

Hej Habr! Vašoj pozornosti predstavljam prijevod članka
.
Kada su u pitanju relacijske baze podataka, ne mogu a da ne pomislim da nešto nedostaje. Koriste se posvuda. Dostupno je mnogo različitih baza podataka, od male i korisne SQLite do moćne Teradate. Ali postoji samo nekoliko članaka koji objašnjavaju kako baza podataka radi. Možete tražiti sami koristeći "howdoesarelationaldatabasework" da vidite koliko malo rezultata ima. Štoviše, ti su članci kratki. Ako ste u potrazi za najnovijim buzzy tehnologijama (BigData, NoSQL ili JavaScript), pronaći ćete detaljnije članke koji objašnjavaju kako one funkcioniraju.
Jesu li relacijske baze podataka prestare i predosadne da bi se objašnjavale izvan sveučilišnih kolegija, znanstvenih radova i knjiga?

Kao programer, mrzim koristiti nešto što ne razumijem. A ako se baze podataka koriste više od 40 godina, mora postojati razlog. Tijekom godina proveo sam stotine sati kako bih uistinu razumio ove čudne crne kutije koje koristim svaki dan. Relacijske baze podataka vrlo zanimljivo jer oni temeljeno na korisnim i ponovno upotrebljivim konceptima. Ako ste zainteresirani za razumijevanje baze podataka, ali nikada niste imali vremena ili volje zadubiti se u ovu široku temu, trebali biste uživati u ovom članku.
Iako je naslov ovog članka eksplicitan, svrha ovog članka nije razumjeti kako koristiti bazu podataka, dakle, trebali biste već znati kako napisati jednostavan zahtjev za povezivanje i osnovne upite ZDRAVO; inače možda nećete razumjeti ovaj članak. To je jedino što trebate znati, ostalo ću vam objasniti.
Počet ću s nekim osnovama računalne znanosti, kao što je vremenska složenost algoritama (BigO). Znam da neki od vas mrze ovaj koncept, ali bez njega nećete moći razumjeti zamršenosti unutar baze podataka. Budući da je ovo velika tema, Usredotočit ću se na ono što mislim da je važno: kako baza podataka obrađuje SQL upit. Samo ću se predstaviti osnovni pojmovi baze podatakatako da na kraju članka imate ideju o tome što se događa ispod haube.
Budući da je ovo dugačak i tehnički članak koji uključuje mnogo algoritama i podatkovnih struktura, uzmite si vremena da ga pročitate. Neki koncepti mogu biti teški za razumijevanje; možete ih preskočiti i svejedno dobiti opću ideju.
Za bolje upućene, ovaj članak je podijeljen u 3 dijela:
- Pregled komponenti baze podataka niske i visoke razine
- Pregled procesa optimizacije upita
- Pregled upravljanja transakcijama i međuspremnikom
Natrag na osnove
Prije mnogo godina (u dalekoj, dalekoj galaksiji...), programeri su morali znati točan broj operacija koje su kodirali. Znali su svoje algoritme i strukture podataka napamet jer si nisu mogli priuštiti trošenje CPU-a i memorije svojih sporih računala.
U ovom dijelu, podsjetit ću vas na neke od ovih koncepata jer su ključni za razumijevanje baze podataka. Također ću predstaviti koncept indeks baze podataka.
O(1) nasuprot O(n2)
U današnje vrijeme mnogi programeri ne mare za vremensku složenost algoritama... i u pravu su!
Ali kada imate posla s mnogo podataka (ne govorim o tisućama) ili ako se borite s milisekundama, postaje kritično razumjeti ovaj koncept. I kao što možete zamisliti, baze podataka moraju se nositi s obje situacije! Neću vas tjerati da trošite više vremena nego što je potrebno da biste prenijeli poantu. To će nam pomoći da kasnije razumijemo koncept optimizacije temeljene na troškovima (koštati temelji se optimizacija).
koncept
Vremenska složenost algoritma koristi se da se vidi koliko će vremena trebati da se izvrši algoritam za određenu količinu podataka. Da bismo opisali ovu složenost, koristimo matematičku notaciju velikog O. Ova se notacija koristi s funkcijom koja opisuje koliko operacija treba algoritam za određeni broj ulaza.
Na primjer, kada kažem "ovaj algoritam ima složenost O(some_function())", to znači da algoritam zahtijeva neke_funkcije(a_certain_amount_of_data) operacije za obradu određene količine podataka.
U tom slučaju, Nije bitna količina podataka**, inače ** kako se broj operacija povećava s povećanjem količine podataka. Vremenska složenost ne daje točan broj operacija, ali je dobar način za procjenu vremena izvršenja.
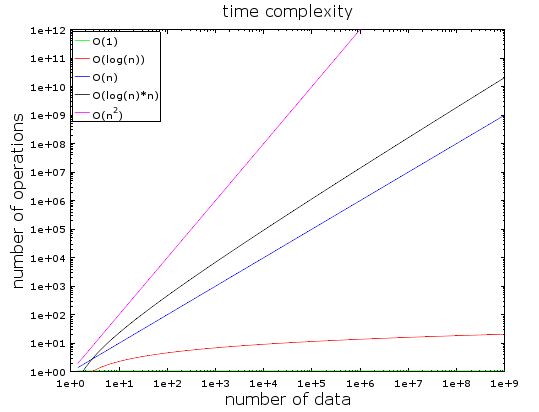
Na ovom grafikonu možete vidjeti broj operacija u odnosu na količinu ulaznih podataka za različite vrste vremenske složenosti algoritama. Koristio sam logaritamsku ljestvicu da ih prikažem. Drugim riječima, količina podataka brzo raste s 1 na 1 milijardu. Vidimo da:
- O(1) ili konstantna složenost ostaje konstantna (inače se ne bi zvala konstantna složenost).
- O(klada(n)) ostaje nizak čak i s milijardama podataka.
- Najveća poteškoća - O(n2), gdje broj operacija brzo raste.
- Druge dvije komplikacije rastu jednako brzo.
Primjeri
Kod male količine podataka razlika između O(1) i O(n2) je zanemariva. Na primjer, recimo da imate algoritam koji treba obraditi 2000 elemenata.
- O(1) algoritam koštat će vas 1 operacija
- O(log(n)) algoritam koštat će vas 7 operacija
- O(n) algoritam koštat će vas 2 operacija
- O(n*log(n)) algoritam koštat će vas 14 operacija
- O(n2) algoritam koštat će vas 4 operacija
Razlika između O(1) i O(n2) se čini velikom (4 milijuna operacija), ali ćete izgubiti najviše 2 ms, samo vrijeme da trepnete očima. Doista, moderni procesori mogu obraditi . Zbog toga performanse i optimizacija nisu problem u mnogim IT projektima.
Kao što sam rekao, i dalje je važno poznavati ovaj koncept kada radite s ogromnim količinama podataka. Ako ovaj put algoritam mora obraditi 1 elemenata (što nije puno za bazu podataka):
- O(1) algoritam koštat će vas 1 operacija
- O(log(n)) algoritam koštat će vas 14 operacija
- O(n) algoritam koštat će vas 1 operacija
- O(n*log(n)) algoritam koštat će vas 14 operacija
- O(n2) algoritam koštat će vas 1 operacija
Nisam računao, ali rekao bih da uz O(n2) algoritam imate vremena popiti kavu (čak dvije!). Dodate li još 0 količini podataka, imat ćete vremena odspavati.
Idemo dublje
Za vaše podatke:
- Dobro pretraživanje hash tablice pronalazi element u O(1).
- Pretraživanje dobro uravnoteženog stabla daje rezultate u O(log(n)).
- Pretraživanje niza daje rezultate u O(n).
- Najbolji algoritmi za sortiranje imaju složenost O(n*log(n)).
- Loš algoritam sortiranja ima složenost O(n2).
Napomena: U sljedećim dijelovima vidjet ćemo ove algoritme i strukture podataka.
Postoji nekoliko vrsta vremenske složenosti algoritama:
- scenarij prosječnog slučaja
- najbolji mogući scenarij
- i najgori mogući scenarij
Vremenska složenost često je najgori mogući scenarij.
Govorio sam samo o vremenskoj složenosti algoritma, ali složenost se također odnosi na:
- potrošnja memorije algoritma
- algoritam potrošnje I/O diska
Naravno, postoje komplikacije gore od n2, na primjer:
- n4: ovo je strašno! Neki od spomenutih algoritama imaju ovu složenost.
- 3n: ovo je još gore! Jedan od algoritama koje ćemo vidjeti u sredini ovog članka ima ovu složenost (i zapravo se koristi u mnogim bazama podataka).
- faktorijel n: nikada nećete dobiti rezultate čak ni s malom količinom podataka.
- nn: Ako naiđete na ovu kompleksnost, trebali biste se zapitati je li to doista vaše polje djelovanja...
Napomena: Nisam vam dao stvarnu definiciju oznake velikog O, samo ideju. Ovaj članak možete pročitati na za realnu (asimptotsku) definiciju.
Spoji Sort
Što radite kada trebate sortirati zbirku? Što? Pozovete funkciju sort()... Ok, dobar odgovor... Ali za bazu podataka, morate razumjeti kako ova funkcija sort() radi.
Postoji nekoliko dobrih algoritama za sortiranje, pa ću se usredotočiti na najvažnije: sortiranje spajanjem. Možda trenutno ne razumijete zašto je sortiranje podataka korisno, ali trebali biste nakon dijela optimizacije upita. Štoviše, razumijevanje sortiranja spajanjem pomoći će nam da kasnije razumijemo uobičajenu operaciju spajanja baze podataka tzv spojiti pridruži (udruga spajanja).
Sjediniti
Kao i mnogi korisni algoritmi, sortiranje spajanjem oslanja se na trik: kombiniranje 2 sortirana niza veličine N/2 u N-elementno sortirano polje košta samo N operacija. Ova operacija se naziva spajanje.
Pogledajmo što to znači na jednostavnom primjeru:
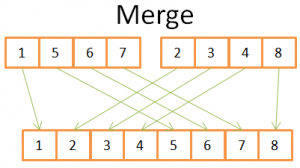
Ova slika pokazuje da za izgradnju konačnog sortiranog niza od 8 elemenata trebate samo jednom ponoviti kroz 2 niza od 4 elementa. Budući da su oba niza od 4 elementa već sortirana:
- 1) uspoređujete oba trenutna elementa u dva niza (na početku trenutni = prvi)
- 2) zatim uzmite najmanji i stavite ga u niz od 8 elemenata
- 3) i prijeđite na sljedeći element u nizu gdje ste uzeli najmanji element
- i ponavljajte 1,2,3 dok ne dođete do posljednjeg elementa jednog od nizova.
- Zatim uzmete preostale elemente drugog niza da biste ih stavili u niz od 8 elemenata.
Ovo funkcionira jer su oba niza od 4 elementa sortirana pa se ne morate "vraćati" u tim nizovima.
Sada kada razumijemo trik, evo mog pseudokoda za spajanje:
array mergeSort(array a)
if(length(a)==1)
return a[0];
end if
//recursive calls
[left_array right_array] := split_into_2_equally_sized_arrays(a);
array new_left_array := mergeSort(left_array);
array new_right_array := mergeSort(right_array);
//merging the 2 small ordered arrays into a big one
array result := merge(new_left_array,new_right_array);
return result;Sortiranje spajanjem rastavlja problem na manje probleme i zatim pronalazi rezultate manjih problema kako bi se dobio rezultat izvornog problema (napomena: ova vrsta algoritma zove se podijeli pa vladaj). Ako ne razumijete ovaj algoritam, ne brinite; Nisam to razumio prvi put kad sam to vidio. Ako vam može pomoći, ovaj algoritam vidim kao dvofazni algoritam:
- Faza podjele, gdje se niz dijeli na manje nizove
- Faza razvrstavanja je u kojoj se mali nizovi kombiniraju (pomoću unije) da bi se formirao veći niz.
Faza podjele
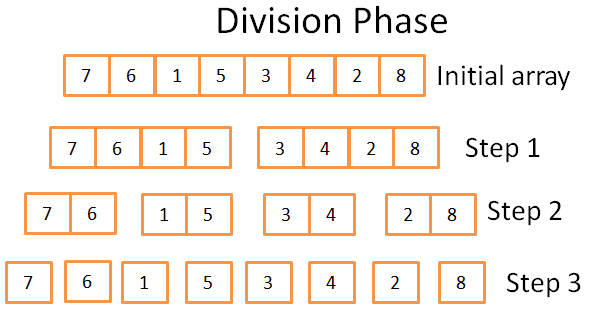
U fazi podjele, niz se dijeli na jedinstvene nizove u 3 koraka. Formalni broj koraka je log(N) (budući da je N=8, log(N) = 3).
Kako ja to znam?
Ja sam genije! Jednom riječju – matematika. Ideja je da svaki korak dijeli veličinu izvornog niza s 2. Broj koraka je koliko puta možete podijeliti izvorni niz na dva. Ovo je točna definicija logaritma (baza 2).
Faza sortiranja
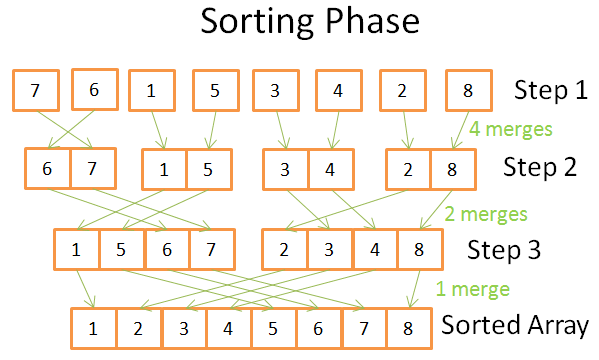
U fazi sortiranja počinjete s jedinstvenim (jednoelementnim) nizovima. Tijekom svakog koraka primjenjujete više operacija spajanja, a ukupni trošak je N = 8 operacija:
- U prvoj fazi imate 4 spajanja koja koštaju 2 operacije svako
- U drugom koraku imate 2 spajanja koja koštaju 4 operacije svako
- U trećem koraku imate 1 spajanje koje košta 8 operacija
Budući da ima log(N) koraka, ukupni trošak N * log(N) operacija.
Prednosti sortiranja spajanjem
Zašto je ovaj algoritam tako moćan?
Jer:
- Možete ga promijeniti kako biste smanjili memorijski otisak tako da ne stvarate nove nizove, već izravno mijenjate ulazni niz.
Napomena: ova vrsta algoritma se zove (sortiranje bez dodatne memorije).
- Možete ga promijeniti tako da istovremeno koristi prostor na disku i malu količinu memorije, a da pritom ne stvarate značajne I/O troškove. Ideja je da se u memoriju učitaju samo oni dijelovi koji se trenutno obrađuju. Ovo je važno kada trebate sortirati tablicu od više gigabajta sa samo međuspremnikom od 100 megabajta.
Napomena: ova vrsta algoritma se zove .
- Možete ga promijeniti da radi na više procesa/niti/poslužitelja.
Na primjer, distribuirano sortiranje spajanjem jedna je od ključnih komponenti (što je struktura u velikim podacima).
- Ovaj algoritam može pretvoriti olovo u zlato (stvarno!).
Ovaj algoritam sortiranja koristi se u većini (ako ne i u svim) bazama podataka, ali nije jedini. Ako želite znati više, možete pročitati ovo , koji govori o prednostima i manama uobičajenih algoritama za sortiranje baza podataka.
Niz, stablo i hash tablica
Sada kada razumijemo ideju vremenske složenosti i sortiranja, trebao bih vam reći o 3 strukture podataka. Ovo je važno jer oni temelj su modernih baza podataka. Također ću predstaviti koncept indeks baze podataka.
red
Dvodimenzionalni niz je najjednostavnija struktura podataka. Tablica se može smatrati nizom. Na primjer:
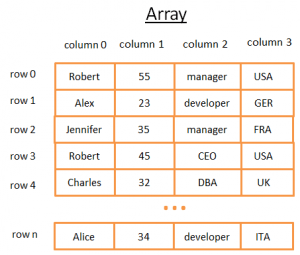
Ovaj 2-dimenzionalni niz je tablica s redovima i stupcima:
- Svaka linija predstavlja entitet
- Stupci pohranjuju svojstva koja opisuju entitet.
- Svaki stupac pohranjuje podatke određene vrste (cijeli broj, niz, datum...).
Ovo je prikladno za pohranu i vizualizaciju podataka, međutim, kada trebate pronaći određenu vrijednost, to nije prikladno.
Na primjer, ako želite pronaći sve dečke koji rade u Ujedinjenom Kraljevstvu, trebali biste pogledati svaki red da biste utvrdili pripada li taj red Ujedinjenom Kraljevstvu. To će vas koštati N transakcijaGdje N - broj linija, što nije loše, ali može li postojati brži način? Sada je vrijeme da se upoznamo sa drvećem.
Bilješka: većina modernih baza podataka pruža proširene nizove za učinkovito pohranjivanje tablica: tablice organizirane hrpom i tablice organizirane indeksom. Ali to ne mijenja problem brzog pronalaženja određenog stanja u grupi stupaca.
Stablo baze podataka i indeks
Binarno stablo pretraživanja je binarno stablo s posebnim svojstvom, ključ na svakom čvoru mora biti:
- veći od svih ključeva pohranjenih u lijevom podstablu
- manje od svih ključeva pohranjenih u desnom podstablu
Pogledajmo što to vizualno znači
Ideja
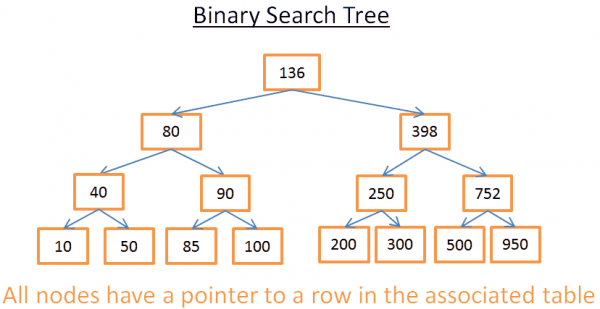
Ovo stablo ima N = 15 elemenata. Recimo da tražim 208:
- Počinjem od korijena čiji je ključ 136. Budući da je 136<208, gledam desno podstablo čvora 136.
- 398>208 stoga gledam lijevo podstablo čvora 398
- 250>208 stoga gledam lijevo podstablo čvora 250
- 200<208, stoga gledam desno podstablo čvora 200. Ali 200 nema pravo podstablo, vrijednost ne postoji (jer ako postoji, bit će u desnom podstablu 200).
Sada recimo da tražim 40
- Počinjem od korijena čiji je ključ 136. Budući da je 136 > 40, gledam lijevo podstablo čvora 136.
- 80 > 40, stoga gledam lijevo podstablo čvora 80
- 40 = 40, čvor postoji. Dohvaćam ID retka unutar čvora (nije prikazan na slici) i tražim u tablici zadani ID retka.
- Poznavanje ID-a retka omogućuje mi da točno znam gdje se podaci nalaze u tablici, tako da ih mogu odmah dohvatiti.
Na kraju će me obje pretrage koštati broja razina unutar stabla. Ako ste pažljivo pročitali dio o sortiranju spajanjem, trebali biste vidjeti da postoje log(N) razine. Ispada, dnevnik troškova pretraživanja (N), nije loše!
Vratimo se našem problemu
Ali ovo je vrlo apstraktno, pa se vratimo našem problemu. Umjesto jednostavnog cijelog broja, zamislite niz koji predstavlja državu nekoga iz prethodne tablice. Recimo da imate stablo koje sadrži polje "država" (stupac 3) tablice:
- Ako želite znati tko radi u UK
- pogledate stablo da biste dobili čvor koji predstavlja Veliku Britaniju
- unutar "UKnode" pronaći ćete lokaciju evidencije radnika u UK.
Ova će pretraga koštati log(N) operacija umjesto N operacija ako izravno koristite niz. Ono što ste upravo predstavili bilo je indeks baze podataka.
Možete izgraditi stablo indeksa za bilo koju grupu polja (niz, broj, 2 retka, broj i niz, datum...) sve dok imate funkciju za usporedbu ključeva (tj. grupe polja) tako da možete postaviti poredak među ključevima (što je slučaj za sve osnovne tipove u bazi podataka).
B+TreeIndex
Iako ovo stablo dobro funkcionira za dobivanje određene vrijednosti, postoji VELIKI problem kada vam zatreba dobiti više elemenata između dvije vrijednosti. To će koštati O(N) jer ćete morati pogledati svaki čvor u stablu i provjeriti nalazi li se između ove dvije vrijednosti (npr. s uređenim obilaskom stabla). Štoviše, ova operacija nije prilagođena I/O disku jer morate čitati cijelo stablo. Moramo pronaći način za učinkovito izvršenje zahtjev za opseg. Kako bi riješile ovaj problem, moderne baze podataka koriste modificiranu verziju prethodnog stabla pod nazivom B+Tree. U stablu B+Tree:
- samo najniži čvorovi (listovi) pohraniti informacije (lokacija redaka u povezanoj tablici)
- ostali čvorovi su ovdje za usmjeravanje na ispravan čvor tijekom pretrage.
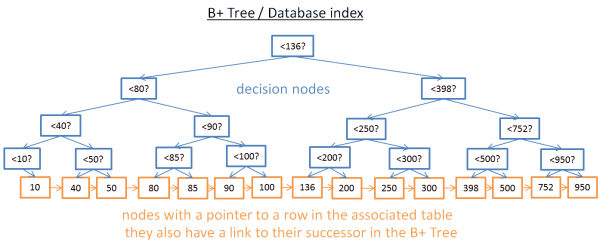
Kao što vidite, ovdje ima više čvorova (dvaput). Doista, imate dodatne čvorove, "čvorove odlučivanja", koji će vam pomoći da pronađete ispravan čvor (koji pohranjuje lokaciju redaka u pridruženoj tablici). Ali složenost pretraživanja je i dalje O(log(N)) (postoji još samo jedna razina). Velika je razlika u tome čvorovi na nižoj razini povezani su sa svojim nasljednicima.
S ovim B+Tree, ako tražite vrijednosti između 40 i 100:
- Samo trebate potražiti 40 (ili najbližu vrijednost nakon 40 ako 40 ne postoji) kao što ste učinili s prethodnim stablom.
- Zatim prikupite 40 nasljednika koristeći izravne veze nasljednika dok ne dosegnete 100.
Recimo da pronađete M nasljednika i stablo ima N čvorova. Pronalaženje određenog čvora košta log(N) kao i prethodno stablo. Ali kada dobijete ovaj čvor, dobit ćete M nasljednika u M operacijama s referencama na njihove nasljednike. Ova pretraga košta samo M+log(N) operacija u usporedbi s N operacijama na prethodnom stablu. Štoviše, ne morate čitati cijelo stablo (samo M+log(N) čvorova), što znači manje korištenje diska. Ako je M malo (npr. 200 redaka), a N veliko (1 redaka), bit će VELIKA razlika.
Ali tu (opet!) nastaju novi problemi. Ako dodate ili izbrišete red u bazi podataka (a time i u pridruženom indeksu B+Tree):
- morate održavati red između čvorova unutar B+Stabla, inače nećete moći pronaći čvorove unutar nesortiranog stabla.
- morate zadržati minimalni mogući broj razina u B+Tree, inače O(log(N)) vremenska složenost postaje O(N).
Drugim riječima, B+Tree mora biti samouređujući i uravnotežen. Srećom, to je moguće pomoću pametnih operacija brisanja i umetanja. Ali to ima svoju cijenu: umetanja i brisanja u B+ stablu koštaju O(log(N)). Zato su neki od vas to čuli korištenje previše indeksa nije dobra ideja. Stvarno, usporavate brzo umetanje/ažuriranje/brisanje retka u tablicijer baza podataka treba ažurirati indekse tablice koristeći skupu O(log(N)) operaciju za svaki indeks. Štoviše, dodavanje indeksa znači više posla za transakcijski menadžer (bit će opisano na kraju članka).
Za više detalja možete pogledati članak na Wikipediji . Ako želite primjer implementacije B+Tree u bazu podataka, pogledajte и od vodećeg MySQL programera. Obojica se fokusiraju na to kako InnoDB (MySQL motor) rukuje indeksima.
Napomena: čitatelj mi je rekao da bi, zbog optimizacije niske razine, B+ stablo trebalo biti potpuno uravnoteženo.
Raspršena tablica
Naša posljednja važna struktura podataka je hash tablica. Ovo je vrlo korisno kada želite brzo potražiti vrijednosti. Štoviše, razumijevanje hash tablice pomoći će nam da kasnije razumijemo uobičajenu operaciju spajanja baze podataka koja se zove hash pridruživanje ( hash pridružiti). Ovu strukturu podataka baza podataka također koristi za pohranu nekih internih stvari (npr. zaključati stol ili međuspremnik, kasnije ćemo vidjeti oba ova koncepta).
Raspršena tablica je struktura podataka koja brzo pronalazi element prema ključu. Za izradu hash tablice potrebno je definirati:
- ključ za svoje elemente
- hash funkcija za ključeve. Izračunati hash ključevi daju lokaciju elemenata (tzv segmentima ).
- funkcija za usporedbu ključeva. Nakon što pronađete ispravan segment, morate pronaći element koji tražite unutar segmenta pomoću ove usporedbe.
Jednostavan primjer
Uzmimo jasan primjer:
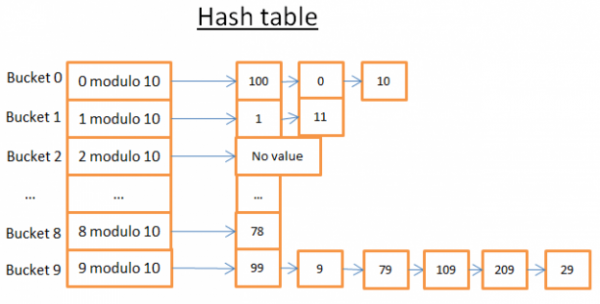
Ova hash tablica ima 10 segmenata. Pošto sam lijen, slikao sam samo 5 segmenata, ali znam da si pametan, pa ću ti pustiti da sam slikaš ostalih 5. Koristio sam hash funkciju modulo 10 ključa. Drugim riječima, pohranjujem samo posljednju znamenku ključa elementa da pronađem njegov segment:
- ako je zadnja znamenka 0, element spada u segment 0,
- ako je zadnja znamenka 1, element spada u segment 1,
- ako je zadnja znamenka 2, element spada u područje 2,
- ...
Funkcija usporedbe koju sam koristio je jednostavno jednakost između dva cijela broja.
Recimo da želite dobiti element 78:
- Hash tablica izračunava hash kod za 78, što je 8.
- Hash tablica gleda na segment 8, a prvi element koji pronađe je 78.
- Vraća vam stavku 78
- Pretraga košta samo 2 operacije (jedan za izračunavanje hash vrijednosti, a drugi za traženje elementa unutar segmenta).
Sada recimo da želite dobiti element 59:
- Hash tablica izračunava hash kod za 59, što je 9.
- Hash tablica pretražuje u segmentu 9, prvi pronađeni element je 99. Budući da je 99!=59, element 99 nije važeći element.
- Istom logikom uzima se drugi element (9), treći (79), ..., zadnji (29).
- Element nije pronađen.
- Pretraga je koštala 7 operacija.
Dobra hash funkcija
Kao što vidite, ovisno o vrijednosti koju tražite, cijena nije ista!
Ako sada promijenim hash funkciju modulo 1 ključa (to jest, uzimajući zadnjih 000 znamenki), drugo traženje košta samo 000 operaciju jer nema elemenata u segmentu 6. Pravi je izazov pronaći dobru funkciju raspršivanja koja će stvoriti spremnike koji sadrže vrlo mali broj elemenata.
U mom primjeru, lako je pronaći dobru hash funkciju. Ali ovo je jednostavan primjer, teže je pronaći dobru hash funkciju kada je ključ:
- niz (na primjer - prezime)
- 2 reda (na primjer - prezime i ime)
- 2 reda i datum (na primjer - prezime, ime i datum rođenja)
- ...
S dobrom hash funkcijom, pretraživanje hash tablice košta O(1).
Array vs hash tablica
Zašto ne koristiti niz?
Hmm, dobro pitanje.
- Hash tablica može biti djelomično učitano u memoriju, a preostali segmenti mogu ostati na disku.
- S nizom morate koristiti kontinuirani prostor u memoriji. Ako opterećujete veliki stol vrlo je teško pronaći dovoljno kontinuiranog prostora.
- Za hash tablicu možete odabrati ključ koji želite (na primjer, državu i prezime osobe).
Za više informacija, možete pročitati članak o , što je učinkovita implementacija hash tablice; ne morate razumjeti Javu da biste razumjeli koncepte obrađene u ovom članku.
Izvor: www.habr.com
