E sería aínda máis interesante metelas nunha alerta".
O exemplo de consulta SQL tómase como exemplo de
Configuramos un servidor Redis e usamos os nosos complementos Collectd, que van a Postgres e toman todos os datos de alí, enviando métricas a Graphite. Pero substituímos o nome da métrica por hash. Simultáneamente enviamos o mesmo hash a Redis como clave e toda a consulta SQL como valor. Todo o que temos que facer é asegurarnos de que Grafana pode ir a Redis e levar esta información. Estamos abrindo a API de Graphite porque... esta é a interface principal para a interacción de todos os compoñentes de monitorización con grafito, e alí introducimos unha nova función chamada aliasByHash() - de Grafana obtemos o nome da métrica e utilízaa nunha solicitude a Redis como clave, en resposta obtemos o valor da clave, que é a nosa "consulta SQL" " Así, mostramos en Grafana unha visualización dunha consulta SQL, que en teoría era imposible mostrar alí, xunto con estatísticas sobre ela (chamadas, filas, tempo_total,...).
Resultados de
Dispoñibilidade O noso servizo de vixilancia está dispoñible 24 horas ao día, 7 días ao día desde calquera aplicación e calquera código. Se tes acceso a instalacións de almacenamento, podes escribir datos no servizo. A lingua non é importante, as decisións non son importantes. Só necesitas saber como abrir un socket, poñer alí unha métrica e pechar o socket.
Fiabilidade. Todos os compoñentes son tolerantes a fallos e manexan ben as nosas cargas.
Baixa barreira de entrada. Para usar este sistema, non é necesario aprender linguaxes de programación e consultas en Grafana. Só ten que abrir a súa aplicación, introducir nela un socket que enviará métricas a Graphite, pechala, abrir Grafana, crear alí paneis de control e ver o comportamento das súas métricas, recibindo notificacións a través de Moira.
Independencia. Podes facelo ti mesmo, sen a axuda dos enxeñeiros de DevOps. E esta é unha vantaxe, porque podes supervisar o teu proxecto agora mesmo, non tes que pedirlle a ninguén, nin para comezar a traballar nin para facer cambios.
A que pretendemos?
Todo o que se enumera a continuación non son só pensamentos abstractos, senón algo para o que polo menos se deron os primeiros pasos.
- Detector de anomalías. Queremos crear un servizo que irá aos nosos almacenamentos de grafito e comprobará cada métrica mediante varios algoritmos. Xa hai algoritmos que queremos ver, hai datos, sabemos como traballar con eles.
- Metadatos. Temos moitos servizos, cambian co paso do tempo, igual que a xente que traballa con eles. Manter manualmente a documentación constantemente non é unha opción. É por iso que agora incorporamos metadatos nos nosos microservizos. Indica quen o desenvolveu, os idiomas cos que interactúa, os requisitos de SLA, onde e a quen se deben enviar as notificacións. Cando se implementa un servizo, todos os datos da entidade créanse de forma independente. Como resultado, obtén dúas ligazóns: unha para activadores e outra para paneis de control en Grafana.
- Vixilancia en cada fogar. Cremos que todos os desenvolvedores deberían usar ese sistema. Neste caso, sempre entendes onde está o teu tráfico, que lle pasa, onde cae, onde están os seus puntos débiles. Se, por exemplo, chega algo e falla o teu servizo, aprenderás sobre iso non durante unha chamada do xestor, senón mediante unha alerta, e poderás abrir inmediatamente os rexistros máis recentes e ver o que pasou alí.
- Alto rendemento. O noso proxecto está en constante crecemento, e hoxe procesa uns 2 de valores métricos por minuto. Hai un ano, esta cifra era de 000 000. E o crecemento continúa, e isto significa que despois dun tempo Graphite (susurro) comezará a cargar moito o subsistema do disco. Como xa dixen, este sistema de monitorización é bastante universal debido á intercambiabilidade de compoñentes. Alguén mantén e amplía constantemente a súa infraestrutura específicamente para Graphite, pero decidimos seguir unha ruta diferente: utilizar como repositorio para as nosas métricas. Esta transición xa está case completa, e moi pronto contarei con máis detalle como se fixo: que dificultades houbo e como se superaron, como foi o proceso de migración, describirei os compoñentes escollidos como vinculantes e as súas configuracións.
Grazas pola súa atención! Fai as túas preguntas sobre o tema, tentarei responder aquí ou nas seguintes publicacións. Quizais alguén teña experiencia construíndo un sistema de monitorización similar ou cambiando a Clickhouse nunha situación similar; compárteo nos comentarios.
Fonte: www.habr.com
