

Postoje situacije kada u tablicu bez primarnog ključa ili neki drugi jedinstveni indeks, zbog previda, sadrži potpune klonove već postojećih zapisa.

Na primjer, vrijednosti kronološke metrike zapisuju se u PostgreSQL pomoću COPY streama, a zatim dolazi do iznenadnog kvara i ponovno se pojavljuju potpuno identični podaci.
Kako se riješiti nepotrebnih klonova iz baze podataka?
Kada PK nije koristan
Najjednostavnije rješenje je spriječiti da se ova situacija uopće pojavi. Na primjer, implementacijom PRIMARNOG KLJUČA. Ali to nije uvijek moguće bez povećanja količine pohranjenih podataka.
Na primjer, ako je točnost izvornog sustava veća od točnosti polja u bazi podataka:
metric | ts | data
--------------------------------------------------
cpu.busy | 2019-12-20 00:00:00 | {"value" : 12.34}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 10}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 11.2}
cpu.busy | 2019-12-20 00:00:03 | {"value" : 15.7}
Jeste li primijetili? Odbrojavanje je, umjesto 00:00:02, zabilježeno u ts bazi podataka sekundu ranije, ali je s praktičnog stajališta ostalo savršeno valjano (uostalom, vrijednosti podataka su različite!).
Naravno, može se napraviti PK(metrički, ts) — ali onda ćemo dobiti sukobe umetanja za valjane podatke.
Mogu učiniti PK(metrika, ts, podaci) - ali to će uvelike povećati njegov volumen, koji nećemo koristiti.
Stoga je najispravnija opcija stvaranje regularnog nejedinstvenog indeksa. (metrički, ts) i rješavati probleme naknadno ako se pojave.
Klonovski ratovi su počeli.
Dogodila se neka vrsta nesreće i sada moramo uništiti klonirane zapise iz tablice.

Simulirajmo početne podatke:
CREATE TABLE tbl(k text, v integer);
INSERT INTO tbl
VALUES
('a', 1)
, ('a', 3)
, ('b', 2)
, ('b', 2) -- oops!
, ('c', 3)
, ('c', 3) -- oops!!
, ('c', 3) -- oops!!
, ('d', 4)
, ('e', 5)
;Ovdje nam se ruka tri puta zatresla, Ctrl+V se zaglavio, i evo ga...
Prvo, shvatimo da naša tablica može biti prilično velika, pa nakon što pronađemo sve klonove, morat ćemo ih doslovno "bockati prstom" da bismo ih izbrisali. određene zapise bez ponovnog pretraživanja.
I postoji takav način - ovo je , fizički identifikator određenog zapisa.
Dakle, prije svega, moramo prikupiti CTID-ove zapisa na temelju punog sadržaja retka tablice. Najjednostavnija opcija je pretvoriti cijeli redak u tekst:
SELECT
T::text
, array_agg(ctid) ctids
FROM
tbl T
GROUP BY
1;
t | ctids
---------------------------------
(e,5) | {"(0,9)"}
(d,4) | {"(0,8)"}
(c,3) | {"(0,5)","(0,6)","(0,7)"}
(b,2) | {"(0,3)","(0,4)"}
(a,3) | {"(0,2)"}
(a,1) | {"(0,1)"}
Je li moguće ne bacati?U principu, to je moguće u većini slučajeva. Dok ne počnete koristiti polja u ovoj tablici tipovi bez operatora jednakosti:
CREATE TABLE tbl(k text, v integer, x point);
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T;
-- ERROR: could not identify an equality operator for type tbl
Aha, odmah vidimo da ako u nizu ima više od jednog unosa, svi su klonovi. Zadržimo samo njih:
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T;unnest
------
(0,6)
(0,7)
(0,4)Za one koji vole pisati kraćeMožete to napisati i ovako:
SELECT
unnest((array_agg(ctid))[2:])
FROM
tbl T
GROUP BY
T::text;Budući da nas ne zanima sama vrijednost serijaliziranog niza, jednostavno smo ga izostavili iz vraćenih stupaca podupita.
Sve što preostaje je natjerati DELETE da koristi skup koji smo primili:
DELETE FROM
tbl
WHERE
ctid = ANY(ARRAY(
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T
)::tid[]);Provjerimo sami sebe:
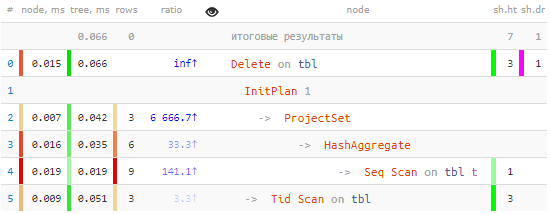
Da, točno: naša 3 zapisa su odabrana u jednom Seq Scan-u cijele tablice, a čvor Delete je korišten za pretraživanje podataka. jednokratni prolaz s Tid skeniranjem:
-> Tid Scan on tbl (actual time=0.050..0.051 rows=3 loops=1)
TID Cond: (ctid = ANY ($0))Ako ste izbrisali mnogo zapisa, .
Provjerimo veću tablicu i s većim brojem duplikata:
TRUNCATE TABLE tbl;
INSERT INTO tbl
SELECT
chr(ascii('a'::text) + (random() * 26)::integer) k -- a..z
, (random() * 100)::integer v -- 0..99
FROM
generate_series(1, 10000) i; 
Dakle, metoda uspješno funkcionira, ali je treba koristiti s određenim oprezom. Jer za svaki izbrisani zapis, postoji jedna stranica s podacima pročitana u Tid Scan i jedna u Delete.
Izvor: www.habr.com
