

Razmotrite koncept Kubernetes nadzora, upoznajte se s Prometheus alatom i razgovarajte o uzbunjivanju.
Tema monitoringa je opsežna, ne može se rastaviti u jednom članku. Svrha ovog teksta je pružiti pregled alata, koncepata i pristupa.
Materijal članka je stisak iz . Ako želite pohađati cijeli tečaj - prijavite se za tečaj na .

Što se nadzire u Kubernetes klasteru
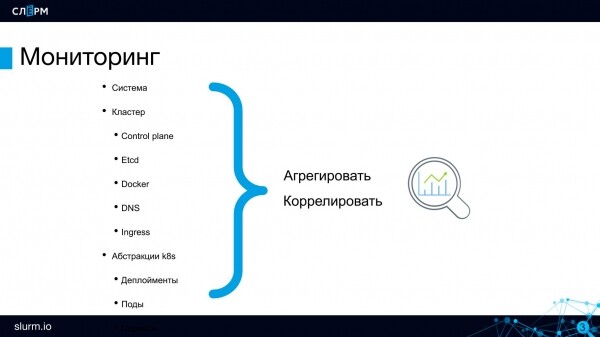
fizičkih poslužitelja. Ako je Kubernetes klaster raspoređen na svojim poslužiteljima, morate pratiti njihovo zdravlje. Zabbix rješava ovaj zadatak; ako radite s njim, onda ne trebate odbiti, neće biti sukoba. Zabbix je taj koji prati stanje naših poslužitelja.
Prijeđimo na praćenje na razini klastera.
Komponente kontrolne ravnine: API, Scheduler i drugi. U najmanju ruku, morate biti sigurni da je API poslužitelja ili etcd-a veći od 0. Etcd može vratiti puno metrika: po diskovima na kojima se vrti, po zdravlju njegovog etcd klastera i druge.
Lučki radnik pojavio se davno i svi su svjesni njegovih problema: puno kontejnera stvara smrzavanje i druge probleme. Stoga bi i sam Docker, kao sustav, trebao biti kontroliran, barem zbog dostupnosti.
dns. Ako DNS otpadne u klasteru, onda će cijela Discovery usluga otpasti nakon toga, pozivi od podova do podova će prestati raditi. U mojoj praksi nije bilo takvih problema, ali to ne znači da stanje DNS-a ne treba pratiti. Kašnjenje zahtjeva i neke druge metrike mogu se pratiti na CoreDNS-u.
Ingress. Potrebno je kontrolirati dostupnost ulaza (uključujući Ingress Controller) kao ulaznih točaka u projekt.
Glavne komponente klastera su rastavljene - sada se spustimo na razinu apstrakcija.
Čini se da se aplikacije izvode u podovima, što znači da ih treba kontrolirati, ali u stvarnosti nisu. Podovi su prolazni: danas rade na jednom poslužitelju, sutra na drugom; danas ih ima 10, sutra 2. Dakle, mahune nitko ne prati. Unutar arhitekture mikroservisa važnije je kontrolirati dostupnost aplikacije u cjelini. Posebno provjerite dostupnost krajnjih točaka usluge: radi li nešto? Ako je aplikacija dostupna, što se događa iza nje, koliko sada ima replika - to su pitanja drugog reda. Nema potrebe nadzirati pojedinačne primjerke.
Na posljednjoj razini trebate kontrolirati rad same aplikacije, uzeti poslovne metrike: broj narudžbi, ponašanje korisnika i tako dalje.
Prometej
Najbolji sustav za praćenje klastera je . Ne znam niti jedan alat koji može parirati Prometeju po kvaliteti i jednostavnosti korištenja. Izvrstan je za fleksibilnu infrastrukturu, pa kad kažu “Kubernetes nadzor”, obično misle na Prometheus.
Postoji nekoliko opcija za početak rada s Prometheusom: koristeći Helm, možete instalirati obični Prometheus ili Prometheus Operator.
- Obični Prometej. S njim je sve u redu, ali trebate konfigurirati ConfigMap - zapravo, napisati tekstualne konfiguracijske datoteke, kao što smo radili prije, prije arhitekture mikroservisa.
- Prometheus Operator je malo rašireniji, malo kompliciraniji u smislu interne logike, ali je lakše raditi s njim: postoje zasebni objekti, apstrakcije se dodaju u klaster, tako da su mnogo praktičniji za kontrolu i konfiguraciju.
Da biste razumjeli proizvod, preporučujem da prvo instalirate obični Prometheus. Sve ćete morati konfigurirati kroz config, ali to će biti korisno: shvatit ćete što čemu pripada i kako je konfigurirano. U Prometheus Operatoru odmah se uzdižete na apstrakciju više, iako možete zaroniti iu dubine ako želite.
Prometheus je dobro integriran s Kubernetesom: može pristupiti i komunicirati s API poslužiteljem.
Prometheus je popularan, zbog čega ga podržava veliki broj aplikacija i programskih jezika. Podrška je potrebna, jer Prometheus ima svoj vlastiti metrički format, a za prijenos vam je potrebna ili biblioteka unutar aplikacije ili gotov izvoznik. A takvih izvoznika ima poprilično. Na primjer, postoji PostgreSQL Exporter: uzima podatke iz PostgreSQL-a i pretvara ih u Prometheus format tako da Prometheus može raditi s njima.
Prometejska arhitektura
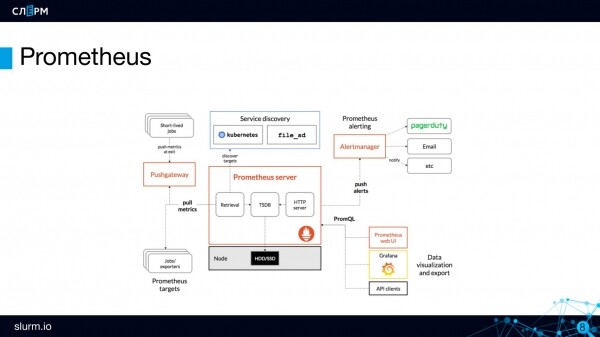
Prometheus poslužitelj je zadnji dio, Prometejev mozak. Ovdje se pohranjuju i obrađuju metrički podaci.
Mjerni podaci su pohranjeni u bazi podataka vremenskih serija (TSDB). TSDB nije zasebna baza podataka, već paket na jeziku Go koji je ugrađen u Prometheus. Grubo rečeno, sve je u jednoj binarnoj jedinici.
Ne pohranjujte podatke u TSDB dugo vremena
Infrastruktura Prometheus nije prikladna za dugotrajnu pohranu metrike. Zadano razdoblje zadržavanja je 15 dana. Možete premašiti ovo ograničenje, ali imajte na umu: što više podataka pohranjujete u TSDB i što dulje to činite, to će potrošiti više resursa. Pohranjivanje povijesnih podataka u Prometheusu smatra se lošom praksom.
Ako imate ogroman promet, broj metrika je stotine tisuća u sekundi, tada je bolje ograničiti njihovu pohranu prostorom na disku ili razdobljem. Obično se "vrući podaci" pohranjuju u TSDB, metrika za samo nekoliko sati. Za dužu pohranu koristi se vanjska pohrana u onim bazama podataka koje su stvarno prikladne za to, na primjer, InfluxDB, ClickHouse i tako dalje. Vidio sam više dobrih recenzija o ClickHouseu.
Prometheus Server radi na modelu povući: on traži metriku do onih krajnjih točaka koje smo mu dali. Rekli su: "idi na API poslužitelj", a on odlazi tamo svakih n-tih sekundi i uzima metriku.
Za objekte s kratkim vijekom trajanja (posao ili cron posao) koji se mogu pojaviti između razdoblja struganja, postoji komponenta Pushgateway. U njega se guraju metrike iz kratkoročnih objekata: posao je podignut, izvršio radnju, poslao metrike Pushgatewayu i dovršen. Nakon nekog vremena, Prometheus će sići vlastitim tempom i pokupiti ove metrike od Pushgatewaya.
Za konfiguriranje obavijesti u Prometheusu postoji zasebna komponenta - Alertmanager. I pravila uzbunjivanja. Na primjer, trebate stvoriti upozorenje ako je API poslužitelja 0. Kada se događaj pokrene, upozorenje se prosljeđuje upravitelju upozorenja za daljnje slanje. Upravitelj upozorenja ima prilično fleksibilne postavke usmjeravanja: jedna grupa upozorenja može se poslati u telegram chat administratora, druga u chat programera, a treća u chat infrastrukturnih radnika. Obavijesti se mogu slati na Slack, Telegram, e-poštu i druge kanale.
I na kraju, ispričat ću vam o značajci Prometheus killer - Otkrivanje. Kada radite s Prometheusom, ne morate specificirati specifične adrese objekata za praćenje, dovoljno je postaviti njihovu vrstu. Odnosno, ne morate pisati "ovdje je IP adresa, ovdje je port - monitor", umjesto toga morate odrediti po kojim principima pronaći te objekte (ciljevi - ciljevi). Prometheus sam, ovisno o tome koji su objekti trenutno aktivni, izvlači potrebne i dodaje ih u nadzor.
Ovaj pristup dobro se uklapa u strukturu Kubernetesa, gdje također sve pluta: danas ima 10 poslužitelja, sutra 3. Kako ne bi svaki put navodili IP adresu poslužitelja, jednom su napisali kako ga pronaći - a Discovering će to učiniti .
Prometejski jezik se zove PromQL. Koristeći ovaj jezik, možete dobiti vrijednosti specifičnih mjernih podataka i zatim ih pretvoriti, izgraditi analitičke izračune na temelju njih.
https://prometheus.io/docs/prometheus/latest/querying/basics/
Простой запрос
container_memory_usage_bytes
Математические операции
container_memory_usage_bytes / 1024 / 1024
Встроенные функции
sum(container_memory_usage_bytes) / 1024 / 1024
Уточнение запроса
100 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]) * 100)Prometheus web sučelje
Prometheus ima vlastito, prilično minimalističko web sučelje. Prikladno samo za otklanjanje pogrešaka ili demonstraciju.
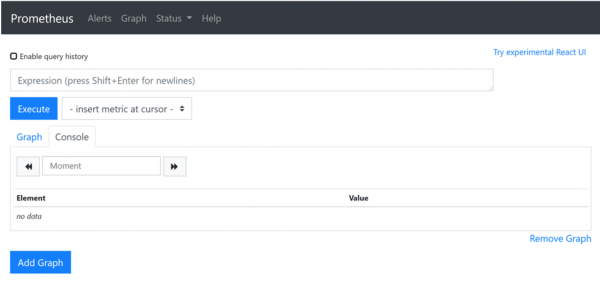
U retku Expression možete napisati upit u PromQL jeziku.
Kartica Upozorenja sadrži pravila upozorenja i imaju tri statusa:
- neaktivno - ako upozorenje trenutno nije aktivno, to jest, sve je u redu s njim, a nije radilo;
- na čekanju - ovo je ako je upozorenje radilo, ali slanje još nije prošlo. Odgoda je postavljena da kompenzira treptanje mreže: ako je navedena usluga porasla unutar jedne minute, tada se alarm još ne bi trebao oglasiti;
- pucanje je treći status kada uzbuna svijetli i šalje poruke.
U izborniku Status pronaći ćete pristup informacijama o tome što je Prometheus. Postoji i prijelaz na mete (ciljeve), o kojima smo gore govorili.
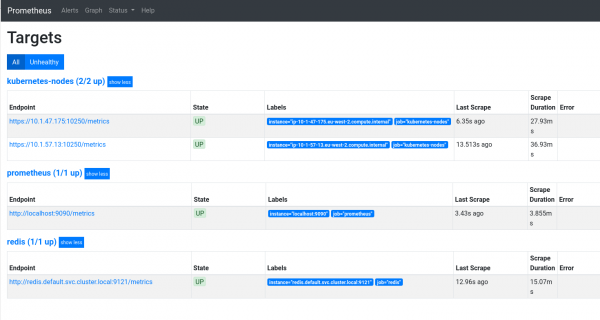
Za detaljniji pregled Prometheus sučelja, pogledajte .
Integracija s Grafanom
U Prometheus web sučelju nećete pronaći lijepe i razumljive grafikone iz kojih možete zaključiti o stanju klastera. Kako bi ih izgradio, Prometheus je integriran s Grafanom. Dobivamo takve nadzorne ploče.
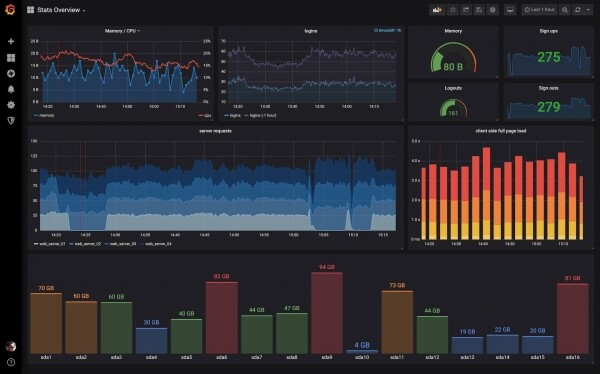
Postavljanje integracije Prometheusa i Grafane nije nimalo teško, upute možete pronaći u dokumentaciji: Pa, s ovim ću završiti.
U sljedećim člancima nastavit ćemo temu monitoringa: govorit ćemo o prikupljanju i analizi logova pomoću Grafana Lokija i alternativnih alata.
Autor: Marcel Ibraev, certificirani Kubernetes administrator, inženjer u praksi u tvrtki , govornik i programer tečaja Slurm.
Izvor: www.habr.com
