

1. Početni podaci
Čišćenje podataka jedan je od izazova s kojima se suočavaju zadaci analize podataka. Ovaj materijal je odražavao razvoj i rješenja koja su nastala kao rezultat rješavanja praktičnog problema analize baze podataka u formiranju katastarske vrijednosti. Izvori ovdje .
Razmatran je fajl “Usporedni model total.ods” u “Prilogu B. Rezultati utvrđivanja KS 5. Podaci o načinu utvrđivanja katastarske vrijednosti 5.1 Komparativni pristup”.
Tablica 1. Statistički pokazatelji skupa podataka u datoteci “Usporedni model total.ods”
Ukupan broj polja, kom. — 44
Ukupan broj zapisa, kom. — 365 490
Ukupan broj znakova, kom. — 101 714 693
Prosječan broj znakova u zapisu, kom. — 278,297
Standardna devijacija znakova u zapisu, kom. — 15,510
Minimalan broj znakova u unosu, kom. — 198
Maksimalan broj znakova u unosu, kom. — 363
2. Uvodni dio. Osnovni standardi
Pri analizi navedene baze formiran je zadatak preciziranja zahtjeva za stupanj pročišćavanja, budući da, kao što je svima jasno, navedena baza stvara pravne i ekonomske posljedice za korisnike. Tijekom rada pokazalo se da ne postoje posebni zahtjevi za stupanj čišćenja velikih podataka. Analizirajući pravne norme u ovoj materiji, došao sam do zaključka da su sve one nastale iz mogućnosti. Odnosno, pojavio se određeni zadatak, sastavljaju se izvori informacija za zadatak, zatim se formira skup podataka i na temelju stvorenog skupa podataka alati za rješavanje problema. Dobivena rješenja su referentne točke u odabiru alternativa. To sam prikazao na slici 1.
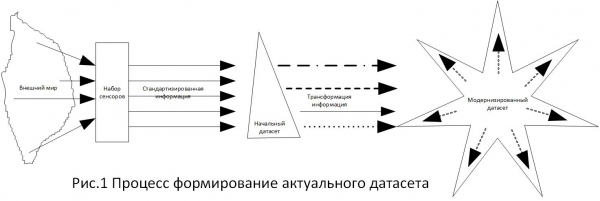
Budući da je u pitanjima određivanja bilo kojih standarda poželjno oslanjati se na provjerene tehnologije, odabrao sam zahtjeve navedene u , jer sam ovaj dokument smatrao najopsežnijim za ovu problematiku. Konkretno, u ovom dokumentu odjeljak kaže "Treba napomenuti da se zahtjevi za integritetom podataka jednako primjenjuju na ručne (papirnate) i elektroničke podatke." (prijevod: “...zahtjevi za cjelovitost podataka jednako se primjenjuju na ručne (papirnate) i elektroničke podatke”). Ova se formulacija sasvim specifično povezuje s pojmom „pisani dokaz“, u odredbama čl. 71. Zakona o parničnom postupku, čl. 70. CAS, čl. 75. ZKP-a, „pismeno” čl. 84 Zakon o parničnom postupku.
Slika 2. prikazuje dijagram formiranja pristupa vrstama informacija u pravosuđu.
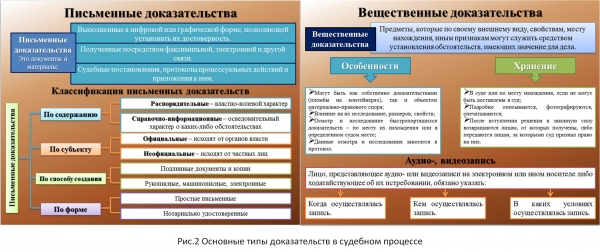
Riža. 2. Izvor .
Slika 3 prikazuje mehanizam sa Slike 1, za zadatke iz gornjeg "Uputstva". Lako je, usporedbom, vidjeti da su pristupi koji se koriste pri ispunjavanju zahtjeva za cjelovitošću informacija u suvremenim standardima za informacijske sustave značajno ograničeni u usporedbi s pravnim pojmom informacija.
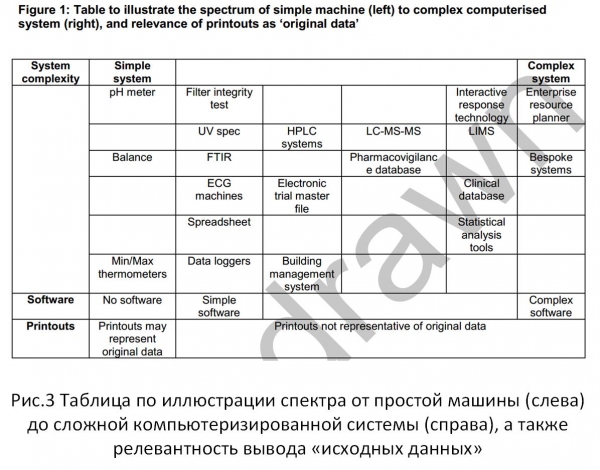
Sl. 3
U navedenom dokumentu (Guidance) veza s tehničkim dijelom, mogućnostima obrade i pohrane podataka, dobro je potvrđena citatom iz poglavlja 18.2. Relacijska baza podataka: "Ova je struktura datoteke sama po sebi sigurnija jer se podaci čuvaju u velikom formatu datoteke koji čuva odnos između podataka i metapodataka."
Zapravo, u ovom pristupu - od postojećih tehničkih mogućnosti, nema ničeg nenormalnog i, sam po sebi, to je prirodan proces, budući da širenje pojmova dolazi iz najproučavanije aktivnosti - dizajna baze podataka. Ali, s druge strane, pojavljuju se zakonske norme koje ne daju popuste na tehničke mogućnosti postojećih sustava, na primjer: .

Riža. 4. Lijevak tehničkih mogućnosti ().
U tim aspektima postaje jasno da će izvorni skup podataka (Sl. 1) morati, prije svega, biti spremljen, a kao drugo, biti osnova za izdvajanje dodatnih informacija iz njega. Pa, na primjer: kamere koje snimaju prometna pravila su sveprisutne, sustavi za obradu informacija eliminiraju prekršitelje, ali i druge informacije mogu se ponuditi drugim potrošačima, primjerice, kao marketinško praćenje strukture protoka kupaca u trgovački centar. A to je izvor dodatne dodane vrijednosti kada koristite BigDat. Sasvim je moguće da će skupovi podataka koji se sada prikupljaju, negdje u budućnosti, imati vrijednost prema mehanizmu sličnom vrijednosti rijetkih izdanja iz 1700. u današnje vrijeme. Uostalom, zapravo su privremeni skupovi podataka jedinstveni i malo je vjerojatno da će se ponoviti u budućnosti.
3. Uvodni dio. Kriteriji evaluacije
Tijekom procesa obrade razvijena je sljedeća klasifikacija pogrešaka.
1. Klasa pogreške (na temelju GOST R 8.736-2011): a) sustavne pogreške; b) slučajne pogreške; c) greška.
2. Po mnogostrukosti: a) mono izobličenje; b) višestruka distorzija.
3. Prema kritičnosti posljedica: a) kritične; b) nije kritično.
4. Prema izvoru nastanka:
A) Tehničke – greške koje se javljaju tijekom rada opreme. Prilično relevantna greška za IoT sustave, sustave sa značajnim stupnjem utjecaja na kvalitetu komunikacije, opremu (hardver).
B) Operatorske pogreške - pogreške u širokom rasponu od operatorskih tipfelera tijekom unosa do pogrešaka u tehničkim specifikacijama za dizajn baze podataka.
C) Pogreške korisnika - ovdje su pogreške korisnika u cijelom rasponu od "zaboravio sam promijeniti izgled" do pogrešnog mijenjanja metara za stope.
5. Izdvojeni u zasebnu klasu:
a) “zadatak separatora”, odnosno razmak i “:” (u našem slučaju) kada je umnožen;
b) riječi napisane zajedno;
c) bez razmaka iza službenih znakova
d) simetrično više simbola: (), "", "...".
Uzevši zajedno, sa sistematizacijom pogrešaka baze podataka prikazanom na slici 5, formiran je prilično učinkovit koordinatni sustav za traženje pogrešaka i razvoj algoritma za čišćenje podataka za ovaj primjer.
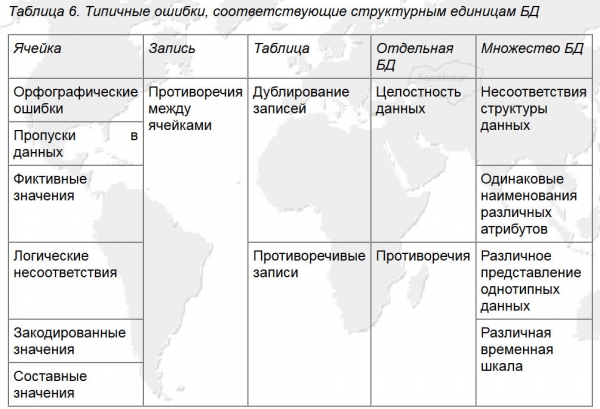
Riža. 5. Tipične pogreške koje odgovaraju strukturnim jedinicama baze podataka (Izvor: ).
Točnost, Integritet domene, Vrsta podataka, Dosljednost, Redundancija, Cjelovitost, Umnožavanje, Usklađenost s poslovnim pravilima, Strukturna određenost, Anomalija podataka, Jasnoća, Pravovremenost, Pridržavanje pravila o integritetu podataka. (Stranica 334. Osnove skladištenja podataka za IT profesionalce / Paulraj Ponniah.—2. izdanje.)
Predstavljen engleski tekst i ruski strojni prijevod u zagradama.
Točnost. Vrijednost pohranjena u sustavu za podatkovni element je prava vrijednost za to pojavljivanje podatkovnog elementa. Ako imate ime kupca i adresu pohranjenu u zapisu, tada je adresa točna adresa za kupca s tim imenom. Ako pronađete naručenu količinu kao 1000 jedinica u zapisu za broj narudžbe 12345678, tada je ta količina točna količina za tu narudžbu.
[Točnost. Vrijednost pohranjena u sustavu za podatkovni element ispravna je vrijednost za tu pojavu podatkovnog elementa. Ako imate ime kupca i adresu pohranjenu u zapisu, tada je adresa točna adresa za kupca s tim imenom. Ako pronađete naručenu količinu od 1000 jedinica u zapisu za broj narudžbe 12345678, tada je ta količina točna količina za tu narudžbu.]
Integritet domene. Podatkovna vrijednost atributa spada u raspon dopuštenih, definiranih vrijednosti. Uobičajen primjer su dopuštene vrijednosti "male" i "female" za element podataka o spolu.
[Cjelovitost domene. Vrijednost podataka atributa spada unutar raspona valjanih, definiranih vrijednosti. Opći primjer su važeće vrijednosti "male" i "female" za element podataka o spolu.]
Tip podataka. Vrijednost za atribut podataka zapravo je pohranjena kao vrsta podataka definirana za taj atribut. Kada je tip podataka polja naziva trgovine definiran kao "tekst", sve instance tog polja sadrže naziv trgovine prikazan u tekstualnom formatu, a ne numeričke kodove.
[Tip podataka. Vrijednost atributa podataka zapravo je pohranjena kao vrsta podataka definirana za taj atribut. Ako je tip podataka polja naziva trgovine definiran kao "tekst", sve instance ovog polja sadrže naziv trgovine prikazan u tekstualnom formatu, a ne numeričke kodove.]
Dosljednost. Oblik i sadržaj podatkovnog polja isti je u višestrukim izvornim sustavima. Ako je kod proizvoda za proizvod ABC u jednom sustavu 1234, tada je kod za ovaj proizvod 1234 u svakom izvornom sustavu.
[Dosljednost. Oblik i sadržaj podatkovnog polja isti su u različitim izvornim sustavima. Ako je šifra proizvoda za proizvod ABC na jednom sustavu 1234, tada je šifra za taj proizvod 1234 na svakom izvornom sustavu.]
Redundancija. Isti podaci ne smiju biti pohranjeni na više od jednog mjesta u sustavu. Ako je, zbog učinkovitosti, podatkovni element namjerno pohranjen na više od jednog mjesta u sustavu, tada se redundancija mora jasno identificirati i provjeriti.
[Redundantnost. Isti podaci ne smiju biti pohranjeni na više od jednog mjesta u sustavu. Ako je, zbog učinkovitosti, podatkovni element namjerno pohranjen na više lokacija u sustavu, tada se redundancija mora jasno definirati i provjeriti.]
Potpunost. Ne postoje vrijednosti koje nedostaju za određeni atribut u sustavu. Na primjer, u datoteci kupca mora postojati valjana vrijednost za polje "stanje" za svakog kupca. U datoteci s detaljima narudžbe svaki detaljni zapis za narudžbu mora biti u potpunosti ispunjen.
[Potpunost. Nema nedostajućih vrijednosti u sustavu za ovaj atribut. Na primjer, datoteka klijenta mora imati valjanu vrijednost za polje "status" za svakog klijenta. U datoteci s detaljima narudžbe svaki zapis s detaljima narudžbe mora biti u potpunosti ispunjen.]
Dupliciranje. Umnožavanje zapisa u sustavu je u potpunosti riješeno. Ako je poznato da datoteka proizvoda ima dvostruke zapise, identificiraju se svi dvostruki zapisi za svaki proizvod i stvara se unakrsna referenca.
[Duplikat. Umnožavanje zapisa u sustavu je u potpunosti eliminirano. Ako se zna da datoteka proizvoda sadrži dvostruke unose, identificiraju se svi dvostruki unosi za svaki proizvod i stvara se unakrsna referenca.]
Usklađenost s poslovnim pravilima. Vrijednosti svake podatkovne stavke pridržavaju se propisanih poslovnih pravila. U dražbenom sustavu cijena čekića ili prodajna cijena ne može biti niža od rezervne cijene. U sustavu bankovnih kredita stanje kredita uvijek mora biti pozitivno ili nula.
[Poštivanje pravila poslovanja. Vrijednosti svakog elementa podataka u skladu su s utvrđenim poslovnim pravilima. U dražbenom sustavu cijena čekića ili prodajna cijena ne može biti niža od rezervne cijene. U bankovnom kreditnom sustavu stanje kredita uvijek mora biti pozitivno ili nula.]
Strukturna određenost. Gdje god se podatkovna stavka može prirodno strukturirati u pojedinačne komponente, stavka mora sadržavati ovu dobro definiranu strukturu. Na primjer, ime pojedinca prirodno se dijeli na ime, srednje slovo i prezime. Vrijednosti za imena pojedinaca moraju biti pohranjene kao ime, srednje slovo i prezime. Ova karakteristika kvalitete podataka pojednostavljuje provedbu standarda i smanjuje nedostajuće vrijednosti.
[Strukturalna sigurnost. Tamo gdje se podatkovni element može prirodno strukturirati u pojedinačne komponente, element mora sadržavati ovu dobro definiranu strukturu. Na primjer, ime osobe prirodno se dijeli na ime, srednje slovo i prezime. Vrijednosti za pojedinačna imena trebaju biti pohranjene kao ime, srednje slovo i prezime. Ova karakteristika kvalitete podataka pojednostavljuje primjenu standarda i smanjuje vrijednosti koje nedostaju.]
Anomalija podataka. Polje se mora koristiti samo u svrhu za koju je definirano. Ako je polje Adresa-3 definirano za bilo koji mogući treći red adrese za duge adrese, tada se ovo polje mora koristiti samo za zapis trećeg retka adrese. Ne smije se koristiti za unos broja telefona ili faksa kupca.
[Anomalija podataka. Polje se smije koristiti samo u svrhu za koju je definirano. Ako je polje Adresa-3 definirano za bilo koju moguću treću adresnu liniju za duge adrese, tada će se ovo polje koristiti samo za bilježenje treće adresne linije. Ne smije se koristiti za unos broja telefona ili faksa kupca.]
Jasnoća. Podatkovni element može posjedovati sve ostale karakteristike kvalitetnih podataka, ali ako korisnici ne razumiju jasno njegovo značenje, tada podatkovni element za korisnike nema nikakvu vrijednost. Ispravne konvencije imenovanja pomažu da korisnici dobro razumiju elemente podataka.
[Jasnoća. Element podataka može imati sve druge karakteristike dobrih podataka, ali ako korisnici jasno ne razumiju njegovo značenje, tada element podataka nema nikakvu vrijednost za korisnike. Ispravne konvencije imenovanja pomažu da korisnici dobro razumiju elemente podataka.]
Pravovremeno. Korisnici određuju pravodobnost podataka. Ako korisnici očekuju da podaci o dimenziji kupaca ne budu stariji od jednog dana, promjene podataka o korisnicima u izvornim sustavima moraju se svakodnevno primjenjivati na skladište podataka.
[Pravovremeno. Korisnici određuju pravodobnost podataka. Ako korisnici očekuju da podaci o dimenziji kupaca nisu stariji od jednog dana, promjene podataka o korisnicima u izvornim sustavima trebaju se primjenjivati na skladište podataka na dnevnoj bazi.]
Korisnost. Svaki podatkovni element u skladištu podataka mora zadovoljiti neke zahtjeve zbirke korisnika. Podatkovni element može biti točan i kvalitetan, ali ako nema nikakvu vrijednost za korisnike, onda je potpuno nepotrebno da se taj podatkovni element nalazi u skladištu podataka.
[Korisnost. Svaka podatkovna stavka u pohrani podataka mora zadovoljiti neke zahtjeve korisničke zbirke. Podatkovni element može biti točan i visoke kvalitete, ali ako ne pruža vrijednost korisnicima, tada nije nužno da taj podatkovni element bude u skladištu podataka.]
Pridržavanje pravila o integritetu podataka. Podaci pohranjeni u relacijskim bazama podataka izvornih sustava moraju se pridržavati pravila integriteta entiteta i referentnog integriteta. Bilo koja tablica koja dopušta null kao primarni ključ nema integritet entiteta. Referentni integritet prisiljava na ispravno uspostavljanje odnosa roditelj-dijete. U odnosu kupac-narudžba, referentni integritet osigurava postojanje kupca za svaku narudžbu u bazi podataka.
[Poštivanje pravila o integritetu podataka. Podaci pohranjeni u relacijskim bazama podataka izvornih sustava moraju biti u skladu s pravilima integriteta entiteta i referentnog integriteta. Bilo koja tablica koja dopušta null kao primarni ključ nema integritet entiteta. Referentni integritet prisiljava da se odnos između roditelja i djece uspostavi ispravno. U odnosu kupac-narudžba, referentni integritet osigurava da kupac postoji za svaku narudžbu u bazi podataka.]
4. Kvaliteta čišćenja podataka
Kvaliteta čišćenja podataka prilično je problematično pitanje u bigdata. Odgovor na pitanje koji je stupanj čišćenja podataka potreban za dovršenje zadatka temeljan je za svakog analitičara podataka. Kod većine aktualnih problema svaki analitičar to sam utvrđuje i malo je vjerojatno da itko izvana može procijeniti taj aspekt u svom rješenju. Ali za zadatak koji je u ovom slučaju bio pri ruci, ovo je pitanje bilo izuzetno važno, budući da bi pouzdanost pravnih podataka trebala težiti jednom.
Razmatranje tehnologija testiranja softvera za određivanje operativne pouzdanosti. Danas postoji više od ovih modela . Mnogi modeli koriste model servisiranja zahtjeva:
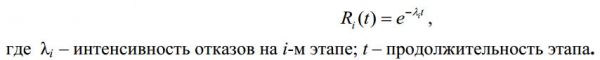
Slika. 6
Razmišljajući na sljedeći način: "Ako je pronađena pogreška događaj sličan događaju kvara u ovom modelu, kako onda pronaći analogiju parametra t?" I sastavio sam sljedeći model: Zamislimo da je vrijeme koje je testeru potrebno da provjeri jedan zapis 1 minuta (za dotičnu bazu podataka), a zatim će mu trebati 365 494 minute da pronađe sve greške, što je otprilike 3 godine i 3 mjeseci radnog vremena. Koliko razumijemo, ovo je vrlo velika količina posla i troškovi provjere baze podataka bit će previsoki za sastavljača ove baze podataka. U tom promišljanju pojavljuje se ekonomski koncept troškova i nakon analize došao sam do zaključka da je to prilično učinkovit alat. Na temelju zakona ekonomije: “Opseg proizvodnje (u jedinicama) pri kojem se postiže maksimalni profit poduzeća nalazi se u točki gdje se granični trošak proizvodnje nove jedinice outputa uspoređuje s cijenom koju to poduzeće može primiti za novu jedinicu.” Na temelju postulata da pronalaženje svake sljedeće pogreške zahtijeva sve više i više provjere zapisa, ovo je trošak. To jest, postulat usvojen u modelima testiranja poprima fizičko značenje u sljedećem obrascu: ako je za pronalaženje i-te pogreške bilo potrebno provjeriti n zapisa, tada će za pronalaženje sljedeće (i+1) pogreške biti potrebno provjeriti m zapisa i ujedno n
- Kada se broj zapisa provjerenih prije pronalaska nove pogreške stabilizira;
- Kada se poveća broj zapisa koji se provjeravaju prije pronalaska sljedeće pogreške.
Kako bih odredio kritičnu vrijednost, okrenuo sam se konceptu ekonomske izvedivosti, koji se u ovom slučaju, koristeći koncept društvenih troškova, može formulirati na sljedeći način: „Troškove ispravljanja pogreške trebao bi snositi ekonomski subjekt koji može učiniti po najnižoj cijeni.” Imamo jednog agenta - testera koji utroši 1 minutu na provjeru jednog zapisa. U novčanom smislu, ako zaradite 6000 rubalja dnevno, to će biti 12,2 rublje. (otprilike danas). Ostaje utvrditi drugu stranu ravnoteže u gospodarskom pravu. Rezonirao sam ovako. Postojeća pogreška će zahtijevati da se dotična osoba uloži u napor da je ispravi, odnosno vlasnik nekretnine. Recimo da ovo zahtijeva 1 dan radnje (podnesite zahtjev, primite ispravljeni dokument). Tada će mu, socijalno gledano, troškovi biti jednaki prosječnoj dnevnoj plaći. Prosječna obračunata plaća u autonomnom okrugu Khanty-Mansi 73285 rub. ili 3053,542 rublja/dan. Prema tome, dobivamo kritičnu vrijednost jednaku:
3053,542: 12,2 = 250,4 jedinica zapisa.
To znači, s društvenog gledišta, ako je tester provjerio 251 zapis i pronašao jednu pogrešku, to je jednako kao da je korisnik sam ispravio tu pogrešku. U skladu s tim, ako je ispitivač proveo vrijeme jednako provjeri 252 zapisa kako bi pronašao sljedeću pogrešku, tada je u ovom slučaju bolje prebaciti trošak ispravka na korisnika.
Ovdje je predstavljen pojednostavljeni pristup, budući da je sa socijalnog gledišta potrebno uzeti u obzir svu dodatnu vrijednost koju generira svaki stručnjak, odnosno troškove uključujući poreze i socijalna davanja, ali model je jasan. Posljedica tog odnosa je sljedeći uvjet za stručnjake: stručnjak iz IT industrije mora imati plaću veću od državnog prosjeka. Ako je njegova plaća manja od prosječne plaće potencijalnih korisnika baze podataka, onda on sam mora provjeriti cijelu bazu podataka iz ruke u ruku.
Pri korištenju opisanog kriterija postavlja se prvi zahtjev za kvalitetu baze podataka:
I(tr). Udio kritičnih pogrešaka ne bi trebao biti veći od 1/250,4 = 0,39938%. Nešto manje od zlato u industriji. A u fizičkom smislu nema više od 1459 zapisa s pogreškama.
Ekonomsko povlačenje.
Naime, tolikim brojem grešaka u evidenciji društvo pristaje na ekonomske gubitke u iznosu od:
1459*3053,542 = 4 455 118 rubalja.
Taj je iznos određen činjenicom da društvo nema alate za smanjenje tih troškova. Iz toga slijedi da ako netko ima tehnologiju koja mu omogućuje smanjenje broja zapisa s pogreškama na npr. 259, onda će to društvu omogućiti uštedu:
1200*3053,542 = 3 664 250 rubalja.
Ali u isto vrijeme, on može tražiti za svoj talent i rad, pa, recimo - 1 milijun rubalja.
Odnosno, društveni troškovi se smanjuju za:
3 664 250 – 1 000 000 = 2 664 250 rubalja.
U biti, ovaj učinak je dodana vrijednost od korištenja BigDat tehnologija.
Ali ovdje treba uzeti u obzir da se radi o društvenom učinku, a vlasnik baze podataka su općinske vlasti, njihov prihod od korištenja imovine evidentirane u ovoj bazi podataka, po stopi od 0,3%, iznosi: 2,778 milijardi rubalja/ godina. A ti troškovi (4 rubalja) ne smetaju mu mnogo, budući da se prenose na vlasnike imovine. I, u tom aspektu, programer više rafiniranih tehnologija u Bigdata morat će pokazati sposobnost da uvjeri vlasnika ove baze podataka, a takve stvari zahtijevaju znatan talent.
U ovom primjeru algoritam za procjenu pogreške odabran je na temelju Schumannova modela [2] verifikacije softvera tijekom testiranja pouzdanosti. Zbog rasprostranjenosti na internetu i mogućnosti dobivanja potrebnih statističkih pokazatelja. Metodologija je preuzeta od Monakhov Yu.M. “Funkcionalna stabilnost informacijskih sustava”, vidi ispod spojlera na sl. 7-9 (prikaz, ostalo).
Riža. 7 – 9 Metodologija Schumannova modela


Drugi dio ovog materijala predstavlja primjer čišćenja podataka, u kojem se dobivaju rezultati korištenja Schumannova modela.
Dopustite mi da predstavim dobivene rezultate:
Procijenjeni broj grešaka N = 3167 n.
Parametar C, lambda i funkcija pouzdanosti:
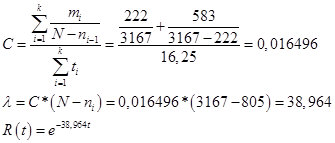
Sl. 17
U biti, lambda je stvarni pokazatelj intenziteta s kojim se pogreške otkrivaju u svakoj fazi. Ako pogledate drugi dio, procjena za ovaj pokazatelj bila je 42,4 pogreške po satu, što je sasvim usporedivo sa Schumannovim pokazateljem. Gore je utvrđeno da stopa kojom programer pronalazi pogreške ne smije biti niža od 1 pogreške na 250,4 zapisa, kada se provjerava 1 zapis u minuti. Otuda kritična vrijednost lambda za Schumannov model:
60 / 250,4 = 0,239617.
Odnosno, potrebno je provoditi postupke otkrivanja grešaka sve dok se lambda s postojećih 38,964 ne smanji na 0,239617.
Ili dok indikator N (potencijalni broj pogrešaka) minus n (ispravljeni broj pogrešaka) ne padne ispod našeg prihvaćenog praga - 1459 kom.
Književnost
- Monakhov, Yu. M. Funkcionalna stabilnost informacijskih sustava. U 3 sata.Dio 1. Pouzdanost softvera : udžbenik. dodatak / Yu. M. Monakhov; Vladim. država sveuč. – Vladimir: Izvo Vladim. država Sveučilište, 2011. – 60 str. – ISBN 978-5-9984-0189-3.
- Martin L. Shooman, “Probabilistički modeli za predviđanje pouzdanosti softvera.”
- Osnove skladištenja podataka za IT profesionalce / Paulraj Ponniah.—2. izdanje.
Izvor: www.habr.com
