

Pozdrav, izrađujem aplikacije za DBMS je platforma koju je razvila Mail.ru Group koja kombinira DBMS visokih performansi i aplikacijski poslužitelj na jeziku Lua. Velika brzina rješenja koja se temelje na Tarantoolu postiže se, posebice, zahvaljujući podršci za način rada DBMS-a u memoriji i mogućnosti izvršavanja poslovne logike aplikacije u jednom adresnom prostoru s podacima. U isto vrijeme, postojanost podataka je osigurana pomoću ACID transakcija (WAL dnevnik se održava na disku). Tarantool ima ugrađenu podršku za replikaciju i dijeljenje. Počevši od verzije 2.1, podržani su upiti u SQL jeziku. Tarantool je otvorenog koda i licenciran pod Simplified BSD licencom. Postoji i komercijalna Enterprise verzija.

Osjetite snagu! (…odnosno uživajte u izvedbi)
Sve navedeno čini Tarantool atraktivnom platformom za izradu visokoopterećenih aplikacija koje rade s bazama podataka. U takvim aplikacijama često postoji potreba za replikacijom podataka.
Kao što je gore spomenuto, Tarantool ima ugrađenu replikaciju podataka. Načelo njegovog rada je sekvencijalno izvršavanje na replikama svih transakcija sadržanih u glavnom dnevniku (WAL). Obično takva replikacija (dalje ćemo je zvati niska razina) koristi se za osiguravanje tolerancije na pogreške aplikacije i/ili za raspodjelu opterećenja čitanja između čvorova klastera.
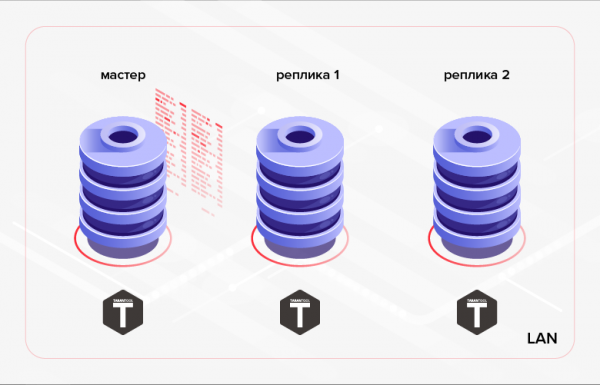
Riža. 1. Replikacija unutar klastera
Primjer alternativnog scenarija bio bi prijenos podataka stvorenih u jednoj bazi podataka u drugu bazu podataka za obradu/nadzor. U potonjem slučaju, prikladnije rješenje može biti korištenje visoka razina replikacija - replikacija podataka na razini poslovne logike aplikacije. Oni. Ne koristimo gotova rješenja ugrađena u DBMS, već sami implementiramo replikaciju unutar aplikacije koju razvijamo. Ovaj pristup ima i prednosti i nedostatke. Nabrojimo prednosti.
1. Ušteda prometa:
- Ne možete prenijeti sve podatke, već samo dio njih (npr. možete prenijeti samo neke tablice, neke njihove stupce ili zapise koji zadovoljavaju određeni kriterij);
- Za razliku od replikacije niske razine, koja se izvodi kontinuirano u asinkronom (implementiranom u trenutnoj verziji Tarantoola - 1.10) ili sinkronom (implementirati u sljedećim verzijama Tarantoola) načinu rada, replikacija visoke razine može se izvoditi u sesijama (tj. aplikacija prvo sinkronizira podatke - podaci sesije razmjene, zatim dolazi do pauze u replikaciji, nakon čega dolazi do sljedeće sesije razmjene itd.);
- ako se zapis promijenio nekoliko puta, možete prenijeti samo njegovu posljednju verziju (za razliku od replikacije niske razine, u kojoj će se sve promjene napravljene na masteru reproducirati sekvencijalno na replikama).
2. Nema poteškoća s implementacijom HTTP razmjene, koja vam omogućuje sinkronizaciju udaljenih baza podataka.
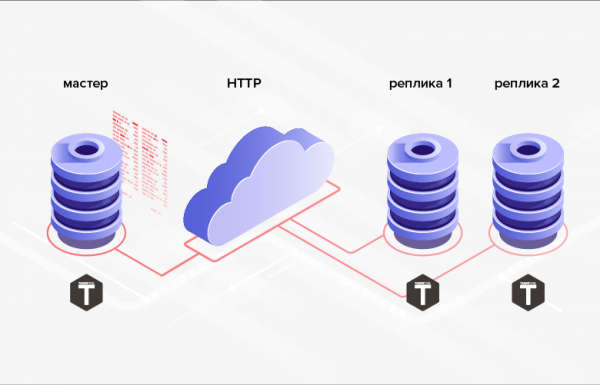
Riža. 2. Replikacija preko HTTP-a
3. Strukture baze podataka između kojih se podaci prenose ne moraju biti iste (štoviše, u općem slučaju moguće je čak koristiti različite DBMS-ove, programske jezike, platforme itd.).
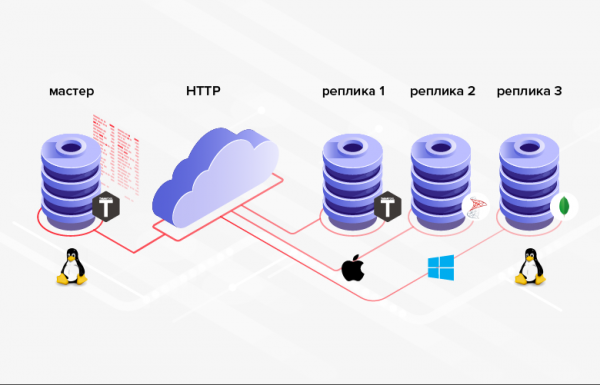
Riža. 3. Replikacija u heterogenim sustavima
Nedostatak je to što je programiranje u prosjeku teže/skuplje od konfiguracije, a umjesto prilagođavanja ugrađene funkcije, morat ćete implementirati vlastitu.
Ako su u vašoj situaciji gore navedene prednosti presudne (ili nužan uvjet), onda ima smisla koristiti replikaciju visoke razine. Pogledajmo nekoliko načina za implementaciju replikacije podataka visoke razine u Tarantool DBMS.
Minimiziranje prometa
Dakle, jedna od prednosti replikacije na visokoj razini je ušteda prometa. Kako bi se ova prednost u potpunosti ostvarila, potrebno je minimizirati količinu podataka koji se prenose tijekom svake sesije razmjene. Naravno, ne treba zaboraviti da na kraju sesije primatelj podataka mora biti sinkroniziran s izvorom (barem za onaj dio podataka koji je uključen u replikaciju).
Kako minimizirati količinu podataka koji se prenose tijekom replikacije na visokoj razini? Jednostavno rješenje može biti odabir podataka prema datumu i vremenu. Da biste to učinili, možete koristiti polje datum-vrijeme koje već postoji u tablici (ako postoji). Na primjer, dokument "narudžba" može imati polje "potrebno vrijeme izvršenja narudžbe" - delivery_time. Problem s ovim rješenjem je što vrijednosti u ovom polju ne moraju biti u nizu koji odgovara kreiranju naloga. Stoga se ne možemo sjetiti maksimalne vrijednosti polja delivery_time, prenesene tijekom prethodne sesije razmjene, a tijekom sljedeće sesije razmjene odaberite sve zapise s višom vrijednošću polja delivery_time. Zapisi s nižom vrijednošću polja možda su dodani između sesija razmjene delivery_time. Također, poredak je mogao doživjeti promjene, koje ipak nisu utjecale na teren delivery_time. U oba slučaja promjene se neće prenijeti s izvora na odredište. Da bismo riješili te probleme, morat ćemo podatke prenositi "preklapajući". Oni. u svakoj sesiji razmjene prenijet ćemo sve podatke s vrijednošću polja delivery_time, prelazeći neku točku u prošlosti (na primjer, N sati od trenutnog trenutka). Međutim, očito je da je za velike sustave ovaj pristup vrlo suvišan i može svesti uštede prometa kojima težimo na ništa. Osim toga, tablica koja se prenosi možda nema polje povezano s datumom i vremenom.
Drugo rješenje, složenije u smislu implementacije, je potvrda primitka podataka. U tom slučaju, tijekom svake sesije razmjene, prenose se svi podaci čiji primitak nije potvrđen od strane primatelja. Da biste ovo implementirali, morat ćete dodati Booleov stupac izvornoj tablici (na primjer, is_transferred). Ako primatelj potvrdi primitak zapisa, odgovarajuće polje preuzima vrijednost true, nakon čega unos više nije uključen u razmjene. Ova opcija implementacije ima sljedeće nedostatke. Prvo, za svaki preneseni zapis mora se generirati i poslati potvrda. Grubo govoreći, to bi se moglo usporediti s udvostručenjem količine prenesenih podataka i dovesti do udvostručenja broja povratnih putovanja. Drugo, ne postoji mogućnost slanja istog zapisa na više primatelja (prvi primatelj će potvrditi primitak za sebe i za sve ostale).
Metoda koja nema gore navedene nedostatke je dodavanje stupca u prenesenu tablicu za praćenje promjena u njezinim redcima. Takav stupac može biti tipa datum-vrijeme i mora ga aplikacija postaviti/ažurirati na trenutno vrijeme svaki put kada se zapisi dodaju/promijene (atomski s dodavanjem/promjenom). Kao primjer, nazovimo stupac update_time. Spremanjem maksimalne vrijednosti polja ovog stupca za prenesene zapise, možemo započeti sljedeću sesiju razmjene s tom vrijednošću (odaberite zapise s vrijednošću polja update_time, premašujući prethodno pohranjenu vrijednost). Problem s potonjim pristupom je da se promjene podataka mogu dogoditi u serijama. Kao rezultat vrijednosti polja u stupcu update_time ne mora biti jedinstven. Stoga se ovaj stupac ne može koristiti za izlaz podataka u dijelovima (stranica po stranica). Za prikaz podataka stranicu po stranicu, morat ćete izmisliti dodatne mehanizme koji će najvjerojatnije imati vrlo nisku učinkovitost (na primjer, dohvaćanje iz baze podataka svih zapisa s vrijednošću update_time veći od zadanog i proizvodi određeni broj zapisa, počevši od određenog pomaka od početka uzorka).
Učinkovitost prijenosa podataka možete poboljšati neznatnim poboljšanjem prethodnog pristupa. Da bismo to učinili, koristit ćemo tip cijelog broja (long integer) kao vrijednosti polja stupca za praćenje promjena. Imenujmo stupac row_ver. Vrijednost polja ovog stupca i dalje mora biti postavljena/ažurirana svaki put kada se zapis kreira/izmijeni. Ali u ovom slučaju polju neće biti dodijeljen trenutni datum-vrijeme, već vrijednost nekog brojača, uvećana za jedan. Kao rezultat toga, stupac row_ver sadržavat će jedinstvene vrijednosti i može se koristiti ne samo za prikaz "delta" podataka (podaci dodani/promijenjeni od kraja prethodne sesije razmjene), već i za jednostavno i učinkovito rastavljanje na stranice.
Posljednji predloženi način minimiziranja količine podataka koji se prenose u okviru replikacije visoke razine čini mi se najoptimalnijim i univerzalnim. Pogledajmo to detaljnije.
Prosljeđivanje podataka pomoću brojača verzije retka
Implementacija poslužiteljskog/master dijela
U MS SQL Serveru postoji posebna vrsta stupca za implementaciju ovog pristupa - rowversion. Svaka baza podataka ima brojač koji se povećava za jedan svaki put kada se zapis doda/promijeni u tablici koja ima stupac poput rowversion. Vrijednost ovog brojača automatski se dodjeljuje polju ovog stupca u dodanom/promijenjenom zapisu. Tarantool DBMS nema sličan ugrađeni mehanizam. Međutim, u Tarantoolu to nije teško implementirati ručno. Pogledajmo kako se to radi.
Prvo, malo terminologije: tablice u Tarantoolu nazivaju se prostori, a zapisi se zovu torke. U Tarantoolu možete kreirati sekvence. Nizovi nisu ništa drugo nego imenovani generatori uređenih cjelobrojnih vrijednosti. Oni. to je upravo ono što nam treba za naše svrhe. U nastavku ćemo stvoriti takav niz.
Prije izvođenja bilo koje operacije baze podataka u Tarantoolu, trebate pokrenuti sljedeću naredbu:
box.cfg{}Kao rezultat toga, Tarantool će početi pisati snimke baze podataka i zapise transakcija u trenutni direktorij.
Kreirajmo niz row_version:
box.schema.sequence.create('row_version',
{ if_not_exists = true })
Opcija if_not_exists omogućuje višestruko izvršavanje skripte za stvaranje: ako objekt postoji, Tarantool ga neće pokušati ponovno stvoriti. Ova opcija će se koristiti u svim sljedećim DDL naredbama.
Stvorimo prostor kao primjer.
box.schema.space.create('goods', {
format = {
{
name = 'id',
type = 'unsigned'
},
{
name = 'name',
type = 'string'
},
{
name = 'code',
type = 'unsigned'
},
{
name = 'row_ver',
type = 'unsigned'
}
},
if_not_exists = true
})
Ovdje postavljamo naziv prostora (goods), imena polja i njihove vrste.
Polja s automatskim povećanjem u Tarantoolu također se stvaraju pomoću sekvenci. Kreirajmo primarni ključ koji se automatski povećava po polju id:
box.schema.sequence.create('goods_id',
{ if_not_exists = true })
box.space.goods:create_index('primary', {
parts = { 'id' },
sequence = 'goods_id',
unique = true,
type = 'HASH',
if_not_exists = true
})Tarantool podržava nekoliko vrsta indeksa. Najčešće korišteni indeksi su TREE i HASH tipovi, koji se temelje na strukturama koje odgovaraju imenu. TREE je najsvestraniji tip indeksa. Omogućuje vam da dohvatite podatke na organiziran način. Ali za odabir jednakosti, HASH je prikladniji. Sukladno tome, preporučljivo je koristiti HASH za primarni ključ (što smo i učinili).
Za korištenje stupca row_ver da biste prenijeli promijenjene podatke, trebate vezati vrijednosti niza na polja ovog stupca row_ver. Ali za razliku od primarnog ključa, vrijednost polja stupca row_ver treba povećati za jedan ne samo pri dodavanju novih zapisa, već i pri mijenjanju postojećih. Za to možete koristiti okidače. Tarantool ima dvije vrste svemirskih okidača: before_replace и on_replace. Okidači se aktiviraju kad god se podaci u prostoru promijene (za svaku torku na koju promjene utječu, pokreće se funkcija okidača). Za razliku od on_replace, before_replace-okidači vam omogućuju izmjenu podataka torke za koju se okidač izvršava. Sukladno tome, zadnja vrsta okidača nam odgovara.
box.space.goods:before_replace(function(old, new)
return box.tuple.new({new[1], new[2], new[3],
box.sequence.row_version:next()})
end)
Sljedeći okidač zamjenjuje vrijednost polja row_ver pohranjenu torku na sljedeću vrijednost niza row_version.
Kako bi mogli izvlačiti podatke iz svemira goods po stupcu row_ver, kreirajmo indeks:
box.space.goods:create_index('row_ver', {
parts = { 'row_ver' },
unique = true,
type = 'TREE',
if_not_exists = true
})
Vrsta indeksa - stablo (TREE), jer morat ćemo izdvojiti podatke uzlaznim redoslijedom vrijednosti u stupcu row_ver.
Dodajmo neke podatke u prostor:
box.space.goods:insert{nil, 'pen', 123}
box.space.goods:insert{nil, 'pencil', 321}
box.space.goods:insert{nil, 'brush', 100}
box.space.goods:insert{nil, 'watercolour', 456}
box.space.goods:insert{nil, 'album', 101}
box.space.goods:insert{nil, 'notebook', 800}
box.space.goods:insert{nil, 'rubber', 531}
box.space.goods:insert{nil, 'ruler', 135}
Jer Prvo polje je automatski inkrementirajući brojač; umjesto toga prenosimo nulu. Tarantool će automatski zamijeniti sljedeću vrijednost. Slično, kao vrijednost polja stupca row_ver možete proslijediti nil - ili uopće ne navesti vrijednost, jer ovaj stupac zauzima zadnje mjesto u prostoru.
Provjerimo rezultat umetanja:
tarantool> box.space.goods:select()
---
- - [1, 'pen', 123, 1]
- [2, 'pencil', 321, 2]
- [3, 'brush', 100, 3]
- [4, 'watercolour', 456, 4]
- [5, 'album', 101, 5]
- [6, 'notebook', 800, 6]
- [7, 'rubber', 531, 7]
- [8, 'ruler', 135, 8]
...
Kao što vidite, prvo i zadnje polje popunjavaju se automatski. Sada će biti lako napisati funkciju za učitavanje stranica po stranicu promjena prostora goods:
local page_size = 5
local function get_goods(row_ver)
local index = box.space.goods.index.row_ver
local goods = {}
local counter = 0
for _, tuple in index:pairs(row_ver, {
iterator = 'GT' }) do
local obj = tuple:tomap({ names_only = true })
table.insert(goods, obj)
counter = counter + 1
if counter >= page_size then
break
end
end
return goods
end
Funkcija kao parametar uzima vrijednost row_ver, počevši od kojeg je potrebno istovariti promjene, te vraća dio promijenjenih podataka.
Uzorkovanje podataka u Tarantoolu vrši se putem indeksa. Funkcija get_goods koristi iterator prema indeksu row_ver za primanje promijenjenih podataka. Tip iteratora je GT (Greater Than, veće od). To znači da će iterator sekvencijalno prelaziti vrijednosti indeksa počevši od proslijeđenog ključa (vrijednost polja row_ver).
Iterator vraća torke. Kako bi naknadno mogli prenositi podatke putem HTTP-a, potrebno je konvertirati torke u strukturu prikladnu za naknadnu serijalizaciju. Primjer za to koristi standardnu funkciju tomap. Umjesto korištenja tomap možete napisati vlastitu funkciju. Na primjer, možda želimo preimenovati polje name, ne prolaze teren code i dodajte polje comment:
local function unflatten_goods(tuple)
local obj = {}
obj.id = tuple.id
obj.goods_name = tuple.name
obj.comment = 'some comment'
obj.row_ver = tuple.row_ver
return obj
end
Veličina stranice izlaznih podataka (broj zapisa u jednom dijelu) određena je varijablom page_size. U primjeru vrijednost page_size je 5. U pravom programu veličina stranice obično je važnija. Ovisi o prosječnoj veličini prostorne tuple. Optimalna veličina stranice može se empirijski odrediti mjerenjem vremena prijenosa podataka. Što je veća veličina stranice, to je manji broj povratnih putovanja između strane pošiljatelja i primatelja. Na taj način možete smanjiti ukupno vrijeme za preuzimanje promjena. Međutim, ako je stranica prevelika, predugo ćemo provesti na poslužitelju serijalizirajući uzorak. Kao rezultat toga, može doći do kašnjenja u obradi drugih zahtjeva koji dolaze na poslužitelj. Parametar page_size može se učitati iz konfiguracijske datoteke. Za svaki preneseni prostor možete postaviti vlastitu vrijednost. Međutim, za većinu prostora zadana vrijednost (na primjer, 100) može biti prikladna.
Izvršimo funkciju get_goods:
tarantool> get_goods(0)
---
- - row_ver: 1
code: 123
name: pen
id: 1
- row_ver: 2
code: 321
name: pencil
id: 2
- row_ver: 3
code: 100
name: brush
id: 3
- row_ver: 4
code: 456
name: watercolour
id: 4
- row_ver: 5
code: 101
name: album
id: 5
...
Uzmimo vrijednost polja row_ver iz posljednjeg retka i ponovno pozovite funkciju:
tarantool> get_goods(5)
---
- - row_ver: 6
code: 800
name: notebook
id: 6
- row_ver: 7
code: 531
name: rubber
id: 7
- row_ver: 8
code: 135
name: ruler
id: 8
...Ponovno:
tarantool> get_goods(8)
---
- []
...
Kao što vidite, kada se koristi na ovaj način, funkcija vraća sve zapise prostora stranicu po stranicu goods. Nakon posljednje stranice slijedi prazan odabir.
Unesimo promjene u prostor:
box.space.goods:update(4, {{'=', 6, 'copybook'}})
box.space.goods:insert{nil, 'clip', 234}
box.space.goods:insert{nil, 'folder', 432}
Promijenili smo vrijednost polja name za jedan unos i dodao dva nova unosa.
Ponovimo posljednji poziv funkcije:
tarantool> get_goods(8)
---
- - row_ver: 9
code: 800
name: copybook
id: 6
- row_ver: 10
code: 234
name: clip
id: 9
- row_ver: 11
code: 432
name: folder
id: 10
...
Funkcija je vratila promijenjene i dodane zapise. Dakle funkcija get_goods omogućuje primanje podataka koji su se promijenili od posljednjeg poziva, što je osnova metode replikacije koja se razmatra.
Izdavanje rezultata putem HTTP-a u obliku JSON-a ostavit ćemo izvan opsega ovog članka. O ovome možete čitati ovdje:
Implementacija klijent/slave dijela
Pogledajmo kako izgleda implementacija primateljske strane. Napravimo prostor na prijemnoj strani za pohranjivanje preuzetih podataka:
box.schema.space.create('goods', {
format = {
{
name = 'id',
type = 'unsigned'
},
{
name = 'name',
type = 'string'
},
{
name = 'code',
type = 'unsigned'
}
},
if_not_exists = true
})
box.space.goods:create_index('primary', {
parts = { 'id' },
sequence = 'goods_id',
unique = true,
type = 'HASH',
if_not_exists = true
})
Struktura prostora nalikuje strukturi prostora u izvoru. Ali budući da primljene podatke nećemo proslijediti nigdje drugdje, stupac row_ver nije u prostoru primatelja. U polju id identifikatori izvora bit će zabilježeni. Stoga, na strani prijamnika nema potrebe da se automatski povećava.
Osim toga, potreban nam je prostor za spremanje vrijednosti row_ver:
box.schema.space.create('row_ver', {
format = {
{
name = 'space_name',
type = 'string'
},
{
name = 'value',
type = 'string'
}
},
if_not_exists = true
})
box.space.row_ver:create_index('primary', {
parts = { 'space_name' },
unique = true,
type = 'HASH',
if_not_exists = true
})
Za svaki učitani prostor (polje space_name) ovdje ćemo spremiti zadnju učitanu vrijednost row_ver (polje value). Stupac djeluje kao primarni ključ space_name.
Kreirajmo funkciju za učitavanje podataka o prostoru goods putem HTTP-a. Da bismo to učinili, potrebna nam je biblioteka koja implementira HTTP klijent. Sljedeći redak učitava biblioteku i instancira HTTP klijenta:
local http_client = require('http.client').new()Također nam je potrebna biblioteka za json deserijalizaciju:
local json = require('json')Ovo je dovoljno za stvaranje funkcije učitavanja podataka:
local function load_data(url, row_ver)
local url = ('%s?rowVer=%s'):format(url,
tostring(row_ver))
local body = nil
local data = http_client:request('GET', url, body, {
keepalive_idle = 1,
keepalive_interval = 1
})
return json.decode(data.body)
end
Funkcija izvršava HTTP zahtjev na url adresu i šalje ga row_ver kao parametar i vraća deserijalizirani rezultat zahtjeva.
Funkcija za spremanje primljenih podataka izgleda ovako:
local function save_goods(goods)
local n = #goods
box.atomic(function()
for i = 1, n do
local obj = goods[i]
box.space.goods:put(
obj.id, obj.name, obj.code)
end
end)
end
Ciklus spremanja podataka u prostor goods postavljen u transakciju (za to se koristi funkcija box.atomic) za smanjenje broja diskovnih operacija.
Konačno, funkcija sinkronizacije lokalnog prostora goods s izvorom možete implementirati ovako:
local function sync_goods()
local tuple = box.space.row_ver:get('goods')
local row_ver = tuple and tuple.value or 0
—— set your url here:
local url = 'http://127.0.0.1:81/test/goods/list'
while true do
local goods = load_goods(url, row_ver)
local count = #goods
if count == 0 then
return
end
save_goods(goods)
row_ver = goods[count].rowVer
box.space.row_ver:put({'goods', row_ver})
end
end
Prvo čitamo prethodno spremljenu vrijednost row_ver za prostor goods. Ako nedostaje (prva sesija razmjene), tada je uzimamo kao row_ver nula. Sljedeće u ciklusu vršimo preuzimanje stranice po stranicu promijenjenih podataka iz izvora na navedenom URL-u. U svakoj iteraciji spremamo primljene podatke u odgovarajući lokalni prostor i ažuriramo vrijednost row_ver (u svemiru row_ver i u varijabli row_ver) - uzeti vrijednost row_ver od posljednjeg retka učitanih podataka.
Za zaštitu od slučajnog ponavljanja (u slučaju greške u programu), petlja while može se zamijeniti sa for:
for _ = 1, max_req do ...
Kao rezultat izvršavanja funkcije sync_goods prostor goods prijemnik će sadržavati najnovije verzije svih svemirskih zapisa goods u izvoru.
Očito se brisanje podataka ne može emitirati na ovaj način. Ako takva potreba postoji, možete koristiti oznaku za brisanje. Dodaj u prostor goods Booleovo polje is_deleted a umjesto fizičkog brisanja zapisa koristimo se logičkim brisanjem – postavljamo vrijednost polja is_deleted u vrijednosti true. Ponekad umjesto Booleovog polja is_deleted prikladnije je koristiti polje deleted, koji pohranjuje datum-vrijeme logičkog brisanja zapisa. Nakon izvođenja logičkog brisanja, zapis označen za brisanje bit će prebačen s izvora na odredište (prema gore navedenoj logici).
Slijed row_ver može se koristiti za prijenos podataka iz drugih prostora: nema potrebe za stvaranjem zasebnog niza za svaki preneseni prostor.
Pogledali smo učinkovit način replikacije podataka visoke razine u aplikacijama koje koriste Tarantool DBMS.
Zaključci
- Tarantool DBMS je atraktivan, obećavajući proizvod za stvaranje visokoopterećenih aplikacija.
- Replikacija podataka visoke razine ima brojne prednosti u odnosu na replikaciju niske razine.
- Metoda replikacije na visokoj razini o kojoj se raspravlja u članku omogućuje smanjenje količine prenesenih podataka prijenosom samo onih zapisa koji su promijenjeni od posljednje sesije razmjene.
Izvor: www.habr.com
