

Un bo xogo de escondite anticuado pode ser unha gran proba para que os bots de intelixencia artificial (IA) demostren como toman decisións e interactúan entre eles e con varios obxectos que os rodean.
No seu , publicado por investigadores de OpenAI, unha organización de investigación en intelixencia artificial sen ánimo de lucro que se fixo famosa no xogo de ordenador Dota 2, os científicos describen como os axentes controlados pola intelixencia artificial foron adestrados para ser máis sofisticados na procura e esconderse uns dos outros nun ambiente virtual. Os resultados do estudo demostraron que un equipo de dous bots aprende de forma máis eficaz e rápida que calquera axente sen aliados.

Os científicos utilizaron un método que durante moito tempo gañou a súa fama , na que a intelixencia artificial se sitúa nun entorno para ela descoñecido, ao tempo que ten determinadas formas de interactuar con ela, así como un sistema de recompensas e multas por un ou outro resultado das súas accións. Este método é bastante efectivo debido á capacidade da IA para realizar varias accións nun ambiente virtual a unha velocidade enorme, millóns de veces máis rápido do que unha persoa pode imaxinar. Isto permite a proba e erro para atopar as estratexias máis eficaces para resolver un determinado problema. Pero este enfoque tamén ten algunhas limitacións, por exemplo, a creación dun ambiente e a realización de numerosos ciclos formativos requiren enormes recursos informáticos e o propio proceso require un sistema preciso para comparar os resultados das accións de IA co seu obxectivo. Ademais, as habilidades adquiridas polo axente deste xeito limítanse á tarefa descrita e, unha vez que a IA aprenda a xestionala, non haberá máis melloras.
Para adestrar a IA para xogar ás escondidas, os científicos utilizaron un enfoque chamado "Exploración non dirixida", que é onde os axentes teñen total liberdade para desenvolver a súa comprensión do mundo do xogo e desenvolver estratexias gañadoras. Isto é similar ao enfoque de aprendizaxe multiaxente que os investigadores de DeepMind empregaron cando varios sistemas de intelixencia artificial . Como neste caso, os axentes de IA non estaban previamente adestrados nas regras do xogo, pero co paso do tempo aprenderon estratexias básicas e incluso foron capaces de sorprender aos investigadores con solucións non triviais.
Nunha partida de escondidas, varios axentes cuxo traballo consistía en esconderse víronse obrigados a evitar a liña de visión dos seus opoñentes tras unha lixeira vantaxe mentres o equipo de buscadores estaba inmobilizado. Ademais, a "liña de visión" neste contexto é un cono de 135 graos diante dun bot individual. Os axentes non podían aventurarse demasiado fóra da zona de xogo e víronse obrigados a navegar por salas xeradas aleatoriamente coa posibilidade de utilizar algúns obxectos externos (caixas, paredes móbiles, rampas especiais) espallados ao redor que podían utilizarse tanto para crear cobertura como para infiltrarse nelas. .
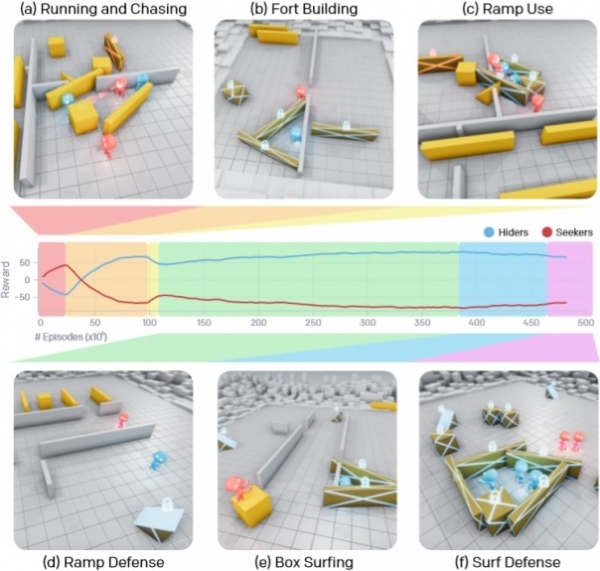
A través dun longo proceso de aprendizaxe, os axentes de IA aprenderon seis estratexias únicas, cada unha das cales lles axudou a avanzar á seguinte fase do xogo. Ao principio, os equipos de buscadores e escondidos simplemente fuxiron e perseguiron uns aos outros, pero despois de preto de 25 millóns de partidos, o equipo de escondidos aprendeu a bloquear os pasaxes con caixas e a construír abrigos fóra delas. Despois doutros 75 millóns de partidos, o equipo descubriu formas de usar ramplas para entrar nestes escondites. Despois de outros 10 millóns de roldas, os escondidos aprenderon a arrastrar ramplas ata o bordo da área de xogo e a bloquealas no seu lugar para evitar que os opoñentes as usasen.

Despois de 388 millóns de partidas, os buscadores aprenderon a usar ramplas bloqueadas para subirse ás caixas que se lles traían e, a continuación, movéndose directamente sobre elas, penetraron nos escondites inimigos creados a partir de paredes portátiles. E finalmente, despois de 458 millóns de partidos, o equipo escondido concluíu que necesitaban bloquear todos os obxectos e despois construír un refuxio, o que ao parecer levou á súa vitoria final.
O que é particularmente impresionante é que despois de 22 millóns de partidos, os axentes aprenderon a coordinar as súas accións e a eficiencia da súa colaboración só aumentou no futuro, por exemplo, cada un trouxo a súa propia caixa ou parede para crear un abrigo e elixiu a súa parte de obxectos. bloquear, para complicar o xogo de dificultade aos adversarios.

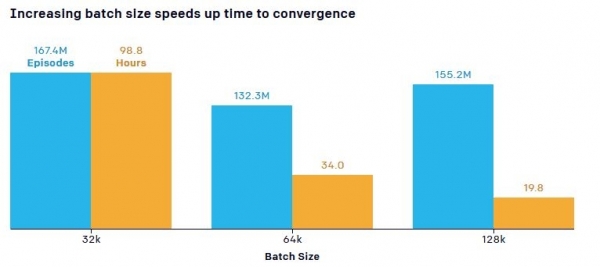
Os científicos tamén sinalaron un punto importante relacionado coa influencia do número de obxectos de adestramento (a cantidade de datos que pasan pola rede neuronal - "Tamaño do lote") na velocidade de aprendizaxe. O modelo predeterminado requiriu 132,3 millóns de partidos en 34 horas de adestramento para chegar ao punto no que o equipo escondido aprendeu a bloquear ramplas, mentres que máis datos resultou nunha notable redución do tempo de adestramento. Por exemplo, aumentar o número de parámetros (parte dos datos obtidos durante todo o proceso de adestramento) de 0,5 millóns a 5,8 millóns aumentou a eficiencia de mostraxe en 2,2 veces e o aumento do tamaño dos datos de entrada de 64 KB a 128 KB reduciu o adestramento. tempo case unha vez e media.
Ao final do seu traballo, os investigadores decidiron probar canto adestramento no xogo podería axudar aos axentes a facer fronte a tarefas similares fóra do xogo. Foron cinco probas en total: conciencia do número de obxectos (entender que un obxecto segue existindo aínda que estea fóra da vista e non se use); "bloquear e volver": a capacidade de lembrar a posición orixinal e volver a ela despois de completar algunha tarefa adicional; "bloqueo secuencial" - 4 caixas foron localizadas aleatoriamente en tres cuartos sen portas, pero con ramplas para entrar, os axentes precisaron atopalas e bloquealas todas; colocación de caixas en sitios predeterminados; creando un abrigo arredor dun obxecto en forma de cilindro.
Como resultado, en tres de cada cinco tarefas, os bots que se adestraron previamente no xogo aprenderon máis rápido e mostraron mellores resultados que a IA que foi adestrada para resolver problemas desde cero. Obtiveron un rendemento lixeiramente mellor ao completar a tarefa e volver á posición inicial, bloqueando secuencialmente caixas en cuartos pechados e colocando caixas en determinadas áreas, pero tiveron un rendemento lixeiramente máis débil ao recoñecer o número de obxectos e á creación de cobertura arredor doutro obxecto.
Os investigadores atribúen resultados mixtos a como a IA aprende e lembra certas habilidades. "Pensamos que as tarefas nas que o adestramento previo no xogo se realizaba mellor implicaba reutilizar as habilidades aprendidas previamente dun xeito familiar, mentres que realizar as tarefas restantes mellor que a IA adestrada desde cero requiriría utilizalas dun xeito diferente, o que moito máis difícil”, escriben os coautores da obra. "Este resultado pon de relevo a necesidade de desenvolver métodos para reutilizar eficazmente as habilidades adquiridas a través da formación ao transferilas dun ambiente a outro".
O traballo realizado é verdadeiramente impresionante, xa que a perspectiva de empregar este método de ensino está moito máis alá dos límites de calquera xogo. Os investigadores din que o seu traballo é un paso importante para crear IA cun comportamento "baseado na física" e "similar ao humano" que pode diagnosticar enfermidades, predecir as estruturas de moléculas de proteína complexa e analizar as exploracións por TC.
No seguinte vídeo podes ver claramente como se desenvolveu todo o proceso de aprendizaxe, como a IA aprendeu a traballar en equipo e as súas estratexias foron cada vez máis astutas e complexas.

Fonte: 3dnews.ru
