

Tehát Ön mérőszámokat gyűjt. Mi is. Mi is gyűjtünk mérőszámokat. Természetesen azokat, amelyek az üzlet szempontjából relevánsak. Ma a monitorozó rendszerünk legelső kapcsolatáról fogunk beszélni – a statsd-kompatibilis aggregációs szerverről. , miért írtuk meg, és miért hagytuk el a Brubecket.
Korábbi cikkeinkből (, ) megtudhatod, hogy egy ideje még a következővel gyűjtöttünk címkéket: C nyelven íródott. Olyan egyszerű, mint egy egér (ami fontos, ha hozzá szeretnél járulni), és ami a legfontosabb, gond nélkül kezeli a másodpercenkénti 2 millió metrikus (MPS) csúcsforgalmunkat. A dokumentáció csillaggal jelölve 4 millió MPS támogatását állítja. Ez azt jelenti, hogy a megadott értéket kapod, ha helyesen konfigurálod a hálózatot. Linux(Nem tudjuk, hogy hány MPS-t kaphatna, ha a hálózatot jelenlegi állapotában hagyná.) Ezen előnyök ellenére számos komoly panasz érkezett a Brubeckkel kapcsolatban.
1. állítás. A Github, a projekt fejlesztője, leállította a támogatását: nem publikál javításokat és hibajavításokat, nem fogadja el a mi (és mások) PR-jeit. Az elmúlt néhány hónapban (valahol 2018 február-március környékén) újraindult a tevékenység, de előtte majdnem két év teljes csend volt. Továbbá a projekt fejlesztés alatt áll. , ami komoly akadályt jelenthet az új funkciók bevezetésében.
2. állítás. Számítási pontosság. A Brubeck mindössze 65 536 értéket gyűjt az összesítéshez. Esetünkben egyes metrikák esetében az összesítési időszak (30 másodperc) lényegesen több értéket is kaphat (csúcsértékként 1 527 392). Ennek a mintavételezésnek az eredményeként a maximális és minimális értékek haszontalannak tűnnek. Például így:
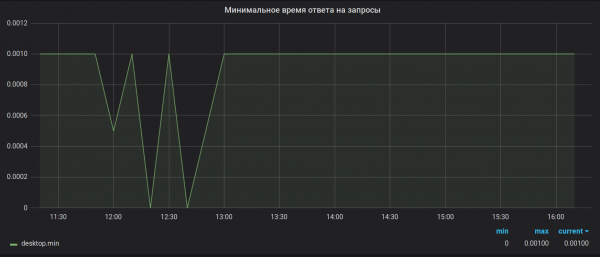
Mint volt
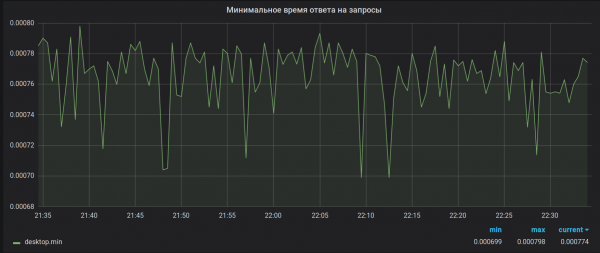
Hogy kellett volna lennie
Ugyanezen okból kifolyólag az összegek is helytelenül kerülnek kiszámításra. Ehhez adjuk hozzá a 32 bites float túlcsordulásos hibát, amely egy látszólag ártatlan metrika fogadásakor szegfault állapotba küldi a szervert, és minden tökéletessé válik. Egyébként ezt a hibát soha nem javították ki.
És végül, X. követelésJelen sorok írásakor készen állunk arra, hogy teszteljük mind a 14 többé-kevésbé működő statsd implementációval, amit találtunk. Képzeljük el, hogy egy adott infrastruktúra annyira megnőtt, hogy 4 millió MPS betöltése már nem elegendő. Vagy, még ha nem is nőtt, a metrikák annyira fontosak számunkra, hogy még a grafikonok rövid, 2-3 perces visszaesései is kritikussá válhatnak, és leküzdhetetlen depressziós rohamokat válthatnak ki a vezetőkben. Mivel a depresszió kezelése hálátlan feladat, technikai megoldásokra van szükség.
Először is, a hibatűrés, hogy egy hirtelen fellépő szerverhiba ne idézzen elő pszichiátriai zombiapokalipszist az irodában. Másodszor, a skálázhatóság, hogy több mint 4 millió MPS-t tudjon kezelni anélkül, hogy mélyen bele kellene ásnia a hálózati verembe. Linux és nyugodtan növekedjen „szélességben” a kívánt méretre.
Mivel volt némi skálázhatósági mozgásterünk, úgy döntöttünk, hogy a hibatűréssel kezdjük. „Ó! Hibatűrés! Ez egyszerű, meg tudjuk csinálni” – gondoltuk, és elindítottunk két szervert, mindegyiken a brubeck egy példányát futtatva. Ehhez mindkét szerverre át kellett másolni a forgalmat a metrikák segítségével, sőt, még egy kódrészletet is kellett írni hozzá. Így megoldottuk a hibatűrési problémát, de... nem túl jól. Eleinte minden rendben lévőnek tűnt: minden brubeck begyűjti a saját aggregációs verzióját, 30 másodpercenként adatokat ír a Graphite-ra, felülírva a régi intervallumot (ez a Graphite oldalon történik). Ha az egyik szerver meghibásodik, mindig van egy második szerverünk az aggregált adatok saját másolatával. De itt a probléma: ha egy szerver meghibásodik, egy "fűrész-fűrész" minta jelenik meg a grafikonokon. Ez annak köszönhető, hogy a brubeck 30 másodperces intervallumai nincsenek szinkronizálva, és amikor az egyik meghibásodik, nem írja felül. Ugyanez történik a második szerver indításakor is. Elviselhető, de jobbat szeretnénk! A skálázhatósági probléma is megmarad. Minden metrika továbbra is egyetlen szerverre megy, és ezért ugyanarra a 2-4 millió MPS-re vagyunk korlátozva, a hálózati teljesítménytől függően.
Ha hólapátolás közben egy kicsit gondolkodsz a problémán, egy kézenfekvő ötlet juthat eszedbe: szükséged van egy statsd-re, amely elosztott módban is tud működni. Vagyis egy olyanra, amely idő és metrikák szerinti szinkronizációt valósít meg a csomópontok között. „Biztosan létezik már ilyen megoldás” – mondtuk, és elkezdtünk keresgélni a Google-ben... De semmit sem találtunk. Miután átfésültük a dokumentációt a különféle statsd-k után ( 2017. december 11-én semmit sem találtunk. Úgy tűnik, sem a fejlesztők, sem a felhasználók nem találkoztak még ENNYI ilyen sok mutatóval, különben biztosan előálltak volna valamivel.
Aztán eszünkbe jutott a „játék” statsd, a bioyino, amit a Just for Fun hackathonon írtunk (a projekt nevét egy szkript generálta a hackathon előtt), és rájöttünk, hogy sürgősen szükségünk van egy saját statsd-re. Miért?
- mert túl kevés statsd klón van a világon,
- mivel biztosítható a kívánt vagy ahhoz közeli hibatűrés és skálázhatóság (beleértve az összesített metrikák szinkronizálását a szerverek között és a küldéskor fellépő ütközések problémájának megoldását),
- mert pontosabban tudod kiszámítani a mutatókat, mint Brubeck,
- mivel mi magunk is részletesebb statisztikákat tudunk gyűjteni, amelyeket a Brubeck gyakorlatilag soha nem adott át nekünk,
- mert lehetőségem volt programozni a saját hiperteljesítményű, elosztott skálázású alkalmazásomat, ami nem teljesen replikálná egy másik hasonló hiperteljesítményű alkalmazás architektúráját... nos, érted.
Mit írjak bele? Rozsdát, természetesen. Miért?
- mivel már létezett a megoldás prototípusa,
- mivel a cikk szerzője már ismerte a Rustot akkoriban, és alig várta, hogy írjon bele valamit éles használatra, azzal a lehetőséggel, hogy nyílt forráskódúként kiadhassa,
- mivel a GC-t használó nyelvek a fogadott forgalom jellege (szinte valós idejű) miatt nem alkalmasak számunkra, és a GC-szünetek gyakorlatilag elfogadhatatlanok,
- mert a C-hez hasonló maximális teljesítményre van szükségünk
- Mert a Rust félelem nélküli párhuzamosságot biztosít, és ha C/C++-ban kezdenénk el írni, akkor még többet kapnánk, mint a brubeck, a sebezhetőségek, a puffer túlcsordulások, a versenyfeltételek és más ijesztő szavak.
Volt egy érv a Rust ellen is. A cégnek nem volt tapasztalata Rustban projektek létrehozásában, és mi sem terveztük használni a fő projektünkben. Így komoly aggodalmak voltak, hogy nem fog működni, de úgy döntöttünk, hogy kockáztatunk és kipróbáljuk.
Telt-múlt az idő…
Végül, számos sikertelen próbálkozás után elkészült az első működő verzió. Mi történt? Így nézett ki.
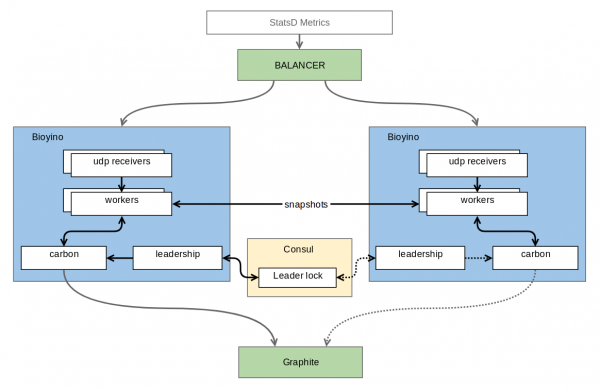
Minden csomópont megkapja a saját metrikakészletét, és összegyűjti azokat, de nem összesíti azokra a típusokra vonatkozó metrikákat, ahol a teljes készletre szükség lenne a végső összesítéshez. A csomópontok egy elosztott zárolási protokollon keresztül kapcsolódnak egymáshoz, amely lehetővé teszi számukra, hogy kiválasszák azt (itt sírtunk), amelyik méltó arra, hogy metrikákat küldjön a Nagy Egynek. Ezt a problémát jelenleg a következő megoldás kezeli: de a szerző ambíciói a jövőben kiterjednek Raft, ahol a konszenzusvezető csomópont természetesen a legérdemesebb. A konszenzus mellett a csomópontok gyakran (alapértelmezés szerint másodpercenként egyszer) elküldik szomszédaiknak az előre aggregált metrikák azon részeit, amelyeket az adott másodperc alatt sikerült összegyűjtöttük. Ez megőrzi a skálázhatóságot és a hibatűrést – minden csomópont továbbra is egy teljes metrikakészletet tart fenn, de a metrikák összesítve, TCP-n keresztül és bináris protokollon kódolva kerülnek elküldésre, ami jelentősen csökkenti a duplikációs költségeket az UDP-hez képest. A bejövő metrikák viszonylag nagy száma ellenére a felhalmozás nagyon kevés memóriát és még kevesebb CPU-t igényel. A jól tömörített metrikáink esetében ez csak néhány tíz megabájt adatot jelent. További előny, hogy a Graphite-ban elkerülhetők a felesleges adatátírások, ahogyan az a burbeck esetében történt.
A metrikákra épülő UDP csomagok a hálózati eszközök csomópontjai között egy egyszerű körforgásos rendszer segítségével kiegyensúlyozatlanok. Természetesen a hálózati hardver nem elemzi a csomagok tartalmát, ezért másodpercenként sokkal több mint 4 millió csomagot képes kezelni, nem is beszélve a metrikákról, amelyekről semmit sem tud. Figyelembe véve, hogy a metrikák nem érkeznek meg külön-külön minden csomagban, itt nem látunk előre teljesítményproblémákat. Ha egy szerver összeomlik, a hálózati eszköz gyorsan (1-2 másodpercen belül) észleli ezt, és eltávolítja a leállt szervert a rotációból. Ennek eredményeként a passzív (azaz nem vezető) csomópontok be- és kikapcsolhatók gyakorlatilag a grafikonok észrevehető csökkenése nélkül. A legtöbb, amit elveszítünk, az az utolsó másodpercben érkezett metrikák egy része. A vezető hirtelen elvesztése/váltása továbbra is kisebb anomáliát okoz (a 30 másodperces intervallum továbbra sincs szinkronban), de ha van kommunikáció a csomópontok között, ezek a problémák minimalizálhatók például szinkronizációs csomagok küldésével.
Egy kicsit a belső funkciókról. Az alkalmazás természetesen többszálú, de a szálarchitektúra eltér a brubeckben használttól. A brubeck szálai azonosak – mindegyik felelős mind az adatgyűjtésért, mind az aggregációért. A bioyino-ban a munkaszálak két csoportra oszlanak: azokra, amelyek a hálózati feldolgozásért felelősek, és azokra, amelyek az aggregációért felelősek. Ez a felosztás rugalmasabb alkalmazáskezelést tesz lehetővé a metrikák típusától függően: ahol intenzív aggregációra van szükség, aggregátorok adhatók hozzá, míg ahol nagy a hálózati forgalom, további hálózati szálak adhatók hozzá. Jelenleg nyolc hálózati szállal és négy aggregációs szállal működünk a szervereinken.
A számítási (aggregációs) rész meglehetősen fárasztó. A hálózati folyamatokkal töltött pufferek a számítási szálak között vannak elosztva, ahol azokat később elemzik és összesítik. Kérésre a metrikák más csomópontokhoz kerülnek. Mindez, beleértve a csomópontok közötti adatátvitelt és a Consul-lal való interakciót is, aszinkron módon történik, és a keretrendszeren fut. .
A metrikák fogadásáért felelős hálózati komponens sokkal több fejlesztési kihívást jelentett. A hálózati folyamatok különálló entitásokra való szétválasztásának elsődleges célja az egyes folyamatok által eltöltött idő csökkentése volt. nincs adatok olvasása egy socketből. Az aszinkron UDP és a szokásos recvmsg használatának lehetőségei gyorsan kihaltak: az előbbi túl sok felhasználói CPU-területet foglal el az eseményfeldolgozáshoz, míg az utóbbi túl sok kontextuskapcsolót. Ezért a jelenlegi megközelítés a következő: Nagy pufferekkel (és a pufferek, uraim, nem akármilyenek!), a hagyományos UDP támogatása alacsony terhelésű esetekre van fenntartva, amikor a recvmmsg-re nincs szükség. A többüzenetes mód eléri a fő célt: a hálózati szál idejének túlnyomó többségét az operációs rendszer várólistájának törlésével tölti – adatok olvasásával a socketből és a felhasználói tér pufferébe történő átvitelével, csak alkalmanként vált át a teljes puffer átadására az aggregátoroknak. A socket várólistája gyakorlatilag soha nem halmozódik fel, és az eldobott csomagok száma alig növekszik.
Megjegyzés
Alapértelmezés szerint a puffer mérete elég nagy. Ha úgy döntesz, hogy magad teszteled a szervert, előfordulhat, hogy néhány metrika elküldése után azok nem érkeznek meg a Graphite-ba, hanem a hálózati adatfolyam pufferében maradnak. Kis számú metrika kezeléséhez kisebb értékeket kell beállítanod a bufsize és a task-queue-size konfigurációs fájlokban.
Végül néhány lista a slágerlisták szerelmeseinek.
Statisztikák az egyes szerverek bejövő metrikáinak számáról: több mint 2 millió MPS.
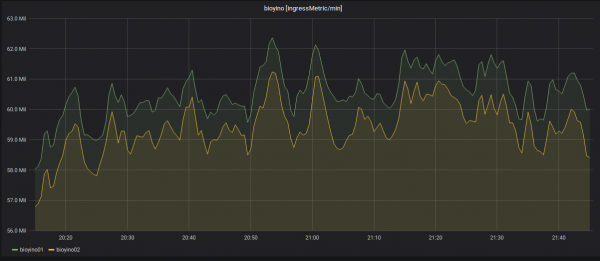
Az egyik csomópont letiltása és a bejövő metrikák újraelosztása.
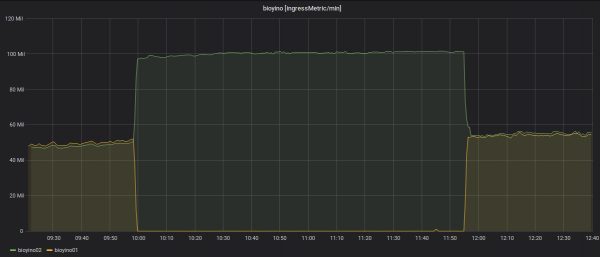
Kimenő metrikák statisztikái: csak egy csomópont küld – a raidfőnök.
Az egyes csomópontok működésének statisztikái, figyelembe véve a különböző rendszermodulokban előforduló hibákat.
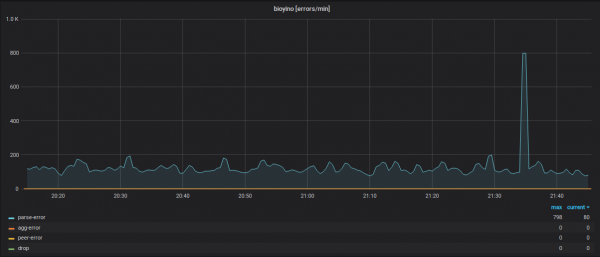
A bejövő metrikák részletei (a metrikák nevei rejtve vannak).
Mit tervezünk ezután csinálni mindezzel? Természetesen kibaszott kódot írni! A projektet eredetileg nyílt forráskódúnak tervezték, és az is marad élete végéig. A közvetlen terveink között szerepel a saját Raft verzióra való váltás, a peer protokoll hordozhatóbbra cserélése, további belső statisztikák hozzáadása, új metrikatípusok, hibajavítások és egyéb fejlesztések.
Természetesen bárkit szívesen látunk, aki hajlandó segíteni a projekt fejlesztésében: írjon PR-eket, problémákat, és mi lehetőség szerint válaszolunk rájuk, fejlesztjük őket stb.
Ennyi az egész, ahogy mondani szokás, vegyétek meg az elefántjainkat!

Forrás: will.com
