


Hogyan érti meg egy háttérfejlesztő, hogy egy SQL-lekérdezés jól fog működni „terméken”? A nagy vagy gyorsan növekvő cégeknél nem mindenki fér hozzá a "termékhez". A hozzáféréssel pedig nem minden kérést lehet fájdalommentesen ellenőrizni, és az adatbázis másolatának elkészítése gyakran órákat vesz igénybe. E problémák megoldására létrehoztunk egy mesterséges DBA-t - Joe. Több cégnél sikeresen bevezették már, és több mint egy tucat fejlesztőnek nyújt segítséget.
videók:

Sziasztok! A nevem Anatolij Stansler. Egy cégnél dolgozom . Elkötelezettek vagyunk a fejlesztési folyamat felgyorsítása mellett azáltal, hogy megszüntetjük a Postgres munkájával összefüggő késéseket a fejlesztők, DBA-k és QA-k elől.
Nagyszerű ügyfeleink vannak, és ma a jelentés egy részét azoknak az eseteknek szentelik, amelyekkel a velük való munka során találkoztunk. Beszélni fogok arról, hogyan segítettünk nekik megoldani az egészen komoly problémákat.

Amikor komplex, nagy terhelésű migrációkat fejlesztünk és végzünk, feltesszük magunknak a kérdést: „Elindul ez a migráció?”. Felülvizsgáljuk, tapasztaltabb kollégák, DBA szakértők tudását használjuk. És meg tudják mondani, hogy repül-e vagy sem.
De talán jobb lenne, ha magunk is kipróbálhatnánk teljes méretű másolatokon. Ma pedig csak arról fogunk beszélni, hogy milyen megközelítések léteznek a teszteléshez, és hogyan lehet ezt jobban megtenni, és milyen eszközökkel. Szó lesz még az ilyen megközelítések előnyeiről és hátrányairól, valamint arról, hogy mit tudunk itt javítani.
Ki készített már indexeket közvetlenül a terméken, vagy végzett bármilyen változtatást? Elég kevés. És ez kinek vezetett oda, hogy adatvesztés vagy leállás volt? Akkor ismered ezt a fájdalmat. Hála Istennek, vannak tartalékok.

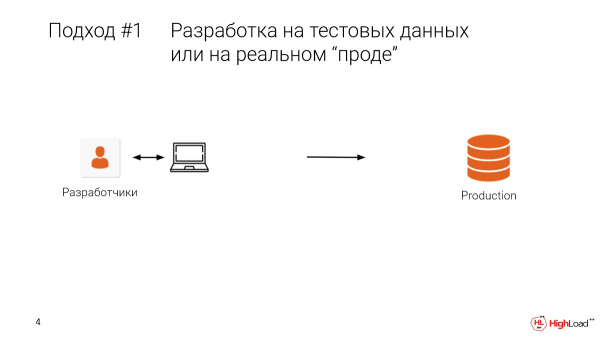
Az első megközelítés a prod-ban történő tesztelés. Illetve, ha egy fejlesztő egy helyi gépen ül, tesztadatokkal rendelkezik, van valami korlátozott választék. És kigurulunk a prod-ba, és megkapjuk ezt a helyzetet.

Fáj, drága. Talán jobb, ha nem.
És mi a legjobb módja ennek?
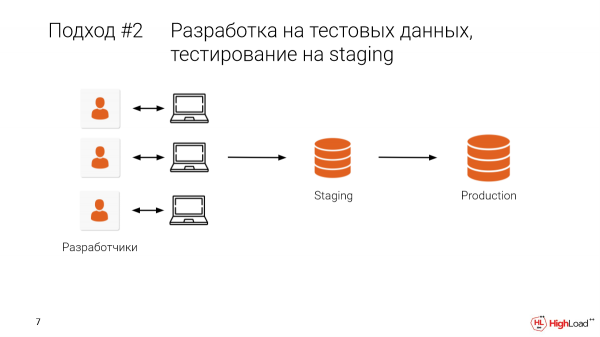
Vegyük a színpadra állítást, és ott válasszuk ki a prod egy részét. Vagy a legjobb esetben vegyünk egy igazi prod-ot, az összes adatot. És miután helyben kifejlesztettük, emellett ellenőrizni fogjuk a színpadra állítást.
Ez lehetővé teszi számunkra, hogy eltávolítsunk néhány hibát, azaz megakadályozzuk, hogy gyártási állapotban legyenek.
Mik a problémák?
- A probléma az, hogy megosztjuk ezt az előadást a kollégákkal. És nagyon gyakran megtörténik, hogy valamiféle változtatást hajt végre, bam - és nincs adat, a munka lefolyik. A rendezés több terabájtos volt. És sokáig kell várni, hogy újra felemelkedjen. És úgy döntünk, hogy holnap véglegesítjük. Ennyi, van fejleményünk.
- És persze sok kolléga dolgozik ott, sok csapat. És ezt kézzel kell megtenni. És ez kényelmetlen.

És érdemes elmondani, hogy csak egy próbálkozásunk van, egy lövésünk van, ha az adatbázison szeretnénk néhány változtatást végrehajtani, érintsük meg az adatokat, módosítsuk a szerkezetet. És ha valami elromlott, ha hiba történt a migrációban, akkor nem fogunk gyorsan visszalépni.
Ez jobb, mint az előző megközelítés, de továbbra is nagy a valószínűsége annak, hogy valamilyen hiba kerül a gyártásba.
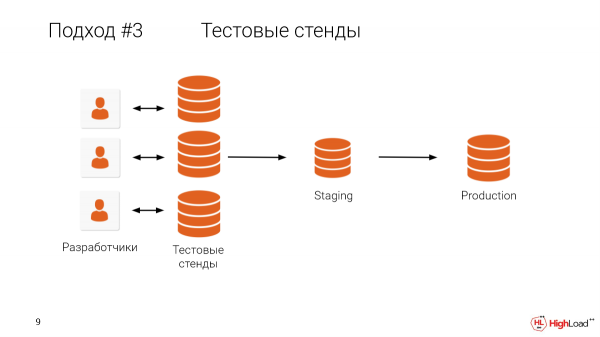
Mi akadályoz meg bennünket abban, hogy minden fejlesztőnek adjunk egy tesztpadot, egy teljes méretű példányt? Szerintem egyértelmű, hogy mi áll az útjában.
Kinek van egy terabájtnál nagyobb adatbázisa? A szoba több mint fele.
És nyilvánvaló, hogy a gépek tartása az egyes fejlesztők számára, amikor ilyen nagy a termelés, nagyon drága, ráadásul sok időt vesz igénybe.
Vannak ügyfeleink, akik felismerték, hogy nagyon fontos, hogy minden változást teljes méretű másolatokon teszteljenek, de adatbázisuk egy terabájtnál kevesebb, és nincs erőforrás minden fejlesztő számára tesztpadot tartani. Ezért a dumpokat helyben kell letölteniük a gépükre, és ilyen módon kell tesztelniük. Sok időbe telik.

Még ha az infrastruktúrán belül csinálod is, óránként egy terabájt adat letöltése már nagyon jó. De logikai dumpokat használnak, helyben töltenek le a felhőből. Náluk a sebesség körülbelül 200 gigabájt/óra. És még időbe telik, mire a logikai dumpból kifordulni, felgöngyölíteni az indexeket stb.
De ezt a megközelítést alkalmazzák, mert ez lehetővé teszi számukra, hogy megbízhatóan tartsák a terméket.
Mit tehetünk itt? Tegyük olcsóbbá a tesztágyakat, és adjunk minden fejlesztőnek saját tesztágyat.
És ez lehetséges.
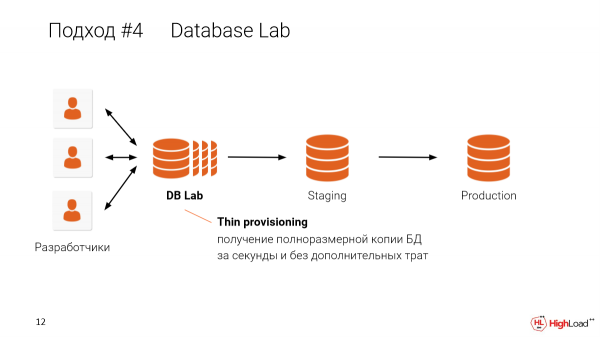
És ebben a megközelítésben, amikor vékony klónokat készítünk minden fejlesztő számára, megoszthatjuk egy gépen. Például, ha van egy 10 TB-os adatbázisa, és 10 fejlesztőnek szeretné átadni, akkor nincs szükség XNUMX x XNUMX TB-os adatbázisra. Csak egy gépre van szüksége ahhoz, hogy vékony, elszigetelt másolatokat készítsen minden egyes előhívóról egy géppel. Kicsit később elmondom, hogyan működik.

Valódi példa:
DB - 4,5 terabájt.
30 másodperc alatt kaphatunk független másolatokat.
Nem kell várnia a próbapadra, és attól függ, hogy mekkora. Másodpercek alatt megkaphatja. Teljesen elszigetelt környezetek lesznek, de megosztják egymással az adatokat.
Ez nagyszerű. Itt a mágiáról és egy párhuzamos univerzumról beszélünk.

Esetünkben ez OpenZFS rendszerrel működik.

Az OpenZFS egy másolás írásra fájlrendszer, amely támogatja a pillanatfelvételeket és a klónozást. Megbízható és skálázható. Nagyon könnyen kezelhető. Szó szerint két csapatban is bevethető.
Vannak más lehetőségek is:
lvm,
Tárolás (például Pure Storage).
A Database Lab, amiről beszélek, moduláris. Ezekkel az opciókkal megvalósítható. De most az OpenZFS-re koncentráltunk, mert konkrétan az LVM-mel voltak problémák.
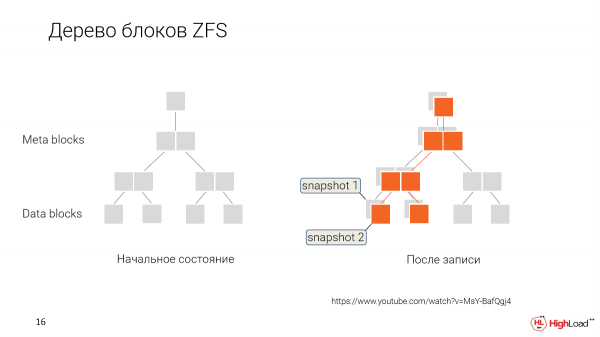
Hogyan működik? Ahelyett, hogy minden módosításkor felülírnánk az adatokat, egyszerűen csak megjelöljük, hogy ez az új adat egy új időpontból, új pillanatképből származik.
És a jövőben, amikor vissza akarjuk állítani, vagy új klónt akarunk készíteni valamelyik régebbi verzióból, csak azt mondjuk: "OK, add meg nekünk ezeket az így megjelölt adatblokkokat."
És ez a felhasználó egy ilyen adatkészlettel fog dolgozni. Fokozatosan megváltoztatja őket, saját pillanatfelvételeket készít.
És elágazunk. Esetünkben minden fejlesztőnek lehetősége lesz saját klónjára, amelyet szerkeszt, és a megosztott adatokat mindenki megosztja.
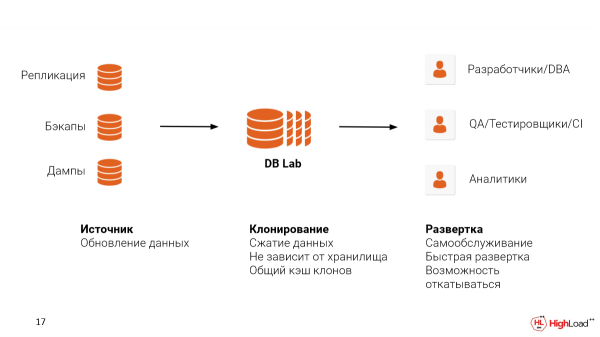
Egy ilyen rendszer otthoni telepítéséhez két problémát kell megoldania:
Az első az adatok forrása, honnan veszi azokat. A replikációt a termeléssel is beállíthatja. Remélem, már használhatja a beállított biztonsági másolatokat. WAL-E, WAL-G vagy Barman. És még akkor is, ha valamilyen felhőmegoldást, például RDS-t vagy Cloud SQL-t használ, használhat logikai dumpokat. De továbbra is azt tanácsoljuk, hogy használjon biztonsági másolatot, mert ezzel a megközelítéssel megőrzi a fájlok fizikai szerkezetét is, ami lehetővé teszi, hogy még közelebb kerüljön azokhoz a mérőszámokhoz, amelyeket az éles folyamatban látna, hogy elkapja a meglévő problémákat.
A második az, ahol az adatbázis-labort kívánja tárolni. Lehet Cloud, lehet On-premise. Itt fontos elmondani, hogy a ZFS támogatja az adattömörítést. És egész jól csinálja.
Képzeld el, hogy minden ilyen klónhoz, attól függően, hogy milyen műveleteket végzünk az alappal, valamiféle fejlesztő fog növekedni. Ehhez a fejlesztőnek is kell hely. De mivel 4,5 terabájtos alapot vettünk, a ZFS 3,5 terabájtra tömöríti. Ez a beállításoktól függően változhat. És még van helyünk a fejlesztőknek.
Egy ilyen rendszer különböző esetekben használható.
Ezek fejlesztők, DBA-k a lekérdezés ellenőrzésére, optimalizálásra.
Ez felhasználható a minőségbiztosítási tesztelés során egy adott áttelepítés tesztelésére, mielőtt gyártási verzióra terjesztenénk ki. Valós adatokkal pedig speciális környezeteket is emelhetünk a minőségbiztosításhoz, ahol új funkcionalitást tesztelhetnek. És a várakozási órák helyett másodpercekbe telik, és néhány más esetben akár napokba is beletelik, amikor nem használnak vékony másolatokat.
És egy másik eset. Ha a cégnél nincs beépített analitikai rendszer, akkor a termékbázis egy vékony klónját elkülöníthetjük, és hosszú lekérdezésekhez vagy speciális, az analitikában használható indexekhez adhatjuk.

Ezzel a megközelítéssel:
Alacsony a hiba valószínűsége a "terméken", mert az összes változást teljes méretű adatokon teszteltük.
Nálunk a tesztelés kultúrája van, mert most már nem kell órákat várnia a saját standjára.
És nincs akadály, nincs várakozás a tesztek között. Tényleg elmehetsz és ellenőrizheted. És jobb lesz így, ahogy felgyorsítjuk a fejlesztést.
Kevesebb lesz az átalakítás. Kevesebb hiba kerül a prod-ba. Később kevésbé fogjuk utólagos refaktorálni őket.
Visszafordíthatjuk a visszafordíthatatlan változásokat. Ez nem a szokásos megközelítés.
- Ez előnyös, mert megosztjuk a próbapadok erőforrásait.
Már jó, de mit lehetne még gyorsítani?

Egy ilyen rendszernek köszönhetően jelentősen csökkenthetjük az ilyen tesztelésbe való belépés küszöbét.
Most van egy ördögi kör, ahol a fejlesztőnek szakértővé kell válnia ahhoz, hogy valódi, teljes méretű adatokhoz férhessen hozzá. Ezt a hozzáférést rá kell bízni.
De hogyan lehet nőni, ha nincs ott. De mi van akkor, ha csak nagyon kis számú tesztadat áll a rendelkezésére? Akkor nem lesz igazi élmény.
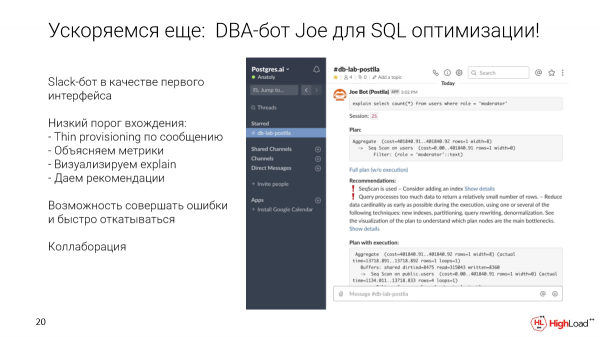
Hogyan lehet kilépni ebből a körből? Első interfészként, amely bármilyen szintű fejlesztő számára kényelmes, a Slack botot választottuk. De lehet bármilyen más interfész.
Mit tesz lehetővé? Elfogadhat egy adott lekérdezést, és elküldheti egy speciális csatornára az adatbázis számára. Másodperceken belül automatikusan telepítünk egy vékony klónt. Futtassuk ezt a kérést. Mérőket és ajánlásokat gyűjtünk. Mutassunk egy vizualizációt. És akkor ez a klón marad, hogy ezt a lekérdezést valahogy optimalizálni lehessen, indexeket hozzáadni stb.
És a Slack is lehetőséget ad nekünk az együttműködésre. Mivel ez csak egy csatorna, elkezdheti megvitatni ezt a kérést ott, az ilyen kérés szálában, pingelni a kollégáit, a vállalaton belüli DBA-kat.

De természetesen vannak problémák. Mivel ez a valós világ, és egy kiszolgálót használunk, amely egyszerre több klónnak ad otthont, tömörítenünk kell a klónok rendelkezésére álló memória és CPU-teljesítmény mennyiségét.
De ahhoz, hogy ezek a tesztek hihetőek legyenek, valahogyan meg kell oldania ezt a problémát.
Nyilvánvaló, hogy a fontos pont ugyanazok az adatok. De már megvan. És ugyanazt a konfigurációt szeretnénk elérni. És egy ilyen majdnem azonos konfigurációt tudunk adni.
Jó lenne, ha ugyanaz a hardver lenne, mint a gyártásban, de ez eltérhet.
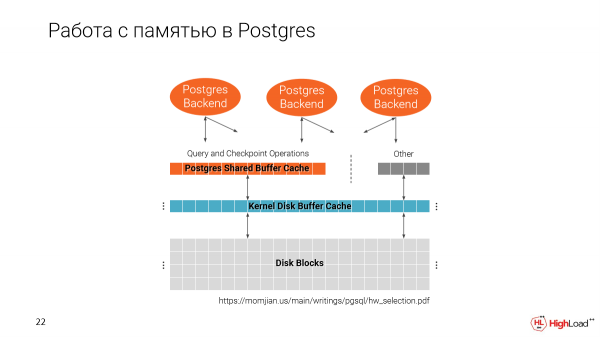
Emlékezzünk arra, hogyan működik a Postgres a memóriával. Két gyorsítótárunk van. Egy a fájlrendszerből és egy natív Postgres, azaz megosztott puffergyorsítótár.
Fontos megjegyezni, hogy a megosztott puffergyorsítótár a Postgres indulásakor kerül lefoglalásra, attól függően, hogy milyen méretet adott meg a konfigurációban.
A második gyorsítótár pedig az összes rendelkezésre álló helyet felhasználja.
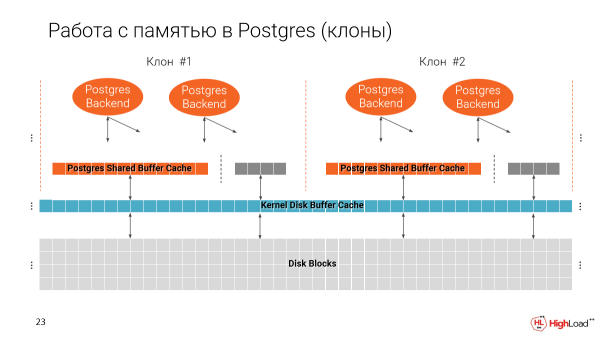
És amikor több klónt készítünk egy gépen, kiderül, hogy fokozatosan feltöltjük a memóriát. És jó értelemben a Shared Buffer Cache a gépen rendelkezésre álló teljes memória 25%-a.
És kiderül, hogy ha nem változtatjuk meg ezt a paramétert, akkor egy gépen csak 4 példányt tudunk futtatni, azaz összesen 4 ilyen vékony klónt. És ez persze rossz, mert szeretnénk, hogy sokkal több legyen belőlük.
De másrészt a Buffer Cache az indexek lekérdezésének végrehajtására szolgál, vagyis a terv attól függ, hogy mekkora a gyorsítótárunk. És ha csak ezt a paramétert vesszük és csökkentjük, akkor a terveink sokat változhatnak.
Például, ha nagy gyorsítótárunk van a prod-on, akkor a Postgres inkább indexet használ. És ha nem, akkor lesz SeqScan. És mi értelme lenne, ha a terveink nem esnének egybe?
De itt arra a következtetésre jutunk, hogy valójában a Postgres-i terv nem a tervben szereplő Shared Bufferben megadott konkrét mérettől, hanem a hatékony_cache_size-től függ.

Az Effective_cache_size a rendelkezésünkre álló gyorsítótár becsült mennyisége, azaz a puffergyorsítótár és a fájlrendszer gyorsítótárának összege. Ezt a konfig állítja be. És ez a memória nincs lefoglalva.
És ennek a paraméternek köszönhetően becsaphatjuk Postgrest, mondván, hogy valójában nagyon sok adat áll rendelkezésünkre, még akkor is, ha ezek az adatok nincsenek. Így a tervek teljesen egybeesnek majd a gyártással.
De ez befolyásolhatja az időzítést. A lekérdezéseket pedig időzítéssel optimalizáljuk, de fontos, hogy az időzítés sok tényezőtől függ:
Ez az aktuális terheléstől függ.
Ez magának a gépnek a jellemzőitől függ.
És ez egy közvetett paraméter, de valójában pontosan a lekérdezés által beolvasott adatok mennyiségével tudjuk optimalizálni, hogy megkapjuk az eredményt.
És ha azt szeretné, hogy az időzítés közel legyen ahhoz, amit prod-ban fogunk látni, akkor a leginkább hasonló hardvert kell vennünk, és lehetőleg még többet, hogy az összes klón elférjen. De ez egy kompromisszum, azaz ugyanazokat a terveket kapod, látni fogod, hogy egy adott lekérdezés mennyi adatot fog olvasni, és arra következtethetsz, hogy ez a lekérdezés jó (vagy migráció) vagy rossz, még optimalizálni kell .
Nézzük meg, hogyan optimalizálták Joe-t.
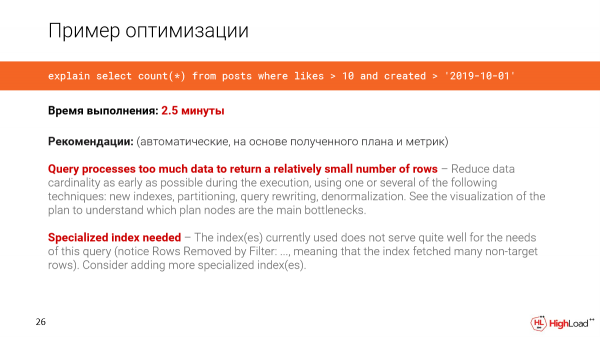
Vegyünk egy kérést egy valós rendszertől. Ebben az esetben az adatbázis 1 terabájt. És meg akarjuk számolni azokat a friss bejegyzéseket, amelyek több mint 10 like-ot kaptak.
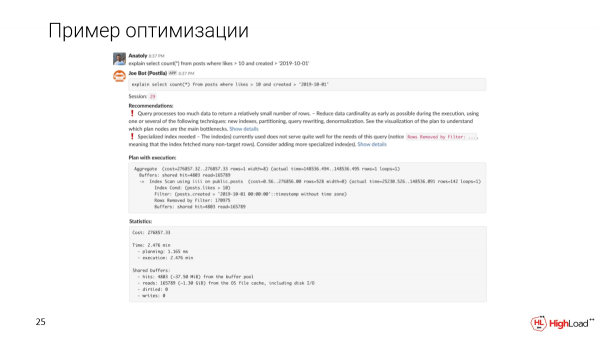
Üzenetet írunk a csatornának, egy klónt telepítettek számunkra. És látni fogjuk, hogy egy ilyen kérés 2,5 perc alatt teljesül. Ez az első dolog, amit észreveszünk.
B Joe a terv és a mutatók alapján automatikus ajánlásokat fog mutatni.
Látni fogjuk, hogy a lekérdezés túl sok adatot dolgoz fel ahhoz, hogy viszonylag kis számú sort kapjon. Valamilyen speciális indexre pedig szükség van, mivel észrevettük, hogy túl sok szűrt sor van a lekérdezésben.
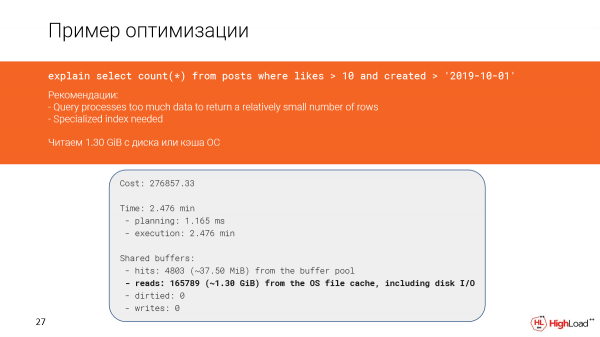
Nézzük meg közelebbről a történteket. Valóban azt látjuk, hogy majdnem másfél gigabájtnyi adatot olvastunk ki a fájlgyorsítótárból vagy akár a lemezről. És ez nem jó, mert csak 142 sort kaptunk.
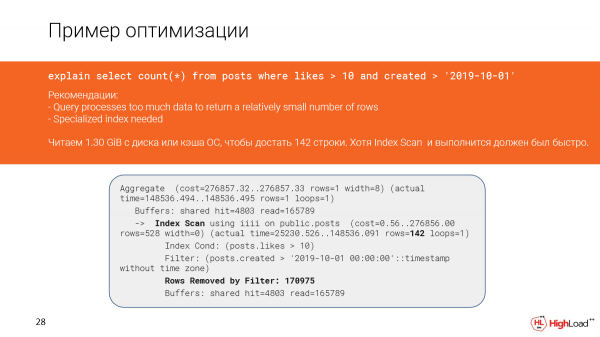
És úgy tűnik, itt van egy indexvizsgálat, és gyorsan kellett volna, de mivel túl sok sort szűrtünk ki (meg kellett számolnunk), a lekérdezés lassan sikerült.
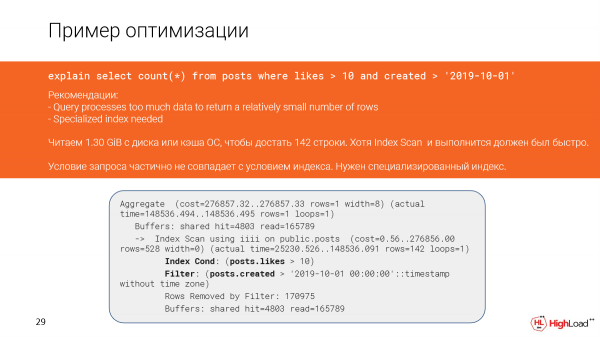
És ez azért történt a tervben, mert a lekérdezés feltételei részben nem egyeznek az indexben.
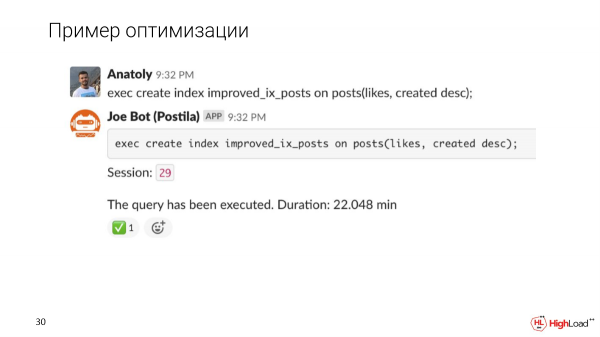
Próbáljuk meg pontosítani az indexet, és nézzük meg, hogyan változik ezután a lekérdezés végrehajtása.
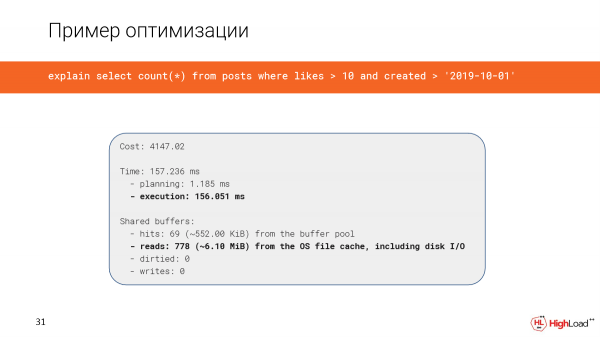
Az index létrehozása meglehetősen sokáig tartott, de most megnézzük a lekérdezést, és azt látjuk, hogy az idő 2,5 perc helyett csak 156 ezredmásodperc, ami elég jó. És csak 6 megabájt adatot olvasunk.
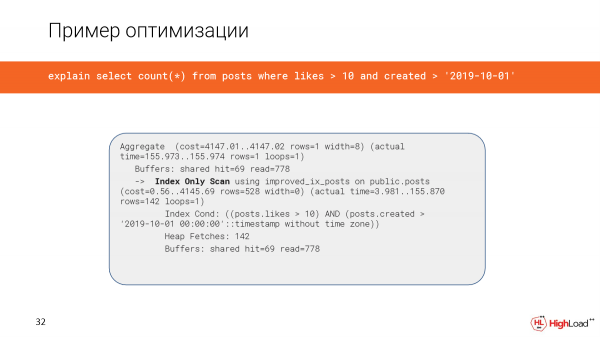
És most csak indexvizsgálatot használunk.
A másik fontos történet, hogy a tervet valamivel érthetőbben szeretnénk bemutatni. A Flame Graphs segítségével valósítottuk meg a vizualizációt.
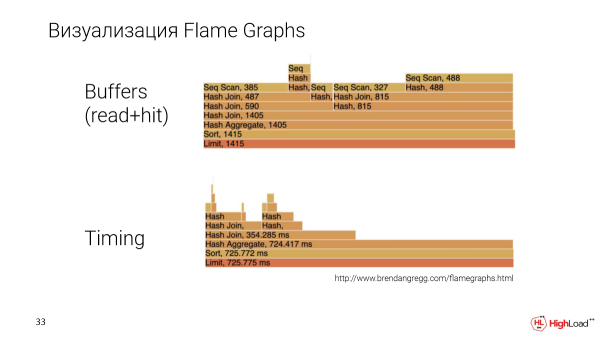
Ez egy másik kérés, intenzívebb. A Flame Graphokat pedig két paraméter szerint építjük: ennyi adatmennyiséget számolt egy adott csomópont a tervben és az időzítésben, vagyis a csomópont végrehajtási ideje.
Itt össze tudjuk hasonlítani az egyes csomópontokat egymással. És világos lesz, hogy melyiküknek kell több vagy kevesebb, ami más renderelési módszereknél általában nehéz.
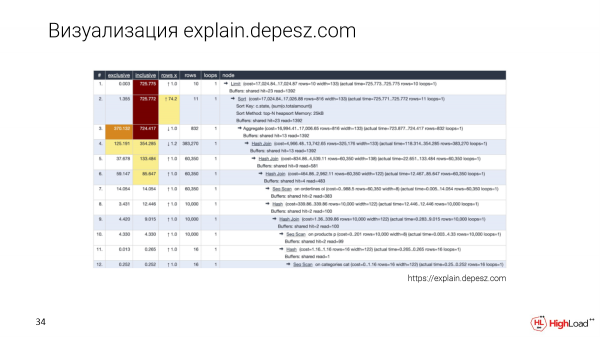
Persze mindenki tudja, hogy magyarázza.depesz.com. Ennek a vizualizációnak az a jó tulajdonsága, hogy elmentjük a szöveges tervet, és néhány alapvető paramétert is táblázatba helyezünk, hogy rendezni tudjuk.
Azok a fejlesztők pedig, akik még nem mélyedtek el ebbe a témába, szintén a magyarázat.depesz.com oldalt használják, mert így könnyebben kitalálják, melyik mérőszám fontos és melyik nem.
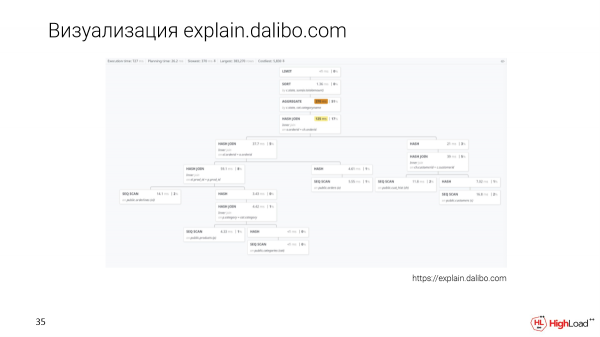
A vizualizációnak új megközelítése van – ez a magyarázat.dalibo.com. Favizualizációt végeznek, de nagyon nehéz összehasonlítani a csomópontokat egymással. Itt jól érthető a szerkezet, de ha nagy kérés van, akkor oda-vissza kell görgetni, de egy lehetőség is.
együttműködés
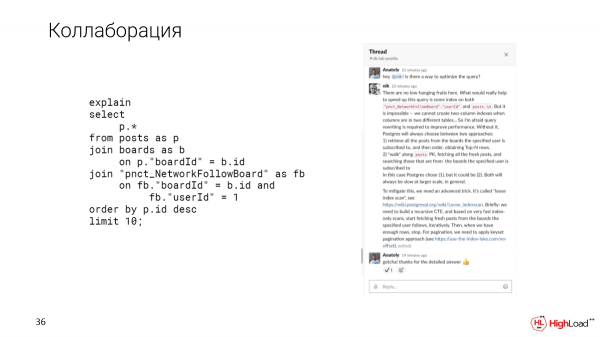
És ahogy mondtam, a Slack lehetőséget ad az együttműködésre. Például, ha olyan összetett lekérdezéssel találkozunk, amely nem világos, hogyan kell optimalizálni, a problémát kollégáinkkal tisztázhatjuk a Slack egyik szálában.

Számunkra úgy tűnik, hogy fontos a teljes méretű adatokon történő tesztelés. Ennek érdekében elkészítettük az Update Database Lab eszközt, amely nyílt forráskódú. Használhatja a Joe botot is. Most azonnal átveheti és megvalósíthatja a helyén. Ott minden útmutató elérhető.
Azt is fontos megjegyezni, hogy maga a megoldás nem forradalmi, mert van Delphix, de ez egy vállalati megoldás. Teljesen zárt, nagyon drága. Kifejezetten a Postgres-re szakosodtunk. Ezek mind nyílt forráskódú termékek. Csatlakozz hozzánk!
Itt végzek. Köszönöm!
kérdések
Helló! Köszönöm a beszámolót! Nagyon érdekes, különösen számomra, mert valamikor régen megoldottam ugyanezt a problémát. És ezért van egy sor kérdésem. Remélem, legalább egy részét megkapom.
Kíváncsi vagyok, hogyan számítja ki ennek a környezetnek a helyét? A technológia azt jelenti, hogy bizonyos körülmények között klónjai a maximális méretre nőhetnek. Durván szólva, ha van egy tíz terabájtos adatbázisunk és 10 klónunk, akkor könnyen szimulálhatunk egy olyan helyzetet, amikor minden klón 10 egyedi adatot nyom. Hogyan számítja ki ezt a helyet, vagyis azt a deltát, amelyről beszélt, és ahol ezek a klónok élni fognak?
Jó kérdés. Itt fontos nyomon követni az egyes klónokat. És ha egy klón túl nagy változáson megy keresztül, elkezd növekedni, akkor erről először figyelmeztethetjük a felhasználót, vagy azonnal leállíthatjuk a klónt, hogy ne legyen hiba.
Igen, van egy beágyazott kérdésem. Vagyis hogyan biztosítja ezeknek a moduloknak az életciklusát? Van ez a probléma, és egy teljesen külön történet. Hogyan történik ez?
Minden klónhoz tartozik néhány ttl. Alapvetően van egy fix ttl.
Mi van, ha nem titok?
1 óra, azaz üresjárat - 1 óra. Ha nem használjuk, akkor dörzsöljük. De nincs itt semmi meglepetés, hiszen másodpercek alatt fel tudjuk emelni a klónt. És ha újra szüksége van rá, akkor kérem.
A technológiák választása is érdekel, mert például több módszert is alkalmazunk párhuzamosan ilyen-olyan okból. Miért a ZFS? Miért nem LVM-et használtál? Említetted, hogy problémák vannak az LVM-mel. Mik voltak a problémák? Szerintem a legoptimálisabb megoldás a tárolással, teljesítmény szempontjából.
Mi a fő probléma a ZFS-sel? Az a tény, hogy ugyanazon a gazdagépen kell futnia, azaz minden példány ugyanazon az operációs rendszeren belül fog élni. Tárolás esetén pedig különféle berendezéseket csatlakoztathat. A szűk keresztmetszetet pedig csak azok a blokkok jelentik, amelyek a tárolórendszeren vannak. A technológiák kiválasztásának kérdése pedig érdekes. Miért nem LVM?
Az LVM-et konkrétan megbeszélhetjük a találkozón. Ami a tárolást illeti, az csak drága. A ZFS-t bárhová telepíthetjük. Telepítheted a saját gépedre. Egyszerűen letöltheted a tárolót és telepítheted. A ZFS szinte bárhová telepíthető, ha már a következőkről beszélünk... Linux Erről beszélünk. Tehát egy nagyon rugalmas megoldást kapunk. És maga a ZFS is rengeteget kínál alapból. Annyi adatot tölthetsz bele, amennyit csak akarsz, nagyszámú lemezt csatlakoztathatsz hozzá, és pillanatképeket is készít. És, ahogy már mondtam, könnyen kezelhető. Szóval, nagyon kellemesnek tűnik használni. Bizonyított, már évek óta létezik. Nagyon nagy közössége van, ami folyamatosan növekszik. A ZFS egy nagyon megbízható megoldás.
Nikolai Samokhvalov: Hozzászólhatok még? A nevem Nikolay, együtt dolgozunk Anatolijjal. Egyetértek azzal, hogy a tárolás nagyszerű. És néhány ügyfelünknek van Pure Storage stb.
Anatolij helyesen megjegyezte, hogy mi a modularitásra összpontosítunk. És a jövőben megvalósíthat egy interfészt - pillanatfelvételt készíthet, klónt készíthet, megsemmisítheti a klónt. Minden könnyű. A tárolás pedig klassz, ha van.
De a ZFS mindenki számára elérhető. A DelPhix már elég, 300 ügyfelük van. Ebből a fortune 100-nak 50 kliense van, vagyis a NASA-t célozzák meg stb.. Itt az ideje, hogy mindenki megszerezze ezt a technológiát. És ezért van egy nyílt forráskódú Core-unk. Van egy felületrészünk, amely nem nyílt forráskódú. Ez az a platform, amelyet megmutatunk. De azt szeretnénk, hogy mindenki számára elérhető legyen. Forradalmat akarunk csinálni, hogy minden tesztelő ne találgasson a laptopokkal kapcsolatban. Meg kell írnunk a SELECT-et, és azonnal látjuk, hogy lassú. Ne várj arra, hogy a DBA elmondja neked. Itt van a fő cél. És azt hiszem, hogy mindannyian eljutunk idáig. És ezt mindenki számára elkészítjük. Ezért a ZFS, mert mindenhol elérhető lesz. Köszönet a közösségnek a problémák megoldásáért és azért, hogy van nyílt forráskódú licenc stb. *
Üdvözlet! Köszönöm a beszámolót! A nevem Maxim. Ugyanazokkal a kérdésekkel foglalkoztunk. Egyedül döntöttek. Hogyan osztod meg az erőforrásokat a klónok között? Minden klón bármikor megteheti a saját dolgait: az egyik egyet tesztel, a másik a másikat, valaki indexet épít, valakinek nehéz munkája van. És ha továbbra is lehet osztani CPU-val, akkor IO-val, hogyan kell osztani? Ez az első kérdés.
A második kérdés pedig a lelátók különbözőségére vonatkozik. Tegyük fel, hogy itt van ZFS és minden menő, de a prod-on lévő kliensben nem ZFS van, hanem pl ext4. Hogyan ebben az esetben?
Nagyon jók a kérdések. Kicsit említettem ezt a problémát azzal a ténnyel, hogy megosztjuk az erőforrásokat. A megoldás pedig ez. Képzeld el, hogy a színpadon tesztelsz. Egyszerre előfordulhat olyan helyzet is, hogy valaki egy terhelést ad, valaki mást. Ennek eredményeként érthetetlen mutatókat lát. Még a prod esetében is előfordulhat ugyanez a probléma. Amikor ellenőrizni akarunk valamilyen kérést és látni, hogy valami probléma van vele - lassan működik, akkor valójában nem a kérésben volt a probléma, hanem abban, hogy van valami párhuzamos terhelés.
És ezért itt fontos arra összpontosítani, hogy mi lesz a terv, milyen lépéseket teszünk a tervben, és mennyi adatot gyűjtünk ehhez. Az, hogy például a lemezeinket feltöltik valamivel, az kifejezetten befolyásolja az időzítést. De meg tudjuk becsülni, hogy ez a kérés mennyire terhelt az adatmennyiség alapján. Nem annyira fontos, hogy ugyanakkor valamiféle végrehajtás is legyen.
Két kérdésem van. Ez nagyon klassz cucc. Voltak olyan esetek, amikor a gyártási adatok, például a hitelkártyaszámok kritikusak? Kész van már valami vagy ez egy külön feladat? És a második kérdés: létezik-e ilyesmi a MySQL-hez?
Az adatokról. Addig csináljuk az elhomályosítást, amíg meg nem tesszük. De ha pontosan Joe-t telepíti, ha nem ad hozzáférést a fejlesztőknek, akkor nem fér hozzá az adatokhoz. Miért? Mert Joe nem mutat adatokat. Csak mutatókat, terveket mutat, és ennyi. Ezt szándékosan tették, mert ez ügyfelünk egyik követelménye. Azt akarták, hogy anélkül optimalizálhassák, hogy mindenkinek hozzáférést adnának.
A MySQL-ről. Ez a rendszer bármire használható, ami az állapotot lemezen tárolja. És mivel mi csináljuk a Postgres-t, most először a Postgres automatizálását végezzük el. Automatizálni akarjuk a biztonsági mentésből származó adatok lekérését. A Postgrest megfelelően konfiguráljuk. Tudjuk, hogyan kell összeegyeztetni a terveket stb.
De mivel a rendszer bővíthető, MySQL-hez is használható. És vannak ilyen példák. A Yandexnek van hasonló, de nem teszik közzé sehol. A Yandex.Metricán belül használják. És csak egy történet a MySQL-ről. De a technológiák ugyanazok, ZFS.
Köszönöm a beszámolót! Nekem is lenne egy-két kérdésem. Említetted, hogy a klónozás felhasználható elemzésre, például további indexek építésére. Mesélnél egy kicsit bővebben a működéséről?
És rögtön felteszem a második kérdést a lelátók hasonlóságáról, a tervek hasonlóságáról. A terv a Postgres által gyűjtött statisztikáktól is függ. Hogyan oldja meg ezt a problémát?
Az elemzések szerint konkrét esetek nincsenek, mert még nem éltünk vele, de van ilyen lehetőség. Ha indexekről beszélünk, akkor képzeljük el, hogy egy lekérdezés egy több száz millió rekordot tartalmazó táblát üldöz, és egy oszlopot, amelyet általában nem indexelnek prod-ban. És ott szeretnénk néhány adatot kiszámítani. Ha ez a kérés prod-on fut, akkor lehetséges, hogy prod-on egyszerű lesz, mert ott egy percig feldolgozzák a kérést.
Rendben, készítsünk egy vékony klónt, amelyet nem szörnyű néhány percre megállítani. És annak érdekében, hogy kényelmesebb legyen az elemzések elolvasása, indexeket adunk azokhoz az oszlopokhoz, amelyekben az adatok érdekelnek.
Az index minden alkalommal létrejön?
Csinálhatod úgy, hogy érintsük meg az adatokat, készítsünk pillanatfelvételeket, majd ebből a pillanatképből helyreállunk, és új kéréseket hajtunk végre. Azaz elkészítheted úgy, hogy új klónokat nevelhess már felragasztott indexekkel.
Ami a statisztikával kapcsolatos kérdést illeti, ha biztonsági másolatból állítunk vissza, ha replikációt végzünk, akkor a statisztikánk pontosan ugyanaz lesz. Ugyanis a teljes fizikai adatstruktúra megvan, vagyis az adatokat úgy hozzuk, ahogy vannak az összes statisztikai mérőszámmal együtt.
Itt van egy másik probléma. Ha felhős megoldást használsz, akkor ott csak logikai dumpok érhetők el, mert a Google, Amazon nem engedi, hogy fizikai másolatot készíts. Probléma lesz.
Köszönöm a prezentációt. Két jó kérdés merült fel a MySQL-lel és az erőforrás-megosztással kapcsolatban. De lényegében az egész arról szól, hogy ez nem az egyes adatbázis-kezelő rendszerek témája, hanem az egész fájlrendszeré. És ennek megfelelően az erőforrás-megosztási problémákat is onnan kell kezelni, nem csak a Postgresben, hanem magában a fájlrendszerben is. szerver, például.
A kérdésem kicsit más. Ez közelebb áll a többrétegű adatbázishoz, ahol több réteg van. Például beállítunk egy tíz terabájtos képfrissítést, replikálunk. Ezt a megoldást pedig kifejezetten adatbázisokhoz használjuk. A replikáció folyamatban van, az adatok frissítése folyamatban van. Itt párhuzamosan 100 alkalmazott dolgozik, akik folyamatosan indítják ezeket a különböző felvételeket. Mit kell tenni? Hogyan lehet meggyőződni arról, hogy nincs konfliktus, elindítottak egyet, majd megváltozott a fájlrendszer, és ezek a képek mind mentek?
Nem mennek, mert így működik a ZFS. Külön egy szálban tarthatjuk a replikáció miatti fájlrendszer-változásokat. És tartsa meg a fejlesztők által használt klónokat az adatok régebbi verzióiban. És nálunk működik, ezzel minden rendben van.
Kiderült, hogy a frissítés plusz rétegként fog megtörténni, és már minden új kép megy, ez a réteg alapján, nem?
Az előző rétegekből, amelyek korábbi replikációkból származtak.
Az előző rétegek leesnek, de a régi rétegre fognak hivatkozni, és a frissítésben érkezett utolsó rétegről fognak új képeket venni?
Általában igen.
Akkor ennek következtében akár egy fignyi rétegünk lesz. És idővel össze kell őket tömöríteni?
Igen minden helyes. Van egy ablak. Hetente készítünk pillanatfelvételeket. Attól függ, milyen erőforrással rendelkezik. Ha sok adatot képes tárolni, akkor a pillanatképeket hosszú ideig tárolhatja. Nem mennek el maguktól. Nem lesz adatsérülés. Ha a pillanatképek elavultak, ahogy nekünk tűnik, vagyis a cég szabályzatától függ, akkor egyszerűen törölhetjük őket, és helyet szabadíthatunk fel.
Sziasztok! Köszönjük a beszámolót! Kérdés Joe-val kapcsolatban. Azt mondta, hogy az ügyfél nem akart mindenkinek hozzáférést adni az adatokhoz. Szigorúan véve, ha valaki rendelkezik az Explain Analyze eredményével, akkor le tudja nézni az adatokat.
Ez olyan. Például írhatjuk: "SELECT FROM WHERE email = arra". Vagyis magát az adatot nem fogjuk látni, de néhány közvetett jelet láthatunk. Ezt meg kell érteni. De másrészt minden megvan. Nálunk van a naplók auditálása, a többi kollégánk ellenőrzése, akik szintén látják, mit csinálnak a fejlesztők. És ha valaki megpróbálja ezt megtenni, akkor a biztonsági szolgálat eljön hozzá, és foglalkozik ezzel a kérdéssel.
Jó napot Köszönöm a beszámolót! Lenne egy rövid kérdésem. Ha a cég nem használja a Slacket, van-e most valamilyen kötés hozzá, vagy a fejlesztők telepíthetnek példányokat, hogy tesztalkalmazást kapcsoljanak az adatbázisokhoz?
Most van egy link a Slackhez, vagyis nincs más messenger, de nagyon szeretnék támogatást nyújtani más messengereknek is. Mit tudsz csinálni? A DB Lab-t Joe nélkül is telepítheti, a REST API segítségével vagy platformunk segítségével klónokat hozhat létre, és csatlakozhat PSQL-hez. De ezt megteheti, ha készen áll arra, hogy hozzáférést biztosítson a fejlesztőinek az adatokhoz, mert többé nem lesz képernyő.
Nekem nem ez a réteg kell, de kell egy ilyen lehetőség.
Akkor igen, meg lehet csinálni.
Forrás: will.com
