


Yadda ake karanta wannan labarin: Ina baku hakuri saboda rubutun ya yi tsayi da hargitsi. Don ɓata lokaci, zan fara kowane babi da gabatarwar “Abin da Na Koya”, wanda ke taƙaita ainihin babin cikin jimla ɗaya ko biyu.
"Ki nuna min mafita!" Idan kawai kuna son ganin inda na fito, to, ku tsallake zuwa babin "Ƙarin Ƙirƙiri," amma ina tsammanin ya fi ban sha'awa da amfani don karanta game da gazawar.
Kwanan nan an ba ni ɗawainiya tare da kafa tsari don sarrafa babban adadin danyen jerin DNA (a fasaha na guntu SNP). Bukatar shine a hanzarta samun bayanai game da wurin da aka bayar (wanda ake kira SNP) don ƙirar ƙira da sauran ayyuka na gaba. Yin amfani da R da AWK, na sami damar tsaftacewa da tsara bayanai ta wata hanya ta dabi'a, tana ƙara saurin sarrafa tambaya. Wannan bai kasance mai sauƙi a gare ni ba kuma yana buƙatar maimaitawa da yawa. Wannan labarin zai taimake ka ka guje wa wasu kurakurai na kuma ya nuna maka abin da na ƙare.
Na farko, wasu bayanan gabatarwa.
data
Cibiyar sarrafa bayanan kwayoyin halitta ta jami'armu ta ba mu bayanai a cikin nau'i na 25 TB TSV. Na karbe su zuwa fakiti 5, Gzip ya matse su, kowannensu yana dauke da fayiloli kusan 240 mai girman gigabyte hudu. Kowane jere ya ƙunshi bayanai don SNP ɗaya daga mutum ɗaya. Gabaɗaya, an watsa bayanai akan ~ 2,5 miliyan SNPs da ~ 60 dubu mutane. Baya ga bayanan SNP, fayilolin sun ƙunshi ginshiƙai masu yawa tare da lambobi masu nuna halaye daban-daban, kamar ƙarfin karantawa, yawan nau'ikan alloli daban-daban, da sauransu. Gabaɗaya akwai kusan ginshiƙai 30 masu ƙima na musamman.
Manufar
Kamar kowane aikin sarrafa bayanai, abu mafi mahimmanci shine sanin yadda za a yi amfani da bayanan. A wannan yanayin mafi yawa za mu zaɓi samfura da ayyukan aiki don SNP bisa SNP. Wato, za mu buƙaci bayanai akan SNP ɗaya kawai a lokaci ɗaya. Dole ne in koyi yadda zan dawo da duk bayanan da ke da alaƙa da ɗaya daga cikin SNPs miliyan 2,5 cikin sauƙi, da sauri da arha mai yiwuwa.
Yadda ba a yi wannan ba
Don faɗi kalma mai dacewa:
Ban kasa kasa sau dubu ba, na gano hanyoyi dubu ne kawai don guje wa karkatar da tarin bayanai a cikin tsarin tambaya.
Gwada farko
Me na koya: Babu wata hanya mai arha don tantance TB 25 a lokaci guda.
Bayan da na ɗauki kwas ɗin "Hanyoyin Ci gaba don Babban Tsarin Bayanai" a Jami'ar Vanderbilt, na tabbata cewa dabarar tana cikin jaka. Wataƙila zai ɗauki sa'a ɗaya ko biyu don saita uwar garken Hive don gudanar da duk bayanan da bayar da rahoton sakamakon. Tun da an adana bayanan mu a AWS S3, na yi amfani da sabis ɗin , wanda ke ba ku damar amfani da tambayoyin Hive SQL zuwa bayanan S3. Ba kwa buƙatar saita/ɗaɗa tarin Hive, kuma kuna biya kawai don bayanan da kuke nema.
Bayan na nuna wa Athena bayanana da tsarin sa, na yi wasu gwaje-gwaje tare da tambayoyi kamar haka:
select * from intensityData limit 10;Kuma da sauri ya sami ingantaccen sakamako mai tsari. Shirya
Har sai mun yi ƙoƙarin yin amfani da bayanan a cikin aikinmu ...
An nemi in fitar da duk bayanan SNP don gwada samfurin akan. Na gudanar da tambayar:
select * from intensityData
where snp = 'rs123456';... kuma ya fara jira. Bayan mintuna takwas da fiye da TB na bayanan da aka nema, na sami sakamakon. Ana tuhumar Athena ta yawan adadin bayanan da aka samu, $4 kowace terabyte. Don haka wannan buƙatar guda ɗaya ta biya $5 da minti takwas na jira. Don gudanar da samfurin akan duk bayanan, dole ne mu jira shekaru 20 kuma mu biya dala miliyan 38. Babu shakka, wannan bai dace da mu ba.
Ya zama dole don amfani da Parquet ...
Me na koya: Yi hankali da girman fayilolin Parquet da ƙungiyar su.
Na farko kokarin gyara halin da ake ciki ta maida duk TSVs zuwa . Sun dace don aiki tare da manyan bayanan bayanai saboda an adana bayanan da ke cikinsu a cikin sigar columnar: kowane ginshiƙi yana kwance a cikin ɓangaren ƙwaƙwalwar ajiya / diski, sabanin fayilolin rubutu, wanda layuka ke ɗauke da abubuwa na kowane shafi. Kuma idan kuna buƙatar nemo wani abu, to kawai karanta ginshiƙin da ake buƙata. Bugu da ƙari, kowane fayil yana adana nau'ikan ƙima a cikin ginshiƙi, don haka idan ƙimar da kuke nema ba ta cikin kewayon ginshiƙi, Spark ba zai ɓata lokaci don bincika dukkan fayil ɗin ba.
Na gudanar da aiki mai sauƙi don canza TSVs ɗinmu zuwa Parquet kuma mun jefa sabbin fayiloli zuwa Athena. Ya ɗauki kimanin awa 5. Amma lokacin da na gudanar da buƙatun, ya ɗauki kusan adadin lokaci ɗaya da ƙarancin kuɗi kaɗan don kammalawa. Gaskiyar ita ce, Spark, ƙoƙarin inganta aikin, kawai ya buɗe TSV chunk guda ɗaya kuma ya sanya shi a cikin ɓangaren Parquet na kansa. Kuma saboda kowane yanki ya isa ya ƙunshi dukan bayanan mutane da yawa, kowane fayil ya ƙunshi duk SNPs, don haka Spark ya buɗe duk fayilolin don cire bayanan da yake buƙata.
Abin sha'awa shine, tsohowar Parquet (kuma shawarar) nau'in matsawa, ƙwaƙƙwal, ba a raba shi ba. Saboda haka, kowane mai zartarwa ya makale a kan aikin kwancewa da zazzage cikakken bayanan 3,5 GB.
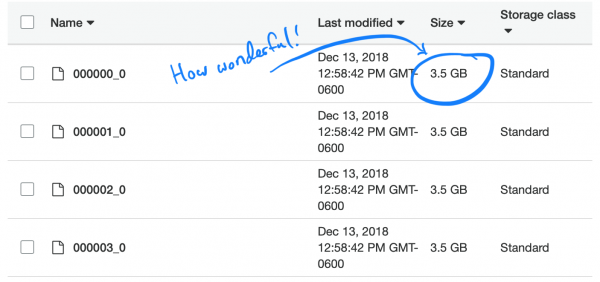
Mu gane matsalar
Me na koya: Rarraba yana da wahala, musamman idan an rarraba bayanan.
Da alama yanzu na fahimci ainihin matsalar. Ina bukata ne kawai don warware bayanan ta hanyar SNP, ba ta mutane ba. Sa'an nan kuma za a adana SNPs da yawa a cikin ɓangarorin bayanan daban, sannan aikin "mai wayo" na Parquet "buɗe kawai idan darajar tana cikin kewayon" zai nuna kanta a cikin ɗaukakarsa. Abin takaici, rarrabuwa ta biliyoyin layuka da aka warwatse a cikin gungu ya zama aiki mai wahala.
Ina shan ajin algorithms a kwaleji: "Ugh, babu wanda ya damu da hadaddun lissafin duk waɗannan algorithms"
Ina ƙoƙarin warwarewa akan ginshiƙi a cikin 20TB tebur: "Me yasa wannan yake ɗaukar lokaci mai tsawo haka?" gwagwarmaya.
- Nick Strayer (@NicholasStrayer)
Tabbas AWS ba ya son mayar da kuɗi saboda dalilin "Ni ɗalibi ne mai raba hankali". Bayan da na yi gudu a kan Amazon Glue, ya yi aiki na kwanaki 2 kuma ya fadi.
Game da rabuwa fa?
Me na koya: Rarraba a cikin Spark dole ne a daidaita su.
Sai na zo da ra'ayin rarraba bayanai a cikin chromosomes. Akwai 23 daga cikinsu (kuma da yawa idan kun yi la'akari da DNA na mitochondrial da yankuna marasa taswira).
Wannan zai ba ka damar raba bayanan zuwa ƙananan guntu. Idan ka ƙara layi ɗaya kawai zuwa aikin fitarwa na Spark a cikin rubutun manne partition_by = "chr", to sai a raba bayanan zuwa guga.
Kwayoyin halitta sun ƙunshi guntu masu yawa da ake kira chromosomes.
Abin takaici, bai yi aiki ba. Chromosomes suna da girma dabam dabam, wanda ke nufin adadin bayanai daban-daban. Wannan yana nufin cewa ayyukan da Spark ya aika wa ma'aikata ba su daidaita kuma an kammala su a hankali saboda wasu nodes sun ƙare da wuri kuma ba su da aiki. Duk da haka, an kammala ayyukan. Amma lokacin neman SNP ɗaya, rashin daidaituwa ya sake haifar da matsaloli. Farashin sarrafa SNPs akan manyan chromosomes (wato, inda muke son samun bayanai) ya ragu da kusan kashi 10 kawai. Da yawa, amma bai isa ba.
Idan muka raba shi zuwa ƙananan sassa fa?
Me na koya:Kada kayi ƙoƙarin yin partitions miliyan 2,5 kwata-kwata.
Na yanke shawarar fita duka kuma na raba kowace SNP. Wannan ya tabbatar da cewa sassan sun kasance daidai da girman. MUMMUNAN AQIDA CE. Na yi amfani da Manna kuma na ƙara layin marar laifi partition_by = 'snp'. Aikin ya fara kuma ya fara aiwatarwa. Bayan kwana guda na duba na ga har yanzu babu wani abu da aka rubuta wa S3, sai na kashe aikin. Yana kama da Manna yana rubuta matsakaitan fayiloli zuwa wani ɓoye a cikin S3, fayiloli da yawa, watakila miliyan biyu. A sakamakon haka, kuskurena ya ci fiye da dala dubu kuma bai gamsar da mai ba ni ba.
Rarraba + rarrabawa
Me na koyaHar yanzu rarrabuwa yana da wahala, kamar yadda ake kunna Spark.
Ƙoƙari na na ƙarshe na rabuwa ya haɗa da ni rarraba chromosomes sannan in rarraba kowane bangare. A ka'idar, wannan zai hanzarta kowace tambaya saboda bayanan SNP da ake so dole ne su kasance cikin ƴan ɓangarorin Parquet a cikin kewayon da aka bayar. Abin baƙin ciki, rarrabuwar ma bayanan da aka raba ya zama aiki mai wahala. A sakamakon haka, na canza zuwa EMR don gungu na al'ada kuma na yi amfani da lokutta takwas masu ƙarfi (C5.4xl) da Sparklyr don ƙirƙirar ingantaccen aiki mai sauƙi ...
# Sparklyr snippet to partition by chr and sort w/in partition
# Join the raw data with the snp bins
raw_data
group_by(chr) %>%
arrange(Position) %>%
Spark_write_Parquet(
path = DUMP_LOC,
mode = 'overwrite',
partition_by = c('chr')
)...duk da haka, har yanzu ba a kammala aikin ba. Na tsara shi ta hanyoyi daban-daban: ƙara yawan adadin ƙwaƙwalwar ajiya ga kowane mai aiwatar da tambaya, amfani da nodes tare da adadi mai yawa na ƙwaƙwalwar ajiya, amfani da ma'anar watsa shirye-shirye (masu rarraba watsa shirye-shirye), amma duk lokacin da waɗannan suka zama rabin ma'auni, kuma a hankali masu zartarwa sun fara. kasa har komai ya tsaya.
Sabuntawa: don haka ya fara.
- Nick Strayer (@NicholasStrayer)
Ina ƙara haɓakawa
Me na koya: Wani lokaci bayanai na musamman na buƙatar mafita na musamman.
Kowane SNP yana da ƙimar matsayi. Wannan lamba ce da ta yi daidai da adadin tushe tare da chromosome. Wannan hanya ce mai kyau kuma ta halitta don tsara bayanan mu. Da farko ina so in raba ta yankuna na kowane chromosome. Misali, matsayi na 1 - 2000, 2001 - 4000, da sauransu. Amma matsalar ita ce SNPs ba a rarraba daidai gwargwado a cikin chromosomes, don haka girman rukuni zai bambanta sosai.
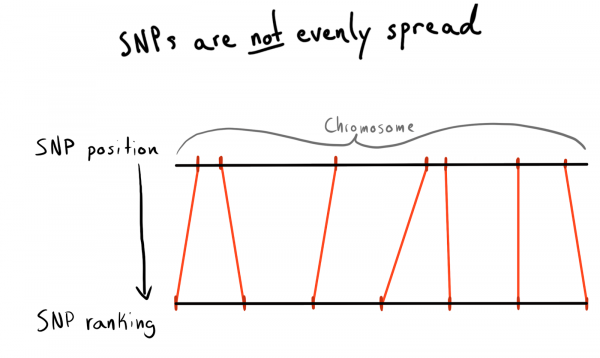
A sakamakon haka, na zo ga rushewar mukamai zuwa rukuni (daraja). Yin amfani da bayanan da aka riga aka sauke, na gudanar da buƙatun samun jerin SNPs na musamman, matsayinsu da chromosomes. Daga nan sai na jera bayanan cikin kowane chromosome kuma na tattara SNPs zuwa kungiyoyi (bin) na girman da aka bayar. Bari mu ce 1000 SNPs kowanne. Wannan ya ba ni dangantakar SNP-zuwa-ƙungiyar-kowace-chromosome.
A ƙarshe, na yi ƙungiyoyi (bin) na 75 SNPs, dalilin za a bayyana a kasa.
snp_to_bin <- unique_snps %>%
group_by(chr) %>%
arrange(position) %>%
mutate(
rank = 1:n()
bin = floor(rank/snps_per_bin)
) %>%
ungroup()Na farko gwada da Spark
Me na koya: Haɗawar tartsatsi yana da sauri, amma rabon har yanzu yana da tsada.
Ina so in karanta wannan ƙaramin bayanan (layukan miliyan 2,5) a cikin Spark, haɗa shi da ɗanyen bayanan, sannan in raba shi ta sabon shafi da aka ƙara. bin.
# Join the raw data with the snp bins
data_w_bin <- raw_data %>%
left_join(sdf_broadcast(snp_to_bin), by ='snp_name') %>%
group_by(chr_bin) %>%
arrange(Position) %>%
Spark_write_Parquet(
path = DUMP_LOC,
mode = 'overwrite',
partition_by = c('chr_bin')
)
na yi amfani sdf_broadcast(), don haka Spark ya san cewa yakamata ya aika da firam ɗin bayanai zuwa duk nodes. Wannan yana da amfani idan bayanan ƙarami ne kuma ana buƙata don duk ayyuka. In ba haka ba, Spark yana ƙoƙari ya zama mai wayo kuma yana rarraba bayanai kamar yadda ake buƙata, wanda zai iya haifar da raguwa.
Kuma a sake, ra'ayina bai yi aiki ba: ayyukan sun yi aiki na ɗan lokaci, sun kammala ƙungiyar, sa'an nan kuma, kamar masu zartarwa da aka kaddamar ta hanyar rarraba, sun fara raguwa.
Ƙara AWK
Me na koya: Kada ka yi barci lokacin da ake koya maka abubuwa masu mahimmanci. Tabbas wani ya riga ya warware matsalar ku a shekarun 1980.
Har zuwa wannan lokacin, dalilin duk gazawar da na yi tare da Spark shine tarin bayanai a cikin tari. Wataƙila za a iya inganta yanayin tare da riga-kafi. Na yanke shawarar raba danyen bayanan rubutu zuwa ginshiƙan chromosomes, don haka ina fatan samar da Spark da bayanan “wanda aka riga aka raba”.
Na bincika akan StackOverflow don yadda ake raba ta ƙimar shafi kuma na samo Tare da AWK zaku iya raba fayil ɗin rubutu ta ƙimar shafi ta rubuta shi a cikin rubutun maimakon aika sakamakon zuwa stdout.
Na rubuta rubutun Bash don gwada shi. Zazzage ɗaya daga cikin fakitin TSVs, sannan a buɗe shi ta amfani da shi gzip kuma aika zuwa awk.
gzip -dc path/to/chunk/file.gz |
awk -F 't'
'{print $1",..."$30">"chunked/"$chr"_chr"$15".csv"}'Ya yi aiki!
Cika ma'auni
Me na koya: gnu parallel - abu ne na sihiri, kowa ya kamata ya yi amfani da shi.
Rabuwa yayi a hankali kuma lokacin da na fara htopdon duba amfani da misali mai ƙarfi (kuma mai tsada) EC2, ya zamana cewa ina amfani da cibiya ɗaya kawai da kusan 200 MB na ƙwaƙwalwar ajiya. Don magance matsalar kuma kada muyi asarar kuɗi mai yawa, dole ne mu gano yadda za mu daidaita aikin. Abin farin ciki, a cikin cikakken littafi mai ban mamaki Na sami babi na Jeron Janssens akan daidaitawa. Daga shi na koyi game da gnu parallel, hanya mai sauƙi don aiwatar da multithreading a cikin Unix.

Lokacin da na fara rarrabawa ta amfani da sabon tsari, komai yana da kyau, amma har yanzu akwai ƙwanƙwasa - zazzage abubuwan S3 zuwa faifai ba su da sauri sosai kuma ba a daidaita su ba. Don gyara wannan, na yi wannan:
- Na gano cewa yana yiwuwa a aiwatar da matakin saukewar S3 kai tsaye a cikin bututun, gaba ɗaya kawar da matsakaicin matsakaici akan faifai. Wannan yana nufin zan iya guje wa rubuta ɗanyen bayanai zuwa faifai kuma in yi amfani da ƙarami, sabili da haka mai rahusa, ajiya akan AWS.
- tawagar
aws configure set default.s3.max_concurrent_requests 50ya ƙara yawan adadin zaren da AWS CLI ke amfani da shi (ta tsohuwa akwai 10). - Na canza zuwa misalin EC2 da aka inganta don saurin hanyar sadarwa, tare da harafin n a cikin sunan. Na gano cewa asarar ikon sarrafawa lokacin amfani da n-misali ya fi ramawa ta hanyar haɓaka saurin lodawa. Don yawancin ayyuka na yi amfani da c5n.4xl.
- Canza
gzipa kan , Wannan kayan aikin gzip ne wanda zai iya yin abubuwa masu sanyi don daidaita aikin farko wanda ba a daidaita shi ba na lalata fayiloli (wannan ya taimaka mafi ƙanƙanta).
# Let S3 use as many threads as it wants
aws configure set default.s3.max_concurrent_requests 50
for chunk_file in $(aws s3 ls $DATA_LOC | awk '{print $4}' | grep 'chr'$DESIRED_CHR'.csv') ; do
aws s3 cp s3://$batch_loc$chunk_file - |
pigz -dc |
parallel --block 100M --pipe
"awk -F 't' '{print $1",..."$30">"chunked/{#}_chr"$15".csv"}'"
# Combine all the parallel process chunks to single files
ls chunked/ |
cut -d '_' -f 2 |
sort -u |
parallel 'cat chunked/*_{} | sort -k5 -n -S 80% -t, | aws s3 cp - '$s3_dest'/batch_'$batch_num'_{}'
# Clean up intermediate data
rm chunked/*
doneAna haɗa waɗannan matakan tare da juna don yin komai yayi aiki da sauri. Ta hanyar haɓaka saurin saukewa da kawar da rubuce-rubucen faifai, yanzu zan iya sarrafa fakitin terabyte 5 a cikin 'yan sa'o'i kaɗan.
Babu wani abu mai daɗi kamar ganin duk abubuwan da kuke biyan kuɗi akan AWS ana amfani da su. Godiya ga gnu-parallel Zan iya kwance zip da raba 19gig csv daidai da sauri kamar yadda zan iya zazzage shi. Ba na iya ko samun tartsatsi don gudanar da wannan.
- Nick Strayer (@NicholasStrayer)
Wannan tweet yakamata ya ambaci 'TSV'. Kash
Amfani da sabbin bayanan da aka tantance
Me na koyaSpark yana son bayanan da ba a matsawa ba kuma baya son hada bangare.
Yanzu bayanan suna cikin S3 a cikin wanda ba a tattara ba (karanta: rabawa) da tsarin da aka ba da oda, kuma zan iya komawa Spark kuma. Abin mamaki ya jira ni: Na sake kasa cimma abin da nake so! Yana da matukar wahala a gaya wa Spark daidai yadda aka raba bayanan. Kuma ko da na yi wannan, sai ya zama cewa an sami rabo da yawa (dubu 95), da lokacin da na yi amfani da su coalesce ya rage adadinsu zuwa iyakoki masu ma'ana, wannan ya lalata rabona. Na tabbata za a iya gyara wannan, amma bayan kwanaki biyu na bincike na kasa samun mafita. Daga ƙarshe na gama duk ayyuka a cikin Spark, kodayake ya ɗauki ɗan lokaci kuma fayilolin Parquet na tsaga ba ƙanƙanta ba ne (~ 200 KB). Koyaya, bayanan sun kasance inda ake buƙata.
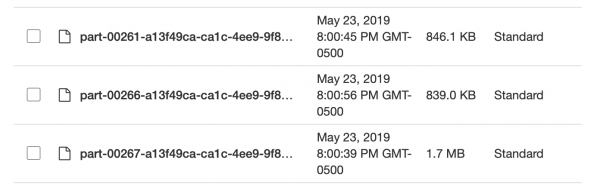
Karami da rashin daidaituwa, ban mamaki!
Gwajin tambayoyin Spark na gida
Me na koya: Spark yana da yawa fiye da kima yayin magance matsaloli masu sauƙi.
Ta hanyar zazzage bayanan a cikin tsari mai wayo, na sami damar gwada saurin. Saita rubutun R don gudanar da uwar garken Spark na gida, sannan loda firam ɗin bayanan Spark daga ƙayyadadden ma'ajiyar ƙungiyar Parquet (bin). Na yi ƙoƙarin loda duk bayanan amma na kasa samun Sparklyr don gane rabuwar.
sc <- Spark_connect(master = "local")
desired_snp <- 'rs34771739'
# Start a timer
start_time <- Sys.time()
# Load the desired bin into Spark
intensity_data <- sc %>%
Spark_read_Parquet(
name = 'intensity_data',
path = get_snp_location(desired_snp),
memory = FALSE )
# Subset bin to snp and then collect to local
test_subset <- intensity_data %>%
filter(SNP_Name == desired_snp) %>%
collect()
print(Sys.time() - start_time)Kisan ya dauki dakika 29,415. Mafi kyau, amma ba ma kyau ga taro gwajin wani abu. Bugu da ƙari, ba zan iya hanzarta abubuwa tare da caching ba saboda lokacin da na yi ƙoƙarin cache firam ɗin bayanai a cikin ƙwaƙwalwar ajiya, Spark koyaushe yana faɗuwa, ko da lokacin da na keɓe fiye da 50 GB na ƙwaƙwalwar ajiya ga ma'aunin bayanai wanda nauyinsa bai wuce 15 ba.
Koma zuwa AWK
Me na koya: Ƙungiyoyin haɗin gwiwa a cikin AWK suna da inganci sosai.
Na gane cewa zan iya cimma mafi girma gudu. Na tuna cewa a cikin ban mamaki Na karanta game da wani kyakkyawan yanayi mai suna "" Ainihin, waɗannan nau'ikan nau'ikan ƙima ne, waɗanda saboda wasu dalilai an kira su daban a cikin AWK, sabili da haka ko ta yaya ban yi tunani sosai game da su ba. tuna cewa kalmar "haɗin kai" ya girme fiye da kalmar "key-value pair". Ko da ku , ba za ku ga wannan kalmar a can ba, amma za ku sami tsararraki masu alaƙa! Bugu da kari, “biyu-darajar maɓalli” galibi ana haɗa su da bayanan bayanai, don haka yana da ma'ana sosai a kwatanta shi da taswirar hashmap. Na gane cewa zan iya amfani da waɗannan tsarin haɗin gwiwar don haɗa SNPs na tare da tebur na bin da danyen bayanai ba tare da amfani da Spark ba.
Don yin wannan, a cikin rubutun AWK na yi amfani da toshe BEGIN. Wannan wani yanki ne na lambar da aka aiwatar kafin a wuce layin farko na bayanai zuwa babban jikin rubutun.
join_data.awk
BEGIN {
FS=",";
batch_num=substr(chunk,7,1);
chunk_id=substr(chunk,15,2);
while(getline < "snp_to_bin.csv") {bin[$1] = $2}
}
{
print $0 > "chunked/chr_"chr"_bin_"bin[$1]"_"batch_num"_"chunk_id".csv"
}
tawagar while(getline...) an loda dukkan layuka daga rukunin CSV (bin), saita ginshiƙi na farko (sunan SNP) azaman maɓalli na tsararrun haɗin gwiwa. bin da ƙima na biyu (ƙungiyar) azaman darajar. Sannan a cikin block { }, wanda aka aiwatar akan duk layin babban fayil ɗin, kowane layi ana aika shi zuwa fayil ɗin fitarwa, wanda ke karɓar suna na musamman dangane da rukuninsa (bin): ..._bin_"bin[$1]"_....
Bambanci batch_num и chunk_id ya dace da bayanan da bututun ya bayar, da guje wa yanayin tsere, kuma kowane zaren kisa yana gudana parallel, ya rubuta zuwa fayil ɗin sa na musamman.
Tun da na warwatsa duk danyen bayanan cikin manyan fayiloli akan chromosomes da suka rage daga gwajin da na gabata tare da AWK, yanzu zan iya rubuta wani rubutun Bash don aiwatar da chromosome guda ɗaya a lokaci guda kuma in aika bayanai mai zurfi zuwa S3.
DESIRED_CHR='13'
# Download chromosome data from s3 and split into bins
aws s3 ls $DATA_LOC |
awk '{print $4}' |
grep 'chr'$DESIRED_CHR'.csv' |
parallel "echo 'reading {}'; aws s3 cp "$DATA_LOC"{} - | awk -v chr=""$DESIRED_CHR"" -v chunk="{}" -f split_on_chr_bin.awk"
# Combine all the parallel process chunks to single files and upload to rds using R
ls chunked/ |
cut -d '_' -f 4 |
sort -u |
parallel "echo 'zipping bin {}'; cat chunked/*_bin_{}_*.csv | ./upload_as_rds.R '$S3_DEST'/chr_'$DESIRED_CHR'_bin_{}.rds"
rm chunked/*
Rubutun yana da sassa biyu parallel.
A cikin sashe na farko, ana karanta bayanai daga duk fayilolin da ke ɗauke da bayanai akan chromosome da ake so, sannan ana rarraba wannan bayanan a cikin zaren, wanda ke rarraba fayilolin zuwa ƙungiyoyin da suka dace (bin). Don guje wa yanayin tsere lokacin da zaren da yawa suka rubuta zuwa fayil iri ɗaya, AWK yana ƙaddamar da sunayen fayil don rubuta bayanai zuwa wurare daban-daban, misali. chr_10_bin_52_batch_2_aa.csv. A sakamakon haka, an ƙirƙiri ƙananan fayiloli da yawa akan faifai (don wannan na yi amfani da kundin terabyte EBS).
Mai jigilar kaya daga kashi na biyu parallel suna shiga cikin ƙungiyoyin (bin) kuma suna haɗa fayilolinsu ɗaya zuwa CSV na gama gari catsannan a tura su zuwa kasashen waje.
Watsawa a cikin R?
Me na koya: Kuna iya tuntuɓar stdin и stdout daga rubutun R, sabili da haka amfani da shi a cikin bututun.
Wataƙila kun lura da wannan layin a cikin rubutun ku na Bash: ...cat chunked/*_bin_{}_*.csv | ./upload_as_rds.R.... Yana fassara duk fayilolin ƙungiyar da aka haɗa (bin) zuwa rubutun R da ke ƙasa. {} fasaha ce ta musamman parallel, wanda ke shigar da duk bayanan da ta aika zuwa ga keɓaɓɓen rafi kai tsaye cikin umarnin da kansa. Zabin {#} yana ba da ID ɗin zare na musamman, da {%} yana wakiltar lambar ramin aikin (maimaitawa, amma ba lokaci guda ba). Ana iya samun jerin duk zaɓuɓɓuka a ciki
#!/usr/bin/env Rscript
library(readr)
library(aws.s3)
# Read first command line argument
data_destination <- commandArgs(trailingOnly = TRUE)[1]
data_cols <- list(SNP_Name = 'c', ...)
s3saveRDS(
read_csv(
file("stdin"),
col_names = names(data_cols),
col_types = data_cols
),
object = data_destination
)
Lokacin da m file("stdin") watsa zuwa readr::read_csv, an ɗora bayanan da aka fassara zuwa rubutun R a cikin firam, wanda ke cikin tsari .rds- amfani da fayil aws.s3 rubuta kai tsaye zuwa S3.
RDS wani abu ne mai kama da ƙaramin sigar Parquet, ba tare da ƙarancin ajiyar lasifika ba.
Bayan na gama rubutun Bash sai na samu daure .rds-files da ke cikin S3, wanda ya ba ni damar yin amfani da ingantaccen matsawa da nau'ikan ginannun ciki.
Duk da amfani da birki R, komai yayi aiki da sauri. Ba abin mamaki bane, sassan R da ke karantawa da rubuta bayanai an inganta su sosai. Bayan gwaji akan chromosome matsakaici guda ɗaya, aikin ya ƙare akan misalin C5n.4xl cikin kusan awanni biyu.
Iyakokin S3
Me na koya: Godiya ga aiwatar da hanya mai wayo, S3 na iya ɗaukar fayiloli da yawa.
Na damu ko S3 zai iya sarrafa yawancin fayilolin da aka canza zuwa gare ta. Zan iya sa sunayen fayilolin su yi ma'ana, amma ta yaya S3 zai neme su?

Fayiloli a cikin S3 kawai don nunawa ne, a zahiri tsarin ba shi da sha'awar alamar /.
Ya bayyana cewa S3 yana wakiltar hanyar zuwa takamaiman fayil azaman maɓalli mai sauƙi a cikin nau'in tebur na zanta ko tushen bayanai. Ana iya ɗaukar guga a matsayin tebur, kuma ana iya ɗaukar fayiloli a cikin wannan tebur.
Tun da sauri da inganci suna da mahimmanci don samun riba a Amazon, ba abin mamaki ba ne cewa wannan maɓalli-a-fayil-hanyar tsarin yana freaking ingantacce. Na yi ƙoƙarin nemo ma'auni: don kada in sami buƙatun da yawa, amma an aiwatar da buƙatun da sauri. Ya zama mafi kyau a yi kusan fayilolin bin 20 dubu. Ina tsammanin idan muka ci gaba da ingantawa, za mu iya samun karuwa a cikin sauri (alal misali, yin guga na musamman kawai don bayanai, don haka rage girman girman tebur). Amma babu lokaci ko kuɗi don ƙarin gwaje-gwaje.
Me game da daidaituwar giciye?
Abin da Na Koyi: Babban dalilin ɓata lokaci shine inganta hanyar ajiyar ku da wuri.
A wannan gaba, yana da matukar muhimmanci a tambayi kanku: "Me yasa kuke amfani da tsarin fayil na mallakar mallaka?" Dalilin ya ta'allaka ne a cikin saurin lodawa (fayilolin CSV waɗanda gzipped sun ɗauki tsawon sau 7 don ɗauka) da dacewa tare da ayyukanmu. Zan iya sake tunani idan R zai iya loda fayilolin Parquet (ko Arrow) cikin sauƙi ba tare da nauyin Spark ba. Kowa a cikin dakin binciken mu yana amfani da R, kuma idan ina buƙatar canza bayanan zuwa wani tsari, har yanzu ina da ainihin bayanan rubutu, don haka zan iya sake kunna bututun.
Rarraba aikin
Me na koya: Kada ku yi ƙoƙarin inganta ayyuka da hannu, bari kwamfutar ta yi shi.
Na yi kuskuren aikin aiki akan chromosome ɗaya, yanzu ina buƙatar aiwatar da duk sauran bayanan.
Ina so in ɗaga lokuttan EC2 da yawa don juyawa, amma a lokaci guda na ji tsoron samun nauyi mara nauyi a cikin ayyukan sarrafawa daban-daban (kamar yadda Spark ya sha wahala daga ɓangarori marasa daidaituwa). Bugu da ƙari, ban sha'awar haɓaka misali ɗaya a kowace chromosome ba, saboda ga asusun AWS akwai ƙayyadaddun iyaka na lokuta 10.
Sai na yanke shawarar rubuta rubutun a cikin R don inganta ayyukan sarrafawa.
Na farko, na tambayi S3 don lissafta yawan sararin ajiya kowane chromosome ya mamaye.
library(aws.s3)
library(tidyverse)
chr_sizes <- get_bucket_df(
bucket = '...', prefix = '...', max = Inf
) %>%
mutate(Size = as.numeric(Size)) %>%
filter(Size != 0) %>%
mutate(
# Extract chromosome from the file name
chr = str_extract(Key, 'chr.{1,4}.csv') %>%
str_remove_all('chr|.csv')
) %>%
group_by(chr) %>%
summarise(total_size = sum(Size)/1e+9) # Divide to get value in GB
# A tibble: 27 x 2
chr total_size
<chr> <dbl>
1 0 163.
2 1 967.
3 10 541.
4 11 611.
5 12 542.
6 13 364.
7 14 375.
8 15 372.
9 16 434.
10 17 443.
# … with 17 more rows
Sannan na rubuta aikin da ke ɗaukar jimlar girman, yana karkatar da tsari na chromosomes, ya raba su zuwa rukuni. num_jobs kuma ya gaya muku yadda girman duk ayyukan sarrafawa suka bambanta.
num_jobs <- 7
# How big would each job be if perfectly split?
job_size <- sum(chr_sizes$total_size)/7
shuffle_job <- function(i){
chr_sizes %>%
sample_frac() %>%
mutate(
cum_size = cumsum(total_size),
job_num = ceiling(cum_size/job_size)
) %>%
group_by(job_num) %>%
summarise(
job_chrs = paste(chr, collapse = ','),
total_job_size = sum(total_size)
) %>%
mutate(sd = sd(total_job_size)) %>%
nest(-sd)
}
shuffle_job(1)
# A tibble: 1 x 2
sd data
<dbl> <list>
1 153. <tibble [7 × 3]>Sai na yi gudu ta hanyar shuffles dubu ta amfani da purrr kuma na zaɓi mafi kyau.
1:1000 %>%
map_df(shuffle_job) %>%
filter(sd == min(sd)) %>%
pull(data) %>%
pluck(1)
Don haka na ƙare da jerin ayyuka masu kama da girman gaske. Sa'an nan abin da ya rage shi ne in nannade rubutun Bash na baya a cikin babban madauki for. Wannan ingantawa ya ɗauki kusan mintuna 10 don rubutawa. Kuma wannan ya yi ƙasa da yadda zan kashe don ƙirƙirar ayyuka da hannu idan sun kasance marasa daidaituwa. Saboda haka, ina ganin cewa na yi daidai da wannan ingantawa na farko.
for DESIRED_CHR in "16" "9" "7" "21" "MT"
do
# Code for processing a single chromosome
fiA ƙarshe na ƙara umarnin kashewa:
sudo shutdown -h now
... kuma duk abin ya yi aiki! Yin amfani da AWS CLI, na ɗaga misalai ta amfani da zaɓi user_data ya ba su rubutun Bash na ayyukansu na sarrafawa. Sun gudu sun rufe ta atomatik, don haka ba na biya ƙarin ikon sarrafawa ba.
aws ec2 run-instances ...
--tag-specifications "ResourceType=instance,Tags=[{Key=Name,Value=<<job_name>>}]"
--user-data file://<<job_script_loc>>Mu shirya!
Me na koya: API ya kamata ya zama mai sauƙi don sauƙi da sauƙi na amfani.
A ƙarshe na sami bayanan a daidai wurin da tsari. Abin da ya rage shi ne don sauƙaƙe tsarin amfani da bayanai gwargwadon iko don sauƙaƙe ga abokan aiki na. Ina so in yi API mai sauƙi don ƙirƙirar buƙatun. Idan nan gaba na yanke shawarar canzawa daga .rds zuwa fayilolin Parquet, to wannan yakamata ya zama matsala a gare ni, ba ga abokan aiki na ba. Don wannan na yanke shawarar yin kunshin R na ciki.
Gina da rubuta fakiti mai sauƙi mai ƙunshe da ƴan ayyukan samun damar bayanai da aka tsara a kusa da wani aiki get_snp. Na kuma yi gidan yanar gizo ga abokan aikina , don haka a sauƙaƙe suna iya ganin misalai da takardu.
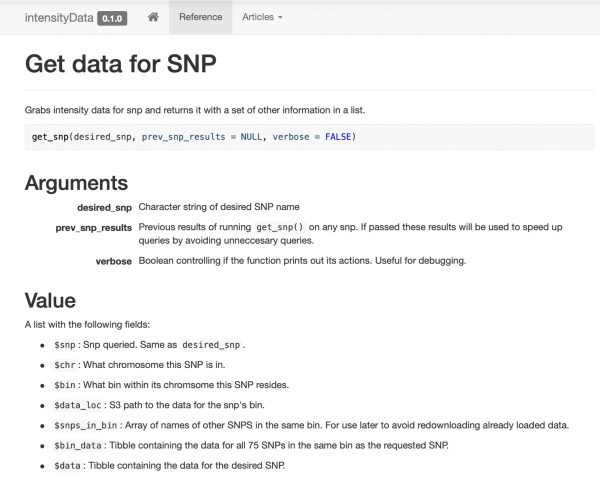
Smart caching
Me na koya: Idan an shirya bayanan ku da kyau, caching zai zama da sauƙi!
Tun da ɗayan manyan ayyukan aiki ya yi amfani da samfurin bincike iri ɗaya zuwa kunshin SNP, na yanke shawarar yin amfani da binning don fa'idata. Lokacin aika bayanai ta hanyar SNP, duk bayanan ƙungiyar (bin) suna haɗe zuwa abin da aka dawo. Wato tsofaffin tambayoyin na iya (a ka'idar) hanzarta aiwatar da sabbin tambayoyin.
# Part of get_snp()
...
# Test if our current snp data has the desired snp.
already_have_snp <- desired_snp %in% prev_snp_results$snps_in_bin
if(!already_have_snp){
# Grab info on the bin of the desired snp
snp_results <- get_snp_bin(desired_snp)
# Download the snp's bin data
snp_results$bin_data <- aws.s3::s3readRDS(object = snp_results$data_loc)
} else {
# The previous snp data contained the right bin so just use it
snp_results <- prev_snp_results
}
...
Lokacin gina fakitin, na gudanar da maƙaloli da yawa don kwatanta saurin lokacin amfani da hanyoyi daban-daban. Ina ba da shawarar kada ku yi sakaci da wannan, saboda wani lokacin sakamakon ba zato ba tsammani. Misali, dplyr::filter ya yi sauri fiye da ɗaukar layuka ta amfani da tacewa bisa tushen ƙididdiga, kuma maido da shafi ɗaya daga firam ɗin da aka tace ya fi sauri fiye da yin amfani da maƙasudin ƙididdiga.
Da fatan za a lura cewa abin prev_snp_results ya ƙunshi maɓalli snps_in_bin. Wannan jeri ne na duk musamman SNPs a cikin rukuni (bin), yana ba ku damar bincika da sauri idan kuna da bayanai daga tambayar da ta gabata. Hakanan yana sauƙaƙa yin madauki ta duk SNPs a cikin rukuni (bin) tare da wannan lambar:
# Get bin-mates
snps_in_bin <- my_snp_results$snps_in_bin
for(current_snp in snps_in_bin){
my_snp_results <- get_snp(current_snp, my_snp_results)
# Do something with results
}Результаты
Yanzu za mu iya (kuma mun fara da gaske) gudanar da samfura da al'amuran da ba za su iya isa gare mu a baya ba. Mafi kyawun abu shine abokan aikina na lab ba dole bane suyi tunanin kowace irin rikitarwa. Suna da aikin da ke aiki kawai.
Kuma ko da yake kunshin ya ba su cikakkun bayanai, na yi ƙoƙari na sauƙaƙe tsarin bayanan da za su iya gane shi idan na bace ba zato ba tsammani gobe ...
Gudun ya ƙaru sosai. Mu yawanci muna bincika guntuwar kwayoyin halitta masu aiki. A baya can, ba za mu iya yin wannan ba (ya juya ya zama tsada sosai), amma yanzu, godiya ga tsarin rukuni (bin) da caching, buƙatar SNP ɗaya yana ɗaukar matsakaicin ƙasa da 0,1 seconds, kuma amfani da bayanai yana da ƙasa sosai. cewa kudin S3 gyada ne.
Kwanan nan na sami canji na 25+ tarin fuka na raw genotyping data don lab na. Lokacin da na fara, amfani da walƙiya ya ɗauki 8 min & farashin $20 don neman SNP. Bayan amfani da AWK+ don aiwatarwa, yanzu yana ɗaukar ƙasa da 10th na daƙiƙa kuma farashin $ 0.00001. Na sirri lashe.
- Nick Strayer (@NicholasStrayer)
ƙarshe
Wannan labarin ba jagora bane kwata-kwata. Maganin ya juya ya zama mutum ɗaya, kuma kusan ba lallai ba ne mafi kyau. Maimakon haka, labarin tafiya ne. Ina so wasu su fahimci cewa irin waɗannan yanke shawara ba su bayyana cikakke a cikin kai ba, sakamakon gwaji ne da kuskure. Hakanan, idan kuna neman masanin kimiyyar bayanai, ku tuna cewa yin amfani da waɗannan kayan aikin yadda ya kamata yana buƙatar ƙwarewa, kuma ƙwarewar tana kashe kuɗi. Na yi farin ciki da cewa ina da abin da zan biya, amma wasu da yawa waɗanda za su iya yin aiki iri ɗaya fiye da ni ba za su sami damar ba saboda rashin kuɗi ko da gwadawa.
Manyan kayan aikin bayanai suna da yawa. Idan kuna da lokacin, kusan zaku iya rubuta bayani mai sauri ta amfani da tsabtace bayanai masu wayo, ajiya, da dabarun cirewa. A ƙarshe yana zuwa zuwa nazarin ƙimar fa'ida.
Abin da na koya:
- babu wata hanya mai arha don tantance tarin tarin fuka 25 a lokaci guda;
- Yi hankali da girman fayilolin Parquet da ƙungiyar su;
- Rarraba a cikin Spark dole ne a daidaita su;
- Gabaɗaya, kada ku yi ƙoƙarin yin ɓangarori miliyan 2,5;
- Rarraba har yanzu yana da wahala, kamar yadda ake kafa Spark;
- wani lokacin bayanai na musamman na buƙatar mafita na musamman;
- Haɗin walƙiya yana da sauri, amma rarraba har yanzu yana da tsada;
- kada ka yi barci lokacin da suke koya maka abubuwan da suka dace, tabbas wani ya riga ya warware matsalarka a shekarun 1980;
gnu parallel- wannan abu ne na sihiri, kowa ya kamata ya yi amfani da shi;- Spark yana son bayanan da ba a matsawa ba kuma baya son hada bangare;
- Spark yana da wuce gona da iri yayin magance matsaloli masu sauƙi;
- Tsarukan haɗin gwiwa na AWK suna da inganci sosai;
- za ku iya tuntuɓar
stdinиstdoutdaga rubutun R, sabili da haka amfani da shi a cikin bututun; - Godiya ga aiwatar da hanya mai wayo, S3 na iya aiwatar da fayiloli da yawa;
- Babban dalilin ɓata lokaci shine inganta hanyar ajiyar ku da wuri;
- kar a yi ƙoƙarin inganta ayyuka da hannu, bari kwamfutar ta yi ta;
- API ɗin ya kamata ya zama mai sauƙi don sauƙi da sauƙi na amfani;
- Idan an shirya bayanan ku da kyau, caching zai zama da sauƙi!
source: www.habr.com
