

Megvizsgáljuk a Zabbix működését egy TimescaleDB adatbázissal, mint háttérrendszerrel. Megmutatjuk, hogyan lehet a nulláról üzembe helyezni, és hogyan lehet PostgreSQL-ről migrálni. Emellett összehasonlító teljesítményteszteket is biztosítunk a két konfigurációról.

HighLoad++ Siberia 2019. Tomszk Csarnok. Június 24., 16:00. Absztraktok és A következő HighLoad++ konferencia 2020. április 6-án és 7-én lesz Szentpéterváron. Részletek és jegyek kaphatók. .
Andrey Gushchin (a továbbiakban – AG): Műszaki támogatási mérnök és oktató vagyok a ZABBIX-nál (a továbbiakban: "Zabbix"). Több mint hat éve dolgozom műszaki támogatásban, és első kézből származó tapasztalattal rendelkezem a teljesítmény terén. Ma a TimescaleDB teljesítménybeli előnyeiről fogok beszélni a standard PostgreSQL 10-hez képest. Röviden bemutatom a működését is.
Főbb teljesítménybeli kihívások: az adatgyűjtéstől az adattisztításig
Kezdjük azzal, hogy minden monitorozó rendszer bizonyos teljesítménybeli kihívásokkal néz szembe. Az első teljesítménybeli kihívás a gyors adatgyűjtés és -feldolgozás.

Egy jó monitorozó rendszernek gyorsan és azonnal fogadnia kell az összes adatot, fel kell dolgoznia azokat a trigger kifejezések szerint, azaz bizonyos kritériumok szerint (ez rendszerenként változik), és adatbázisba kell mentenie későbbi felhasználás céljából.

A második teljesítménybeli kihívás a historikus adatok tárolása. Ezeket az adatokat, amelyeket gyakran adatbázisban tárolnak, gyorsan és könnyen kell elérni, miután egy adott időszak alatt összegyűjtötték őket. A legfontosabb, hogy ezeknek az adatoknak könnyen hozzáférhetőnek kell lenniük, és jelentésekben, grafikonokban, triggerekben, küszöbértékekben, riasztásokban stb. kell felhasználhatóknak lenniük.

A harmadik teljesítménybeli kihívás az előzmények törlése, ami azt jelenti, hogy amikor elérünk egy olyan pontot, ahol már nincs szükség az öt év (vagy akár csak néhány-két hónap) alatt gyűjtött részletes mérőszámok tárolására. Néhány hálózati csomópont törölve lett, vagy egyes hosztokra már nincs szükség, mert a mérőszámok elavultak, és már nem gyűjtik őket. Mindezt meg kell tisztítani, hogy megakadályozzuk az adatbázis túl nagyra növekedését. Általánosságban elmondható, hogy az előzmények törlése gyakran jelentős kihívást jelent a tárolás szempontjából, és gyakran jelentősen befolyásolja a teljesítményt.
Hogyan lehet megoldani a gyorsítótárazási problémákat?
Most konkrétan a Zabbixről fogok beszélni. A Zabbixban az első és a második hívás gyorsítótárazással oldódik meg.

Adatgyűjtés és -feldolgozás – RAM-ot használunk mindezen adatok tárolására. Hamarosan részletesebben is beszélünk ezekről az adatokról.
Az adatbázis oldalon is van némi gyorsítótárazás a főbb kiválasztásokhoz – grafikonokhoz és egyéb dolgokhoz.
Zabbix szerveroldali gyorsítótárazás: van ConfigurationCache, ValueCache, HistoryCache és TrendsCache. Mik ezek?

A ConfigurationCache a fő gyorsítótár, ahol a metrikák, hosztok, adatelemek, triggerek – azaz minden, ami az előfeldolgozáshoz, az adatgyűjtéshez, a gyűjtendő hosztokhoz és a gyakorisághoz szükséges – tárolódik. Mindez a ConfigurationCache-ben tárolódik, hogy elkerüljük az adatbázis-hozzáférést és a felesleges lekérdezéseket. A szerver indulása után frissítjük (létrehozzuk) ezt a gyorsítótárat, és rendszeresen frissítjük (a konfigurációs beállításoktól függően).
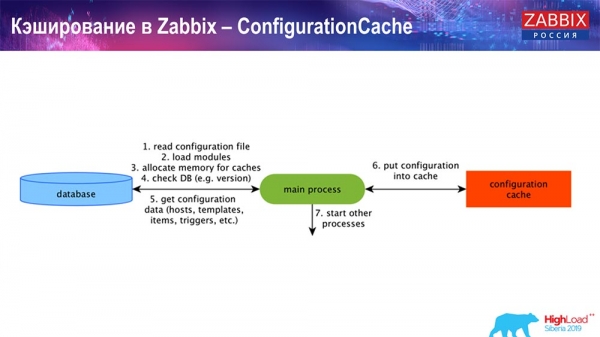
Gyorsítótárazás a Zabbixben. Adatgyűjtés
Itt egy elég nagyméretű ábra:
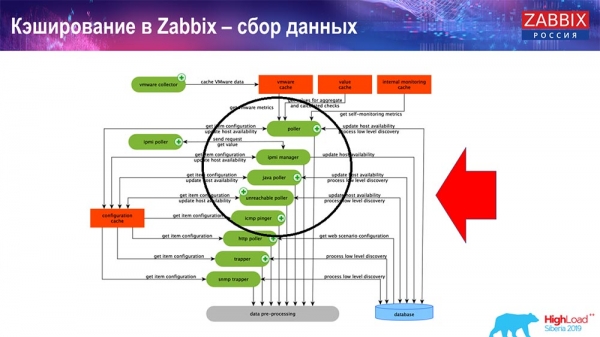
A rendszerben a főbbek ezek az összeszerelők:
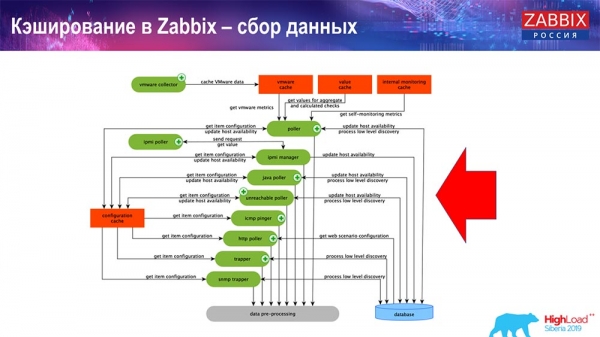
Ezek maguk az építési folyamatok, különféle "lekérdezők", amelyek a különböző típusú építésekért felelősek. ICMP, IPMI és különféle protokollokon keresztül gyűjtik az adatokat, és továbbítják azokat az előfeldolgozásnak.
Előfeldolgozás HistoryCache
Továbbá, ha számított adatelemeink vannak (a Zabbixet ismerők tudják ezt), azaz számított, összesített adatelemek, akkor azokat közvetlenül a ValueCache-ből kérdezzük le. Később elmagyarázom, hogyan töltődik fel. Mindezek a gyűjtők a ConfigurationCache-t használják a feladataik fogadására, majd továbbítják azokat előfeldolgozásra.
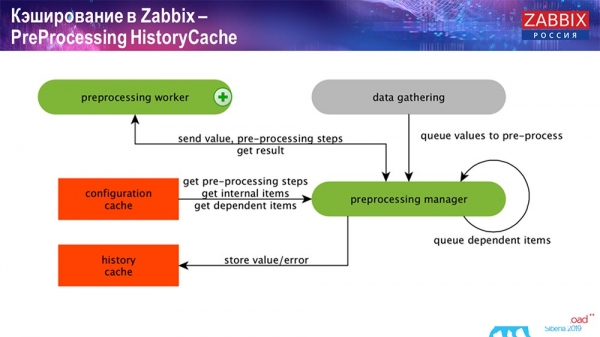
Az előfeldolgozás a ConfigurationCache-t is használja az előfeldolgozási lépések lekéréséhez, és ezeket az adatokat különböző módokon dolgozza fel. A 4.2-es verziótól kezdődően ezt egy proxyra helyeztük át. Ez nagyon kényelmes, mivel maga az előfeldolgozás meglehetősen nehézkes művelet. És ha egy nagyon nagy Zabbix rendszerrel rendelkezik, nagyszámú adatelemmel és magas gyűjtési gyakorisággal, ez jelentősen leegyszerűsíti a munkát.
Ennek megfelelően, miután feldolgoztuk ezeket az adatokat az előfeldolgozás segítségével, elmentjük azokat a HistoryCache-be további feldolgozás céljából. Ezzel befejeződik az adatgyűjtés. Továbblépünk a fő folyamatra.
Előzményszinkronizálás működik
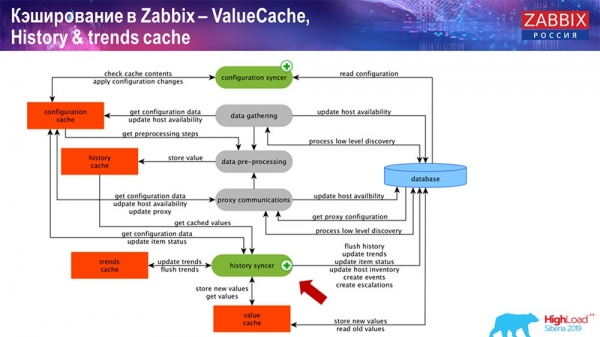
A Zabbix fő folyamata (mivel monolitikus architektúráról van szó) a történetszinkronizáló. Ez a fő folyamat kezeli az egyes adatelemek, azaz az egyes értékek atomi feldolgozását:
- megérkezik az érték (a HistoryCache-ből veszi);
- ellenőrzi a Konfiguráció szinkronizálóban: vannak-e számítási triggerek – kiszámítja azokat;
ha vannak ilyenek, eseményeket hoz létre, eszkalációt hoz létre riasztás létrehozása érdekében, ha a konfiguráció megköveteli; - rögzíti a triggereket a későbbi feldolgozáshoz, összesítéshez; ha az elmúlt órára stb. összesít, akkor a ValueCache megjegyzi ezt az értéket, így nem kell hozzáférni az előzménytáblához; így a ValueCache feltöltődik a triggerek, számított elemek stb. kiszámításához szükséges adatokkal;
- majd az Előzmények szinkronizálója az összes adatot az adatbázisba írja;
- Az adatbázis lemezre írja őket - itt ér véget a feldolgozás.
Adatbázisok. Gyorsítótárazás
Az adatbázis oldalán, ha grafikonokat vagy eseményjelentéseket szeretnél megtekinteni, különféle gyorsítótárak állnak rendelkezésre. De ezeket ebben az előadásban nem fogom részletezni.
MySQL esetén létezik az Innodb_buffer_pool, és egy csomó más, szintén konfigurálható gyorsítótár.
De ezek a főbbek:
- megosztott_pufferek;
- effektív_gyorsítótár_méret;
- megosztott_medence.

Minden adatbázis esetében megmutattam, hogy vannak bizonyos gyorsítótárak, amelyek lehetővé teszik számukra, hogy a lekérdezésekhez gyakran szükséges adatokat a RAM-ban tárolják. Ehhez saját technológiáik vannak.
Az adatbázis teljesítményéről
Ennek megfelelően egy párhuzamos környezetről van szó, ami azt jelenti, hogy a Zabbix szerver adatokat gyűjt és rögzít. Újraindításkor a ValueCache feltöltéséhez az előzményekből is olvas, és így tovább. Használhatsz olyan szkripteket és jelentéseket is, amelyek a webes felületen épülő Zabbix API-t használják. A Zabbix API hozzáfér az adatbázishoz, és lekéri a szükséges adatokat grafikonok, jelentések, események vagy legutóbbi problémák listájának létrehozásához.
Egy másik nagyon népszerű vizualizációs megoldás a Grafana, amelyet felhasználóink használnak. Közvetlenül hozzáférhet az adatokhoz mind a Zabbix API-n, mind az adatbázison keresztül. Emellett némi versenyt is teremt az adatlekérésért: egy finomabb és jobban hangolt adatbázisra van szükség az eredmények gyors leadásához és a teszteléshez.

Előzmények törlése. Zabbixnek van házvezetőnője.
A Zabbixban használt harmadik hívás a Housekeeper segítségével történő előzmények törlése. A Housekeeper minden beállítást figyelembe vesz, ami azt jelenti, hogy az adatelemekben megadjuk a tárolás időtartamát (napokban), a trendek időtartamát és a változások dinamikáját.
Nem említettem a TrendCash-t, amit menet közben számolunk: beérkeznek az adatok, egy óránként összesítjük őket (többnyire az elmúlt órában), kiszámítjuk az átlag/minimum értékeket, és óránként beírjuk őket a Trendek táblába. A Housekeeper lefuttatja és törli az adatokat az adatbázisból a szokásos selectekkel, ami nem mindig hatékony.
Hogyan állapítható meg, hogy ez hatástalan-e? Ezt a képet láthatja a belső folyamatteljesítmény-diagramokon:
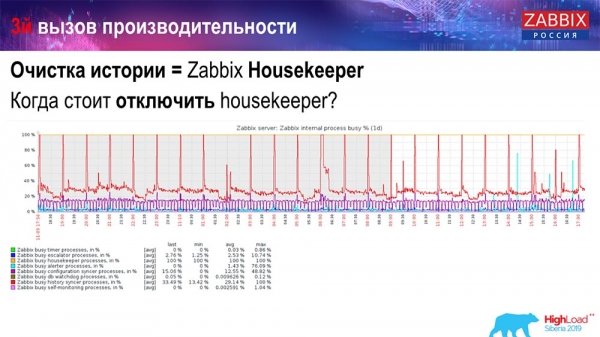
Az Előzményszinkronizálód folyamatosan foglalt (piros grafikon). A felette lévő „narancssárga” grafikon a Housekeeper, amely elindul és várja, hogy az adatbázis törölje az összes megadott sort.
Vegyünk egy kis elemazonosítót: törölnünk kell az utolsó 5-et; természetesen index szerint. De az adathalmaz általában elég nagy – az adatbázis továbbra is a lemezről olvassa és a gyorsítótárba tölti, ami nagyon költséges művelet az adatbázis számára. Méretétől függően ez bizonyos teljesítményproblémákhoz vezethet.
A Housekeeper egyszerűen letiltható – egy ismerős webes felülettel rendelkezünk. Az Adminisztráció Általános (Housekeeper beállítások) részben letiltottuk a belső takarítást a belső előzmények és trendek tekintetében. Következésképpen a Housekeeper a továbbiakban nem kezeli ezeket a funkciókat:

Mit tehetek ezután? Letiltottad, és a grafikonjaid kiegyenesedtek... Milyen más problémák merülhetnek fel ebben az esetben? Mi segíthet?
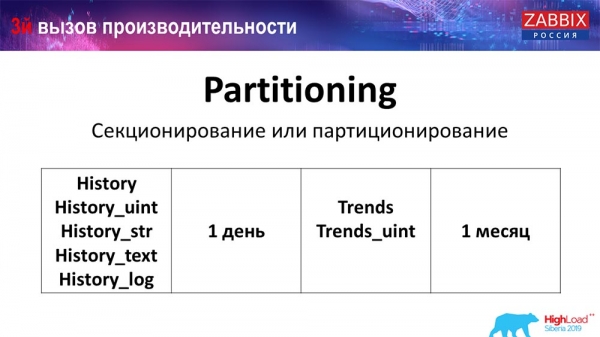
Particionálás (szekcionálás)
Ez jellemzően minden egyes felsorolt relációs adatbázishoz másképp van konfigurálva. A MySQL-nek megvan a saját technológiája. De összességében nagyon hasonlóak, különösen a PostgreSQL 10 és a MySQL esetében. Természetesen számos belső különbség van abban, hogyan valósítják meg a dolgokat, és hogyan befolyásolják a teljesítményt. De összességében egy új partíció létrehozása gyakran bizonyos problémákhoz vezet.

A beállítástól (naponta létrehozott adatmennyiség) függően a minimum általában 1 napra van beállítva partíciónként, míg a „trendek” vagy a változásdinamika esetén 1 hónap új partíciónként. Ez változhat, ha nagyon nagy a beállítása.
Rögtön a telepítési méretekről is beszéljünk: másodpercenként legfeljebb 5000 új érték (úgynevezett NVPS) kis telepítésnek tekinthető. Egy közepes beállítás másodpercenként 5000 és 25 000 érték között mozog. Bármi, ami e felett van, nagy vagy nagyon nagy telepítésnek számít, ami az adatbázis nagyon gondos konfigurálását igényli.
Nagyon nagy telepítések esetén 1 nap nem biztos, hogy optimális. Személyesen láttam már MySQL partíciókat napi 40 gigabájtot (és néha többet) fogyasztani. Ez egy nagyon nagy adatmennyiség, ami problémákat okozhat. Csökkenteni kell.
Miért szükséges a particionálás?
Szerintem mindenki tudja, hogy mit csinál a particionálás: tábla particionálás. Ezek gyakran különálló fájlok a lemezen és span lekérdezések. Optimálisabban választ ki egy partíciót, ha az egy normál particionálás része.
A Zabbix esetében különösen tartományparticionálást használunk, ami azt jelenti, hogy időbélyeget használunk (egy normál számot, az epoch kezdete óta eltelt időt). Megadjuk a nap kezdetét/nap végét, és ez a partíció. Ezért, ha két nappal ezelőtti adatokhoz férünk hozzá, azok gyorsabban lekérhetők az adatbázisból, mivel csak egyetlen fájlt kell betölteni a gyorsítótárba, és azt kell visszaadni (egy nagy táblázat helyett).

Sok adatbázis felgyorsítja a beszúrásokat (egyetlen gyermektáblába történő beszúrást) is. Most elvont módon beszélek, de ez is lehetséges. A particionálás gyakran segít.
Elasticsearch NoSQL-hez
Nemrégiben, a 3.4-es verzióban implementáltunk egy NoSQL megoldást. Hozzáadtuk az Elasticsearchbe való írás lehetőségét. Speciális típusokat írhatunk: számok vagy szimbólumok közül választhatunk; van karakterlánc, naplókat írhatunk az Elasticsearchbe... Ennek megfelelően a webes felület is eléri az Elasticsearch-et. Ez bizonyos esetekben nagyszerűen működik, de egyelőre használható.

Időskála-adatbázis. Hipertáblák
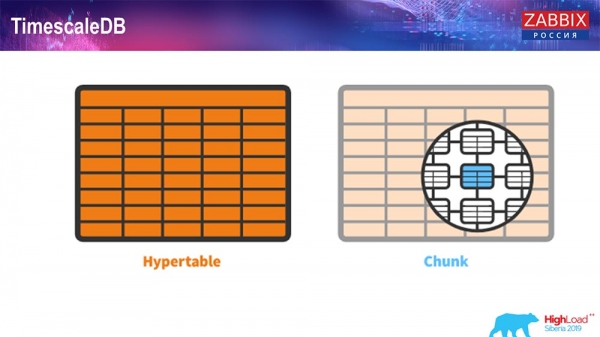
A 4.4.2-es verzióban egy funkciót emeltünk ki: a TimescaleDB-t. Mi is ez? Ez egy PostgreSQL kiterjesztés, ami azt jelenti, hogy natív PostgreSQL felülettel rendelkezik. Ezenkívül ez a kiterjesztés sokkal hatékonyabb munkát tesz lehetővé az idősoros adatokkal és az automatikus particionálást. Így néz ki:

Ez egy hipertábla – van egy ilyen koncepció a Timescale-ben. Ez egy hipertábla, amit te hozol létre, és chunkokat tartalmaz. A chunkok partíciók, vagyis gyermektáblák, ha nem tévedek. Nagyon hatékony.
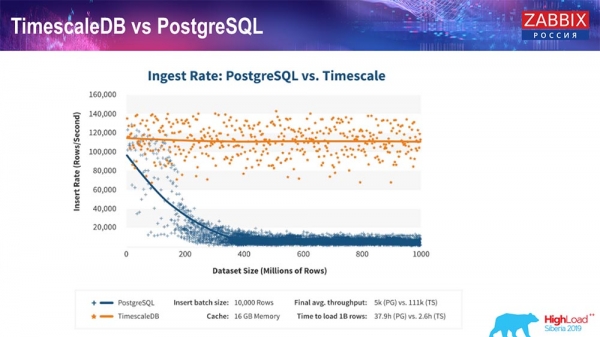
TimescaleDB és PostgreSQL
A TimescaleDB szállítói szerint hatékonyabb lekérdezés-feldolgozó algoritmust használnak, különösen a beszúrásoknál, ami nagyjából állandó teljesítményt tesz lehetővé a beszúrt adathalmaz méretének növekedésével. Vagyis 200 millió sor után a standard PostgreSQL jelentősen romlani kezd, és szó szerint nullára csökkenti a teljesítményt, míg a TimescaleDB lehetővé teszi a beszúrások lehető leghatékonyabb végrehajtását bármilyen adatméret mellett.
Hogyan telepítsem a TimescaleDB-t? Egyszerű!
Benne van a dokumentációban, le van írva – bármilyen csomagból telepítheted... A hivatalos Postgres csomagoktól függ. Manuálisan is lefordítható. Véletlenül nekem kellett lefordítanom az adatbázishoz.
A Zabbixban egyszerűen aktiváljuk az Extensiont. Azt hiszem, akik használták az Extensiont a PostgreSQL-ben… Egyszerűen aktiválod az Extensiont, létrehozod a használt Zabbix adatbázishoz.
És az utolsó lépés…
TimescaleDB: Előzménytáblák migrálása
Létre kell hoznod egy hipertáblázatot. Erre van egy speciális függvény – a Create Hypertable. Az első paramétere határozza meg azt a táblát az adatbázisban, amelyhez hipertáblázatot szeretnél létrehozni.

A létrehozandó mező és a chunk_time_interval (ez a használandó chunkok (partíciók) intervallumát adja meg). A 86 400 egy napot jelent.
migrate_data paraméter: ha igazra állítja, akkor az összes aktuális adatot előre létrehozott adatcsomagokba migrálja.
Én magam a migrate_data függvényt használtam – elég sokáig tart, az adatbázis méretétől függően. Az enyém több mint egy terabájt volt, így a létrehozása több mint egy órát vett igénybe. A tesztelés során néhány esetben töröltem a szöveg (history_text) és a karakterlánc (history_str) historikus adatait, hogy elkerüljem a migrálásukat – nem igazán érdekeltek.
Az utolsó frissítés, amit végrehajtunk, a db_extention változónkban történik: telepítjük a timescaledb-t, hogy az adatbázis, és konkrétan a Zabbixunk, megértse a db_extention létezését. Aktiválja azt, és a megfelelő szintaxist és lekérdezéseket használja az adatbázishoz, kihasználva a TimescaleDB által megkövetelt funkciókat.
Szerverkonfiguráció
Két szervert használtam. Az első szerver egy meglehetősen kicsi virtuális gép 20 processzorral és 16 gigabájt RAM-mal. PostgreSQL 10.8-cal konfiguráltam:

Az operációs rendszer volt Debian, fájlrendszer – xfs. Minimális beállításokat végeztem el kifejezetten ehhez az adatbázishoz, azon kívül, hogy mit fog használni maga a Zabbix. A Zabbix szerver, a PostgreSQL és a betöltőügynökök is telepítve voltak erre a gépre.

50 aktív ügynököt használtam, amelyek a LoadableModule-t használják különféle eredmények gyors előállítására. Karakterláncokat, számokat és így tovább generáltak. Nagy mennyiségű adattal töltöttem fel az adatbázist. A kezdeti konfiguráció hosztonként 5 adatelemet tartalmazott, és körülbelül minden adatelem tartalmazott egy triggert – hogy realisztikus beállítást kapjak. Néha egynél több trigger is szükséges a használathoz.

A frissítési intervallumot és magát a betöltést is szabályoztam nemcsak 50 ügynök használatával (továbbiak hozzáadásával), hanem dinamikus adatelemek használatával és a frissítési intervallum 4 másodpercre csökkentésével.
PostgreSQL teljesítményteszt: 36 000 NVP
Az első indításom, az első beállításom egy tiszta PostgreSQL 10-en történt ezen a hardveren (35 000 érték másodpercenként). Összességében, ahogy a képernyőn is látható, az adatbeillesztés a másodperc töredékét veszi igénybe – minden rendben és gyorsan megy, köszönhetően az SSD meghajtóknak (200 GB). Az egyetlen probléma az, hogy a 20 GB-os meghajtók elég gyorsan megtelnek.
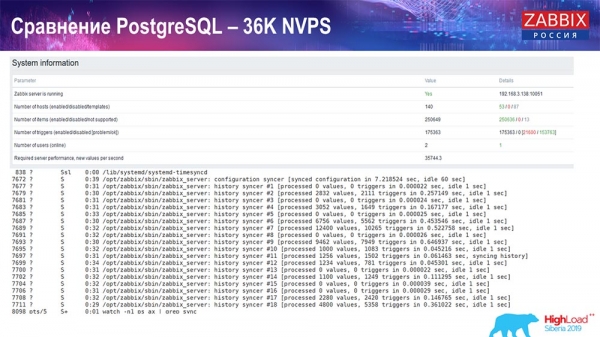
Később lesz még jó néhány ehhez hasonló grafikon. Ez a Zabbix szerver teljesítményének standard irányítópultja.
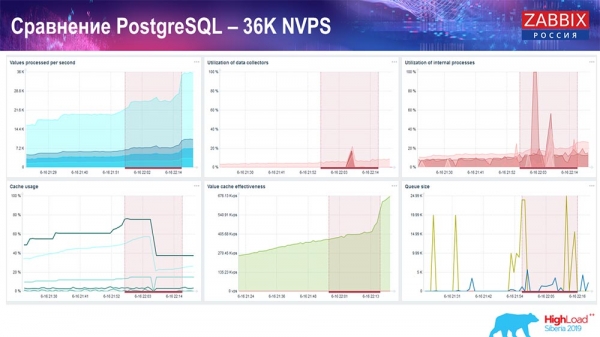
Az első grafikon a másodpercenkénti értékek számát mutatja (kék, bal felső sarok), ebben az esetben 35 000 értéket. Ez (középen felül) az építési folyamatok terhelését mutatja, ez (jobb felső sarok), és ez (jobb felső sarok) a belső folyamatok terhelését mutatja: a history syncers és a housekeeper, amely itt (középen alul) már egy ideje fut.
Ez a grafikon (középen alul) a ValueCache használatát mutatja – hány ValueCache találatot generálnak a triggerek (több ezer érték másodpercenként). Egy másik fontos grafikon a negyedik (balra lent), amely a korábban említett HistoryCache használatát mutatja, amely egy puffer az adatok adatbázisba való beillesztése előtt.
PostgreSQL teljesítményteszt: 50 000 NVP
Ezután ugyanazon a hardveren másodpercenként 50 000 értékre növeltem a terhelést. Housekeeperrel betöltve 2-3 másodperc alatt 10 000 érték íródott ki, a számításokkal együtt. Ez látható a következő képernyőképen:
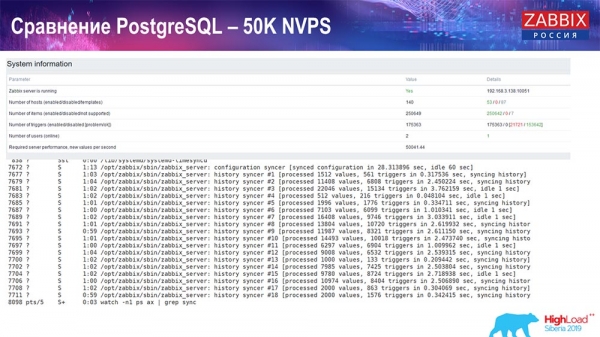
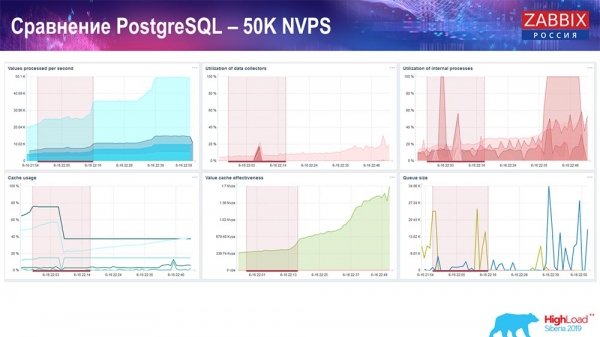
A Housekeeper már elkezdte zavarni a munkát, de összességében a HistoryCache terhelése még mindig 60%-on áll (harmadik grafikon, jobb felső sarok). A HistoryCache már gyorsan kezd megtelni a Housekeeper futása közben (bal alsó sarok). Körülbelül fél gigabájt volt, és 20%-ra telt.
PostgreSQL teljesítményteszt: 80 000 NVP
Aztán másodpercenként 80 ezer értékre növeltem:
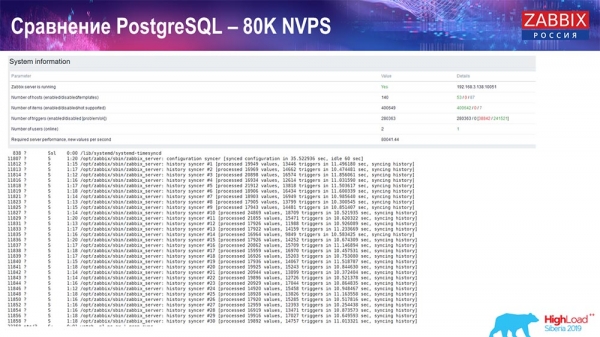
Ez körülbelül 400 000 adatelemet és 280 000 triggert jelentett. Amint látható, a beszúrási arány, a történeti nyelő terhelése alapján (30 volt belőlük), már elég magas volt. Ezután megnöveltem a különböző paramétereket: a történeti nyelőket, a gyorsítótárat... Ezen a hardveren a történeti nyelő terhelése elkezdett a maximumig növekedni, gyakorlatilag a "határig" – ennek megfelelően a HistoryCache nagyon nagy terhelést kezdett el tapasztalni:
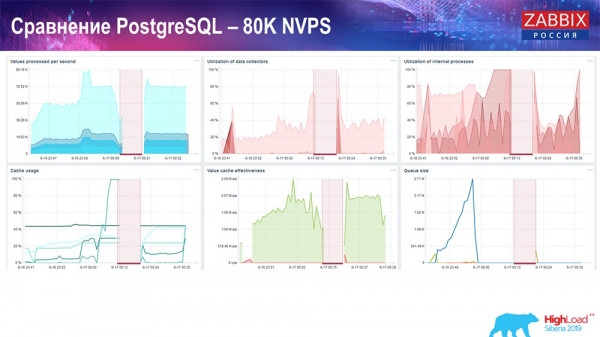
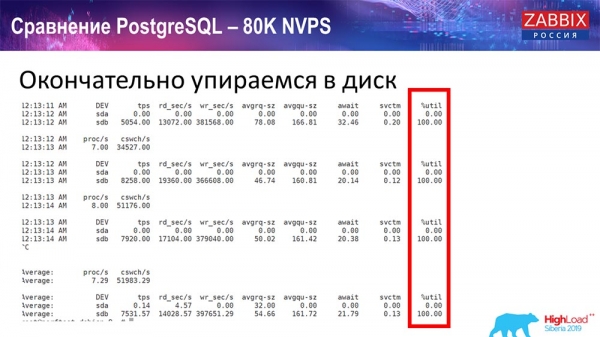
Mindeközben folyamatosan figyeltem az összes rendszerparamétert (processzorhasználat, RAM), és azt tapasztaltam, hogy a lemez kihasználtsága a maximumon van – elértem a lemez maximális kapacitását ezen a hardveren, ebben a virtuális gépben. Ezzel a tempóval a PostgreSQL meglehetősen agresszíven kezdett adatkiíratni, és a lemez nem tudta tartani a lépést az írásokkal, olvasásokkal és más feladatokkal.
Vettem egy másik szervert, amiben már 48 processzor és 128 gigabájt RAM volt:
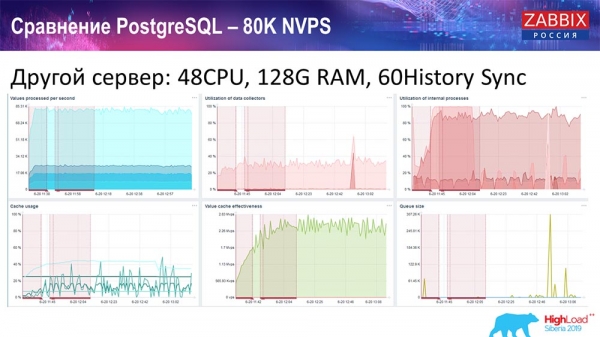
Fel is hangoltam – telepítettem a History Synchronizert (60 darabot), és elfogadható teljesítményt értem el. Még nem tartunk egészen ott, de valószínűleg a teljesítményhatáron vagyunk, ahol tenni kell valamit.
Teljesítményteszt. TimescaleDB: 80 000 NVP
A fő célom a TimescaleDB használata volt. Minden grafikonon látható egy mélypont:
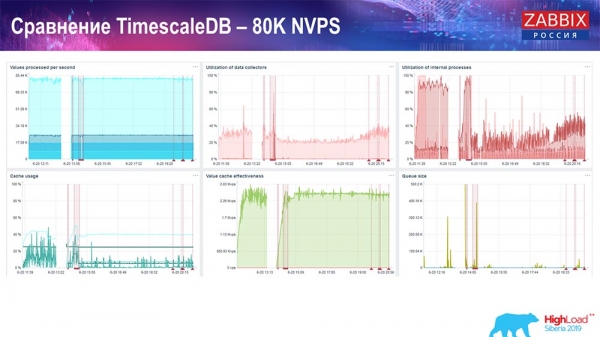
Ezek a visszaesések pontosan az adatmigrációnak tudhatók be. Ezt követően a Zabbix szerver előzménytöltési profilja, amint látható, jelentősen megváltozott. Majdnem háromszor gyorsabb adatbevitelt tesz lehetővé, és kevesebb HistoryCache-t használ, ami azt jelenti, hogy időben megkapod az adatokat. Ismétlem, a másodpercenkénti 80 3 érték elég magas arány (a Yandex esetében biztosan nem). Összességében ez egy meglehetősen nagy beállítás, egyetlen szerverrel.
PostgreSQL teljesítményteszt: 120 000 NVP
Ezután félmillióra növeltem az adatelemek számát, és másodpercenként 125 ezer becsült értéket kaptam:
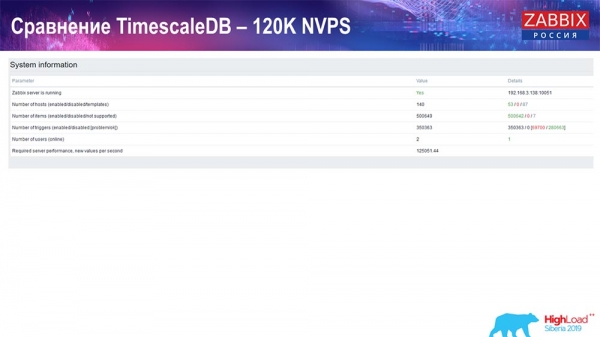
És ezeket a grafikonokat kaptam:
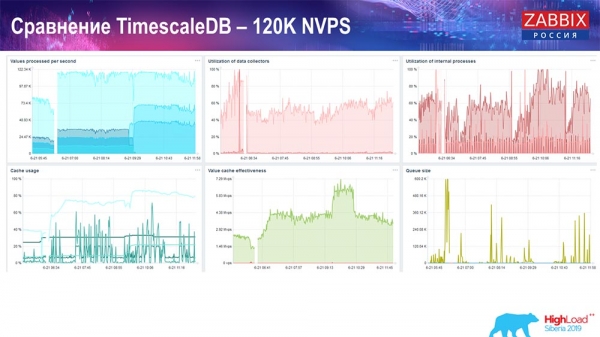
Elvileg ez egy működő beállítás; elég sokáig futhat. De mivel csak 1,5 terabájt lemezterületem volt, pár nap alatt elhasználtam. A legfontosabb, hogy ezzel egy időben új partíciók jöttek létre a TimescaleDB-ben, és ez a teljesítmény szempontjából teljesen észrevehetetlen volt, ami a MySQL esetében nem jellemző.
A partíciókat jellemzően éjszaka hozzák létre, mert ez teljesen blokkolja a beszúrásokat és a táblamanipulációt, ami potenciálisan szolgáltatásromláshoz vezethet. Ez esetben nem ez a helyzet! A fő cél a TimescaleDB képességeinek tesztelése volt. Az eredmény másodpercenként 120 000 érték lett.
Vannak erre példák a "közösségben" is:
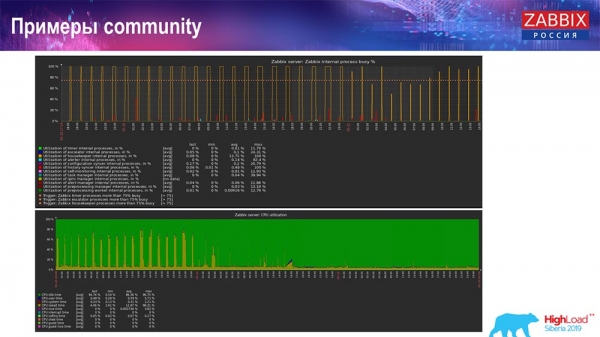
Valaki engedélyezte a TimescaleDB-t is, és az io.weight használatának CPU-terhelése csökkent; a belső folyamatelemek használata is csökkent a TimescaleDB-nek köszönhetően. És ezek sima lemezek voltak, ami azt jelenti, hogy egy sima virtuális gép futott sima lemezeken (nem SSD-ken)!
Kisebb, lemezteljesítmény által korlátozott rendszerek esetén a TimescaleDB nagyon jó megoldásnak tűnik. Lehetővé teszi a folyamatos működést, mielőtt gyorsabb adatbázis-hardverre váltanánk.
Mindenkit szeretettel meghívok rendezvényeinkre: Konferencia Moszkvában, Csúcstalálkozó Rigában. Használjátok csatornáinkat – Telegram, fórum, IRC. Ha bármilyen kérdésetek van, gyertek el a standunkhoz – mindent megbeszélhetünk.
Közönségkérdések
Közönségkérdés (a továbbiakban: A): Ha a TimescaleDB ilyen egyszerűen beállítható és ilyen teljesítménynövekedést biztosít, talán ezt kellene bevált gyakorlatként alkalmazni a Zabbix Postgres-szel történő beállításához? Vannak-e buktatók vagy hátrányok ebben a megoldásban, vagy igaz, hogy ha úgy döntök, hogy Zabbixet építek, akkor egyszerűen telepíthetem a Timescale-t közvetlenül a Postgres-be, használhatom, és nem kell aggódnom semmilyen probléma miatt?

AG: – Igen, azt mondanám, hogy jó ajánlás a PostgreSQL használata a TimescaleDB kiterjesztéssel. Ahogy mondtam, sok jó értékelés van róla, annak ellenére, hogy ez a funkció kísérleti jellegű. De valójában a tesztek azt mutatják, hogy kiváló megoldás (a TimescaleDB-vel), és szerintem folyamatosan fejlődni fog! Figyelemmel kísérjük, hogyan fejlődik ez a kiterjesztés, és elvégezzük a szükséges módosításokat.
Még az egyik jól ismert funkciójukra is támaszkodtunk a fejlesztés során: lehetővé tette, hogy egy kicsit másképp dolgozzunk a chunkokkal. De aztán a következő kiadásban eltávolították, és abba kellett hagynunk erre a kódra való támaszkodást. Sok beállításhoz ajánlom ezt a megoldást. Ha MySQL-t használsz… Átlagos beállításokhoz bármelyik megoldás jól működik.
és: – A közösség legújabb listái között szerepelt egy Housekeeperrel ellátott lista is:
Folytatta a munkát. Mit csinál a Housekeeper a TimescaleDB-vel?
AG: „Jelenleg nem tudom biztosan megmondani – megnézem a kódot, és további részleteket adok. Kifejezetten TimescaleDB lekérdezéseket használ, nem darabok törlésére, hanem valamiféle aggregációra. Még nem állok készen arra, hogy megválaszoljam ezt a technikai kérdést. Ezt ma vagy holnap megerősítjük a standon.”
és: – Hasonló kérdésem lenne – a Timescale törlési műveletének teljesítményéről.
A (válasz a közönségből): „Amikor adatokat törölsz egy táblázatból, ha a delete paranccsal teszed, akkor végig kell menned a táblázaton – mindent el kell távolítanod, ki kell tisztítanod és meg kell jelölnöd későbbi felhasználásra. A Timescale-ben, mivel vannak chunkok, el lehet dobni. Nagyjából szólva, a Big Data-ban egyszerűen azt kell mondanod a fájlnak: „Törlés!””
A Timescale egyszerűen megérti, hogy a chunk már nem létezik. És mivel integrálva van a lekérdezéstervezőbe, a select utasításokban vagy más műveletekben lévő feltételekhez kapcsolódik, és azonnal megérti, hogy a chunk már nem létezik – „Nem megyek oda többet!” (nincs adat). Ennyi! Tehát a tábla beolvasását a bináris fájl törlése váltja fel, így gyors.
és: Már érintettük a nem SQL témáját. Amennyire én értem, a Zabbixnak valójában nincs szüksége adatok módosítására; az egész egyfajta naplózás. Lehetséges-e olyan speciális adatbázisokat használni, amelyek nem tudják módosítani az adataikat, de sokkal gyorsabban tárolják, gyűjtik és kérik le az adatokat – például a Clickhouse, vagy valami hasonló a Kafkához? A Kafka is egy napló! Lehetséges-e valahogy integrálni őket?
AG: – Exportálhatsz. A 3.4-es verzió óta van egy speciális funkciónk: az összes historikus adatot, eseményt és minden mást fájlokba írhatsz; majd valamilyen kezelővel elküldheted azokat bármely más adatbázisba. Sőt, sokan átdolgozzák, és közvetlenül az adatbázisba írnak. A historikus fájlok menet közben fájlokba írják az egészet, forgatják ezeket a fájlokat, és így tovább, és átviheted a Clickhouse-ba. A terveinkről nem tudok nyilatkozni, de talán a NoSQL megoldások (mint például a Clickhouse) további támogatása is folytatódni fog.
és: – Szóval, lehetséges teljesen megszabadulni a Postgrestől?
AG: „Természetesen a Zabbix legnagyobb kihívását a historikus táblázatok jelentik, amelyek a legtöbb problémát okozzák, és az események. Ebben az esetben, ha nem tároljuk sokáig az eseményeket, és a historikus adatokat és a trendeket valamilyen más gyors tárolóban tároljuk, akkor összességében azt hiszem, nem lesznek problémák.”
és: – Meg tudja becsülni, mennyivel gyorsabban fog minden működni, ha például a Clickhouse-ra vált?
AG: „Nem teszteltem. Szerintem elég könnyű lenne legalább ugyanazokat a számokat elérni, tekintve, hogy a Clickhouse-nak saját felülete van, de ezt nem tudom biztosan megmondani. A legjobb, ha teszteled. Minden a konfigurációtól függ: hány hosztod van, és így tovább. A beszúrás egy dolog, de ezeket az adatokat is össze kell gyűjteni – Grafanával vagy valami mással.”
és: – Tehát egyenlő küzdelemről beszélünk, és nem ezeknek a gyors BD-knek a nagy előnyéről?
AG: – Szerintem, amikor integrálódunk, pontosabb tesztek lesznek.
és: – Hová tűnt a jó öreg RRD? Miért váltottatok SQL adatbázisokra? Kezdetben minden metrikát az RRD-n gyűjtöttek.
AG: „A Zabbixnek lehet, hogy egy nagyon régi RRD verziója volt. Mindig is voltak SQL adatbázisaink – a klasszikus megközelítés. A klasszikus megközelítés a MySQL és a PostgreSQL (ezek már nagyon régóta léteznek). Szinte soha nem használtunk közös felületet az SQL és az RRD adatbázisokhoz.”


Néhány hirdetés 🙂
Köszönjük, hogy velünk tartott. Tetszenek cikkeink? További érdekes tartalmakat szeretne látni? Támogass minket rendeléssel vagy ajánlj ismerőseidnek, , a belépő szintű szerverek egyedülálló analógja, amelyet mi találtunk ki Önnek: (RAID1 és RAID10, akár 24 maggal és akár 40 GB DDR4-gyel is elérhető).
A Dell R730xd kétszer olcsóbb az amszterdami Equinix Tier IV adatközpontban? Csak itt Hollandiában! Dell R420 - 2x E5-2430 2.2 Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - 99 dollártól! Olvasni valamiről
Forrás: will.com
