


Entrada
Ola!
Neste artigo compartirei a miña experiencia na construción dunha arquitectura de microservizos para un proxecto utilizando redes neuronais.
Falemos dos requisitos da arquitectura, miremos varios diagramas estruturais, analicemos cada un dos compoñentes da arquitectura acabada e tamén avalemos as métricas técnicas da solución.
Goza de lectura!
Unhas palabras sobre o problema e a súa solución
A idea principal é avaliar o atractivo dunha persoa nunha escala de dez puntos baseada nunha foto.
Neste artigo afastarémonos de describir tanto as redes neuronais empregadas como o proceso de preparación e adestramento dos datos. Non obstante, nunha das seguintes publicacións, definitivamente volveremos a analizar en profundidade o proceso de avaliación.
Agora pasaremos polo pipeline de avaliación no nivel superior e centrarémonos na interacción dos microservizos no contexto da arquitectura global do proxecto.
Ao traballar no pipeline de avaliación do atractivo, a tarefa descompuxose nos seguintes compoñentes:
- Selección de rostros nas fotos
- Valoración de cada persoa
- Mostra o resultado
O primeiro é resolto polas forzas de pre-adestrados . Para o segundo, adestrouse unha rede neuronal convolucional en PyTorch, utilizando - do balance "calidade / velocidade de inferencia na CPU"

Diagrama funcional da canalización de avaliación
Análise dos requisitos da arquitectura do proxecto
No ciclo vital As fases de traballo do proxecto sobre a arquitectura e a automatización do despregamento de modelos adoitan estar entre as que consumen máis tempo e recursos.
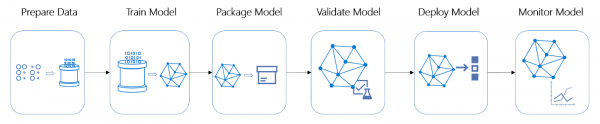
Ciclo de vida dun proxecto de ML
Este proxecto non é unha excepción: tomouse a decisión de envolver o pipeline de avaliación nun servizo en liña, o que requiriu mergullarnos na arquitectura. Identificáronse os seguintes requisitos básicos:
- Almacenamento de rexistros unificado: todos os servizos deben escribir rexistros nun só lugar, deben ser convenientes para analizalos
- Posibilidade de escalado horizontal do servizo de avaliación - como o pescozo de botella máis probable
- Débese asignar a mesma cantidade de recursos do procesador para avaliar cada imaxe co fin de evitar valores atípicos na distribución do tempo de inferencia.
- (re)impregamento rápido tanto de servizos específicos como da pila no seu conxunto
- A capacidade, se é necesario, de utilizar obxectos comúns en diferentes servizos
Arquitectura
Despois de analizar os requisitos, quedou obvio que a arquitectura de microservizos encaixa case perfectamente.
Para desfacerse de dores de cabeza innecesarios, escolleuse a API de Telegram como frontend.
En primeiro lugar, vexamos o diagrama estrutural da arquitectura acabada, despois pasemos á descrición de cada un dos compoñentes e tamén formalicemos o proceso de procesamento de imaxes exitoso.
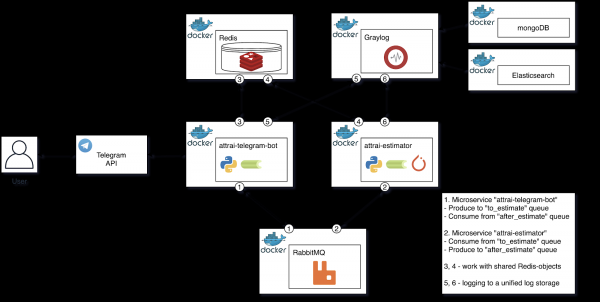
Esquema estrutural da arquitectura acabada
Falemos con máis detalle de cada un dos compoñentes do diagrama, denotándoos Responsabilidade Única no proceso de avaliación da imaxe.
Microservizo "attrai-telegram-bot"
Este microservizo encapsula todas as interaccións coa API de Telegram. Hai 2 escenarios principais: traballar cunha imaxe personalizada e traballar co resultado dun pipeline de avaliación. Vexamos os dous escenarios en termos xerais.
Cando recibas unha mensaxe personalizada cunha imaxe:
- Realízase a filtración, que consiste nas seguintes comprobacións:
- Dispoñibilidade dun tamaño de imaxe óptimo
- Número de imaxes de usuario que xa están na cola
- Ao pasar o filtrado inicial, a imaxe gárdase no volume docker
- Prodúcese unha tarefa na cola "to_estimate", que inclúe, entre outras cousas, o camiño ata a imaxe situada no noso volume
- Se os pasos anteriores se completan con éxito, o usuario recibirá unha mensaxe co tempo aproximado de procesamento da imaxe, que se calcula en función do número de tarefas na cola. Se se produce un erro, o usuario será notificado explícitamente enviando unha mensaxe con información sobre o que puido ter fallado.
Ademais, este microservizo, como un traballador de apio, escoita a cola "after_estimate", que está destinada a tarefas que pasaron pola canalización de avaliación.
Ao recibir unha nova tarefa de "after_estimate":
- Se a imaxe se procesa correctamente, enviámoslle o resultado ao usuario; se non, avisamos dun erro.
- Eliminando a imaxe que é resultado do pipeline de avaliación
Microservizo de avaliación “attrai-estimator”
Este microservizo é un traballador do apio e encapsula todo o relacionado co pipeline de avaliación de imaxes. Aquí só hai un algoritmo de traballo: analicemos.
Ao recibir unha nova tarefa de "to_estimate":
- Imos executar a imaxe a través do pipeline de avaliación:
- Cargando a imaxe na memoria
- Traemos a imaxe ao tamaño necesario
- Buscando todas as caras (MTCNN)
- Avaliamos todas as caras (envolvemos as caras atopadas no último paso nun lote e inferimos ResNet34)
- Renderizar a imaxe final
- Imos debuxar os cadros delimitadores
- Debuxo das valoracións
- Eliminando unha imaxe personalizada (orixinal).
- Gardando a saída do pipeline de avaliación
- Poñemos a tarefa na cola "after_estimate", que escoita o microservizo "attrai-telegram-bot" comentado anteriormente.
Graylog (+ mongoDB + Elasticsearch)
é unha solución para a xestión centralizada de rexistros. Neste proxecto, utilizouse para o propósito previsto.
A elección recaeu nel, e non na habitual pila, debido á comodidade de traballar con el desde Python. Todo o que tes que facer para iniciar sesión en Graylog é engadir o GELFTCPHandler do paquete ao resto dos controladores de rexistro raíz do noso microservizo Python.
Como alguén que anteriormente só traballara coa pila ELK, tiven unha experiencia global positiva ao traballar con Graylog. O único que é deprimente é a superioridade das funcións de Kibana sobre a interface web de Graylog.
CoelloMQ
é un corredor de mensaxes baseado no protocolo AMQP.
Neste proxecto utilizouse como corredor de apio e traballou en modo duradeiro.
Redis
é un DBMS NoSQL que funciona con estruturas de datos clave-valor
Ás veces é necesario utilizar obxectos comúns que implementen determinadas estruturas de datos en diferentes microservizos de Python.
Por exemplo, Redis almacena un hashmap da forma "telegram_user_id => número de tarefas activas na cola", o que permite limitar o número de solicitudes dun usuario a un determinado valor e, así, evitar ataques DoS.
Formalicemos o proceso de procesamento de imaxes exitoso
- O usuario envía unha imaxe ao bot de Telegram
- "attrai-telegram-bot" recibe unha mensaxe da API de Telegram e analízaa
- A tarefa coa imaxe engádese á cola asíncrona "to_estimate"
- O usuario recibe unha mensaxe co tempo de avaliación previsto
- "attrai-estimator" toma unha tarefa da cola "to_estimate", executa as estimacións a través da canalización e produce a tarefa na cola "after_estimate"
- "attrai-telegram-bot" escoitando a cola "after_estimate", envía o resultado ao usuario
DevOps
Finalmente, despois de revisar a arquitectura, podes pasar á parte igualmente interesante: DevOps
Enxame Docker

— un sistema de agrupación, cuxa funcionalidade está implementada dentro do motor Docker e está dispoñible de forma inmediata.
Usando un "enxame", todos os nós do noso clúster pódense dividir en dous tipos: traballador e xestor. Nas máquinas do primeiro tipo despréganse grupos de contedores (pilas), as máquinas do segundo tipo encárganse de escalar, equilibrar e . Os directivos tamén son traballadores por defecto.
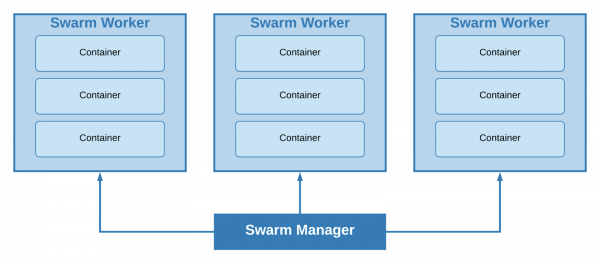
Clúster cun xerente líder e tres traballadores
O tamaño mínimo de clúster posible é de 1 nodo; unha única máquina actuará simultáneamente como xestor líder e traballador. En función do tamaño do proxecto e dos requisitos mínimos de tolerancia a fallos, decidiuse utilizar este enfoque.
De cara ao futuro, direi que dende a primeira entrega de produción, que foi a mediados de xuño, non houbo problemas asociados a esta organización do clúster (pero isto non significa que tal organización sexa de ningún xeito aceptable en calquera medio-grande proxectos, que están suxeitos a requisitos de tolerancia a fallos).
Docker Stack
No modo enxame, el é o responsable da implantación de pilas (conxuntos de servizos docker)
Admite configuracións docker-compose, o que lle permite usar adicionalmente as opcións de implementación.
Por exemplo, usando estes parámetros, os recursos para cada unha das instancias do microservizo de avaliación eran limitados (asignamos N núcleos para N instancias, no propio microservizo limitamos o número de núcleos utilizados por PyTorch a un)
attrai_estimator:
image: 'erqups/attrai_estimator:1.2'
deploy:
replicas: 4
resources:
limits:
cpus: '4'
restart_policy:
condition: on-failure
…É importante ter en conta que Redis, RabbitMQ e Graylog son servizos con estado e non se poden escalar tan facilmente como "atrai-estimator"
Prefigurando a pregunta: por que non Kubernetes?
Parece que usar Kubernetes en proxectos pequenos e medianos é unha sobrecarga; toda a funcionalidade necesaria pódese obter de Docker Swarm, que é bastante fácil de usar para un orquestrador de contedores e tamén ten unha baixa barreira de entrada.
A Infraestrutura
Todo isto foi despregado en VDS coas seguintes características:
- CPU: CPU Intel® Xeon® Gold 4 de 5120 núcleos a 2.20 GHz
- RAM: 8 GB
- SSD: 160 GB
Despois da proba de carga local, parecía que cunha afluencia seria de usuarios esta máquina sería suficiente.
Pero, inmediatamente despois da implantación, publiquei unha ligazón a un dos cadros de imaxes máis populares do CIS (si, ese mesmo), despois de que a xente se interesou e en poucas horas o servizo procesou con éxito decenas de miles de imaxes. Ao mesmo tempo, nos momentos pico, os recursos de CPU e RAM non se usaban nin a metade.
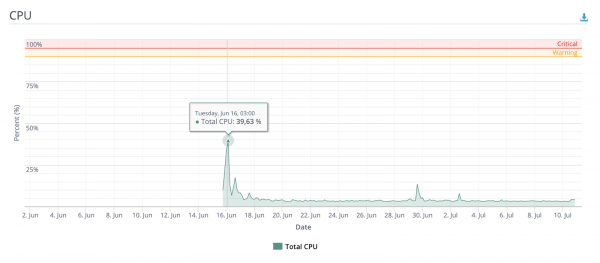
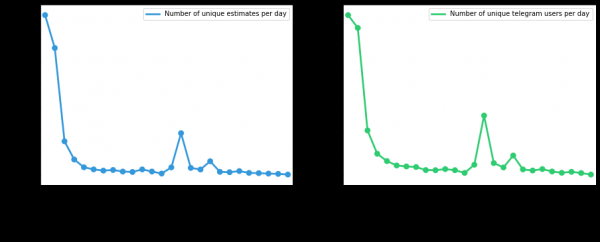
Algúns gráficos máis
Número de usuarios únicos e solicitudes de avaliación desde a implantación, dependendo do día
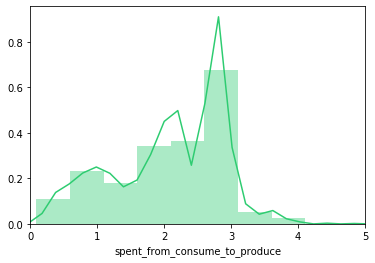
Distribución do tempo de inferencia de pipeline de avaliación
Descubrimentos
En resumo, podo dicir que a arquitectura e o enfoque da orquestración dos contedores xustificábanse por si mesmos, mesmo nos momentos de punta non houbo caídas nin caídas no tempo de procesamento.
Creo que os proxectos pequenos e medianos que usan a inferencia en tempo real de redes neuronais na CPU no seu proceso poden adoptar con éxito as prácticas descritas neste artigo.
Engaderei que inicialmente o artigo era máis longo, pero para non publicar unha lectura longa, decidín omitir algúns puntos neste artigo; volveremos sobre eles en próximas publicacións.
Podes picar o bot en Telegram - @AttraiBot, funcionará polo menos ata finais do outono de 2020. Permíteme recordarche que non se almacenan datos do usuario, nin as imaxes orixinais nin os resultados do pipeline de avaliación, todo é demolido despois do procesamento.
Fonte: www.habr.com
