

Ez a cikk a médiumról szóló cikkem fordítása - , ami elég népszerűnek bizonyult, valószínűleg az egyszerűsége miatt. Ezért úgy döntöttem, hogy oroszul írom, és hozzáteszem egy kicsit, hogy egy hétköznapi ember számára, aki nem adatszakértő, világos legyen, mi az adattárház (DW), és mi az adattó (Data Lake), és hogyan kijönni együtt.
Miért akartam az adattóról írni? Több mint 10 éve foglalkozom adatokkal és elemzésekkel, és most határozottan a big data-okkal dolgozom a cambridge-i Amazon Alexa AI-nél, amely Bostonban van, bár a Vancouver Island-i Victoria-ban élek, és gyakran látogatok Bostonba, Seattle-be. , és Vancouverben, sőt néha Moszkvában is konferenciákon beszélek. Írok is időnként, de főleg angolul írok, és már írtam is , szükségem van az észak-amerikai elemzési trendek megosztására is, és néha be is írok .
Mindig is adattárházakkal dolgoztam, és 2015 óta szorosan együttműködtem az Amazon Web Services-szel, és általában a felhőelemzésre váltottam (AWS, Azure, GCP). 2007 óta figyeltem az analitikai megoldások fejlődését, sőt dolgoztam az adattárház-szállító Teradata-nál, és implementáltam a Sberbankban, és ekkor jelent meg a Big Data with Hadoop. Mindenki azt kezdte mondani, hogy a tárolás korszaka lejárt, és most már minden a Hadoopon van, aztán megint a Data Lake-ről kezdtek beszélni, hogy most már határozottan eljött az adattárház vége. De szerencsére (talán sajnos azok számára, akik sok pénzt kerestek a Hadoop létrehozásával) az adattárház nem tűnt el.
Ebben a cikkben megvizsgáljuk, mi az az adattó. Ez a cikk azoknak szól, akiknek nincs vagy kevés tapasztalatuk van az adattárházakkal kapcsolatban.

A képen a Bledi tó, ez az egyik kedvenc tavam, bár csak egyszer voltam ott, életem végéig emlékeztem rá. De beszélni fogunk egy másik típusú tóról - egy adattóról. Talán sokan hallottatok már erről a kifejezésről, de még egy meghatározás nem árt senkinek.
Először is, itt vannak a Data Lake legnépszerűbb definíciói:
„Minden típusú nyers adat fájltárolója, amely a szervezeten belül bárki számára elérhető elemzésre” – Martin Fowler.
„Ha úgy gondolja, hogy a Data Mart egy palack víz – megtisztítva, becsomagolva és kényelmesen becsomagolva, akkor az adattó természetes formájában hatalmas víztározó. Felhasználók, vizet gyűjthetek magamnak, merülhetek mélyre, fedezhetek fel” – James Dixon.
Ma már biztosan tudjuk, hogy egy adattó az analitikáról szól, lehetővé teszi, hogy nagy mennyiségű adatot tároljunk eredeti formájában, és az adatokhoz a szükséges és kényelmes hozzáférésünk van.
Gyakran szeretem leegyszerűsíteni a dolgokat. Ha egy összetett kifejezést egyszerűen el tudok magyarázni, az azt jelenti, hogy megértettem, hogyan működik és mire való. Egyszer éppen a... iPhone a fotógalériában, és rájöttem, hogy ez egy igazi adattó, sőt, még egy diát is készítettem a konferenciákhoz:
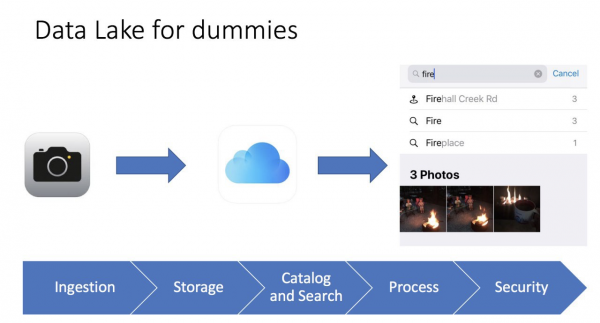
Nagyon egyszerű. Készítünk egy fotót a telefonunkkal, a fotó mentésre kerül a telefonra, és menthető az iCloudba (egy felhőalapú fájltároló szolgáltatás). A telefon a fotó metaadatait is gyűjti: mi van a fotón, a geocímkét és az időpontot. Ennek eredményeként egy felhasználóbarát felületet használhatunk. iPhoneA fotónk megtalálásához még a mutatókat is látjuk. Például, amikor olyan fotókat keresek, amelyekben szerepel a „tűz” szó, három tábortűzről készült fotót találok. Számomra ez olyan, mint egy üzleti intelligencia eszköz, amely nagyon gyorsan és hatékonyan működik.
És persze nem szabad megfeledkezni a biztonságról (engedélyezés és hitelesítés), különben könnyen közkinccsé kerülhetnek adataink. Sok hír érkezik nagyvállalatokról, startupokról, amelyek adatai a fejlesztők hanyagsága és az egyszerű szabályok be nem tartása miatt váltak nyilvánossá.
Már egy ilyen egyszerű kép is segít elképzelni, hogy mi is az adattó, mi a különbség a hagyományos adattárháztól és főbb elemei:
- adatok betöltése (Lenyelés) az adattó kulcsfontosságú összetevője. Az adatok kétféleképpen juthatnak be az adattárházba - kötegelt (időközönkénti betöltés) és streaming (adatfolyam).
- Fájltárolás (Storage) a Data Lake fő összetevője. Szükségünk volt arra, hogy a tároló könnyen méretezhető, rendkívül megbízható és alacsony költségű legyen. Például az AWS-ben S3.
- Katalógus és keresés (Katalógus és Keresés) - annak érdekében, hogy elkerüljük a Data Swamp-et (ez az, amikor az összes adatot egy kupacba rakjuk, és akkor lehetetlen vele dolgozni), létre kell hoznunk egy metaadat réteget az adatok osztályozására így a felhasználók könnyen megtalálhatják az elemzéshez szükséges adatokat. Ezenkívül további keresési megoldásokat is használhat, mint például az ElasticSearch. A keresés egy felhasználóbarát felületen keresztül segíti a felhasználót a keresett adatok megtalálásában.
- Feldolgozás (Feldolgozás) - ez a lépés az adatok feldolgozásáért és átalakításáért felelős. Átalakíthatjuk az adatokat, megváltoztathatjuk a szerkezetüket, tisztíthatjuk és még sok minden mást.
- biztonság (Biztonság) – Fontos, hogy időt szánjunk a megoldás biztonsági tervezésére. Például adattitkosítás tárolás, feldolgozás és betöltés közben. Fontos a hitelesítési és engedélyezési módszerek használata. Végül szükség van egy audit eszközre.
Gyakorlati szempontból három attribútummal jellemezhetünk egy adattavat:
- Gyűjts össze és tárolj bármit — az adattó tartalmazza az összes adatot, mind a nyers feldolgozatlan adatokat bármely időszakra vonatkozóan, mind a feldolgozott/tisztított adatokat.
- Deep Scan — egy adattó lehetővé teszi a felhasználók számára az adatok feltárását és elemzését.
- Rugalmas hozzáférés — Az adattó rugalmas hozzáférést biztosít a különböző adatokhoz és különböző forgatókönyvekhez.
Most már beszélhetünk az adattárház és az adattó közötti különbségről. Általában az emberek azt kérdezik:
- Mi a helyzet az adattárral?
- Az adattárházat lecseréljük egy adattóra, vagy bővítjük?
- Lehetséges még adattó nélkül?
Röviden: nincs egyértelmű válasz. Minden az adott helyzettől, a csapat képességeitől és a költségvetéstől függ. Például egy adattárház áttelepítése Oracle-re AWS-re, és adattó létrehozása az Amazon leányvállalata által - Woot - .
Másrészt a Snowflake szállító azt mondja, hogy többé nem kell data Lake-re gondolni, mivel az adatplatformjuk (2020-ig adattárház volt) lehetővé teszi az adattó és az adattárház kombinálását. Nem sokat dolgoztam a Snowflake-kel, és ez valóban egy egyedülálló termék, amely képes erre. A kibocsátás ára más kérdés.
Összefoglalva, személyes véleményem az, hogy továbbra is szükségünk van egy adattárházra, mint a jelentéskészítés fő adatforrására, és ami nem fér bele, azt egy adattóban tároljuk. Az analitika teljes szerepe az, hogy könnyű hozzáférést biztosítson a vállalkozások számára a döntéshozatalhoz. Bármit is mondjunk, az üzleti felhasználók hatékonyabban dolgoznak egy adattárral, mint egy adattóval, például az Amazonban - van Redshift (analitikai adattárház) és van Redshift Spectrum/Athena (SQL interfész az S3-ban lévő adattóhoz, amely a Hive/Presto). Ugyanez vonatkozik más modern analitikai adattárházakra is.
Nézzünk egy tipikus adattárház-architektúrát:
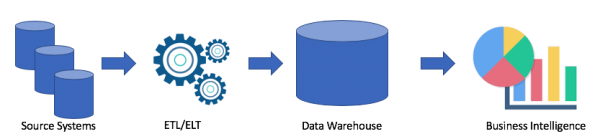
Ez egy klasszikus megoldás. Forrásrendszereink vannak, az ETL/ELT segítségével egy analitikus adattárházba másoljuk az adatokat, és összekapcsoljuk egy Business Intelligence megoldással (az én kedvencem a Tableau, mi van a tieddel?).
Ennek a megoldásnak a következő hátrányai vannak:
- Az ETL/ELT műveletek időt és erőforrásokat igényelnek.
- Általános szabály, hogy az analitikai adattárházban az adatok tárolására szolgáló memória nem olcsó (például Redshift, BigQuery, Teradata), mivel egy teljes klasztert kell vásárolnunk.
- Az üzleti felhasználók hozzáférhetnek a tisztított és gyakran összesített adatokhoz, és nem férnek hozzá a nyers adatokhoz.
Természetesen minden az Ön esetétől függ. Ha nincs problémája az adattárházával, akkor egyáltalán nincs szüksége Data Lake-re. De ha problémák merülnek fel a helyhiányból, az áramellátásból vagy az árból, amely kulcsszerepet játszik, akkor fontolóra veheti az adattó lehetőségét. Ez az oka annak, hogy az adattó nagyon népszerű. Íme egy példa egy Data Lake architektúrára:
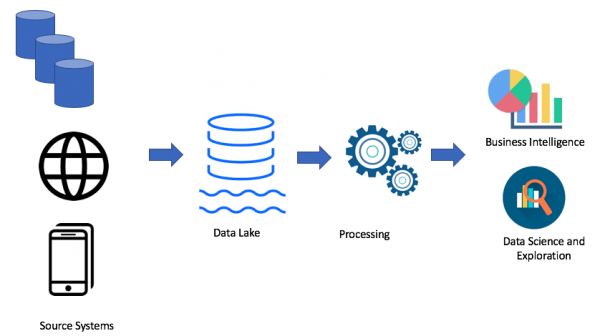
A Data Lake megközelítést használva nyers adatokat töltünk be adattónkba (kötegelt vagy streaming), majd szükség szerint feldolgozzuk az adatokat. Az adattó lehetővé teszi az üzleti felhasználók számára, hogy saját adatátalakításokat hozzanak létre (ETL/ELT), vagy elemezzék az adatokat Business Intelligence megoldásokban (ha a szükséges illesztőprogram rendelkezésre áll).
Minden elemzési megoldás célja az üzleti felhasználók kiszolgálása. Ezért mindig az üzleti követelményeknek megfelelően kell dolgoznunk. (Az Amazonnál ez az egyik alapelv – visszafelé dolgozni).
Egy adattárházzal és egy adattóval együtt dolgozva mindkét megoldást összehasonlíthatjuk:
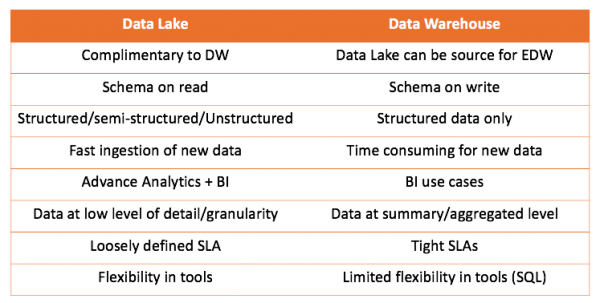
A levonható fő következtetés az, hogy az adattárház nem versenyez az adattóval, hanem kiegészíti azt. De rajtad múlik, hogy mi a megfelelő az esetedben. Mindig érdekes kipróbálni magad, és levonni a megfelelő következtetéseket.
Elmesélném továbbá az egyik esetet, amikor elkezdtem használni az adattó megközelítést. Minden elég triviális, próbáltam ELT eszközt (nálunk Matillion ETL volt) és Amazon Redshiftet használni, a megoldásom működött, de nem felelt meg a követelményeknek.
Webnaplókat kellett készítenem, átalakítanom és összesíteni kellett, hogy 2 esetre szolgálhassak adatot:
- A marketingcsapat a bottevékenységet kívánta elemezni a SEO szempontjából
- Az IT meg akarta vizsgálni a webhely teljesítménymutatóit
Nagyon egyszerű, nagyon egyszerű rönkök. Íme egy példa:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188
192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57
"GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2
arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067
"Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012"
1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"Egy fájl 1-4 megabájtot nyomott.
De volt egy nehézség. 7 domainünk volt szerte a világon, és egy nap alatt 7000 ezer fájl jött létre. Ez nem sokkal nagyobb mennyiség, mindössze 50 gigabájt. De a Redshift klaszterünk mérete is kicsi volt (4 csomópont). Egy fájl hagyományos módon történő betöltése körülbelül egy percig tartott. Vagyis a probléma nem oldódott meg homlokegyenest. És ez volt a helyzet, amikor úgy döntöttem, hogy az adattó megközelítést használom. A megoldás valahogy így nézett ki:
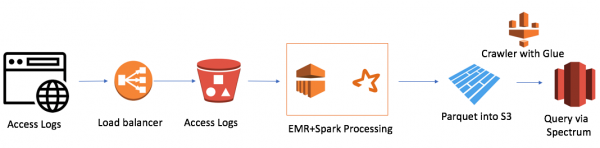
Nagyon egyszerű (meg akarom jegyezni, hogy a felhőben való munka előnye az egyszerűség). Használtam:
- AWS Elastic Map Reduce (Hadoop) a számítási teljesítményért
- Az AWS S3 fájltárolóként képes titkosítani az adatokat és korlátozni a hozzáférést
- Spark mint InMemory számítási teljesítmény és PySpark a logikai és adatátalakításhoz
- Spark eredményeként parketta
- Az AWS Glue Crawler metaadatgyűjtőként az új adatokról és partíciókról
- Redshift Spectrum mint SQL interfész az adattóhoz a meglévő Redshift felhasználók számára
A legkisebb EMR+Spark-fürt 30 perc alatt feldolgozta a teljes fájlköteget. Vannak más esetek az AWS-hez, különösen sok az Alexához kapcsolódóan, ahol sok adat van.
Nemrég tudtam meg, hogy a Data Lake egyik hátránya a GDPR. A probléma az, hogy amikor a kliens kéri a törlést, és az adatok valamelyik fájlban vannak, nem tudjuk használni az adatkezelési nyelvet és a TÖRLÉS műveletet, mint egy adatbázisban.
Remélem, ez a cikk tisztázza az adattárház és az adattó közötti különbséget. Ha felkeltette érdeklődését, le tudom fordítani több cikkemet, vagy szakemberek cikkeit, amelyeket olvasok. És meséljen azokról a megoldásokról, amelyekkel dolgozom, és azok felépítéséről.
Forrás: will.com
