

Anuncio
Compañeiros, a mediados do verán planeo lanzar outra serie de artigos sobre o deseño de sistemas de colas: "O experimento VTrade" - un intento de escribir un marco para sistemas de negociación. A serie examinará a teoría e a práctica de construír un intercambio, poxa e tenda. Ao final do artigo convídovos a votar polos temas que máis vos interesen.

Este é o artigo final da serie sobre aplicacións reactivas distribuídas en Erlang/Elixir. EN podes atopar os fundamentos teóricos da arquitectura reactiva. ilustra os patróns e mecanismos básicos para construír tales sistemas.
Hoxe abordaremos cuestións de desenvolvemento do código base e dos proxectos en xeral.
Organización dos servizos
Na vida real, ao desenvolver un servizo, moitas veces tes que combinar varios patróns de interacción nun controlador. Por exemplo, o servizo de usuarios, que resolve o problema da xestión dos perfís de usuarios do proxecto, debe responder ás solicitudes de req-resp e informar das actualizacións dos perfís a través de pub-sub. Este caso é bastante sinxelo: detrás da mensaxería hai un controlador que implementa a lóxica do servizo e publica actualizacións.
A situación complícase máis cando necesitamos implementar un servizo distribuído tolerante a fallos. Imaxinemos que os requisitos para os usuarios cambiaron:
- agora o servizo debería procesar solicitudes en 5 nodos do clúster,
- ser capaz de realizar tarefas de procesamento en segundo plano,
- e tamén poder xestionar de forma dinámica listas de subscricións para actualizacións de perfil.
Comentario: Non consideramos o problema do almacenamento coherente e a replicación de datos. Supoñamos que estes problemas se resolveron antes e que o sistema xa ten unha capa de almacenamento fiable e escalable, e que os controladores teñen mecanismos para interactuar con ela.
A descrición formal do servizo de usuarios volveuse máis complicada. Desde o punto de vista dun programador, os cambios son mínimos debido ao uso da mensaxería. Para satisfacer o primeiro requisito, necesitamos configurar o equilibrio no punto de intercambio req-resp.
O requisito de procesar tarefas en segundo plano ocorre con frecuencia. Nos usuarios, isto podería ser a comprobación de documentos de usuario, o procesamento de multimedia descargada ou a sincronización de datos coas redes sociais. redes. Estas tarefas deben distribuírse dalgún xeito dentro do clúster e supervisar o progreso da execución. Polo tanto, temos dúas opcións de solución: ou ben utilizar o modelo de distribución de tarefas do artigo anterior ou, se non convén, escribir un programador de tarefas personalizado que xestionará o conxunto de procesadores do xeito que necesitemos.
O punto 3 require a extensión do modelo pub-sub. E para a implementación, despois de crear un punto de intercambio pub-sub, necesitamos lanzar adicionalmente o controlador deste punto dentro do noso servizo. Así, é coma se estiveramos trasladando a lóxica de procesamento de subscricións e baixas da capa de mensaxería á implementación dos usuarios.
Como resultado, a descomposición do problema mostrou que, para cumprir os requisitos, necesitamos lanzar 5 instancias do servizo en diferentes nodos e crear unha entidade adicional: un controlador pub-sub, responsable da subscrición.
Para executar 5 controladores, non é necesario cambiar o código de servizo. A única acción adicional é establecer regras de equilibrio no punto de intercambio, das que falaremos un pouco máis adiante.
Tamén hai unha complexidade adicional: o controlador pub-sub e o programador de tarefas personalizados deben funcionar nunha única copia. De novo, o servizo de mensaxería, como fundamental, debe proporcionar un mecanismo para seleccionar un líder.
Selección do líder
Nos sistemas distribuídos, a elección do líder é o procedemento para nomear un único proceso responsable de programar o procesamento distribuído dalgunha carga.
En sistemas que non son propensos á centralización, utilízanse algoritmos universais e baseados no consenso, como os paxos ou a balsa.
Dado que a mensaxería é un intermediario e un elemento central, coñece todos os controladores de servizos: líderes candidatos. A mensaxería pode nomear un líder sen votar.
Despois de iniciar e conectarse ao punto de intercambio, todos os servizos reciben unha mensaxe do sistema #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers}. Se LeaderPid coincide con pid proceso actual, é nomeado como líder, e a lista Servers inclúe todos os nodos e os seus parámetros.
No momento en que aparece un novo e un nodo de clúster en funcionamento está desconectado, todos os controladores de servizo reciben #'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} и #'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} respectivamente.
Deste xeito, todos os compoñentes son conscientes de todos os cambios, e o clúster ten garantido ter un líder en cada momento.
Intermediarios
Para implementar procesos de procesamento distribuído complexos, así como en problemas de optimización dunha arquitectura existente, é conveniente utilizar intermediarios.
Para non cambiar o código do servizo e resolver, por exemplo, problemas de procesamento, enrutamento ou rexistro de mensaxes adicionais, pode activar un controlador de proxy antes do servizo, que realizará todo o traballo adicional.
Un exemplo clásico de optimización pub-sub é unha aplicación distribuída cun núcleo empresarial que xera eventos de actualización, como cambios de prezos no mercado, e unha capa de acceso: N servidores que proporcionan unha API websocket para clientes web.
Se decides de frente, o servizo de atención ao cliente é o seguinte:
- o cliente establece conexións coa plataforma. No lado do servidor que finaliza o tráfico, lánzase un proceso para atender esta conexión.
- No contexto do proceso de servizo, prodúcense a autorización e subscrición ás actualizacións. O proceso chama ao método de subscrición para os temas.
- Unha vez que se xera un evento no núcleo, entrégase aos procesos que atenden as conexións.
Imaxinemos que temos 50000 subscritores ao tema "noticias". Os subscritores distribúense uniformemente en 5 servidores. Como resultado, cada actualización, que chega ao punto de intercambio, replicarase 50000 veces: 10000 veces en cada servidor, segundo o número de subscritores no mesmo. Non é un esquema moi efectivo, non?
Para mellorar a situación, introduzamos un proxy que teña o mesmo nome que o punto de intercambio. O rexistrador global de nomes debe ser capaz de devolver o proceso máis próximo polo nome, isto é importante.
Imos lanzar este proxy nos servidores da capa de acceso, e todos os nosos procesos que serven a API websocket subscribiranse a el, e non ao punto de intercambio pub-sub orixinal do núcleo. Proxy subscríbese ao núcleo só no caso dunha subscrición única e replica a mensaxe entrante a todos os seus subscritores.
Como resultado, enviaranse 5 mensaxes entre o núcleo e os servidores de acceso, en lugar de 50000.
Enrutamento e equilibrio
Req-Resp
Na implementación actual de mensaxería, hai 7 estratexias de distribución de solicitudes:
default. A solicitude envíase a todos os controladores.round-robin. As solicitudes son enumeradas e distribúense cíclicamente entre os controladores.consensus. Os controladores que serven o servizo divídense en líderes e escravos. As solicitudes envíanse só ao líder.consensus & round-robin. O grupo ten un líder, pero as solicitudes repártense entre todos os membros.sticky. A función hash calcúlase e asígnase a un controlador específico. As solicitudes posteriores con esta sinatura van ao mesmo xestor.sticky-fun. Ao inicializar o punto de intercambio, a función de cálculo hash parastickyequilibrando.fun. Do mesmo xeito que sticky-fun, só ti podes redirixilo, rexeitalo ou preprocesalo.
A estratexia de distribución establécese cando se inicializa o punto de intercambio.
Ademais de equilibrar, a mensaxería permítelle etiquetar entidades. Vexamos os tipos de etiquetas do sistema:
- Etiqueta de conexión. Permite comprender a través de que conexión se produciron os eventos. Utilízase cando un proceso controlador se conecta ao mesmo punto de intercambio, pero con claves de enrutamento diferentes.
- Etiqueta de servizo. Permítelle combinar controladores en grupos para un servizo e ampliar as capacidades de enrutamento e equilibrio. Para o patrón req-resp, o enrutamento é lineal. Enviamos unha solicitude ao punto de intercambio, despois pásao ao servizo. Pero se necesitamos dividir os controladores en grupos lóxicos, entón a división faise usando etiquetas. Ao especificar unha etiqueta, a solicitude enviarase a un grupo específico de controladores.
- Solicitar etiqueta. Permite distinguir entre respostas. Dado que o noso sistema é asíncrono, para procesar as respostas do servizo debemos poder especificar unha RequestTag ao enviar unha solicitude. A partir del poderemos entender a resposta a que solicitude nos chegou.
Pub-sub
Para pub-sub todo é un pouco máis sinxelo. Temos un punto de intercambio no que se publican as mensaxes. O punto de intercambio distribúe as mensaxes entre os subscritores que se subscribían ás claves de enrutamento que necesitan (podemos dicir que isto é análogo aos temas).
Escalabilidade e tolerancia a fallos
A escalabilidade do sistema no seu conxunto depende do grao de escalabilidade das capas e compoñentes do sistema:
- Os servizos escalan engadindo nodos adicionais ao clúster con controladores para este servizo. Durante a operación de proba, pode escoller a política de equilibrio óptimo.
- O servizo de mensaxería en si dentro dun clúster separado é xeralmente escalado movendo puntos de intercambio particularmente cargados a nós de clúster separados ou engadindo procesos proxy a áreas do clúster especialmente cargadas.
- A escalabilidade de todo o sistema como característica depende da flexibilidade da arquitectura e da capacidade de combinar clusters individuais nunha entidade lóxica común.
O éxito dun proxecto depende a miúdo da sinxeleza e da velocidade de escalado. A mensaxería na súa versión actual crece xunto coa aplicación. Aínda que carezamos dun clúster de 50-60 máquinas, podemos recorrer á federación. Desafortunadamente, o tema da federación está fóra do alcance deste artigo.
Reserva
Ao analizar o equilibrio de carga, xa falamos da redundancia dos controladores de servizo. Non obstante, tamén hai que reservar a mensaxería. No caso dun fallo de nodo ou máquina, a mensaxería debería recuperarse automaticamente e no menor tempo posible.
Nos meus proxectos uso nodos adicionais que recollen a carga en caso de caída. Erlang ten unha implementación estándar en modo distribuído para aplicacións OTP. O modo distribuído realiza a recuperación en caso de fallo iniciando a aplicación fallida noutro nodo iniciado previamente. O proceso é transparente; despois dun fallo, a aplicación móvese automaticamente ao nodo de conmutación por fallo. Podes ler máis sobre esta función .
Produtividade
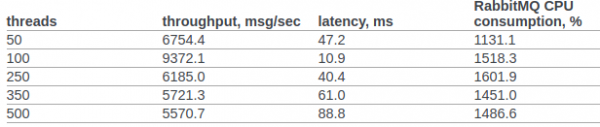
Tentemos comparar polo menos o rendemento de rabbitmq e a nosa mensaxe personalizada.
Atopei proba rabbitmq do equipo de openstack.
No punto 6.14.1.2.1.2.2. O documento orixinal mostra o resultado do RPC CAST:
Non faremos ningunha configuración adicional para o kernel do sistema operativo ou erlang VM con antelación. Condicións para a proba:
- erl opta: +A1 +sbtu.
- A proba dentro dun único nodo erlang realízase nun portátil cun i7 antigo na versión móbil.
- As probas de clúster realízanse en servidores cunha rede 10G.
- O código execútase en contedores docker. Rede en modo NAT.
Código de proba:
req_resp_bench(_) ->
W = perftest:comprehensive(10000,
fun() ->
messaging:request(?EXCHANGE, default, ping, self()),
receive
#'$msg'{message = pong} -> ok
after 5000 ->
throw(timeout)
end
end
),
true = lists:any(fun(E) -> E >= 30000 end, W),
ok.Escenario 1: A proba realízase nun portátil cunha versión móbil antiga i7. A proba, a mensaxería e o servizo execútanse nun nodo nun contedor Docker:
Sequential 10000 cycles in ~0 seconds (26987 cycles/s)
Sequential 20000 cycles in ~1 seconds (26915 cycles/s)
Sequential 100000 cycles in ~4 seconds (26957 cycles/s)
Parallel 2 100000 cycles in ~2 seconds (44240 cycles/s)
Parallel 4 100000 cycles in ~2 seconds (53459 cycles/s)
Parallel 10 100000 cycles in ~2 seconds (52283 cycles/s)
Parallel 100 100000 cycles in ~3 seconds (49317 cycles/s)Escenario 2: 3 nodos que se executan en diferentes máquinas baixo docker (NAT).
Sequential 10000 cycles in ~1 seconds (8684 cycles/s)
Sequential 20000 cycles in ~2 seconds (8424 cycles/s)
Sequential 100000 cycles in ~12 seconds (8655 cycles/s)
Parallel 2 100000 cycles in ~7 seconds (15160 cycles/s)
Parallel 4 100000 cycles in ~5 seconds (19133 cycles/s)
Parallel 10 100000 cycles in ~4 seconds (24399 cycles/s)
Parallel 100 100000 cycles in ~3 seconds (34517 cycles/s)En todos os casos, a utilización da CPU non superou o 250%
Resultados de
Espero que este ciclo non pareza un vertedoiro mental e que a miña experiencia sexa de verdadeiro beneficio tanto para os investigadores de sistemas distribuídos como para os profesionais que están no inicio da construción de arquitecturas distribuídas para os seus sistemas empresariais e están mirando Erlang/Elixir con interese. , pero tes dúbidas, paga a pena...
foto
Só os usuarios rexistrados poden participar na enquisa. , por favor.
Que temas debo tratar con máis detalle como parte da serie VTrade Experiment?
Teoría: mercados, pedidos e a súa temporalización: DAY, GTD, GTC, IOC, FOK, MOO, MOC, LOO, LOC
Libro de pedidos. Teoría e práctica da implementación dun libro con agrupacións
Visualización de negociación: ticks, barras, resolucións. Como almacenar e como pegar
Backoffice. Planificación e desenvolvemento. Seguimento dos empregados e investigación de incidentes
API. Imos descubrir que interfaces son necesarias e como implementalas
Almacenamento de información: PostgreSQL, Timescale, Tarantool en sistemas de negociación
Reactividade nos sistemas comerciais
Outra. Vou escribir nos comentarios
Votaron 6 usuarios. 4 usuarios abstivéronse.
Fonte: www.habr.com
