

Boas tardes. Hai 2 anos que se escribiu. sobre analizar Habr, e algúns puntos cambiaron.
Cando quería ter unha copia de Habr, decidín escribir un analizador que gardara todo o contido dos autores na base de datos. Como pasou e que erros atopei: podes ler baixo o corte.
TLDR-
A primeira versión do analizador. Un fío, moitos problemas
Para comezar, decidín facer un prototipo de guión no que o artigo sería analizado e colocado na base de datos inmediatamente despois da descarga. Sen pensalo dúas veces, usei sqlite3, porque. era menos laborioso: non era necesario ter un servidor local, creado-parecía-eliminado e cousas así.
one_thread.py
from bs4 import BeautifulSoup
import sqlite3
import requests
from datetime import datetime
def main(min, max):
conn = sqlite3.connect('habr.db')
c = conn.cursor()
c.execute('PRAGMA encoding = "UTF-8"')
c.execute("CREATE TABLE IF NOT EXISTS habr(id INT, author VARCHAR(255), title VARCHAR(255), content TEXT, tags TEXT)")
start_time = datetime.now()
c.execute("begin")
for i in range(min, max):
url = "https://m.habr.com/post/{}".format(i)
try:
r = requests.get(url)
except:
with open("req_errors.txt") as file:
file.write(i)
continue
if(r.status_code != 200):
print("{} - {}".format(i, r.status_code))
continue
html_doc = r.text
soup = BeautifulSoup(html_doc, 'html.parser')
try:
author = soup.find(class_="tm-user-info__username").get_text()
content = soup.find(id="post-content-body")
content = str(content)
title = soup.find(class_="tm-article-title__text").get_text()
tags = soup.find(class_="tm-article__tags").get_text()
tags = tags[5:]
except:
author,title,tags = "Error", "Error {}".format(r.status_code), "Error"
content = "При парсинге этой странице произошла ошибка."
c.execute('INSERT INTO habr VALUES (?, ?, ?, ?, ?)', (i, author, title, content, tags))
print(i)
c.execute("commit")
print(datetime.now() - start_time)
main(1, 490406)Todo é clásico: usamos Beautiful Soup, solicitudes e un prototipo rápido está listo. Iso é só…
A descarga da páxina está nun fío
Se interrompes a execución do script, toda a base de datos non irá a ningún lado. Despois de todo, a confirmación realízase só despois de toda a análise.
Por suposto, pode realizar cambios na base de datos despois de cada inserción, pero entón o tempo de execución do script aumentará significativamente.Analizar os primeiros 100 artigos levoume 000 horas.
A continuación atopo o artigo do usuario , que lin e atopei algúns trucos de vida para acelerar este proceso:
- O uso de multithreading acelera a descarga ás veces.
- Podes obter non a versión completa do habr, senón a súa versión móbil.
Por exemplo, se un artigo cointegrado na versión de escritorio pesa 378 KB, na versión móbil xa é de 126 KB.
Segunda versión. Moitos fíos, prohibición temporal de Habr
Cando busquei en Internet sobre o tema do multithreading en Python, escollín a opción máis sinxela con multiprocessing.dummy, notei que aparecían problemas xunto co multithreading.
SQLite3 non quere traballar con máis dun fío.
fixo check_same_thread=False, pero este erro non é o único, ao tentar inserir na base de datos, ás veces ocorren erros que non puiden solucionar.
Por iso, decido abandonar a inserción instantánea de artigos directamente na base de datos e, lembrando a solución cointegrada, decido utilizar ficheiros, porque non hai problemas coa escritura multiproceso nun ficheiro.
Habr comeza a prohibir por usar máis de tres fíos.
Os intentos especialmente celosos de acceder a Habr poden acabar cunha prohibición de IP durante un par de horas. Polo tanto, só tes que usar 3 fíos, pero isto xa é bo, xa que o tempo para iterar máis de 100 artigos redúcese de 26 a 12 segundos.
Paga a pena notar que esta versión é bastante inestable e que as descargas caen periodicamente nunha gran cantidade de artigos.
async_v1.py
from bs4 import BeautifulSoup
import requests
import os, sys
import json
from multiprocessing.dummy import Pool as ThreadPool
from datetime import datetime
import logging
def worker(i):
currentFile = "files\{}.json".format(i)
if os.path.isfile(currentFile):
logging.info("{} - File exists".format(i))
return 1
url = "https://m.habr.com/post/{}".format(i)
try: r = requests.get(url)
except:
with open("req_errors.txt") as file:
file.write(i)
return 2
# Запись заблокированных запросов на сервер
if (r.status_code == 503):
with open("Error503.txt", "a") as write_file:
write_file.write(str(i) + "n")
logging.warning('{} / 503 Error'.format(i))
# Если поста не существует или он был скрыт
if (r.status_code != 200):
logging.info("{} / {} Code".format(i, r.status_code))
return r.status_code
html_doc = r.text
soup = BeautifulSoup(html_doc, 'html5lib')
try:
author = soup.find(class_="tm-user-info__username").get_text()
timestamp = soup.find(class_='tm-user-meta__date')
timestamp = timestamp['title']
content = soup.find(id="post-content-body")
content = str(content)
title = soup.find(class_="tm-article-title__text").get_text()
tags = soup.find(class_="tm-article__tags").get_text()
tags = tags[5:]
# Метка, что пост является переводом или туториалом.
tm_tag = soup.find(class_="tm-tags tm-tags_post").get_text()
rating = soup.find(class_="tm-votes-score").get_text()
except:
author = title = tags = timestamp = tm_tag = rating = "Error"
content = "При парсинге этой странице произошла ошибка."
logging.warning("Error parsing - {}".format(i))
with open("Errors.txt", "a") as write_file:
write_file.write(str(i) + "n")
# Записываем статью в json
try:
article = [i, timestamp, author, title, content, tm_tag, rating, tags]
with open(currentFile, "w") as write_file:
json.dump(article, write_file)
except:
print(i)
raise
if __name__ == '__main__':
if len(sys.argv) < 3:
print("Необходимы параметры min и max. Использование: async_v1.py 1 100")
sys.exit(1)
min = int(sys.argv[1])
max = int(sys.argv[2])
# Если потоков >3
# то хабр банит ipшник на время
pool = ThreadPool(3)
# Отсчет времени, запуск потоков
start_time = datetime.now()
results = pool.map(worker, range(min, max))
# После закрытия всех потоков печатаем время
pool.close()
pool.join()
print(datetime.now() - start_time)Terceira versión. Final
Mentres depuraba a segunda versión, descubrín que Habr, de súpeto, ten unha API á que accede a versión móbil do sitio. Carga máis rápido que a versión móbil, xa que é só json, que nin sequera precisa ser analizado. Ao final, decidín reescribir o meu guión de novo.
Entón, tendo atopado API, podes comezar a analizalo.
async_v2.py
import requests
import os, sys
import json
from multiprocessing.dummy import Pool as ThreadPool
from datetime import datetime
import logging
def worker(i):
currentFile = "files\{}.json".format(i)
if os.path.isfile(currentFile):
logging.info("{} - File exists".format(i))
return 1
url = "https://m.habr.com/kek/v1/articles/{}/?fl=ru%2Cen&hl=ru".format(i)
try:
r = requests.get(url)
if r.status_code == 503:
logging.critical("503 Error")
return 503
except:
with open("req_errors.txt") as file:
file.write(i)
return 2
data = json.loads(r.text)
if data['success']:
article = data['data']['article']
id = article['id']
is_tutorial = article['is_tutorial']
time_published = article['time_published']
comments_count = article['comments_count']
lang = article['lang']
tags_string = article['tags_string']
title = article['title']
content = article['text_html']
reading_count = article['reading_count']
author = article['author']['login']
score = article['voting']['score']
data = (id, is_tutorial, time_published, title, content, comments_count, lang, tags_string, reading_count, author, score)
with open(currentFile, "w") as write_file:
json.dump(data, write_file)
if __name__ == '__main__':
if len(sys.argv) < 3:
print("Необходимы параметры min и max. Использование: asyc.py 1 100")
sys.exit(1)
min = int(sys.argv[1])
max = int(sys.argv[2])
# Если потоков >3
# то хабр банит ipшник на время
pool = ThreadPool(3)
# Отсчет времени, запуск потоков
start_time = datetime.now()
results = pool.map(worker, range(min, max))
# После закрытия всех потоков печатаем время
pool.close()
pool.join()
print(datetime.now() - start_time)
Contén campos relacionados tanto co propio artigo como co autor que o escribiu.
API.png
Non volquei o json completo de cada artigo, pero gardei só os campos que necesitaba:
- id
- é_titorial
- tempo_publicado
- título
- contido
- comentarios_conto
- lang é a lingua na que está escrito o artigo. Ata agora, só ten en e ru.
- tags_string: todas as etiquetas da publicación
- conta_lecturas
- Author
- puntuación — clasificación do artigo.
Así, usando a API, reducín o tempo de execución do script a 8 segundos por 100 URL.
Despois de descargar os datos que necesitamos, debemos procesalos e introducilos na base de datos. Tampouco tiven ningún problema con isto:
analizador.py
import json
import sqlite3
import logging
from datetime import datetime
def parser(min, max):
conn = sqlite3.connect('habr.db')
c = conn.cursor()
c.execute('PRAGMA encoding = "UTF-8"')
c.execute('PRAGMA synchronous = 0') # Отключаем подтверждение записи, так скорость увеличивается в разы.
c.execute("CREATE TABLE IF NOT EXISTS articles(id INTEGER, time_published TEXT, author TEXT, title TEXT, content TEXT,
lang TEXT, comments_count INTEGER, reading_count INTEGER, score INTEGER, is_tutorial INTEGER, tags_string TEXT)")
try:
for i in range(min, max):
try:
filename = "files\{}.json".format(i)
f = open(filename)
data = json.load(f)
(id, is_tutorial, time_published, title, content, comments_count, lang,
tags_string, reading_count, author, score) = data
# Ради лучшей читаемости базы можно пренебречь читаемостью кода. Или нет?
# Если вам так кажется, можно просто заменить кортеж аргументом data. Решать вам.
c.execute('INSERT INTO articles VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)', (id, time_published, author,
title, content, lang,
comments_count, reading_count,
score, is_tutorial,
tags_string))
f.close()
except IOError:
logging.info('FileNotExists')
continue
finally:
conn.commit()
start_time = datetime.now()
parser(490000, 490918)
print(datetime.now() - start_time)
estatística
Ben, tradicionalmente, finalmente, podes extraer algunhas estatísticas dos datos:
- Das 490 descargas previstas, só se descargaron 406 artigos. Resulta que máis da metade (228) dos artigos sobre Habré estaban agochados ou borrados.
- Toda a base de datos, formada por case medio millón de artigos, pesa 2.95 GB. En forma comprimida - 495 MB.
- En total, 37804 persoas son os autores de Habré. Lémbrovos que estas estatísticas son só de publicacións en directo.
- O autor máis produtivo de Habré - - 8774 artigos.
- - 1448 plus
- — 1660841 vistas
- — 2444 comentarios
Ben, en forma de topsTop 15 autores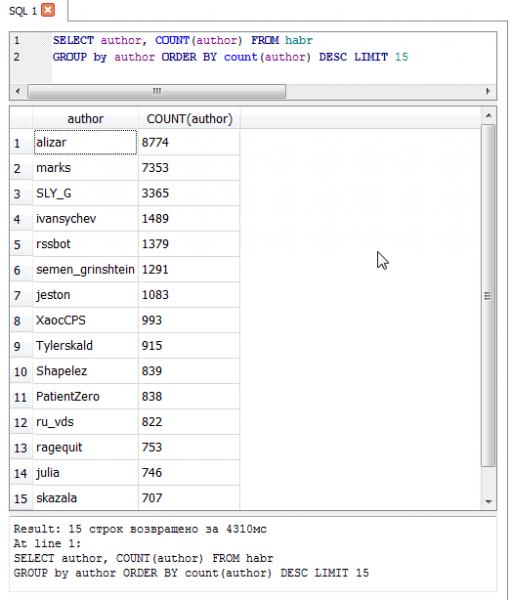
Top 15 por valoración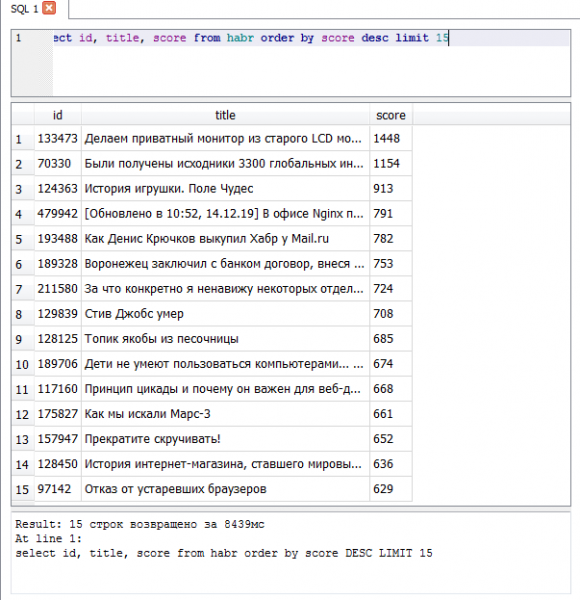
Top 15 de lecturas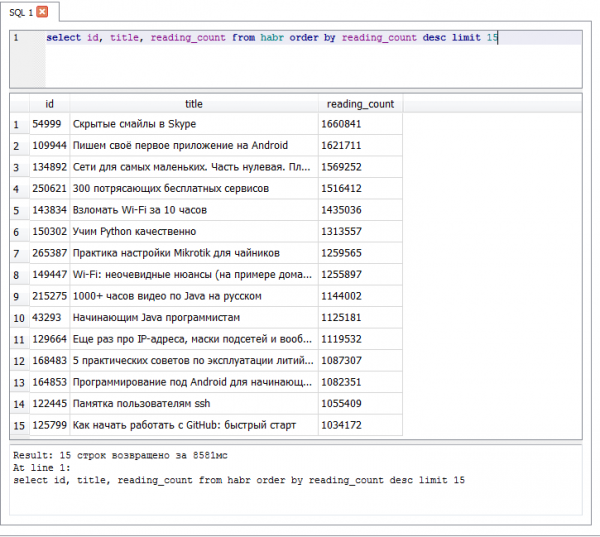
Top 15 discutidos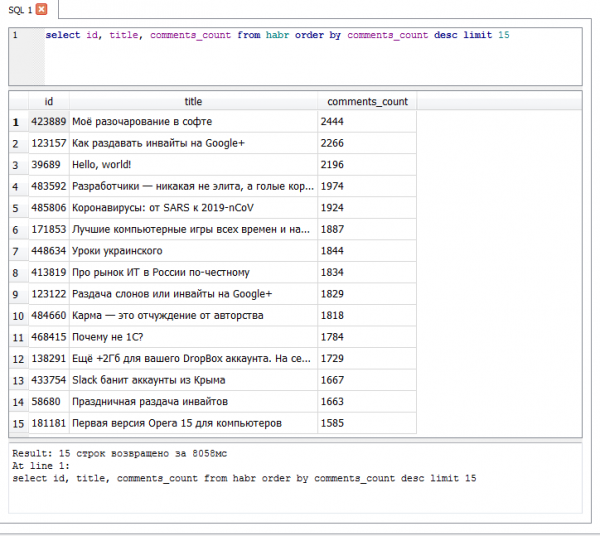
Fonte: www.habr.com
