

Ola a todos, compartimos con vós a segunda parte da publicación "Sistemas de ficheiros virtuais en LinuxPor que son necesarios e como funcionan? A primeira parte pódese ler . Lembrámosvos que esta serie de publicacións está programada para coincidir co lanzamento dun novo fluxo no curso , que comeza moi pronto.
Como supervisar VFS usando ferramentas eBPF e bcc
A forma máis sinxela de entender como funciona o núcleo nos ficheiros sysfs é velo na práctica, e a forma máis sinxela de ver ARM64 é usar eBPF. eBPF (abreviatura de Berkeley Packet Filter) consiste nunha máquina virtual en execución , que os usuarios con privilexios poden solicitar (query) desde a liña de comandos. As fontes do núcleo dinlle ao lector o que pode facer o núcleo; executar as ferramentas eBPF nun sistema cargado mostra o que está a facer realmente o núcleo.

Afortunadamente, comezar a usar eBPF é bastante sinxelo coa axuda de ferramentas , que están dispoñibles como paquetes da distribución xeral e documentado en detalle . Ferramentas bcc son scripts de Python con pequenas insercións de código C, o que significa que calquera persoa familiarizada con ambas linguaxes pode modificalas facilmente. EN bcc/tools Hai 80 scripts de Python, o que significa que o máis probable é que un desenvolvedor ou administrador do sistema poida escoller algo axeitado para resolver o problema.
Para ter polo menos unha idea superficial do traballo que fan os VFS nun sistema en execución, proba vfscount ou vfsstat. Isto mostrará, digamos, que ducias de chamadas vfs_open() e "os seus amigos" ocorren literalmente cada segundo.
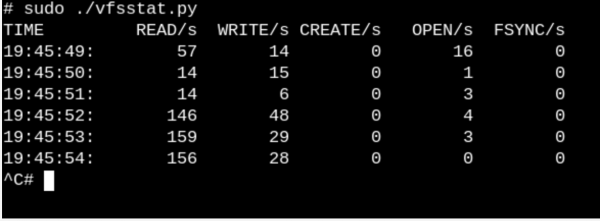
vfsstat.pyé un script de Python con insercións de código C que simplemente conta as chamadas de funcións VFS.
Poñamos un exemplo máis trivial e vexamos que pasa cando introducimos unha unidade flash USB nun ordenador e o sistema a detecta.
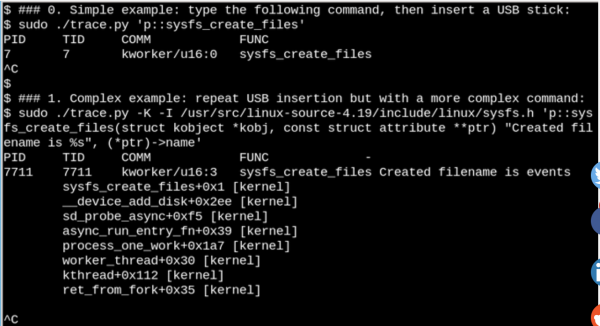
Usando eBPF podes ver o que está a suceder
/syscando se insira unha unidade flash USB. Aquí móstrase un exemplo sinxelo e complexo.
No exemplo mostrado anteriormente, bcc ferramenta imprime unha mensaxe cando se executa o comando sysfs_create_files(). Vemos iso sysfs_create_files() foi lanzado usando kworker transmitir en resposta ao feito de que se inseriu a unidade flash, pero que ficheiro se creou? O segundo exemplo mostra o poder de eBPF. Aquí trace.py Imprime unha traza inversa do núcleo (opción -K) e o nome do ficheiro que se creou sysfs_create_files(). A inserción dunha única instrución é un código C que inclúe unha cadea de formato facilmente recoñecible proporcionada polo script Python que executa LLVM compilador xusto a tempo. Compila esta liña e execútaa nunha máquina virtual dentro do núcleo. Sinatura de función completa sysfs_create_files () debe reproducirse no segundo comando para que a cadea de formato poida referirse a un dos parámetros. Os erros neste fragmento de código C producen erros recoñecibles do compilador C. Por exemplo, se se omite o parámetro -l, verá "Fallo ao compilar o texto BPF". Os desenvolvedores que estean familiarizados con C e Python atoparán as ferramentas bcc fácil de ampliar e cambiar.
Cando se insira a unidade USB, a traza inversa do núcleo mostrará que o PID 7711 é un fío kworkerque creou o ficheiro «events» в sysfs. En consecuencia, a chamada de sysfs_remove_files() mostrará que a eliminación da unidade provocou a eliminación do ficheiro events, que se corresponde co concepto xeral de reconto de referencia. Ao mesmo tempo, visualización sysfs_create_link () con eBPF ao inserir a unidade USB mostrará que se crearon polo menos 48 ligazóns simbólicas.
Entón, cal é o punto do ficheiro de eventos? Uso Para buscar , mostra o que provoca disk_add_events (), e tampouco "media_change"Ou "eject_request" pódese gravar nun ficheiro de eventos. Aquí a capa de bloque do núcleo informa ao espazo de usuario de que apareceu e expulsou un "disco". Teña en conta o informativo que é este método de investigación ao inserir unha unidade USB, en comparación con tentar descubrir como funcionan as cousas só desde a fonte.
Os sistemas de ficheiros raíz de só lectura permiten dispositivos incorporados
Por suposto, ninguén apaga o servidor nin o seu ordenador tirando do enchufe da toma. Pero por qué? Isto débese a que os sistemas de ficheiros montados en dispositivos de almacenamento físico poden ter escrituras atrasadas e as estruturas de datos que rexistran o seu estado poden non estar sincronizadas coas escrituras no almacenamento. Cando isto ocorre, os propietarios do sistema teñen que esperar ata o próximo inicio para iniciar a utilidade. fsck filesystem-recovery e, no peor dos casos, perder datos.
Non obstante, todos sabemos que moitos dispositivos da IoT, así como routers, termostatos e coches, agora funcionan con LinuxMoitos destes dispositivos practicamente non teñen interface de usuario e non hai xeito de apagalos de xeito sinxelo. Imaxina arrancar un coche cunha batería descargada cando se corta a alimentación do dispositivo de control. saltando constantemente arriba e abaixo. Como é que o sistema arranca sen moito tempo fsckcando por fin comeza a funcionar o motor? E a resposta é sinxela. Os dispositivos incorporados dependen do sistema de ficheiros raíz (abreviado ro-rootfs (sistema de ficheiros raíz de só lectura)).
ro-rootfs ofrecen moitos beneficios que son menos obvios que a autenticidade. Unha vantaxe é que o malware non pode escribir /usr ou /lib, se non hai ningún proceso Linux non se pode escribir nel. Outra é que un sistema de ficheiros en gran parte inmutable é crucial para o soporte de campo de dispositivos remotos, xa que o persoal de soporte usa sistemas locais que son nominalmente idénticos aos sistemas in situ. Quizais a vantaxe máis importante (pero tamén a máis insidiosa) sexa que ro-rootfs obriga aos desenvolvedores a decidir que obxectos do sistema serán inmutables ao principio do deseño do sistema. Traballar con ro-rootfs pode ser incómodo e doloroso, como adoita ocorrer coas variables const nas linguaxes de programación, pero os seus beneficios superan con creces a sobrecarga adicional.
creación rootfs A funcionalidade de só lectura require un esforzo adicional para os desenvolvedores integrados, e aquí é onde entra en xogo o VFS. Linux require que os ficheiros en /var eran escribibles e, ademais, moitas aplicacións populares que executan sistemas integrados tentarán crear unha configuración dot-files в $HOME. Unha solución para os ficheiros de configuración no directorio de inicio adoita ser xeralos previamente e incorporalos rootfs. Para /var Un enfoque posible é montalo nunha partición escribible separada, mentres / montado de só lectura. Outra alternativa popular é usar soportes de unión ou superposición.
Soportes enlazables e apilables, o seu uso por contedores
Execución de comandos man mount é a mellor forma de aprender sobre montaxes vinculables e superpostas, que ofrecen aos desenvolvedores e administradores de sistemas a posibilidade de crear un sistema de ficheiros nun camiño e despois expoñelo a aplicacións noutro. Para sistemas integrados, isto significa a capacidade de almacenar ficheiros /var nunha unidade flash de só lectura, pero unha ruta de montaxe superposta ou vinculable desde tmpfs в /var ao cargar, permitirá que as aplicacións escriban notas alí (scrawl). A próxima vez que active os cambios en /var perderase. Un soporte de superposición crea unha unión entre eles tmpfs e o sistema de ficheiros subxacente e permítelle facer cambios aparentes nos ficheiros existentes en ro-tootf mentres que unha montura vinculable pode facer outras novas baleiras tmpfs carpetas visibles como escribibles en ro-rootfs formas. Mentres overlayfs este é o correcto (proper) tipo de sistema de ficheiros, o montaxe vinculable está implementado en .
Con base na descrición da superposición e do montaxe vinculable, ninguén se sorprende úsanse activamente. A ver que pasa cando usamos para executar o contedor mediante a ferramenta mountsnoop de bcc.
Chamar system-nspawn inicia o contedor mentres se está a executar mountsnoop.py.
A ver que pasou:
Lanzamento mountsnoop mentres o contenedor está "iniciando" mostra que o tempo de execución do contenedor depende moito da montaxe que se está ligando (só se mostra o inicio da saída longa).
Aquí systemd-nspawn ofrece ficheiros seleccionados en procfs и sysfs host ao contenedor como camiños cara a el rootfs. Ademais MS_BIND marca que configura a montaxe vinculante, algunhas outras marcas na montaxe definen a relación entre os cambios nos espazos de nomes do host e do contenedor. Por exemplo, un montaxe ligado pode omitir cambios /proc и /sys no contedor ou ocultalos segundo a chamada.
Conclusión
Comprender a estrutura interna Linux pode parecer unha tarefa imposible, xa que o propio núcleo contén unha enorme cantidade de código, deixando de lado as aplicacións no espazo de usuario Linux e interfaces de chamadas de sistema en bibliotecas C como glibc. Unha forma de progresar é ler o código fonte dun subsistema do núcleo, facendo énfase na comprensión das chamadas do sistema e das cabeceiras do espazo de usuario, así como das principais interfaces internas do núcleo, como a táboa. file_operations. As operacións de ficheiros proporcionan o principio de "todo é un ficheiro", polo que son especialmente agradables de xestionar. Ficheiros fonte do núcleo C no directorio de nivel superior fs/ representan unha implementación de sistemas de ficheiros virtuais, que son unha capa envolvente que proporciona unha compatibilidade ampla e relativamente sinxela entre os sistemas de ficheiros e os dispositivos de almacenamento máis populares. Montaxe con vinculación e superposición a través de espazos de nomes Linux — é a maxia de VFS que permite crear contedores e sistemas de ficheiros raíz de só lectura. Combinado cun estudo do código fonte, a ferramenta do núcleo eBPF e a súa interface bcc
facendo a exploración do núcleo máis fácil que nunca.
Amigos, dicídeme se este artigo vos foi útil. Quizais teñades algún comentario ou suxestión? E para os interesados no curso de "Administrador", Linux", convidámosvos a , que terá lugar o 18 de abril.
Fonte: www.habr.com
