


Pozdrav, ja sam Sergey Elantsev, razvijam se u Yandex.Cloudu. Prethodno sam vodio razvoj balansera L7 za portal Yandex - kolege se šale da što god da radim, ispada da je balanser. Reći ću čitateljima Habra kako upravljati opterećenjem u cloud platformi, što vidimo kao idealan alat za postizanje tog cilja i kako idemo prema izgradnji tog alata.
Prvo, predstavimo neke pojmove:
- VIP (virtualni IP) - IP adresa balansera
- Poslužitelj, backend, instanca - virtualni stroj koji pokreće aplikaciju
- RIP (Real IP) - IP adresa poslužitelja
- Healthcheck - provjera spremnosti poslužitelja
- Zona dostupnosti, AZ - izolirana infrastruktura u podatkovnom centru
- Regija - unija različitih AZ
Balanseri opterećenja rješavaju tri glavna zadatka: oni obavljaju samo balansiranje, poboljšavaju toleranciju na pogreške usluge i pojednostavljuju njezino skaliranje. Tolerancija grešaka osigurana je automatskim upravljanjem prometom: balanser prati stanje aplikacije i iz balansiranja isključuje instance koje ne prođu provjeru živosti. Skaliranje je osigurano ravnomjernom raspodjelom opterećenja po instancama, kao i ažuriranjem popisa instanci u hodu. Ako balansiranje nije dovoljno ujednačeno, neke od instanci će primiti opterećenje koje premašuje ograničenje njihovog kapaciteta, a usluga će postati manje pouzdana.
Uravnoteživač opterećenja često se klasificira prema sloju protokola iz OSI modela na kojem radi. Cloud Balancer radi na TCP razini, što odgovara četvrtom sloju, L4.
Prijeđimo na pregled arhitekture Cloud balancera. Postupno ćemo povećavati razinu detalja. Komponente balansera dijelimo u tri klase. Klasa konfiguracijske ravnine odgovorna je za interakciju korisnika i pohranjuje ciljno stanje sustava. Kontrolna ravnina pohranjuje trenutno stanje sustava i upravlja sustavima iz klase podatkovne ravnine, koji su direktno odgovorni za isporuku prometa od klijenata do vaših instanci.
Podatkovna ravnina
Promet završava na skupim uređajima koji se nazivaju granični usmjerivači. Kako bi se povećala tolerancija na greške, nekoliko takvih uređaja radi istovremeno u jednom podatkovnom centru. Zatim, promet ide balanserima, koji objavljuju bilo koje IP adrese svim AZ-ovima putem BGP-a za klijente.
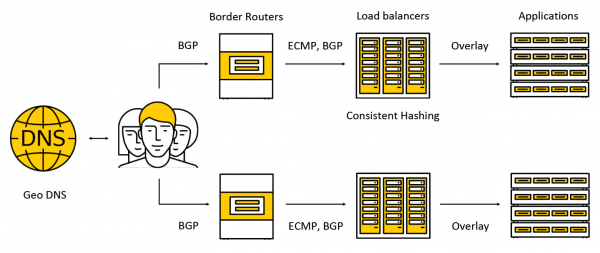
Promet se prenosi preko ECMP-a - to je strategija usmjeravanja prema kojoj može postojati nekoliko jednako dobrih ruta do cilja (u našem slučaju cilj će biti odredišna IP adresa) i paketi se mogu slati duž bilo kojeg od njih. Također podržavamo rad u nekoliko zona dostupnosti prema sljedećoj shemi: reklamiramo adresu u svakoj zoni, promet ide do najbliže i ne prelazi njene granice. Kasnije ćemo u postu pogledati detaljnije što se događa s prometom.
Konfiguracijska ravnina
Ključna komponenta konfiguracijske ravnine je API, preko kojeg se izvode osnovne operacije s balanserima: kreiranje, brisanje, promjena sastava instanci, dobivanje rezultata provjere stanja, itd. S jedne strane, ovo je REST API, a s drugo, mi u Cloud-u vrlo često koristimo framework gRPC, pa REST “prevodimo” u gRPC i onda koristimo samo gRPC. Svaki zahtjev dovodi do stvaranja niza asinkronih idempotentnih zadataka koji se izvršavaju na zajedničkom skupu Yandex.Cloud radnika. Zadaci su napisani tako da se u bilo kojem trenutku mogu obustaviti i ponovno pokrenuti. To osigurava skalabilnost, ponovljivost i bilježenje operacija.
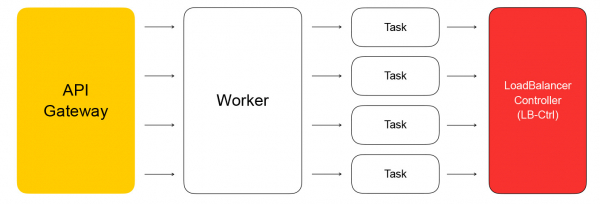
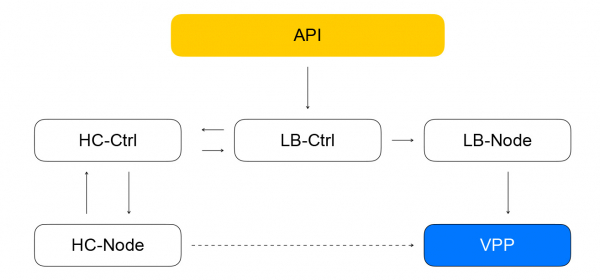
Kao rezultat toga, zadatak iz API-ja uputit će zahtjev kontroleru usluge balansiranja, koji je napisan u Go. Može dodavati i uklanjati balansere, mijenjati sastav pozadina i postavki.
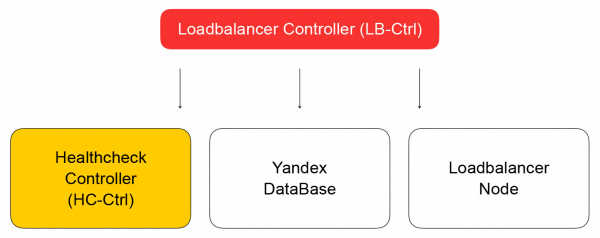
Usluga pohranjuje svoje stanje u Yandex bazi podataka, distribuiranoj upravljanoj bazi podataka koju ćete uskoro moći koristiti. U Yandex.Cloudu, kao i mi , vrijedi koncept hrane za pse: ako mi sami koristimo naše usluge, onda će ih i naši klijenti rado koristiti. Yandex Database primjer je implementacije takvog koncepta. Sve svoje podatke pohranjujemo u YDB i ne moramo razmišljati o održavanju i skaliranju baze podataka: ti su problemi za nas riješeni, bazu podataka koristimo kao uslugu.
Vratimo se na kontroler balansera. Njegova je zadaća spremiti podatke o balanseru i poslati zadatak za provjeru spremnosti virtualnog stroja kontroleru za provjeru stanja.
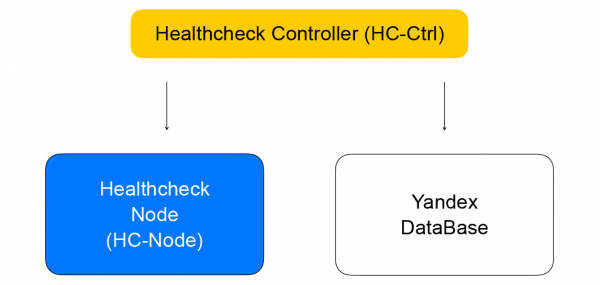
Kontrolor Healthcheck
Prima zahtjeve za promjenu pravila provjere, sprema ih u YDB, distribuira zadatke među healtcheck čvorovima i agregira rezultate, koji se zatim spremaju u bazu podataka i šalju kontroleru loadbalancera. On, pak, šalje zahtjev za promjenu sastava klastera u podatkovnoj ravnini čvoru loadbalancer-a, o čemu ću govoriti u nastavku.
Razgovarajmo više o zdravstvenim pregledima. Mogu se podijeliti u nekoliko klasa. Revizije imaju različite kriterije uspjeha. TCP provjere trebaju uspješno uspostaviti vezu unutar fiksnog vremena. HTTP provjere zahtijevaju i uspješnu vezu i odgovor sa statusnim kodom 200.
Također, čekovi se razlikuju po klasi djelovanja - aktivni su i pasivni. Pasivne provjere jednostavno prate što se događa s prometom bez poduzimanja ikakvih posebnih radnji. Ovo ne funkcionira dobro na L4 jer ovisi o logici protokola više razine: na L4 nema informacija o tome koliko je operacija trajala ili je li dovršetak veze bio dobar ili loš. Aktivne provjere zahtijevaju da balanser pošalje zahtjeve svakoj instanci poslužitelja.
Većina uređaja za balansiranje opterećenja sama provodi provjere izdržljivosti. U Cloudu smo odlučili odvojiti ove dijelove sustava kako bismo povećali skalabilnost. Ovaj pristup omogućit će nam povećanje broja balansera uz zadržavanje broja zahtjeva za provjeru ispravnosti usluge. Provjere izvode zasebni čvorovi provjere stanja, preko kojih se ciljevi provjere dijele i repliciraju. Ne možete izvršiti provjere s jednog glavnog računala jer bi moglo uspjeti. Tada nećemo dobiti stanje instanci koje je provjerio. Provjeravamo bilo koju od instanci iz najmanje tri čvora provjere stanja. Dijelimo svrhe provjera između čvorova pomoću dosljednih algoritama raspršivanja.
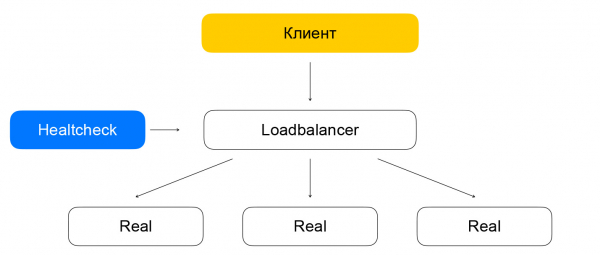
Razdvajanje balansiranja i provjere stanja može dovesti do problema. Ako čvor za provjeru stanja postavlja zahtjeve instanci, zaobilazeći balanser (koji trenutno ne opslužuje promet), dolazi do čudne situacije: čini se da je resurs živ, ali promet neće doći do njega. Ovaj problem rješavamo na ovaj način: zajamčeno je da ćemo pokrenuti promet provjere stanja kroz balansere. Drugim riječima, shema za premještanje paketa s prometom od klijenata i od zdravstvenih provjera minimalno se razlikuje: u oba slučaja paketi će doći do balansera koji će ih isporučiti ciljnim resursima.
Razlika je u tome što klijenti podnose zahtjeve VIP-u, dok zdravstveni pregledi podnose zahtjeve svakom pojedinačnom RIP-u. Ovdje se javlja zanimljiv problem: našim korisnicima dajemo mogućnost stvaranja resursa u sivim IP mrežama. Zamislimo da postoje dva različita vlasnika oblaka koji su sakrili svoje usluge iza balansera. Svaki od njih ima resurse u podmreži 10.0.0.1/24, s istim adresama. Morate ih nekako razlikovati, a ovdje morate zaroniti u strukturu virtualne mreže Yandex.Cloud. Bolje je saznati više detalja u , sada nam je važno da je mreža višeslojna i da ima tunele koji se mogu razlikovati po ID-u podmreže.
Čvorovi Healthcheck kontaktiraju balansere koristeći takozvane kvazi-IPv6 adrese. Kvaziadresa je IPv6 adresa s IPv4 adresom i korisničkim ID-om podmreže ugrađenim unutar nje. Promet dolazi do balansera, koji izvlači IPv4 adresu resursa iz njega, zamjenjuje IPv6 s IPv4 i šalje paket na korisničku mrežu.
Obrnuti promet ide na isti način: balanser vidi da je odredište siva mreža od provjera stanja i pretvara IPv4 u IPv6.
VPP - srce podatkovne ravnine
Balancer je implementiran pomoću tehnologije vektorske obrade paketa (VPP), okvira tvrtke Cisco za skupnu obradu mrežnog prometa. U našem slučaju okvir radi povrh knjižnice za upravljanje mrežnim uređajima korisničkog prostora - Data Plane Development Kit (DPDK). Ovo osigurava visoku izvedbu obrade paketa: puno manje prekida događa se u kernelu i nema kontekstnih prebacivanja između prostora kernela i korisničkog prostora.
VPP ide još dalje i istiskuje još više performansi iz sustava kombiniranjem paketa u serije. Poboljšanje performansi dolazi od agresivne upotrebe predmemorije na modernim procesorima. Koriste se i predmemorije podataka (paketi se obrađuju u "vektorima", podaci su blizu jedni drugima) i predmemorije instrukcija: u VPP-u obrada paketa slijedi graf čiji čvorovi sadrže funkcije koje obavljaju isti zadatak.
Na primjer, obrada IP paketa u VPP-u odvija se sljedećim redoslijedom: prvo se zaglavlja paketa analiziraju u čvoru za raščlanjivanje, a zatim se šalju čvoru, koji prosljeđuje pakete dalje prema tablicama usmjeravanja.
Malo hardcore. Autori VPP-a ne toleriraju kompromise u korištenju predmemorije procesora, pa tipični kod za obradu vektora paketa sadrži ručnu vektorizaciju: postoji procesna petlja u kojoj se obrađuje situacija poput “imamo četiri paketa u redu čekanja”, zatim isto za dvoje, zatim - za jednog. Instrukcije prethodnog dohvaćanja često se koriste za učitavanje podataka u predmemorije kako bi se ubrzao pristup njima u sljedećim iteracijama.
n_left_from = frame->n_vectors;
while (n_left_from > 0)
{
vlib_get_next_frame (vm, node, next_index, to_next, n_left_to_next);
// ...
while (n_left_from >= 4 && n_left_to_next >= 2)
{
// processing multiple packets at once
u32 next0 = SAMPLE_NEXT_INTERFACE_OUTPUT;
u32 next1 = SAMPLE_NEXT_INTERFACE_OUTPUT;
// ...
/* Prefetch next iteration. */
{
vlib_buffer_t *p2, *p3;
p2 = vlib_get_buffer (vm, from[2]);
p3 = vlib_get_buffer (vm, from[3]);
vlib_prefetch_buffer_header (p2, LOAD);
vlib_prefetch_buffer_header (p3, LOAD);
CLIB_PREFETCH (p2->data, CLIB_CACHE_LINE_BYTES, STORE);
CLIB_PREFETCH (p3->data, CLIB_CACHE_LINE_BYTES, STORE);
}
// actually process data
/* verify speculative enqueues, maybe switch current next frame */
vlib_validate_buffer_enqueue_x2 (vm, node, next_index,
to_next, n_left_to_next,
bi0, bi1, next0, next1);
}
while (n_left_from > 0 && n_left_to_next > 0)
{
// processing packets by one
}
// processed batch
vlib_put_next_frame (vm, node, next_index, n_left_to_next);
}Dakle, Healthchecks razgovaraju preko IPv6 s VPP-om, koji ih pretvara u IPv4. To čini čvor u grafu, koji nazivamo algoritamski NAT. Za obrnuti promet (i konverziju iz IPv6 u IPv4) postoji isti algoritamski NAT čvor.
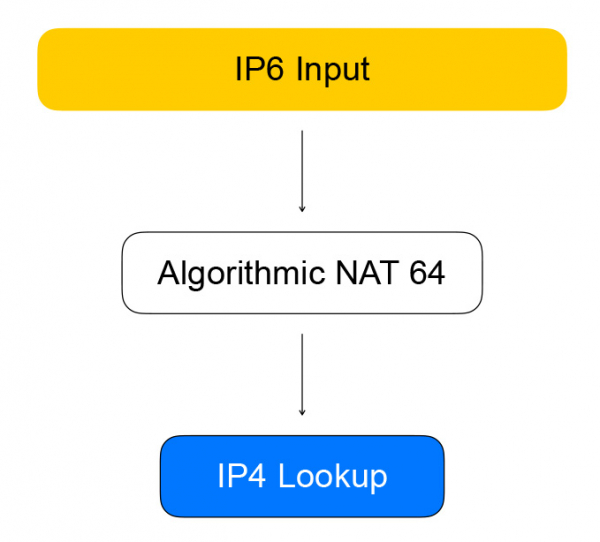
Izravni promet od klijenata balansera prolazi kroz čvorove grafa, koji obavljaju samo balansiranje.
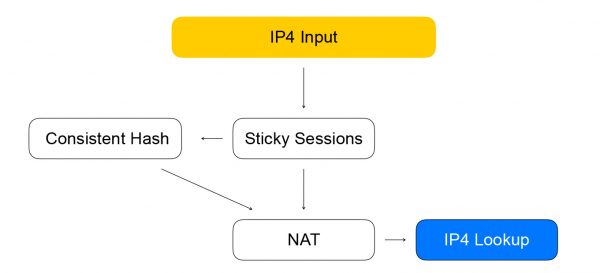
Prvi čvor su ljepljive sesije. Pohranjuje hash od za uspostavljene sesije. 5-torka uključuje adresu i port klijenta s kojeg se informacije prenose, adresu i portove resursa dostupnih za primanje prometa, kao i mrežni protokol.
Raspršivanje 5-torke pomaže nam da izvedemo manje izračuna u sljedećem dosljednom čvoru raspršivanja, kao i da bolje obrađujemo promjene popisa resursa iza balansera. Kada paket za koji ne postoji sesija stigne u balanser, šalje se konzistentnom čvoru raspršivanja. Ovdje dolazi do balansiranja korištenjem dosljednog hashiranja: odabiremo resurs s popisa dostupnih "živih" resursa. Zatim se paketi šalju u NAT čvor, koji zapravo zamjenjuje odredišnu adresu i ponovno izračunava kontrolne zbrojeve. Kao što vidite, slijedimo pravila VPP-a - like to like, grupiranje sličnih izračuna radi povećanja učinkovitosti predmemorije procesora.
Dosljedno raspršivanje
Zašto smo ga odabrali i što je to uopće? Prvo, razmotrimo prethodni zadatak - odabir resursa s popisa.
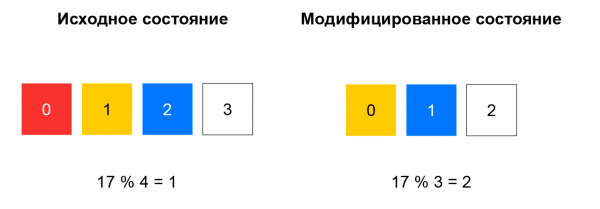
Kod nekonzistentnog raspršivanja izračunava se raspršivanje dolaznog paketa, a resurs se odabire s popisa ostatkom dijeljenja ovog raspršivanja s brojem resursa. Sve dok lista ostaje nepromijenjena, ova shema dobro funkcionira: uvijek šaljemo pakete s istom 5-torkom na istu instancu. Ako je, na primjer, neki resurs prestao odgovarati na zdravstvene provjere, tada će se za značajan dio hashova izbor promijeniti. Klijentove TCP veze bit će prekinute: paket koji je prethodno stigao do instance A može početi dosezati instancu B, koja nije upoznata sa sesijom za ovaj paket.
Dosljedno raspršivanje rješava opisani problem. Najlakši način za objašnjenje ovog koncepta je sljedeći: zamislite da imate prsten kojem raspodjeljujete resurse prema hash-u (na primjer, prema IP:portu). Odabir resursa je okretanje kotačića za kut koji je određen hashom paketa.
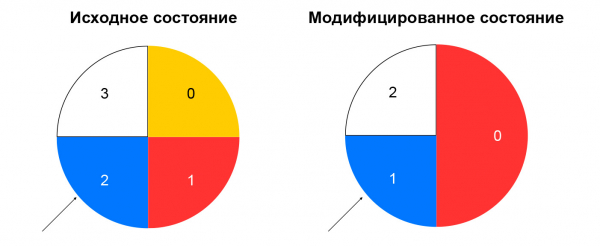
Ovo minimizira preraspodjelu prometa kada se sastav resursa promijeni. Brisanje resursa utjecat će samo na dio dosljednog prstena raspršivanja u kojem se resurs nalazio. Dodavanje resursa također mijenja distribuciju, ali imamo čvor ljepljivih sesija, koji nam omogućuje da ne prebacimo već uspostavljene sesije na nove resurse.
Pogledali smo što se događa s izravnim prometom između balansera i resursa. Sada pogledajmo povratni promet. Slijedi isti obrazac kao promet provjere - kroz algoritamski NAT, to jest, kroz obrnuti NAT 44 za promet klijenta i kroz NAT 46 za promet provjere stanja. Pridržavamo se vlastite sheme: objedinjujemo promet zdravstvenih provjera i promet stvarnih korisnika.
Loadbalancer-čvor i sklopljene komponente
Sastav balansera i resursa u VPP-u izvješćuje lokalna usluga - loadbalancer-node. Pretplaćuje se na tok događaja iz loadbalancer-controllera i može iscrtati razliku između trenutnog VPP stanja i ciljanog stanja primljenog od kontrolera. Dobivamo zatvoreni sustav: događaji iz API-ja dolaze do kontrolora balansera koji dodjeljuje zadatke kontroloru za provjeru zdravlja da provjeri “živost” resursa. To, zauzvrat, dodjeljuje zadatke čvoru za provjeru stanja i agregira rezultate, nakon čega ih šalje natrag u kontroler balansera. Loadbalancer-node pretplaćuje se na događaje iz kontrolera i mijenja stanje VPP-a. U takvom sustavu svaka služba zna samo ono što je potrebno o susjednim uslugama. Broj veza je ograničen i imamo mogućnost samostalnog rada i skaliranja različitih segmenata.
Koji su problemi izbjegnuti?
Sve naše usluge u kontrolnoj ravni napisane su u Go i imaju dobre karakteristike skaliranja i pouzdanosti. Go ima mnogo biblioteka otvorenog koda za izgradnju distribuiranih sustava. Aktivno koristimo GRPC, sve komponente sadrže open source implementaciju otkrivanja servisa - naši servisi međusobno prate izvedbu, mogu dinamički mijenjati svoj sastav, a to smo povezali s GRPC balansiranjem. Za metriku također koristimo rješenje otvorenog koda. U podatkovnoj ravnini dobili smo pristojne performanse i veliku rezervu resursa: pokazalo se da je vrlo teško sastaviti postolje na koje bismo se mogli osloniti na performanse VPP-a, a ne željezne mrežne kartice.
Problemi i rješenja
Što nije dobro funkcioniralo? Go ima automatsko upravljanje memorijom, ali i dalje dolazi do curenja memorije. Najlakši način za rješavanje njih je pokretanje goroutina i ne zaboravite ih prekinuti. Za ponijeti: promatrajte potrošnju memorije vaših Go programa. Često je dobar pokazatelj broj goroutina. Postoji plus u ovoj priči: u Gou je lako doći do podataka o vremenu izvođenja - potrošnja memorije, broj pokrenutih goroutina i mnogi drugi parametri.
Također, Go možda nije najbolji izbor za funkcionalne testove. Prilično su opširni i standardni pristup "pokretanja svega u CI-ju u paketu" nije baš prikladan za njih. Činjenica je da funkcionalni testovi zahtijevaju više resursa i uzrokuju stvarna vremenskog ograničenja. Zbog toga testovi mogu biti neuspješni jer je CPU zauzet jediničnim testovima. Zaključak: Ako je moguće, izvedite "teške" testove odvojeno od jediničnih testova.
Arhitektura događaja mikroservisa složenija je od monolita: prikupljanje zapisa na desecima različitih strojeva nije baš zgodno. Zaključak: ako pravite mikroservise, odmah razmislite o praćenju.
Naši planovi
Pokrenut ćemo interni balanser, IPv6 balanser, dodati podršku za Kubernetes skripte, nastaviti dijeliti naše usluge (trenutačno su samo čvor Healthcheck-node i Healthcheck-ctrl podijeljeni), dodati nove provjere stanja i također implementirati pametno prikupljanje provjera. Razmatramo mogućnost da svoje usluge učinimo još neovisnijima - tako da ne komuniciraju izravno jedna s drugom, već pomoću reda poruka. SQS-kompatibilna usluga nedavno se pojavila u oblaku .
Nedavno je javno objavljen Yandex Load Balancer. Istražiti servisu, upravljajte balanserima na vama prikladan način i povećajte otpornost na greške svojih projekata!
Izvor: www.habr.com
