

Ovo čak nije šala, čini se da baš ova slika najtočnije odražava bit ovih baza podataka, a na kraju će biti jasno i zašto:

Prema DB-Engines Rankingu, dvije najpopularnije NoSQL stupčaste baze podataka su Cassandra (u daljnjem tekstu CS) i HBase (HB).
Voljom sudbine, naš tim za upravljanje učitavanjem podataka u Sberbanku već jest i blisko surađuje s HB. Za to smo vrijeme prilično dobro proučili njegove prednosti i mane i naučili kako ga kuhati. Međutim, prisutnost alternative u obliku CS-a uvijek nas je tjerala da se malo mučimo sumnjama: jesmo li napravili pravi izbor? Štoviše, rezultati , u izvedbi DataStaxa, rekli su da CS lako pobjeđuje HB s gotovo poraznim rezultatom. S druge strane, DataStax je zainteresirana strana i ne biste im trebali vjerovati na riječ. Zbunila nas je i poprilično mala količina informacija o uvjetima testiranja, pa smo odlučili sami saznati tko je kralj BigData NoSql-a, a dobiveni rezultati su se pokazali vrlo zanimljivima.
Međutim, prije nego što prijeđemo na rezultate provedenih testova, potrebno je opisati značajne aspekte konfiguracija okoline. Činjenica je da se CS može koristiti u načinu rada koji dopušta gubitak podataka. Oni. ovo je kada je samo jedan poslužitelj (čvor) odgovoran za podatke određenog ključa, a ako iz nekog razloga zakaže, tada će vrijednost ovog ključa biti izgubljena. Za mnoge zadatke to nije kritično, ali za bankarski sektor ovo je iznimka, a ne pravilo. U našem slučaju, važno je imati nekoliko kopija podataka za pouzdanu pohranu.
Stoga je razmatran samo način rada CS-a u načinu trostruke replikacije, tj. Stvaranje prostora za slučajeve provedeno je sa sljedećim parametrima:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}; Zatim, postoje dva načina da se osigura potrebna razina dosljednosti. Opće pravilo:
SZ + NR > RF
Što znači da broj potvrda od čvorova prilikom pisanja (NW) plus broj potvrda od čvorova prilikom čitanja (NR) mora biti veći od faktora replikacije. U našem slučaju, RF = 3, što znači da su sljedeće opcije prikladne:
2 + 2 > 3
3 + 1 > 3
Budući da nam je temeljno važno što pouzdanije pohraniti podatke, odabrana je shema 3+1. Osim toga, HB radi na sličnom principu, tj. takva će usporedba biti pravednija.
Treba napomenuti da je DataStax u svojoj studiji učinio suprotno, postavili su RF = 1 i za CS i za HB (za potonji promjenom HDFS postavki). Ovo je stvarno važan aspekt jer je utjecaj na performanse CS-a u ovom slučaju ogroman. Na primjer, slika ispod prikazuje povećanje vremena potrebnog za učitavanje podataka u CS:
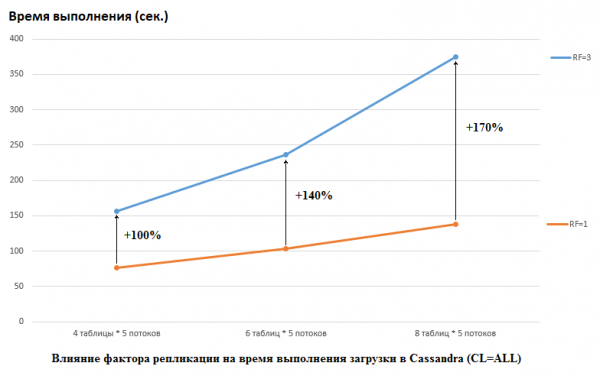
Ovdje vidimo sljedeće: što više konkurentskih niti upisuje podatke, to je dulje potrebno. To je prirodno, ali je važno da je degradacija performansi za RF=3 znatno veća. Drugim riječima, ako zapišemo 4 niti u 5 tablice svaku (ukupno 20), tada RF=3 gubi oko 2 puta (150 sekundi za RF=3 naspram 75 za RF=1). Ali ako povećamo opterećenje učitavanjem podataka u 8 tablica sa po 5 niti (ukupno 40), tada je gubitak RF=3 već 2,7 puta (375 sekundi naspram 138).
Možda je to djelomično tajna uspješnog testiranja opterećenja koje je DataStax proveo za CS, jer za HB na našem štandu promjena faktora replikacije s 2 na 3 nije imala nikakav učinak. Oni. diskovi nisu HB usko grlo za našu konfiguraciju. Međutim, tu ima mnogo drugih zamki, jer treba napomenuti da je naša verzija HB-a malo zakrpana i dotjerana, okruženja su potpuno drugačija itd. Također je vrijedno napomenuti da možda jednostavno ne znam kako pravilno pripremiti CS i postoje neki učinkovitiji načini za rad s njim, a nadam se da ćemo saznati u komentarima. Ali prvo o svemu.
Sva testiranja provedena su na hardverskom klasteru koji se sastoji od 4 poslužitelja, svaki sa sljedećom konfiguracijom:
CPU: Xeon E5-2680 v4 @ 2.40 GHz 64 niti.
Diskovi: 12 komada SATA HDD
verzija java: 1.8.0_111
CS verzija: 3.11.5
cassandra.yml parametribroj_tokena: 256
hinted_handoff_enabled: točno
hinted_handoff_throttle_in_kb: 1024
max_hints_delivery_threads: 2
hints_directory: /data10/cassandra/hints
hints_flush_period_in_ms: 10000
max_hints_file_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
autentifikator: AllowAllAuthenticator
autorizator: AllowAllAuthorizer
role_manager: CassandraRoleManager
role_validity_in_ms: 2000
permissions_validity_in_ms: 2000
vjerodajnice_valjanost_u_ms: 2000
particioner: org.apache.cassandra.dht.Murmur3Partitioner
direktoriji_datoteke_podataka:
- /data1/cassandra/data # svaki dataN direktorij je zaseban disk
- /data2/cassandra/data
- /data3/cassandra/data
- /data4/cassandra/data
- /data5/cassandra/data
- /data6/cassandra/data
- /data7/cassandra/data
- /data8/cassandra/data
commitlog_directory: /data9/cassandra/commitlog
cdc_enabled: netočno
disk_failure_policy: stop
commit_failure_policy: stop
pripremljene_izjave_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
veličina_keša_ključa_u_mb:
key_cache_save_period: 14400
row_cache_size_in_mb: 0
row_cache_save_period: 0
counter_cache_size_in_mb:
counter_cache_save_period: 7200
direktorij_saved_caches: /data10/cassandra/saved_caches
commitlog_sync: periodički
commitlog_sync_period_in_ms: 10000
commitlog_segment_size_in_mb: 32
dobavljač sjemena:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parametri:
— sjemenke: "*,*"
concurrent_reads: 256 # isprobano 64 - nema razlike
concurrent_writes: 256 # isprobano 64 - nema razlike
concurrent_counter_writes: 256 # pokušano 64 - nema razlike
concurrent_materialized_view_writes: 32
memtable_heap_space_in_mb: 2048 # probao 16 GB - bilo je sporije
memtable_allocation_type: heap_buffers
index_summary_capacity_in_mb:
index_summary_resize_interval_in_minutes: 60
trickle_fsync: lažno
trickle_fsync_interval_in_kb: 10240
port za pohranu: 7000
ssl_storage_port: 7001
slušaj_adresu: *
adresa_emitiranja: *
slušaj_na_emitiranoj_adresi: istina
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: točno
izvorna_transportna_luka: 9042
start_rpc: istina
rpc_adresa: *
rpc_port: 9160
rpc_keepalive: istina
rpc_vrsta_poslužitelja: sinkronizacija
štedljiv_u_okviru_transportna_veličina_u_mb: 15
inkrementalne_sigurnosne kopije: netočno
snimka_prije_zbijanja: netočno
auto_snapshot: točno
veličina_indeksa_stupca_u_kb: 64
stupac_index_cache_size_in_kb: 2
istodobni_kompaktori: 4
compaction_throughput_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
read_request_timeout_in_ms: 100000
interval_request_timeout_in_ms: 200000
istek_zahtjeva za pisanje_u_ms: 40000
counter_write_request_timeout_in_ms: 100000
cas_contention_timeout_in_ms: 20000
truncate_request_timeout_in_ms: 60000
zahtjev_timeout_in_ms: 200000
slow_query_log_timeout_in_ms: 500
cross_node_timeout: netočno
endpoint_snitch: GossipingPropertyFileSnitch
dynamic_snitch_update_interval_in_ms: 100
dinamički_snitch_reset_interval_in_ms: 600000
dinamički_snitch_badness_threshold: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
opcije_enkripcije_poslužitelja:
internode_encryption: nema
opcije_enkripcije_klijenta:
omogućeno: lažno
kompresija_internodija: dc
inter_dc_tcp_nodelay: netočno
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: netočno
enable_scripted_user_defined_functions: netočno
windows_timer_interval: 1
transparentne_opcije_enkripcije_podataka:
omogućeno: lažno
tombstone_warn_threshold: 1000
nadgrobni_spomenak_neuspjeh_prag: 100000
batch_size_warn_threshold_in_kb: 200
batch_size_fail_threshold_in_kb: 250
unlogged_batch_across_partitions_warn_threshold: 10
compaction_large_partition_warning_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
back_pressure_enabled: false
enable_materialized_views: istinito
enable_sasi_indexes: točno
GC postavke:
### CMS postavke-XX:+UseParNewGC
-XX:+Koristi ConcMarkSweepGC
-XX:+CMSParallelRemarkEnabled
-XX:Omjer preživjelih=8
-XX:MaxTenuringThreshold=1
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSWaitDuration=10000
-XX:+CMSParallelInitialMarkEnabled
-XX:+CMSEdenChunksRecordAlways
-XX:+CMSClassUnloadingEnabled
Memoriji jvm.options dodijeljeno je 16 Gb (probali smo i 32 Gb, nismo primijetili nikakvu razliku).
Tablice su kreirane naredbom:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};HB verzija: 1.2.0-cdh5.14.2 (u klasi org.apache.hadoop.hbase.regionserver.HRegion isključili smo MetricsRegion što je dovelo do GC-a kada je broj regija bio veći od 1000 na RegionServeru)
Parametri HBase koji nisu zadanizookeeper.session.timeout: 120000
hbase.rpc.timeout: 2 minute(e)
hbase.client.scanner.timeout.period: 2 minute(e)
hbase.master.handler.count: 10
hbase.regionserver.lease.period, hbase.client.scanner.timeout.period: 2 minute(e)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.period: 4 sat(a)
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 GiB
hbase.hregion.memstore.block.multiplier: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompaction: 1 dan(a)
Isječak napredne konfiguracije usluge HBase (sigurnosni ventil) za hbase-site.xml:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Opcije konfiguracije Java za HBase RegionServer:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:ReservedCodeCacheSize=256m
hbase.snapshot.master.timeoutMillis: 2 minute(e)
hbase.snapshot.region.timeout: 2 minute(e)
hbase.snapshot.master.timeout.millis: 2 minute(e)
Maksimalna veličina zapisa HBase REST poslužitelja: 100 MiB
HBase REST poslužitelj Maksimalne sigurnosne kopije datoteka dnevnika: 5
HBase Thrift Server Maksimalna veličina zapisa: 100 MiB
HBase Thrift Server Maksimalne sigurnosne kopije datoteka dnevnika: 5
Glavna maksimalna veličina zapisa: 100 MiB
Glavne maksimalne sigurnosne kopije datoteka dnevnika: 5
Maksimalna veličina dnevnika na poslužitelju regije: 100 MiB
RegionServer Maksimalne sigurnosne kopije datoteka dnevnika: 5
HBase Active Master Detection Window: 4 minute(e)
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: 10 milisekundi
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Maksimalni deskriptori procesne datoteke: 180000 XNUMX
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.size: 20
Niti za pomicanje regije: 6
Veličina Java Heap klijenta u bajtovima: 1 GiB
Zadana grupa HBase REST poslužitelja: 3 GiB
Zadana grupa HBase Thrift Servera: 3 GiB
Veličina Java Heap HBase Master-a u bajtovima: 16 GiB
Veličina Java hrpe HBase RegionServer u bajtovima: 32 GiB
+ZooKeeper
maxClientCnxns: 601
maxSessionTimeout: 120000
Izrada tablica:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
alter 'ns:t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}
Ovdje postoji jedna važna točka - DataStax opis ne kaže koliko je regija korišteno za izradu HB tablica, iako je to kritično za velike količine. Stoga je za testove odabrana količina = 64, koja omogućuje pohranjivanje do 640 GB, tj. stol srednje veličine.
U vrijeme testiranja, HBase je imao 22 tisuće tablica i 67 tisuća regija (ovo bi bilo smrtonosno za verziju 1.2.0 da nije bilo gore spomenute zakrpe).
Sada za šifru. Budući da nije bilo jasno koje su konfiguracije povoljnije za pojedinu bazu podataka, testovi su provedeni u različitim kombinacijama. Oni. u nekim testovima, 4 tablice su učitane istovremeno (sva 4 čvora su korištena za povezivanje). U ostalim testovima radili smo s 8 različitih tablica. U nekim je slučajevima veličina serije bila 100, u drugima 200 (parametar serije - vidi kod u nastavku). Veličina podataka za vrijednost je 10 bajtova ili 100 bajtova (veličina podataka). Ukupno je svaki put upisano i pročitano 5 milijuna zapisa u svaku tablicu. U isto vrijeme, 5 niti je pisano/čitano u svaku tablicu (broj niti - thNum), od kojih je svaka koristila svoj raspon ključeva (count = 1 milijun):
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("BEGIN BATCH ");
for (int i = 0; i < batch; i++) {
String value = RandomStringUtils.random(dataSize, true, true);
sb.append("INSERT INTO ")
.append(tableName)
.append("(id, title) ")
.append("VALUES (")
.append(key)
.append(", '")
.append(value)
.append("');");
key++;
}
sb.append("APPLY BATCH;");
final String query = sb.toString();
session.execute(query);
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN (");
for (int i = 0; i < batch; i++) {
sb = sb.append(key);
if (i+1 < batch)
sb.append(",");
key++;
}
sb = sb.append(");");
final String query = sb.toString();
ResultSet rs = session.execute(query);
}
}
Sukladno tome, slična je funkcionalnost osigurana za HB:
Configuration conf = getConf();
HTable table = new HTable(conf, keyspace + ":" + tableName);
table.setAutoFlush(false, false);
List<Get> lGet = new ArrayList<>();
List<Put> lPut = new ArrayList<>();
byte[] cf = Bytes.toBytes("cf");
byte[] qf = Bytes.toBytes("value");
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lPut.clear();
for (int i = 0; i < batch; i++) {
Put p = new Put(makeHbaseRowKey(key));
String value = RandomStringUtils.random(dataSize, true, true);
p.addColumn(cf, qf, value.getBytes());
lPut.add(p);
key++;
}
table.put(lPut);
table.flushCommits();
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lGet.clear();
for (int i = 0; i < batch; i++) {
Get g = new Get(makeHbaseRowKey(key));
lGet.add(g);
key++;
}
Result[] rs = table.get(lGet);
}
}
Kako u HB-u klijent mora voditi računa o ravnomjernoj distribuciji podataka, ključna funkcija soljenja je izgledala ovako:
public static byte[] makeHbaseRowKey(long key) {
byte[] nonSaltedRowKey = Bytes.toBytes(key);
CRC32 crc32 = new CRC32();
crc32.update(nonSaltedRowKey);
long crc32Value = crc32.getValue();
byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7);
return ArrayUtils.addAll(salt, nonSaltedRowKey);
}
Sada najzanimljiviji dio - rezultati:
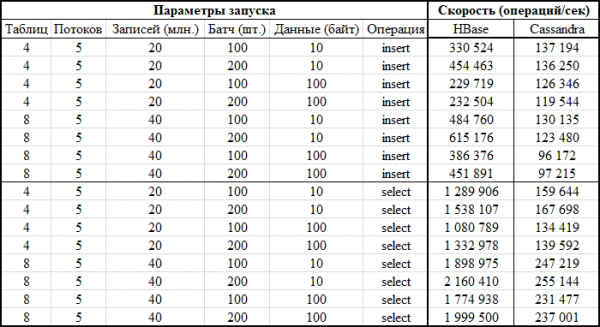
Ista stvar u obliku grafikona:
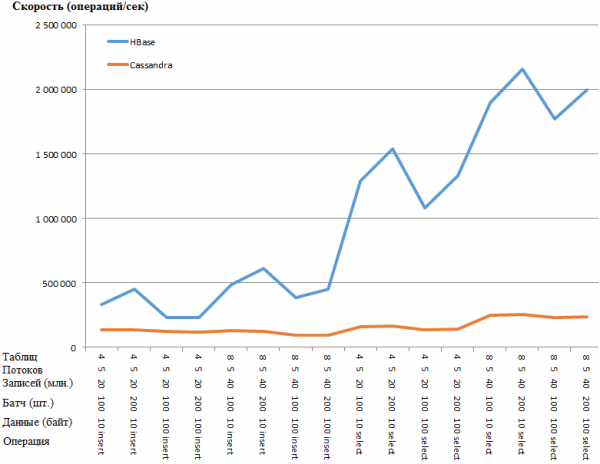
Prednost HB-a je toliko iznenađujuća da postoji sumnja da postoji neka vrsta uskog grla u postavkama CS-a. Međutim, guglanje i traženje najočitijih parametara (poput concurrent_writes ili memtable_heap_space_in_mb) nije ubrzalo stvari. U isto vrijeme, trupci su čisti i ne kunu se ni na što.
Podaci su ravnomjerno raspoređeni po čvorovima, statistika iz svih čvorova bila je približno ista.
Ovako izgleda statistika tablice iz jednog od čvorovaRazmak tipki: ks
Broj čitanja: 9383707
Latencija čitanja: 0.04287025042448576 ms
Broj zapisa: 15462012
Latencija pisanja: 0.1350068438699957 ms
Ispiranje na čekanju: 0
Tablica: t1
Broj SST tablice: 16
Iskorišten prostor (uživo): 148.59 MiB
Iskorišteni prostor (ukupno): 148.59 MiB
Prostor koji koriste snimke (ukupno): 0 bajtova
Iskorištena memorija izvan hrpe (ukupno): 5.17 MiB
SSTable omjer kompresije: 0.5720989576459437
Broj pregrada (procjena): 3970323
Broj memtabilnih ćelija: 0
Veličina memtabilnih podataka: 0 bajtova
Iskorištena memorijska memorija za memoriju izvan hrpe: 0 bajtova
Broj sklopnih sklopki: 5
Lokalni broj čitanja: 2346045
Lokalna latencija čitanja: NaN ms
Lokalni broj upisa: 3865503
Lokalna latencija pisanja: NaN ms
Ispiranje na čekanju: 0
Postotak popravljenih: 0.0
Bloom filtar lažno pozitivan: 25
Falsni omjer Bloom filtra: 0.00000
Iskorišten prostor Bloom filtera: 4.57 MiB
Iskorištena memorija gomile Bloom filtera: 4.57 MiB
Sažetak indeksa iskorištene memorije hrpe: 590.02 KiB
Metapodaci kompresije izvan iskorištene memorije gomile: 19.45 KiB
Minimalni bajt kompaktne particije: 36
Maksimalni bajt kompaktne particije: 42
Srednja vrijednost bajtova kompaktne particije: 42
Prosječan broj živih stanica po rezu (zadnjih pet minuta): NaN
Maksimalan broj živih stanica po rezu (zadnjih pet minuta): 0
Prosječan broj nadgrobnih spomenika po komadu (zadnjih pet minuta): NaN
Maksimalan broj nadgrobnih spomenika po rezu (zadnjih pet minuta): 0
Odbačene mutacije: 0 bajtova
Pokušaj smanjenja veličine paketa (čak i pojedinačnog slanja) nije imao učinka, samo se pogoršalo. Moguće je da je to zapravo maksimalna izvedba za CS, budući da su rezultati dobiveni za CS slični onima dobivenim za DataStax - oko stotine tisuća operacija u sekundi. Osim toga, ako pogledamo iskorištenost resursa, vidjet ćemo da CS koristi puno više CPU-a i diskova:
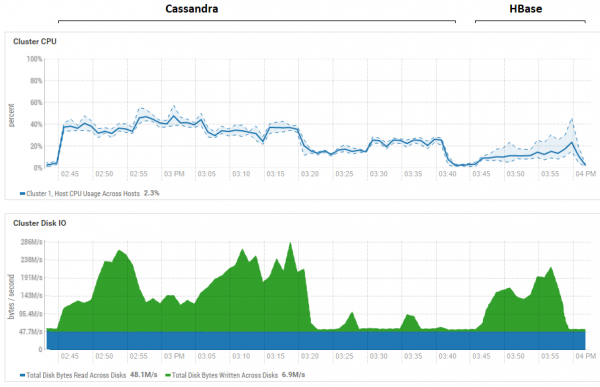
Na slici je prikazana iskorištenost tijekom izvođenja svih testova u nizu za obje baze podataka.
Što se tiče HB-ove snažne prednosti čitanja. Ovdje možete vidjeti da je za obje baze podataka iskorištenost diska tijekom čitanja izuzetno niska (testovi čitanja su završni dio ciklusa testiranja za svaku bazu podataka, npr. za CS to je od 15:20 do 15:40). U slučaju HB-a, razlog je jasan - većina podataka visi u memoriji, u memstoreu, a dio je predmemoriran u blockcacheu. Što se tiče CS-a, nije baš najjasnije kako radi, ali reciklaža diska također nije vidljiva, no za svaki slučaj pokušalo se omogućiti cache row_cache_size_in_mb = 2048 i postaviti caching = {'keys': 'ALL', 'rows_per_partition': ' 2000000'}, ali to ga je dodatno pogoršalo.
Također je vrijedno još jednom spomenuti važnu točku o broju regija u HB. U našem slučaju vrijednost je navedena kao 64. Ako je smanjite i učinite jednakom, na primjer, 4, tada se prilikom čitanja brzina smanjuje za 2 puta. Razlog je što će se memstore brže puniti i datoteke će se češće ispirati, a pri čitanju će trebati obraditi više datoteka, što je prilično komplicirana operacija za HB. U stvarnim uvjetima, to se može riješiti razmišljanjem o strategiji prethodnog dijeljenja i zbijanja; posebno koristimo uslužni program koji smo sami napisali koji skuplja smeće i sažima HDatoteke neprestano u pozadini. Vrlo je moguće da su za DataStax testove dodijelili samo 1 regiju po tablici (što nije točno) i to bi donekle razjasnilo zašto je HB bio toliko inferioran u njihovim testovima čitanja.
Iz ovoga se izvode sljedeći preliminarni zaključci. Pod pretpostavkom da tijekom testiranja nisu napravljene veće pogreške, tada Cassandra izgleda poput kolosa na glinenim nogama. Točnije, dok balansira na jednoj nozi, kao na slici s početka članka, pokazuje relativno dobre rezultate, ali u borbi pod istim uvjetima potpuno gubi. U isto vrijeme, uzimajući u obzir nisku iskorištenost CPU-a na našem hardveru, naučili smo postaviti dva RegionServer HB-a po hostu i time udvostručili performanse. Oni. Uzimajući u obzir iskorištenost resursa, situacija za CS je još žalosnija.
Naravno, ovi testovi su prilično sintetički i količina podataka koja je ovdje korištena je relativno skromna. Moguće je da bi situacija bila drugačija kad bismo prešli na terabajte, ali dok za HB možemo učitati terabajte, za CS se to pokazalo problematičnim. Često je izbacivao OperationTimedOutException čak i s ovim volumenima, iako su parametri za čekanje odgovora već bili nekoliko puta povećani u usporedbi sa zadanim.
Nadam se da ćemo zajedničkim snagama pronaći uska grla CS-a i ako to ubrzamo onda ću na kraju posta svakako dodati informaciju o konačnim rezultatima.
UPD: Zahvaljujući savjetima drugova, uspio sam ubrzati čitanje. Bio je:
159 644 operacije (4 tablice, 5 tokova, serija 100).
Dodano:
.withLoadBalancingPolicy(new TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().build()))
I igrao sam se s brojem niti. Rezultat je sljedeći:
4 tablice, 100 niti, serija = 1 (dio po dio): 301 operacija
4 tablice, 100 niti, serija = 10: 447 608 operacija
4 tablice, 100 niti, serija = 100: 625 655 operacija
Kasnije ću primijeniti druge savjete za ugađanje, pokrenuti cijeli testni ciklus i dodati rezultate na kraju posta.
Izvor: www.habr.com
