

Prijevod članka pripremljen je posebno za studente kolegija .
razvija softver, Go fanatik i rješava probleme. Također je održavatelj Prometheusa i suosnivač Kubernetes SIG instrumentacije. U prošlosti je bio inženjer proizvodnje u SoundCloudu i vodio je tim za praćenje u CoreOS-u. Trenutno radi u Googleu.
- Inženjer infrastrukture u tvrtki Improbable. Zanimaju ga nove tehnologije i problemi distribuiranih sustava. Ima nisko iskustvo u programiranju u Intelu, iskustvo suradnika u Mesosu i prvoklasno iskustvo u proizvodnji SRE u tvrtki Improbable. Posvećen poboljšanju svijeta mikrousluga. Njegove tri ljubavi: Golang, open source i odbojka.
Gledajući naš vodeći proizvod SpatialOS, možete pretpostaviti da Improbable zahtijeva visoko dinamičnu infrastrukturu oblaka na globalnoj razini s desecima Kubernetes klastera. Bili smo jedni od prvih koji su koristili sustav nadzora . Prometheus je sposoban pratiti milijune metrika u stvarnom vremenu i dolazi s moćnim upitnim jezikom koji vam omogućuje izdvajanje informacija koje su vam potrebne.
Jednostavnost i pouzdanost Prometheusa jedna je od njegovih glavnih prednosti. Međutim, nakon što smo prešli određenu ljestvicu, naišli smo na nekoliko nedostataka. Za rješavanje ovih problema razvili smo je projekt otvorenog koda koji je stvorio Improbable kako bi se postojeće klastere Prometheus neprimjetno transformirale u jedinstveni sustav praćenja s neograničenom pohranom povijesnih podataka. Thanos je dostupan na Githubu .
Naši ciljevi s Thanosom
U određenoj mjeri pojavljuju se problemi koji nadilaze mogućnosti vanilla Prometheusa. Kako pouzdano i ekonomično pohraniti petabajte povijesnih podataka? Može li se to učiniti bez ugrožavanja vremena odgovora? Je li moguće pristupiti svim metrikama koje se nalaze na različitim Prometheus poslužiteljima s jednim API zahtjevom? Postoji li neki način za kombiniranje repliciranih podataka prikupljenih pomoću Prometheus HA?
Kako bismo riješili te probleme, stvorili smo Thanosa. Sljedeći odjeljci opisuju kako smo pristupili ovim problemima i objašnjavaju naše ciljeve.
Upit podataka iz više instanci Prometheusa (globalni upit)
Prometheus nudi funkcionalan pristup šardingu. Čak i jedan Prometheus poslužitelj pruža dovoljno skalabilnosti da oslobodi korisnike složenosti horizontalnog dijeljenja u gotovo svim slučajevima upotrebe.
Iako je ovo izvrstan model implementacije, često je potrebno pristupiti podacima na različitim Prometheus poslužiteljima putem jednog API-ja ili korisničkog sučelja - globalni prikaz. Naravno, moguće je prikazati više upita u jednom Grafana panelu, ali se svaki upit može izvršiti samo na jednom Prometheus poslužitelju. S druge strane, s Thanosom možete postavljati upite i agregirati podatke s više Prometheus poslužitelja jer su svi dostupni s jedne krajnje točke.
Prethodno smo, kako bismo dobili globalni prikaz u igrici Improbable, organizirali naše Prometheus instance u višerazinske . To je značilo stvaranje jednog Prometheus meta poslužitelja koji prikuplja neke metrike sa svakog lisnog poslužitelja.
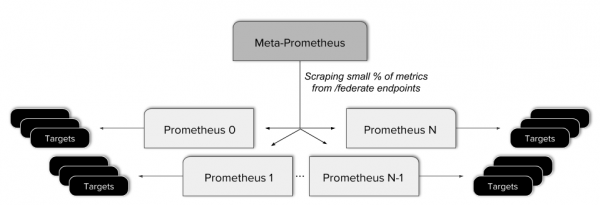
Ovaj se pristup pokazao problematičnim. To je rezultiralo složenijim konfiguracijama, dodavanjem dodatne potencijalne točke kvara i primjenom složenih pravila kako bi se osiguralo da objedinjena krajnja točka prima samo podatke koji su joj potrebni. Osim toga, ova vrsta federacije ne dopušta vam da dobijete pravi globalni prikaz, jer nisu svi podaci dostupni iz jednog API zahtjeva.
Usko povezan s ovim je objedinjeni prikaz podataka prikupljenih na Prometheus poslužiteljima visoke dostupnosti (HA). Prometheusov HA model samostalno prikuplja podatke dva puta, što je toliko jednostavno da jednostavnije ne može biti. Međutim, korištenje kombiniranog i dedupliciranog prikaza oba toka bilo bi mnogo praktičnije.
Naravno, postoji potreba za visoko dostupnim Prometheus poslužiteljima. U tvrtki Improbable vrlo ozbiljno shvaćamo praćenje podataka iz minute u minutu, ali imati jednu instancu Prometheusa po klasteru jedina je točka kvara. Svaka pogreška u konfiguraciji ili kvar hardvera potencijalno može dovesti do gubitka važnih podataka. Čak i jednostavna implementacija može uzrokovati manje smetnje u prikupljanju mjernih podataka jer ponovno pokretanje može biti znatno dulje od intervala skrapinga.
Pouzdana pohrana povijesnih podataka
Jeftina, brza, dugoročna pohrana metrike naš je san (koji dijeli većina korisnika Prometheusa). U igri Improbable bili smo prisiljeni konfigurirati razdoblje zadržavanja metrike na devet dana (za Prometheus 1.8). Ovo dodaje očite granice koliko daleko možemo gledati unatrag.
Prometheus 2.0 poboljšan je u tom smislu, budući da broj vremenskih serija više ne utječe na ukupnu izvedbu poslužitelja (vidi. ). Međutim, Prometheus pohranjuje podatke na lokalni disk. Iako visokoučinkovita kompresija podataka može značajno smanjiti lokalnu upotrebu SSD-a, u konačnici još uvijek postoji ograničenje količine povijesnih podataka koji se mogu pohraniti.
Osim toga, u Improbableu brinemo o pouzdanosti, jednostavnosti i cijeni. Velikim lokalnim diskovima teže je upravljati i stvarati sigurnosnu kopiju. Oni koštaju više i zahtijevaju više alata za sigurnosno kopiranje, što rezultira nepotrebnom složenošću.
Smanjivanje uzorkovanja
Nakon što smo počeli raditi s povijesnim podacima, shvatili smo da postoje temeljne poteškoće s big-O zbog kojih su upiti sve sporiji i sporiji dok radimo s tjednima, mjesecima i godinama podataka.
Standardno rješenje za ovaj problem bilo bi (downsampling) - smanjenje frekvencije uzorkovanja signala. Uz smanjivanje uzorkovanja, možemo se "smanjiti" na veći vremenski raspon i zadržati isti broj uzoraka, održavajući odziv upita.
Snižavanje uzorkovanja starih podataka neizbježan je zahtjev svakog rješenja za dugotrajnu pohranu i izvan je dosega Prometheusa bez boje.
Dodatni ciljevi
Jedan od izvornih ciljeva Thanos projekta bio je besprijekorna integracija sa svim postojećim Prometheusovim instalacijama. Drugi cilj bila je jednostavnost rada s minimalnim preprekama za ulazak. Sve ovisnosti trebaju biti lako zadovoljene i za male i za velike korisnike, što također znači nisku osnovnu cijenu.
Thanos arhitektura
Nakon popisa naših ciljeva u prethodnom odjeljku, proradimo ih i vidimo kako Thanos rješava te probleme.
Globalni pogled
Da bismo dobili globalni pogled na postojeće Prometheus instance, moramo povezati jednu ulaznu točku zahtjeva sa svim poslužiteljima. Upravo to radi komponenta Thanos. . Postavljen je pored svakog Prometheus poslužitelja i djeluje kao proxy, opslužujući lokalne Prometheus podatke putem gRPC Store API-ja, dopuštajući dohvaćanje podataka vremenskih serija prema oznaci i vremenskom rasponu.
S druge strane je scale-out komponenta Querier bez statusa, koja ne radi ništa više od pukog odgovaranja na PromQL upite putem standardnog Prometheus HTTP API-ja. Querier, Sidecar i ostale komponente Thanosa komuniciraju putem .
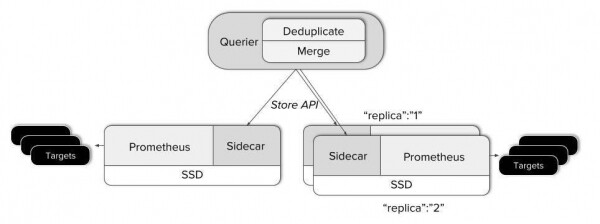
- Querier se po primitku zahtjeva spaja na pripadajući Store API poslužitelj, odnosno na naše Sidecars i prima podatke o vremenskim serijama od odgovarajućih Prometheus poslužitelja.
- Nakon toga kombinira odgovore i na njima izvršava PromQL upit. Querier može spojiti i nepovezane podatke i duplicirane podatke s Prometheus HA poslužitelja.
Ovo rješava glavni dio naše slagalice - kombiniranje podataka s izoliranih Prometheus poslužitelja u jedan prikaz. Zapravo, Thanos se može koristiti samo za ovu značajku. Na postojećim Prometheus poslužiteljima nije potrebno raditi nikakve promjene!
Neograničen rok trajanja!
Međutim, prije ili kasnije poželjet ćemo pohraniti podatke izvan uobičajenog Prometheusovog vremena zadržavanja. Odabrali smo objektnu pohranu za pohranu povijesnih podataka. Široko je dostupan u bilo kojem oblaku kao iu lokalnim podatkovnim centrima i vrlo je isplativ. Osim toga, gotovo bilo koja pohrana objekata dostupna je putem dobro poznatog S3 API-ja.
Prometheus zapisuje podatke iz RAM-a na disk otprilike svaka dva sata. Pohranjeni blok podataka sadrži sve podatke za određeno vremensko razdoblje i nepromjenjiv je. Ovo je vrlo zgodno jer Thanos Sidecar može jednostavno pogledati direktorij podataka Prometheusa i, kako novi blokovi postanu dostupni, učitati ih u kante za pohranu objekata.
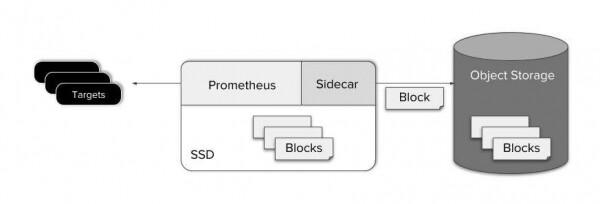
Učitavanje u pohranu objekata odmah nakon pisanja na disk također vam omogućuje da zadržite jednostavnost strugača (Prometheus i Thanos Sidecar). Što pojednostavljuje podršku, troškove i dizajn sustava.
Kao što vidite, backup podataka je vrlo jednostavan. Ali što je s upitima za podatke u pohrani objekata?
Komponenta Thanos Store djeluje kao proxy za dohvaćanje podataka iz pohrane objekata. Kao i Thanos Sidecar, sudjeluje u klasteru ogovaranja i implementira Store API. Na ovaj način ga postojeći Querier može tretirati kao Sidecar, kao još jedan izvor podataka o vremenskoj seriji - nije potrebna posebna konfiguracija.
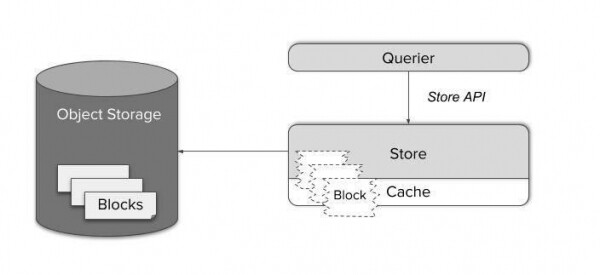
Blokovi podataka vremenske serije sastoje se od nekoliko velikih datoteka. Njihovo učitavanje na zahtjev bilo bi prilično neučinkovito, a njihovo lokalno spremanje zahtijevalo bi veliku količinu memorije i prostora na disku.
Umjesto toga, Store Gateway zna kako postupati s Prometheus formatom pohrane. Zahvaljujući pametnom planeru upita i predmemoriranju samo potrebnih dijelova indeksa blokova, moguće je složene upite svesti na minimalni broj HTTP zahtjeva za datoteke za pohranu objekata. Na taj način možete smanjiti broj zahtjeva za četiri do šest redova veličine i postići vremena odgovora koja je općenito teško razlikovati od zahtjeva za podacima na lokalnom SSD-u.
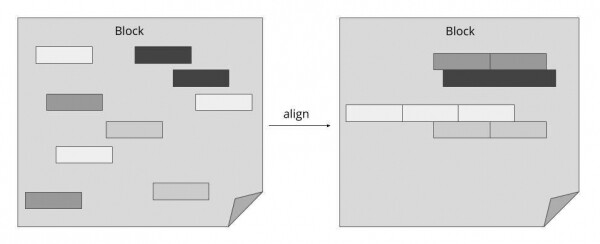
Kao što je prikazano na gornjem dijagramu, Thanos Querier značajno smanjuje cijenu po upitu podataka o pohranjivanju objekata iskorištavanjem Prometheus formata pohrane i postavljanjem povezanih podataka jedan pored drugog. Koristeći ovaj pristup, možemo kombinirati mnogo pojedinačnih zahtjeva u minimalan broj skupnih operacija.
Sažimanje i smanjivanje uzorkovanja
Nakon što se novi blok podataka vremenske serije uspješno učita u pohranu objekta, tretiramo ga kao "povijesne" podatke, koji su odmah dostupni putem Store Gatewaya.
Međutim, nakon nekog vremena blokovi iz jednog izvora (Prometheus s Sidecar) se nakupljaju i više ne koriste puni potencijal indeksiranja. Kako bismo riješili ovaj problem, uveli smo još jednu komponentu pod nazivom Compactor. Jednostavno primjenjuje Prometheusov lokalni mehanizam sažimanja na povijesne podatke u pohrani objekata i može se pokrenuti kao jednostavan periodični skupni posao.
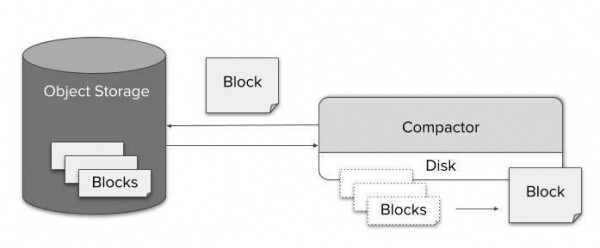
Zahvaljujući učinkovitoj kompresiji, upit za pohranu tijekom dužeg vremenskog razdoblja ne predstavlja problem u pogledu veličine podataka. Međutim, potencijalni trošak raspakiranja milijarde vrijednosti i njihovog provođenja kroz procesor upita neizbježno će rezultirati dramatičnim povećanjem vremena izvršenja upita. S druge strane, budući da na ekranu postoje stotine podatkovnih točaka po pikselu, postaje nemoguće čak i vizualizirati podatke u punoj razlučivosti. Stoga smanjenje uzorkovanja nije samo moguće, nego također neće dovesti do primjetnog gubitka točnosti.
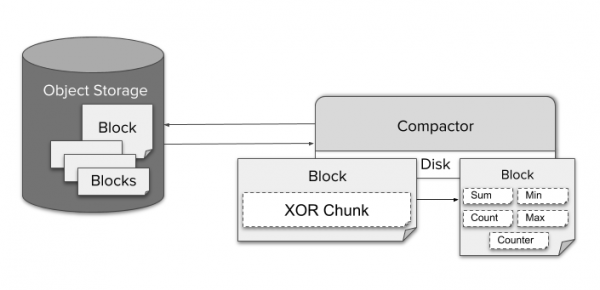
Za smanjenje uzorkovanja podataka, Compactor kontinuirano agregira podatke u rezoluciji od pet minuta i jednog sata. Za svaki neobrađeni komad kodiran korištenjem TSDB XOR kompresije, pohranjuju se različite vrste agregatnih podataka, kao što su min, maksimum ili zbroj za jedan blok. To omogućuje Querieru da automatski odabere agregat koji je prikladan za određeni PromQL upit.
Nije potrebna nikakva posebna konfiguracija da bi korisnik koristio podatke smanjene preciznosti. Querier se automatski prebacuje između različitih rezolucija i neobrađenih podataka kako korisnik povećava i smanjuje prikaz. Po želji, korisnik to može kontrolirati izravno putem parametra "korak" u zahtjevu.
Budući da je cijena pohranjivanja jednog GB niska, Thanos prema zadanim postavkama pohranjuje neobrađene podatke, petominutne i jednosatne podatke. Nema potrebe za brisanjem izvornih podataka.
Pravila snimanja
Čak i s Thanosom, pravila snimanja bitan su dio nadzornog skupa. Oni smanjuju složenost, kašnjenje i cijenu upita. Također su prikladni za korisnike da dobiju agregirane podatke prema metrikama. Thanos se temelji na instancama Prometheusa vanilije, tako da je savršeno prihvatljivo pohraniti pravila snimanja i pravila upozorenja na postojeći Prometheus poslužitelj. Međutim, u nekim slučajevima to možda neće biti dovoljno:
- Globalno upozorenje i pravilo (na primjer, upozorenje kada usluga ne radi na više od dva od tri klastera).
- Pravilo za podatke izvan lokalne pohrane.
- Želja za pohranjivanjem svih pravila i upozorenja na jednom mjestu.
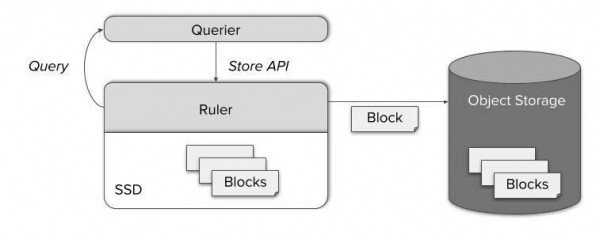
Za sve te slučajeve Thanos uključuje zasebnu komponentu pod nazivom Ruler, koja izračunava pravilo i upozorenje putem Thanos Queriesa. Omogućavanjem dobro poznatog StoreAPI-ja, Query čvor može pristupiti svježe izračunatim metrikama. Kasnije se također pohranjuju u pohranu objekata i stavljaju se na raspolaganje putem Store Gatewaya.
Snaga Thanosa
Thanos je dovoljno fleksibilan da se može prilagoditi vašim potrebama. Ovo je posebno korisno kada migrirate s običnog Prometeja. Ponovimo nakratko što smo naučili o Thanos komponentama s kratkim primjerom. Evo kako odvesti svog vanilla Prometheusa u svijet "neograničene pohrane metrike":
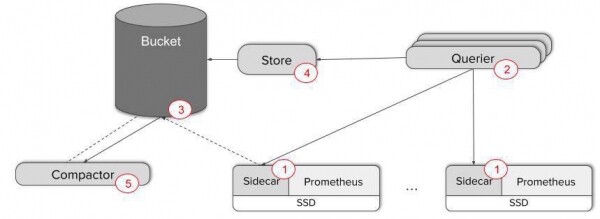
- Dodajte Thanos Sidecar na svoje Prometheus poslužitelje - na primjer, kontejner s prikolicom u Kubernetes pod.
- Implementirajte više replika Thanos Queriera da biste mogli pregledavati podatke. U ovoj fazi lako je uspostaviti trač između Scrapera i Queriera. Za provjeru interakcije komponenti upotrijebite metriku 'thanos_cluster_members'.
Samo ova dva koraka dovoljna su za pružanje globalnog prikaza i besprijekorne deduplikacije podataka iz potencijalnih Prometheus HA replika! Jednostavno povežite svoje nadzorne ploče s Querier HTTP krajnjom točkom ili izravno koristite Thanos UI.
Međutim, ako vam je potrebna sigurnosna kopija metrike i dugoročna pohrana, morat ćete izvršiti još tri koraka:
- Stvorite AWS S3 ili GCS kantu. Konfigurirajte Sidecar za kopiranje podataka u ove segmente. Lokalna pohrana podataka sada se može minimizirati.
- Postavite Store Gateway i povežite ga sa svojim postojećim tračerskim klasterom. Sada možete tražiti sigurnosno kopirane podatke!
- Implementirajte Compactor kako biste poboljšali učinkovitost upita tijekom dugih vremenskih razdoblja pomoću sažimanja i smanjenja uzorkovanja.
Ako želite znati više, ne ustručavajte se pogledati naše и !
U samo pet koraka pretvorili smo Prometheus u pouzdan sustav praćenja s globalnim pregledom, neograničenim vremenom pohrane i potencijalno velikom dostupnošću metrike.
Zahtjev za povlačenje: trebamo vas!
je projekt otvorenog koda od samog početka. Besprijekorna integracija s Prometheusom i mogućnost korištenja samo dijela Thanosa čine ga odličnim izborom za skaliranje vašeg sustava za praćenje bez napora.
Uvijek pozdravljamo GitHub zahtjeve za povlačenje i probleme. U međuvremenu, slobodno nam se obratite putem Github Issues ili Slackako imate pitanja ili povratnih informacija, ili želite podijeliti svoje iskustvo korištenja! Ako vam se sviđa ono što radimo u Improbableu, ne ustručavajte se kontaktirati nas - !
Izvor: www.habr.com
