

Bok svima! Moje ime je Golov Nikolay. Prethodno sam radio u Avitu i vodio Data Platformu šest godina, odnosno radio sam na svim bazama: analitičkim (Vertica, ClickHouse), streaming i OLTP (Redis, Tarantool, VoltDB, MongoDB, PostgreSQL). Tijekom tog vremena bavio sam se velikim brojem baza podataka - vrlo različitih i neobičnih, te s nestandardnim slučajevima njihove uporabe.
Trenutno radim za ManyChat. U biti, ovo je startup – nov, ambiciozan i brzorastući. A kad sam se prvi put pridružio tvrtki, postavilo se klasično pitanje: “Što bi mladi startup sada trebao uzeti s tržišta DBMS-a i baza podataka?”
U ovom članku, na temelju mog izvješća na , odgovorit ću na ovo pitanje. Video verzija izvješća dostupna je na .
Općepoznate baze podataka 2020
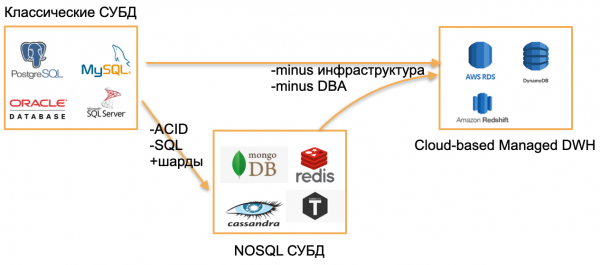
2020. je, pogledao sam oko sebe i vidio tri vrste baza podataka.
Prva vrsta - klasične OLTP baze podataka: PostgreSQL, SQL Server, Oracle, MySQL. Napisani su davno, ali su još uvijek relevantni jer su toliko poznati zajednici programera.
Druga vrsta je baze od "nule". Pokušali su se odmaknuti od klasičnih obrazaca napuštanjem SQL-a, tradicionalnih struktura i ACID-a, dodavanjem ugrađenog dijeljenja i drugih atraktivnih značajki. Na primjer, ovo je Cassandra, MongoDB, Redis ili Tarantool. Sva ta rješenja željela su tržištu ponuditi nešto fundamentalno novo i zauzela su svoju nišu jer su se pokazala izuzetno pogodna za određene zadatke. Ove baze podataka ću označiti krovnim pojmom NOSQL.
“Nule” su prošle, navikli smo se na NOSQL baze podataka, a svijet je, s moje točke gledišta, napravio sljedeći korak - upravljane baze podataka. Ove baze podataka imaju istu jezgru kao klasične OLTP baze podataka ili nove NoSQL. Ali nemaju potrebu za DBA i DevOps i rade na upravljanom hardveru u oblacima. Za programera je to “samo baza” koja negdje radi, ali nikoga nije briga kako je instalirana na server, tko je konfigurirao server i tko ga ažurira.
Primjeri takvih baza podataka:
- AWS RDS je upravljani omotač za PostgreSQL/MySQL.
- DynamoDB je AWS analog baze podataka temeljene na dokumentima, sličan Redisu i MongoDB-u.
- Amazon Redshift je upravljana analitička baza podataka.
To su u osnovi stare baze podataka, ali podignute u upravljanom okruženju, bez potrebe za radom s hardverom.
Bilješka. Primjeri su uzeti za AWS okruženje, ali njihovi analozi postoje i u Microsoft Azure, Google Cloud ili Yandex.Cloud.
Što ima novo u vezi ovoga? U 2020. ništa od ovoga.
Koncept bez poslužitelja
Ono što je zaista novo na tržištu u 2020. su rješenja bez poslužitelja ili bez poslužitelja.
Pokušat ću objasniti što to znači na primjeru obične usluge ili pozadinske aplikacije.
Da bismo postavili uobičajenu pozadinsku aplikaciju, kupujemo ili iznajmljujemo poslužitelj, kopiramo kod na njega, objavljujemo krajnju točku vani i redovito plaćamo najam, struju i usluge podatkovnog centra. Ovo je standardna shema.
Postoji li neki drugi način? S uslugama bez poslužitelja možete.
Što je fokus ovog pristupa: nema servera, nema čak ni najma virtualne instance u oblaku. Za implementaciju usluge kopirajte kod (funkcije) u repozitorij i objavite ga na krajnjoj točki. Tada jednostavno plaćamo svaki poziv ovoj funkciji, potpuno zanemarujući hardver na kojem se izvršava.
Pokušat ću ilustrirati ovaj pristup slikama.
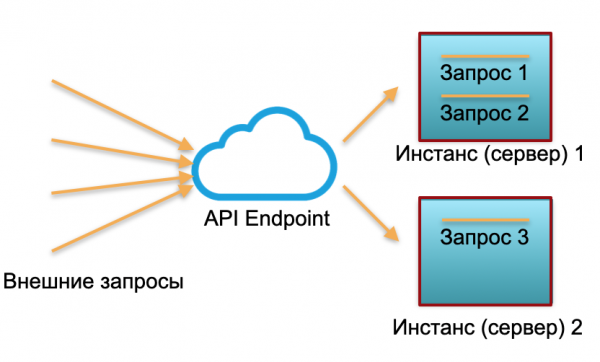
Klasična implementacija. Imamo uslugu s određenim opterećenjem. Podižemo dvije instance: fizičke poslužitelje ili instance u AWS-u. Eksterni zahtjevi se šalju tim instancama i tamo obrađuju.
Kao što vidite na slici, serveri nisu jednako raspoređeni. Jedan je 100% iskorišten, dva su zahtjeva, a jedan je samo 50% - djelomično u mirovanju. Ako ne stignu tri zahtjeva, već 30, tada se cijeli sustav neće moći nositi s opterećenjem i počet će usporavati.
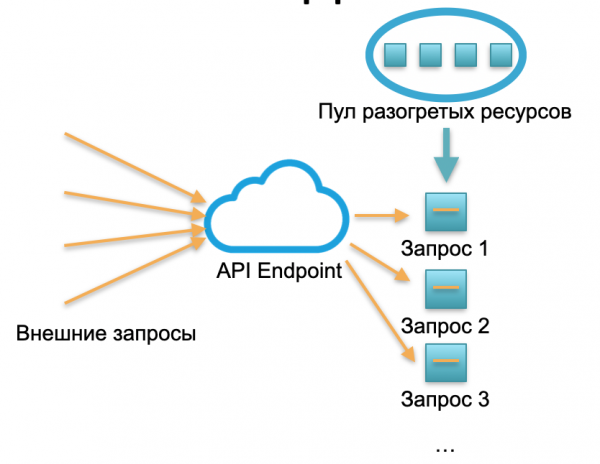
Implementacija bez poslužitelja. U okruženju bez poslužitelja takva usluga nema instance ili poslužitelje. Postoji određeni skup grijanih resursa - mali pripremljeni Docker spremnici s raspoređenim funkcijskim kodom. Sustav prima vanjske zahtjeve i za svaki od njih okvir bez poslužitelja podiže mali spremnik s kodom: obrađuje taj zahtjev i ubija spremnik.
Jedan zahtjev - jedan podignut kontejner, 1000 zahtjeva - 1000 kontejnera. A implementacija na hardverskim poslužiteljima već je posao pružatelja usluga oblaka. Potpuno je skriven okvirom bez poslužitelja. U ovom konceptu plaćamo svaki poziv. Na primjer, jedan poziv je došao dnevno - platili smo jedan poziv, milijun je došao po minuti - platili smo milijun. Ili u sekundi, dogodi se i ovo.
Koncept objavljivanja funkcije bez poslužitelja prikladan je za uslugu bez stanja. A ako vam je potrebna (državna) usluga s punim stanjem, tada usluzi dodajemo bazu podataka. U ovom slučaju, kada se radi o radu sa stanjem, svaka funkcija puna stanja jednostavno piše i čita iz baze podataka. Štoviše, iz baze podataka bilo koje od tri vrste opisane na početku članka.
Koje je zajedničko ograničenje svih ovih baza podataka? To su troškovi konstantno korištenog oblaka ili hardverskog poslužitelja (ili više poslužitelja). Bez obzira koristimo li klasičnu ili upravljanu bazu podataka, imamo li Devops i admina ili ne, svejedno plaćamo hardver, struju i najam data centra 24/7. Ako imamo klasičnu bazu, plaćamo master i slave. Ako se radi o visoko opterećenoj razdijeljenoj bazi podataka, plaćamo 10, 20 ili 30 poslužitelja i stalno plaćamo.
Prisutnost trajno rezerviranih servera u strukturi troškova ranije se doživljavala kao nužno zlo. Konvencionalne baze podataka također imaju druge poteškoće, kao što su ograničenja broja veza, ograničenja skaliranja, geo-distribuirani konsenzus - oni se nekako mogu riješiti u određenim bazama podataka, ali ne sve odjednom i nije idealno.
Baza podataka bez poslužitelja – teorija
Pitanje 2020.: je li moguće napraviti i bazu podataka bez poslužitelja? Svi su čuli za backend bez poslužitelja... pokušajmo bazu podataka učiniti bez poslužitelja?
Ovo zvuči čudno, jer je baza podataka usluga s punim stanjem, nije baš prikladna za infrastrukturu bez poslužitelja. Pritom je stanje baze podataka vrlo veliko: gigabajti, terabajti, au analitičkim bazama čak i petabajti. Nije ga lako uzgajati u laganim Docker spremnicima.
S druge strane, gotovo sve moderne baze podataka sadrže ogromnu količinu logike i komponenti: transakcije, koordinaciju integriteta, procedure, relacijske ovisnosti i puno logike. Za dosta logike baze podataka dovoljno je malo stanje. Gigabajte i terabajte izravno koristi samo mali dio logike baze podataka koji je uključen u izravno izvršavanje upita.
Sukladno tome, ideja je: ako dio logike dopušta izvršavanje bez stanja, zašto ne podijeliti bazu na dijelove s stanjem i bez stanja.
Bez poslužitelja za OLAP rješenja
Pogledajmo kako bi rezanje baze podataka na dijelove s statusom i bez stanja moglo izgledati koristeći praktične primjere.
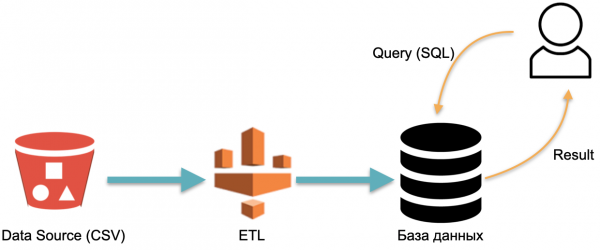
Na primjer, imamo analitičku bazu podataka: vanjski podaci (crveni cilindar lijevo), ETL proces koji učitava podatke u bazu podataka i analitičar koji šalje SQL upite bazi podataka. Ovo je klasična shema rada skladišta podataka.
U ovoj se shemi ETL uvjetno izvodi jednom. Zatim treba stalno plaćati servere na kojima radi baza s podacima punjenim ETL-om, kako bi se imalo čemu slati upite.
Pogledajmo alternativni pristup implementiran u AWS Athena Serverless. Ne postoji trajno namjenski hardver na kojem se pohranjuju preuzeti podaci. Umjesto ovoga:
- Korisnik šalje SQL upit Atheni. Athena optimizator analizira SQL upit i pretražuje pohranu metapodataka (Metapodaci) za specifične podatke potrebne za izvršenje upita.
- Optimizator na temelju prikupljenih podataka preuzima potrebne podatke iz vanjskih izvora u privremenu pohranu (privremenu bazu podataka).
- SQL upit korisnika izvršava se u privremenoj pohrani i rezultat se vraća korisniku.
- Privremena pohrana se briše i resursi se oslobađaju.
U ovoj arhitekturi plaćamo samo proces izvršenja zahtjeva. Nema zahtjeva - nema troškova.
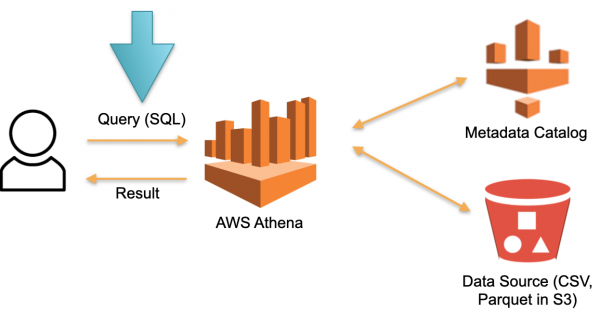
Ovo je radni pristup i implementiran je ne samo u Athena Serverless, već i u Redshift Spectrum (u AWS).
Primjer Athene pokazuje da baza podataka bez poslužitelja radi na stvarnim upitima s desecima i stotinama terabajta podataka. Stotine terabajta će zahtijevati stotine poslužitelja, ali mi ne moramo platiti za njih - mi plaćamo za zahtjeve. Brzina svakog zahtjeva je (jako) niska u usporedbi sa specijaliziranim analitičkim bazama podataka poput Vertice, ali ne plaćamo razdoblja zastoja.
Takva baza podataka primjenjiva je za rijetke analitičke ad-hoc upite. Na primjer, kada spontano odlučimo testirati hipotezu na nekoj golemoj količini podataka. Athena je savršena za ove slučajeve. Za redovite zahtjeve takav sustav je skup. U tom slučaju predmemorirajte podatke u neko specijalizirano rješenje.
Bez poslužitelja za OLTP rješenja
Prethodni primjer se bavio OLAP (analitičkim) zadacima. Sada pogledajmo OLTP zadatke.
Zamislimo skalabilni PostgreSQL ili MySQL. Podignimo regularnu upravljanu instancu PostgreSQL ili MySQL s minimalnim resursima. Kada instanca dobije veće opterećenje, spojit ćemo dodatne replike na koje ćemo rasporediti dio opterećenja čitanja. Ako nema zahtjeva ili učitavanja, isključujemo replike. Prvi primjerak je master, a ostalo su replike.
Ova ideja implementirana je u bazi podataka pod nazivom Aurora Serverless AWS. Princip je jednostavan: zahtjeve iz vanjskih aplikacija prihvaća proxy flota. Vidjevši povećanje opterećenja, dodjeljuje računalne resurse iz prethodno zagrijanih minimalnih instanci - veza se uspostavlja što je brže moguće. Onemogućavanje instanci događa se na isti način.
Unutar Aurore postoji koncept Aurora Capacity Unit, ACU. Ovo je (uvjetno) instanca (server). Svaki specifični ACU može biti glavni ili podređeni. Svaka jedinica kapaciteta ima vlastiti RAM, procesor i minimalni disk. Prema tome, jedan je master, ostali su replike samo za čitanje.
Broj ovih aktivnih Aurora jedinica kapaciteta je parametar koji se može konfigurirati. Minimalna količina može biti jedan ili nula (u ovom slučaju baza podataka ne radi ako nema zahtjeva).
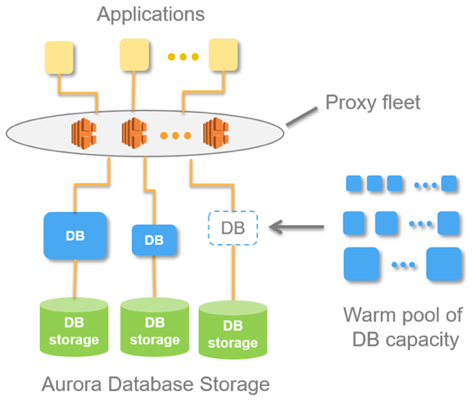
Kada baza primi zahtjeve, proxy flota podiže Aurora CapacityUnits, povećavajući resurse performansi sustava. Sposobnost povećanja i smanjenja resursa omogućuje sustavu "žongliranje" resursima: automatski prikazuje pojedinačne ACU-ove (zamjenjujući ih novima) i uvodi sva trenutna ažuriranja povučenih resursa.
Baza Aurora Serverless može skalirati opterećenje čitanja. Ali dokumentacija to ne govori izravno. Može se činiti kao da mogu podići multi-majstora. Nema magije.
Ova baza podataka dobro je prilagođena za izbjegavanje trošenja ogromnih količina novca na sustave s nepredvidivim pristupom. Na primjer, kada stvaramo MVP ili marketinške stranice s posjetnicama, obično ne očekujemo stabilno opterećenje. Sukladno tome, ako nema pristupa, ne plaćamo instance. Kada dođe do neočekivanog opterećenja, na primjer nakon konferencije ili reklamne kampanje, mnoštvo ljudi posjeti stranicu i opterećenje se dramatično poveća, Aurora Serverless automatski preuzima ovo opterećenje i brzo povezuje resurse koji nedostaju (ACU). Onda konferencija prođe, svi zaborave na prototip, serveri (ACU) se zatamne, a troškovi padnu na nulu - zgodno.
Ovo rješenje nije prikladno za stabilno visoko opterećenje jer ne skalira opterećenje pisanja. Sva ta povezivanja i odspajanja resursa događaju se na takozvanoj "točki skale" - točki u vremenu kada baza podataka nije podržana transakcijom ili privremenim tablicama. Na primjer, u roku od tjedan dana točka ljestvice se možda neće dogoditi, a baza radi na istim resursima i jednostavno se ne može proširiti ili smanjiti.
Nema magije - to je obični PostgreSQL. Ali proces dodavanja strojeva i njihovog isključivanja djelomično je automatiziran.
Bez poslužitelja po dizajnu
Aurora Serverless je stara baza podataka prerađena za oblak kako bi se iskoristile neke od prednosti Serverless. A sada ću vam reći o bazi, koja je izvorno napisana za oblak, za pristup bez poslužitelja - Serverless-by-design. Odmah je razvijen bez pretpostavke da će raditi na fizičkim poslužiteljima.
Ova baza se zove Snježna pahuljica. Ima tri ključna bloka.
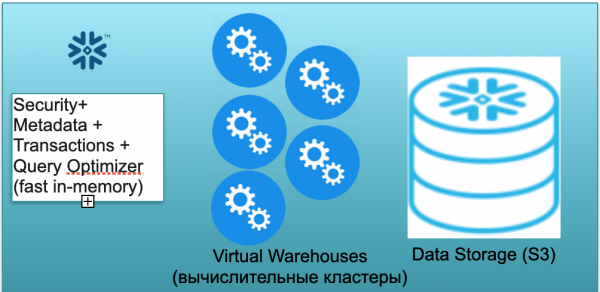
Prvi je blok metapodataka. Ovo je brza usluga u memoriji koja rješava probleme sa sigurnošću, metapodacima, transakcijama i optimizacijom upita (prikazano na ilustraciji lijevo).
Drugi blok je skup virtualnih računalnih klastera za izračune (na slici je skup plavih krugova).
Treći blok je sustav za pohranu podataka temeljen na S3. S3 je pohrana objekata bez dimenzija u AWS-u, nešto poput Dropboxa bez dimenzija za poslovanje.
Pogledajmo kako Snowflake radi, pod pretpostavkom hladnog starta. Odnosno, postoji baza podataka, podaci se učitavaju u nju, nema pokrenutih upita. Sukladno tome, ako nema zahtjeva prema bazi podataka, podigli smo uslugu brzih metapodataka u memoriji (prvi blok). I imamo S3 pohranu, gdje se pohranjuju tablični podaci, podijeljeni na takozvane mikroparticije. Radi jednostavnosti: ako tablica sadrži transakcije, tada su mikroparticije dani transakcija. Svaki dan je posebna mikroparticija, zasebna datoteka. A kada baza podataka radi u ovom načinu rada, plaćate samo za prostor koji zauzimaju podaci. Štoviše, stopa po sjedalu je vrlo niska (posebno uzimajući u obzir značajnu kompresiju). Usluga metapodataka također radi stalno, ali ne trebate puno resursa za optimizaciju upita, a usluga se može smatrati sharewareom.
Sada zamislimo da je korisnik došao do naše baze podataka i poslao SQL upit. SQL upit se odmah šalje Metadata servisu na obradu. Sukladno tome, po primitku zahtjeva, ovaj servis analizira zahtjev, dostupne podatke, korisnička dopuštenja i, ako je sve u redu, izrađuje plan obrade zahtjeva.
Zatim, usluga pokreće pokretanje računalnog klastera. Računalni klaster je klaster poslužitelja koji izvode izračune. Odnosno, ovo je klaster koji može sadržavati 1 poslužitelj, 2 poslužitelja, 4, 8, 16, 32 - koliko god želite. Bacite zahtjev i pokretanje ovog klastera odmah počinje. Zaista su potrebne sekunde.
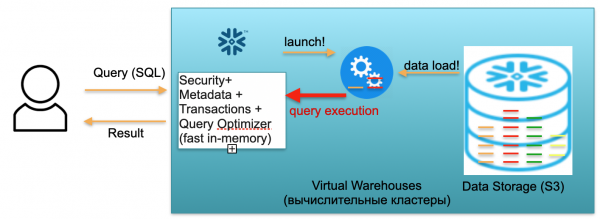
Zatim, nakon pokretanja klastera, mikroparticije potrebne za obradu vašeg zahtjeva počinju se kopirati u klaster sa S3. To jest, zamislimo da su vam za izvršavanje SQL upita potrebne dvije particije iz jedne tablice i jedna iz druge. U tom će slučaju samo tri potrebne particije biti kopirane u klaster, a ne sve tablice u cijelosti. Zbog toga, i upravo zato što je sve smješteno unutar jednog podatkovnog centra i povezano vrlo brzim kanalima, cijeli proces prijenosa odvija se vrlo brzo: u sekundama, vrlo rijetko u minutama, osim ako nije riječ o nekim monstruoznim zahtjevima. Sukladno tome, mikroparticije se kopiraju u računalni klaster, a po završetku, SQL upit se izvršava na ovom računalnom klasteru. Rezultat ovog zahtjeva može biti jedan redak, više redaka ili tablica – šalju se eksterno korisniku kako bi ga on preuzeo, prikazao u svom BI alatu ili upotrijebio na neki drugi način.
Svaki SQL upit ne samo da može čitati agregate iz prethodno učitanih podataka, već i učitati/generirati nove podatke u bazi podataka. Odnosno, to može biti upit koji, na primjer, umeće nove zapise u drugu tablicu, što dovodi do pojave nove particije na računalnom klasteru, koja se zauzvrat automatski sprema u jednu S3 pohranu.
Gore opisani scenarij, od dolaska korisnika do podizanja klastera, učitavanja podataka, izvršavanja upita, dobivanja rezultata, plaća se po tarifi za minute korištenja podignutog virtualnog računalnog klastera, virtualnog skladišta. Stopa varira ovisno o AWS zoni i veličini klastera, ali u prosjeku iznosi nekoliko dolara po satu. Klaster od četiri stroja dvostruko je skuplji od klastera od dva stroja, a klaster od osam strojeva i dalje je dvostruko skuplji. Dostupne su opcije od 16, 32 stroja, ovisno o složenosti zahtjeva. Ali plaćate samo one minute kada klaster stvarno radi, jer kada nema zahtjeva, kao da dignete ruke, a nakon 5-10 minuta čekanja (parametar koji se može konfigurirati) ugasit će se sam od sebe, oslobodite resurse i postanite slobodni.
Potpuno realan scenarij je kad pošaljete zahtjev, klaster vam iskoči, relativno rečeno, za minutu, odbrojava još jednu minutu, pa pet minuta da se ugasi, i na kraju platite sedam minuta rada tog klastera i ne mjesecima i godinama.
Prvi scenarij opisan korištenjem Snowflake u postavci za jednog korisnika. Sada zamislimo da postoji mnogo korisnika, što je bliže stvarnom scenariju.
Recimo da imamo puno analitičara i Tableau izvješća koja neprestano bombardiraju našu bazu podataka velikim brojem jednostavnih analitičkih SQL upita.
Uz to, recimo da imamo inventivne Data Scientiste koji pokušavaju raditi monstruozne stvari s podacima, operiraju s desecima terabajta, analiziraju milijarde i trilijune redaka podataka.
Za dvije gore opisane vrste radnog opterećenja, Snowflake vam omogućuje podizanje nekoliko neovisnih računalnih klastera različitih kapaciteta. Štoviše, ovi računalni klasteri rade neovisno, ali sa zajedničkim dosljednim podacima.
Za veliki broj lakih upita, možete podići 2-3 mala klastera, otprilike 2 stroja svaki. Ovo se ponašanje može implementirati, između ostalog, pomoću automatskih postavki. Pa kažete: “Pahuljice, podigni mali grozd. Ako se opterećenje na njemu poveća iznad određenog parametra, podignite sličan drugi, treći. Kad opterećenje počne popuštati, ugasite višak.” Tako da koliko god analitičara dođe i počne gledati izvješća, svi imaju dovoljno resursa.
U isto vrijeme, ako analitičari spavaju i nitko ne gleda izvješća, klasteri mogu potpuno potamniti, a vi prestanete plaćati za njih.
U isto vrijeme, za teške upite (od Data Scientists), možete podići jedan vrlo veliki klaster za 32 stroja. Ovaj će klaster također biti plaćen samo za one minute i sate kada se tamo izvodi vaš ogromni zahtjev.
Gore opisana mogućnost vam omogućuje da podijelite ne samo 2, već i više vrsta radnog opterećenja u klastere (ETL, praćenje, materijalizacija izvješća,...).
Rezimirajmo Pahuljicu. Baza spaja prekrasnu ideju i izvedivu provedbu. U ManyChatu koristimo Snowflake za analizu svih podataka koje imamo. Nemamo tri klastera, kao u primjeru, već od 5 do 9, različitih veličina. Imamo konvencionalne 16-stroja, 2-stroja, kao i super-male 1-stroja za neke zadatke. Uspješno raspoređuju teret i omogućuju nam veliku uštedu.
Baza podataka uspješno skalira opterećenje čitanja i pisanja. Ovo je velika razlika i veliki napredak u usporedbi s istom "Aurorom", koja je nosila samo opterećenje čitanja. Snowflake vam omogućuje skaliranje radnog opterećenja pisanja pomoću ovih računalnih klastera. Odnosno, kao što sam spomenuo, koristimo nekoliko klastera u ManyChatu, mali i super-mali klasteri se uglavnom koriste za ETL, za učitavanje podataka. A analitičari već žive na srednjim klasterima, na koje ETL opterećenje apsolutno ne utječe, tako da rade vrlo brzo.
Sukladno tome, baza podataka je vrlo prikladna za OLAP zadatke. Međutim, nažalost, još nije primjenjivo za radna opterećenja OLTP-a. Prvo, ova baza je stupčasta, sa svim posljedicama koje iz toga proizlaze. Drugo, sam pristup, kada za svaki zahtjev, po potrebi, dižete računalni klaster i zatrpavate ga podacima, nažalost, još nije dovoljno brz za OLTP opterećenja. Sekunde čekanja za OLAP zadatke su normalne, ali za OLTP zadatke su neprihvatljive, bolje bi bilo 100 ms ili još bolje 10 ms.
Ukupan
Baza podataka bez poslužitelja moguća je dijeljenjem baze podataka na dijelove bez stanja i stanja. Možda ste primijetili da u svim gornjim primjerima Stateful dio, relativno govoreći, pohranjuje mikro particije u S3, a Stateless je optimizator koji radi s metapodacima, rješava sigurnosne probleme koji se mogu pokrenuti kao neovisne lagane Stateless usluge.
Izvršavanje SQL upita također se može percipirati kao usluge laganog stanja koje se mogu pojaviti u načinu rada bez poslužitelja, poput računalnih klastera Snowflake, preuzeti samo potrebne podatke, izvršiti upit i "izaći".
Baze podataka proizvodne razine bez poslužitelja već su dostupne za korištenje, rade. Ove baze podataka bez poslužitelja već su spremne za rukovanje OLAP zadacima. Nažalost, za OLTP zadatke koriste se... s nijansama, budući da postoje ograničenja. S jedne strane, ovo je minus. Ali, s druge strane, ovo je prilika. Možda će netko od čitatelja pronaći način kako napraviti OLTP bazu podataka potpuno bez poslužitelja, bez ograničenja Aurore.
Nadam se da vam je bilo zanimljivo. Bez servera je budućnost :)
Izvor: www.habr.com
