


A Patroni fő célja, hogy magas szintű rendelkezésre állást biztosítson a PostgreSQL számára. De a Patroni csak egy sablon, nem egy kész eszköz (ami általában a dokumentációban szerepel). Első pillantásra, miután beállította a Patronit a tesztlaborban, láthatja, milyen nagyszerű eszközről van szó, és milyen könnyen kezeli a klaszter feltörésének kísérleteit. A gyakorlatban azonban termelési környezetben nem mindig történik minden olyan szépen és elegánsan, mint egy tesztlaborban.

Mesélek egy kicsit magamról. Rendszergazdaként kezdtem. Webfejlesztésben dolgozott. 2014 óta dolgozom a Data Egretnél. A cég tanácsadással foglalkozik a Postgres területén. Mi pedig pontosan a Postgres-t szolgáljuk ki, és a Postgres-szel dolgozunk nap mint nap, így más-más szakértelemmel rendelkezünk az üzemeltetéshez.
2018 végén pedig lassan elkezdtük használni a Patronit. És némi tapasztalat is felhalmozódott. Valahogy diagnosztizáltuk, hangoltuk, és eljutottunk a legjobb gyakorlatainkhoz. És ebben a jelentésben róluk fogok beszélni.
A Postgresen kívül szeretem a következőket is: LinuxSzeretek vele babrálni és felfedezni, és imádok kerneleket készíteni. Imádom a virtualizációt, a konténereket, a Dockert és a Kubernetest. Mindez azért érdekel, mert a régi adminisztrátori szokásaim kezdenek felzárkózni. Szeretek a monitorozással babrálni. Szeretem a Postgreshez kapcsolódó adminisztrációs dolgokat is, mint például a replikáció és a biztonsági mentések. Szabadidőmben pedig Go-ban írok. Nem vagyok szoftvermérnök, csak magamnak írok Go-ban. És élvezem.

- Azt hiszem, sokan tudják, hogy a Postgres nem rendelkezik HA-val (High Availability). A HA eléréséhez telepíteni kell valamit, konfigurálnia kell, erőfeszítéseket kell tennie és be kell szereznie.
- Számos eszköz létezik, és a Patroni az egyik, amely nagyon klassz és nagyon jól megoldja a HA-t. De ha mindezt egy tesztlaborba helyezzük és futtatjuk, láthatjuk, hogy minden működik, reprodukálhatunk néhány problémát, megnézhetjük, hogyan szolgálja ki őket a Patroni. És látni fogjuk, hogy minden remekül működik.
- A gyakorlatban azonban különböző problémákkal szembesültünk. És ezekről a problémákról fogok beszélni.
- Elmondom, hogyan diagnosztizáltuk, mit módosítottunk – segített-e vagy sem.

- A Patronit nem árulom el, mert guglizhatsz az interneten, megnézheted a konfigurációs fájlokat, hogy megértsd, hogyan is kezdődik, hogyan van beállítva. Megértheti a sémákat, architektúrákat, információkat találhat róla az interneten.
- Nem fogok beszélni valaki más tapasztalatairól. Csak azokról a problémákról fogok beszélni, amelyekkel szembesültünk.
- És nem fogok beszélni azokról a problémákról, amelyek kívül esnek a Patroni-on és a PostgreSQL-en. Ha például az egyensúlyozással kapcsolatos problémák merülnek fel, amikor a klaszterünk összeomlott, arról nem beszélek.

És egy kis felelősségkizárás, mielőtt elkezdjük a jelentésünket.
Mindezek a problémák, amelyekkel találkoztunk, az első 6-7-8 hónapban jelentkeztek. Idővel eljutottunk belső legjobb gyakorlatainkhoz. És a problémáink megszűntek. Ezért a jelentést körülbelül hat hónapja jelentették be, amikor minden frissen járt a fejemben, és tökéletesen emlékeztem az egészre.
A riport készítése során már felvetettem régi poszthalált, nézegettem a rönköket. A problémák elemzése során pedig egyes részletek feledésbe merülhetnek, vagy egyes részleteket nem sikerült maradéktalanul kivizsgálni, így néhol úgy tűnhet, hogy a problémákat nem veszik át teljesen, vagy hiányos az információ. Ezért arra kérem, hogy bocsásson meg ezért a pillanatért.

Mi az a Patroni?
- Ez egy sablon a HA felépítéséhez. Ez áll a dokumentációban. És az én szemszögemből ez egy nagyon helyes pontosítás. A Patroni nem egy ezüstgolyó, amely minden problémáját megoldja, vagyis erőfeszítéseket kell tennie, hogy működjön és hasznot hozzon.
- Ez egy ügynökszolgáltatás, amely minden adatbázis-szolgáltatásra telepítve van, és egyfajta indítórendszer a Postgres számára. Elindítja a Postgrest, leállítja, újraindítja, újrakonfigurálja és megváltoztatja a fürt topológiáját.
- Ennek megfelelően a fürt állapotának, jelenlegi reprezentációjának tárolásához, ahogy kinéz, valamilyen tárhelyre van szükség. És ebből a szempontból a Patroni az állapot külső rendszerben való tárolásának útját választotta. Ez egy elosztott konfigurációs tárolórendszer. Ez lehet Etcd, Consul, ZooKeeper vagy kubernetes Etcd, vagyis ezek közül az opciók egyike.
- A Patroni egyik jellemzője pedig az, hogy az autofiler-t a dobozból kiveheti, csak beállításával. Ha összehasonlításnak vesszük a Repmgr-t, akkor ott szerepel a filer. A Repmgr-rel átállást kapunk, de ha autofilert akarunk, akkor azt is be kell állítani. A Patroninak már van egy automatikus szűrője.
- És sok más dolog is van. Például konfigurációk karbantartása, új replikák öntése, biztonsági mentés stb. De ez kívül esik a jelentés keretein, nem beszélek róla.

És egy kis eredmény, hogy a Patroni fő feladata az autofile jól és megbízható elkészítése, hogy a fürtünk működőképes maradjon, és az alkalmazás ne vegye észre a fürt topológiájában bekövetkezett változásokat.

De amikor elkezdjük használni a Patronit, a rendszerünk kicsit bonyolultabb lesz. Ha korábban volt Postgres, akkor Patroni használatakor magát a Patronit kapjuk, DCS-t kapunk, ahol az állapot tárolódik. És mindennek működnie kell valahogy. Szóval mi romolhat el?
Május szünet:
- A Postgres eltörhet. Lehet mester vagy replika, az egyik meghibásodhat.
- Maga a Patroni eltörhet.
- Az állapot tárolására szolgáló DCS megszakadhat.
- És a hálózat megszakadhat.
Mindezeket a szempontokat figyelembe fogom venni a jelentésben.

Az eseteket amint bonyolultabbá válnak, nem abból a szempontból fogom megvizsgálni, hogy az ügy sok összetevőt foglal magában. És a szubjektív érzések szempontjából, hogy ez a tok nehéz volt számomra, nehéz volt szétszedni ... és fordítva, néhány tok könnyű volt, és könnyű volt szétszedni.

És az első eset a legegyszerűbb. Ez a helyzet, amikor vettünk egy adatbázis-fürtöt, és ugyanabban a fürtben telepítettük a DCS-tárolónkat. Ez a leggyakoribb hiba. Ez egy hiba az épületarchitektúrák építésénél, vagyis a különböző komponensek egy helyen történő kombinálásakor.
Szóval, volt egy irattár, menjünk foglalkozni a történtekkel.

És itt arra vagyunk kíváncsiak, hogy mikor történt a fájl. Vagyis minket ez a pillanat érdekel, amikor a klaszter állapota megváltozott.
De a reszelő nem mindig azonnali, azaz nem vesz igénybe időegységet, késleltethető. Hosszan tartó lehet.
Ezért van kezdési és befejezési ideje, azaz folyamatos esemény. És minden eseményt három intervallumra osztunk: van időnk a filer előtt, a filer alatt és a filer után. Vagyis minden eseményt ebben az idővonalban veszünk figyelembe.

És az első dolog, amikor egy irat történt, megkeressük a történtek okát, mi volt az oka annak, ami az irathoz vezetett.
Ha a rönköket nézzük, akkor klasszikus Patroni rönkök lesznek. Elmondja bennük, hogy a szerver lett a mester, és a mester szerepe átszállt erre a csomópontra. Itt van kiemelve.

Ezután meg kell értenünk, hogy miért történt a fájlkezelő, azaz milyen események történtek, amelyek hatására a főszerep egyik csomópontból a másikba került. És ebben az esetben minden egyszerű. Hiba történt a tárolórendszerrel való interakció során. A mester rájött, hogy nem tud dolgozni DCS-vel, vagyis valami probléma van az interakcióval. És azt mondja, hogy nem lehet többé mester, és lemond. Ez a „lefokozott én” sor pontosan ezt mondja.

Ha megnézzük a fájlt megelőző eseményeket, ott pontosan azokat az okokat láthatjuk, amelyek a varázsló folytatását okozták.
Ha megnézzük a Patroni naplókat, látni fogjuk, hogy sok hibánk, időtúllépésünk van, vagyis a Patroni ügynök nem tud dolgozni DCS-vel. Ebben az esetben ez a Consul ügynök, aki a 8500-as porton kommunikál.
A probléma az, hogy a Patroni és az adatbázis ugyanazon a gépen fut. A Consul szerverei is ugyanazon a gépen futottak. Azzal, hogy terhelést generáltunk a szerveren, problémákat okoztunk a következőknek: szervereket Konzul. Nem tudtak normálisan kommunikálni.

Egy idő után, amikor alábbhagyott a terhelés, Patroniunk ismét kommunikálni tudott az ügynökökkel. A normál munka folytatódott. És ismét ugyanaz a Pgdb-2 szerver lett a mester. Vagyis volt egy kis átbillentés, aminek következtében a csomópont lemondott a mester jogköréről, majd újra átvette azokat, vagyis minden visszatért a régi állapotába.

És ez tekinthető téves riasztásnak, vagy úgy, hogy Patroni mindent jól csinált. Vagyis rájött, hogy nem tudja fenntartani a klaszter állapotát, és megvonta a tekintélyét.
És itt a probléma abból fakadt, hogy a Consul szerverek ugyanazon a hardveren vannak, mint az alapok. Ennek megfelelően bármilyen terhelés: akár a lemezek, akár a processzorok terhelése befolyásolja a Consul klaszterrel való interakciót is.

És úgy döntöttünk, hogy nem szabad együtt élni, külön klasztert rendeltünk a konzulnak. És Patroni már külön Consul-lal dolgozott, vagyis volt egy külön Postgres-klaszter, egy külön konzuli klaszter. Ez egy alapvető utasítás arra vonatkozóan, hogyan kell ezeket a dolgokat hordozni és tartani, hogy ne éljenek együtt.
Lehetőségként a ttl, loop_wait, újratry_timeout paramétereket csavarhatja, azaz megpróbálhatja túlélni ezeket a rövid távú terhelési csúcsokat ezen paraméterek növelésével. De ez nem a legmegfelelőbb lehetőség, mert ez a terhelés időben hosszú lehet. És egyszerűen túllépünk ezen paraméterek határain. És lehet, hogy ez nem igazán segít.
Az első probléma, amint érti, egyszerű. Elvittük és összeraktuk a DCS-t az alappal, volt egy probléma.

A második probléma hasonló az elsőhöz. Annyiban hasonló, hogy ismét interoperabilitási problémáink vannak a DCS rendszerrel.

Ha megnézzük a naplókat, azt látjuk, hogy ismét kommunikációs hiba van. És Patroni azt mondja, hogy nem tudok kommunikálni a DCS-vel, így az aktuális mester replika módba lép.
Az öreg mesterből replika lesz, itt a Patroni úgy működik, ahogy kell. A pg_rewind futtatásával visszatekerheti a tranzakciós naplót, majd csatlakozik az új mesterhez, hogy utolérje az új mestert. Itt Patroni úgy dolgozik, ahogy kell.

Itt meg kell találnunk azt a helyet, amely megelőzte a reszelőt, vagyis azokat a hibákat, amelyek miatt lettünk reszelő. És ebben a tekintetben a Patroni naplókkal meglehetősen kényelmes dolgozni. Bizonyos időközönként ugyanazokat az üzeneteket írja. És ha gyorsan elkezdjük görgetni ezeket a naplókat, akkor a naplókból látni fogjuk, hogy a naplók megváltoztak, ami azt jelenti, hogy bizonyos problémák kezdődtek. Gyorsan visszatérünk erre a helyre, meglátjuk, mi történik.
És normál helyzetben a naplók valahogy így néznek ki. A zár tulajdonosát ellenőrzik. És ha például a tulajdonos megváltozott, akkor előfordulhat olyan esemény, amelyre a Patroninak reagálnia kell. De ebben az esetben jól vagyunk. Keressük azt a helyet, ahol a hibák kezdődtek.

És miután eljutottunk addig a pontig, ahol a hibák elkezdtek megjelenni, látjuk, hogy automatikus fájlváltás történt. És mivel a hibáink a DCS-sel való interakcióhoz kapcsolódnak, és esetünkben a Consul-t használtuk, megnézzük a Consul naplóit is, hogy mi történt ott.
Nagyjából összehasonlítva a bejelentő és a Consul naplókban szereplő időt, azt látjuk, hogy a Consul klaszterben lévő szomszédaink kételkedni kezdtek a konzuli klaszter többi tagjának létezésében.

És ha megnézi a többi konzuli ügynök naplóját, azt is láthatja, hogy ott valamiféle hálózati összeomlás folyik. A Consul klaszter minden tagja pedig kételkedik egymás létezésében. És ez volt a lendület a reszelő számára.
Ha megnézi, hogy mi történt ezek előtt a hibák előtt, akkor láthatja, hogy mindenféle hiba van, például határidő, RPC leesett, vagyis egyértelműen a Consul klaszter tagjainak egymás közötti interakciójában van valami probléma. .

A legegyszerűbb válasz a hálózat javítása. De nekem, a dobogón állva, könnyű ezt mondani. De a körülmények olyanok, hogy az ügyfél nem mindig engedheti meg magának a hálózat javítását. Lehet, hogy egy egyenáramban él, és nem tudja megjavítani a hálózatot, befolyásolni a berendezést. És ezért más lehetőségekre van szükség.

Vannak lehetőségek:
- A legegyszerűbb lehetőség, ami véleményem szerint még a dokumentációban is szerepel, a Consul ellenőrzések letiltása, vagyis egyszerűen át kell adni egy üres tömböt. És mondjuk a konzuli ügynöknek, hogy ne használjon csekket. Ezekkel az ellenőrzésekkel figyelmen kívül hagyhatjuk ezeket a hálózati viharokat, és nem kezdeményezhetünk fájlkezelőt.
- Egy másik lehetőség a raft_multiplier kétszeri ellenőrzése. Ez magának a Consul szervernek a paramétere. Alapértelmezés szerint 5-re van állítva. Ezt az értéket az állomásoztatási környezetekre vonatkozó dokumentáció ajánlja. Valójában ez befolyásolja a Consul hálózat tagjai közötti üzenetváltás gyakoriságát. Valójában ez a paraméter befolyásolja a Consul klaszter tagjai közötti szolgáltatási kommunikáció sebességét. A termeléshez pedig már javasolt csökkenteni, hogy a csomópontok gyakrabban cseréljenek üzenetet.
- Egy másik lehetőség, amellyel előálltunk, hogy növeljük a Consul folyamatok prioritását az operációs rendszer folyamatütemezőjének egyéb folyamatai között. Van egy ilyen „szép” paraméter, csak a folyamatok prioritását határozza meg, amit az OS ütemező figyelembe vesz az ütemezésnél. Csökkentettük a konzuli ügynökök szép értéket is, pl. növelte a prioritást, hogy az operációs rendszer több időt adjon a Consul folyamatoknak a munkára és a kód végrehajtására. A mi esetünkben ez megoldotta a problémánkat.
- Egy másik lehetőség, hogy nem használja a Consul-t. Van egy barátom, aki nagy támogatója az Etcd-nek. És rendszeresen vitatkozunk vele, hogy melyik a jobb stb. vagy konzul. De abban a tekintetben, hogy melyik a jobb, általában egyetértünk vele abban, hogy a Consulnak van egy ügynöke, amelynek minden csomóponton futnia kell egy adatbázissal. Vagyis a Patroni és a Consul klaszter interakciója ezen az ügynökön keresztül megy végbe. És ez az ügynök szűk keresztmetszetté válik. Ha valami történik az ügynökkel, akkor Patroni többé nem tud együttműködni a Consul klaszterrel. És ez a probléma. Az Etcd-tervben nincs ügynök. A Patroni közvetlenül tud dolgozni az Etcd-kiszolgálók listájával, és már kommunikál velük. Ebben a tekintetben, ha az Etcd-t használja a cégében, akkor az Etcd valószínűleg jobb választás lesz, mint a Consul. De minket, ügyfeleinket mindig korlátoz az ügyfél által választott és használt. És nagyrészt minden ügyfelünk számára van konzulunk.
- És az utolsó pont a paraméterértékek felülvizsgálata. Felemelhetjük ezeket a paramétereket abban a reményben, hogy rövid távú hálózati problémáink rövidek lesznek, és nem esnek ki ezen paraméterek tartományán. Így csökkenthetjük a Patroni agresszivitását az automatikus fájlkezelésre, ha hálózati problémák lépnek fel.
Azt hiszem, sokan, akik a Patronit használják, ismerik ezt a parancsot.
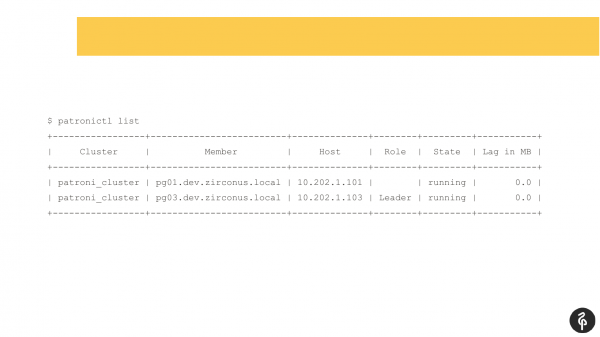
Ez a parancs a fürt aktuális állapotát mutatja. És első pillantásra ez a kép normálisnak tűnhet. Van mesterünk, van replikánk, nincs replikációs késés. De ez a kép egészen addig normális, amíg nem tudjuk, hogy ennek a klaszternek három csomópontnak kell lennie, nem kettőnek.

Ennek megfelelően volt egy autofile. És az automatikus fájl után a replikánk eltűnt. Ki kell derítenünk, miért tűnt el, és vissza kell hoznunk, helyre kell állítani. És ismét a naplókhoz megyünk, és megnézzük, miért volt automatikus fájlváltás.

Ebben az esetben a második replika lett a mester. Itt minden rendben.

És meg kell néznünk azt a replikát, amely leesett, és amely nincs a klaszterben. Megnyitjuk a Patroni naplókat, és azt látjuk, hogy problémánk volt a fürthöz való csatlakozás során a pg_rewind szakaszban. A fürthöz való csatlakozáshoz vissza kell tekerni a tranzakciós naplót, le kell kérni a szükséges tranzakciós naplót a mestertől, és ezzel utol kell érni a mestert.
Ebben az esetben nincs tranzakciós naplónk, és a replika nem indulhat el. Ennek megfelelően hibával leállítjuk a Postgrest. Ezért nincs benne a klaszterben.

Meg kell értenünk, hogy miért nincs a fürtben, és miért nem voltak naplók. Elmegyünk az új mesterhez, és megnézzük, mi van a naplókban. Kiderült, hogy amikor a pg_rewind megtörtént, egy ellenőrzési pont történt. A régi tranzakciós naplók egy részét pedig egyszerűen átnevezték. Amikor a régi mester megpróbált csatlakozni az új mesterhez és lekérdezni ezeket a naplókat, már átnevezték őket, csak nem léteztek.

Összehasonlítottam az időbélyegeket, amikor ezek az események megtörténtek. És ott a különbség szó szerint 150 ezredmásodperc, vagyis az ellenőrzőpont 369 ezredmásodperc alatt készült el, a WAL szegmenseket átnevezték. És szó szerint 517-ben, 150 ezredmásodperc után megkezdődött a visszatekerés a régi replikán. Vagyis szó szerint 150 ezredmásodperc elég volt nekünk ahhoz, hogy a replika ne tudjon csatlakozni és keresni.

Mik a lehetőségek?
Kezdetben replikációs slotokat használtunk. Úgy gondoltuk, hogy jó. Bár a működés első szakaszában kikapcsoltuk a nyílásokat. Számunkra úgy tűnt, hogy ha a slotok sok WAL-szegmenst halmoznak fel, akkor eldobhatjuk a mestert. El fog esni. Egy ideig szenvedtünk résidő nélkül. És rájöttünk, hogy résidőkre van szükségünk, visszaadtuk a résidőket.
De van itt egy probléma, hogy amikor a master a replikához megy, akkor törli a slotokat és törli a WAL szegmenseket a slotokkal együtt. A probléma kiküszöbölése érdekében úgy döntöttünk, hogy megemeljük a wal_keep_segments paramétert. Alapértelmezés szerint 8 szegmens. Emeltük 1-re, és megnéztük, mennyi szabad helyünk van. És 000 gigabájtot adtunk a wal_keep_segments-re. Vagyis váltáskor mindig van tartalékunk 16 gigabájtnyi tranzakciós naplóból az összes csomóponton.
És plusz - továbbra is releváns a hosszú távú karbantartási feladatoknál. Tegyük fel, hogy frissítenünk kell az egyik replikát. És ki akarjuk kapcsolni. Frissítenünk kell a szoftvert, esetleg az operációs rendszert, valami mást. És amikor kikapcsolunk egy replikát, az adott replika nyílása is eltávolításra kerül. És ha egy kis wal_keep_segments-t használunk, akkor a replika hosszú hiányával a tranzakciós naplók elvesznek. Felállítunk egy replikát, lekéri azokat a tranzakciós naplókat, ahol leállt, de lehet, hogy nincsenek a masteren. És a replika sem tud majd csatlakozni. Ezért nagy készletet vezetünk folyóiratokból.

Van gyártóbázisunk. Vannak már folyamatban lévő projektek.
Volt egy irattartó. Bementünk és megnéztük - minden rendben van, a replikák a helyükön vannak, nincs replikációs késés. A naplókban sincs hiba, minden rendben van.
A termékcsapat szerint kellene néhány adat, de egy forrásból látjuk, de nem látjuk az adatbázisban. És meg kell értenünk, mi történt velük.

Nyilvánvaló, hogy a pg_rewind kihagyta őket. Ezt azonnal megértettük, de elmentünk megnézni, mi történik.

A naplókban mindig megtaláljuk, hogy mikor történt az irattartó, ki lett a mester, és meg tudjuk határozni, hogy ki volt a régi mester, és mikor akart replikává válni, vagyis ezekre a naplókra van szükségünk ahhoz, hogy megtudjuk a tranzakciós naplók mennyiségét elveszett.
A régi mesterünk újraindult. És Patroni regisztrálva volt az autorunban. Elindította a Patronit. Ezután elindította a Postgrest. Pontosabban, a Postgres elindítása és a replika elkészítése előtt a Patroni elindította a pg_rewind folyamatot. Ennek megfelelően a tranzakciós naplók egy részét törölte, újakat töltött le és csatlakozott. Itt Patroni okosan dolgozott, vagyis a várakozásoknak megfelelően. A klaszter helyreállt. 3 csomópontunk volt, a filer után 3 csomópont - minden rendben van.

Elvesztettünk néhány adatot. És meg kell értenünk, mennyit veszítettünk. Éppen azt a pillanatot keressük, amikor visszatekertünk. Ilyen naplóbejegyzésekben találjuk. A visszatekerés elindult, ott csinált valamit és véget ért.

Meg kell találnunk azt a pozíciót a tranzakciós naplóban, ahol a régi mester abbahagyta. Ebben az esetben ez a jel. És szükségünk van egy második jelre, vagyis arra a távolságra, amellyel a régi mester különbözik az újtól.
Vegyük a szokásos pg_wal_lsn_diff-et, és összehasonlítjuk ezt a két jelölést. És ebben az esetben 17 megabájtot kapunk. Sokat vagy keveset, mindenki döntse el maga. Mert valakinek 17 megabájt nem sok, valakinek sok és elfogadhatatlan. Itt minden egyén maga határozza meg a vállalkozás igényeinek megfelelően.

De mit tudtunk meg magunktól?
Először is magunknak kell eldöntenünk – mindig szükségünk van a Patroninak a rendszer újraindítása utáni automatikus indításra? Gyakran megesik, hogy el kell mennünk az öreg mesterhez, megnézni, meddig jutott el. Esetleg ellenőrizze a tranzakciós napló egyes szegmenseit, és nézze meg, mi van ott. És annak megértéséhez, hogy elveszíthetjük-e ezeket az adatokat, vagy önálló módban kell futtatnunk a régi mestert az adatok kihúzásához.
És csak ezután kell eldöntenünk, hogy eldobhatjuk-e ezeket az adatokat, vagy visszaállíthatjuk, csatlakoztassa ezt a csomópontot replikaként a fürtünkhöz.
Ezen kívül van egy "maximum_lag_on_failover" paraméter. Alapértelmezés szerint, ha a memóriám nem szolgál, ennek a paraméternek az értéke 1 megabájt.
Hogyan dolgozik? Ha a replikánk 1 megabájt adattal lemarad a replikációs késleltetésben, akkor ez a replika nem vesz részt a választásokon. És ha hirtelen fileover történik, a Patroni megnézi, hogy mely replikák vannak lemaradva. Ha sok tranzakciós napló mögött állnak, nem válhatnak mesterré. Ez egy nagyon jó biztonsági funkció, amely megakadályozza, hogy sok adatot veszítsen.
De van egy probléma, hogy a Patroni-fürtben és a DCS-ben a replikációs késés bizonyos időközönként frissül. Szerintem a 30 másodperc az alapértelmezett ttl érték.
Ennek megfelelően előfordulhat olyan helyzet, hogy a replikákhoz egy replikációs késés van a DCS-ben, de valójában teljesen más lag van, vagy egyáltalán nincs késés, vagyis ez a dolog nem realtime. És ez nem mindig tükrözi a valós képet. És nem érdemes fantáziadús logikát csinálni rajta.
A veszteség kockázata pedig mindig fennáll. És a legrosszabb esetben egy képlet, átlagos esetben pedig egy másik képlet. Vagyis amikor megtervezzük a Patroni megvalósítását, és felmérjük, hogy mennyi adatot veszíthetünk, akkor ezekre a képletekre kell hagyatkoznunk, és nagyjából elképzelni, hogy mennyi adatot veszíthetünk.
És van egy jó hír. Amikor az öreg mester előrement, bizonyos háttérfolyamatok miatt mehet is előre. Vagyis valami autovákuum volt, megírta az adatokat, elmentette a tranzakciós naplóba. És könnyen figyelmen kívül hagyhatjuk és elveszíthetjük ezeket az adatokat. Ebben nincs semmi probléma.

És így néznek ki a naplók, ha a maximum_lag_on_failover be van állítva, és filer történt, és új mestert kell kiválasztani. A replika képtelennek tartja magát a választásokon való részvételre. És nem hajlandó részt venni a versenyben a vezetőért. És várja az új mester kiválasztását, hogy aztán csatlakozhasson hozzá. Ez egy további intézkedés az adatvesztés ellen.

Itt van egy termékcsapatunk, aki azt írta, hogy terméküknek problémái vannak a Postgres-szel. Ugyanakkor magát a mastert nem lehet elérni, mert SSH-n keresztül nem érhető el. És az autofile sem történik meg.
Ez a gazdagép újraindításra kényszerült. Az újraindítás miatt egy auto-file történt, bár kézi auto-fájlt is lehetett csinálni, ahogy most értem. Az újraindítás után pedig már megyünk is megnézni, hogy mi volt az aktuális mesterrel.
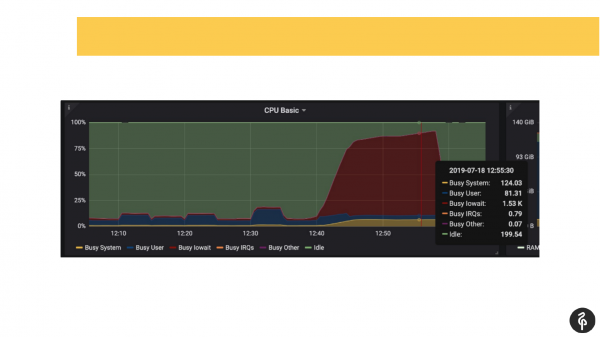
Ugyanakkor előre tudtuk, hogy gondjaink vannak a lemezekkel, vagyis már megfigyelésből tudtuk, hogy hol kell ásni és mit kell keresni.

Bementünk a postgres naplóba, elkezdtük nézni, mi történik ott. Láttunk olyan kötelezettségeket, amelyek egy, két, három másodpercig tartanak, ami egyáltalán nem normális. Láttuk, hogy az autovákuumunk nagyon lassan és furcsán indul be. És láttunk ideiglenes fájlokat a lemezen. Vagyis ezek mind a lemezekkel kapcsolatos problémák jelei.

Megnéztük a rendszer dmesg-jét (kernel log). És láttuk, hogy problémáink vannak az egyik lemezzel. A lemez alrendszere a Raid szoftver volt. Megnéztük a /proc/mdstat fájlt, és azt láttuk, hogy hiányzik egy meghajtó. Vagyis van egy 8 lemezből álló Raid, nekünk egy hiányzik. Ha figyelmesen megnézi a diát, akkor a kimenetben láthatja, hogy ott nincs sde. Nálunk feltételesen kiesett a lemez. Ez lemezproblémákat váltott ki, és az alkalmazások is problémákat tapasztaltak a Postgres-fürttel való munka során.

És ebben az esetben a Patroni semmiben nem segítene nekünk, mert a Patroninak nem az a feladata, hogy figyelje a szerver állapotát, a lemez állapotát. Az ilyen helyzeteket pedig külső megfigyeléssel kell figyelemmel kísérnünk. Gyorsan hozzáadtuk a lemezfigyelést a külső felügyelethez.
És felmerült egy ilyen gondolat – a kerítés vagy a felügyeleti szoftver segíthet rajtunk? Úgy gondoltuk, hogy ebben az esetben aligha segített volna nekünk, mert a problémák alatt Patroni továbbra is együttműködött a DCS klaszterrel, és nem látott problémát. Vagyis a DCS és a Patroni szemszögéből minden rendben volt a klaszterrel, bár valójában a lemezzel, az adatbázis elérhetőségével voltak gondok.
Szerintem ez az egyik legfurcsább probléma, amit nagyon sokáig kutattam, rengeteg naplót elolvastam, újraválogattam és cluster szimulátornak neveztem.

A probléma az volt, hogy a régi mester nem tudott normális replikává válni, vagyis a Patroni elindította, a Patroni megmutatta, hogy ez a csomópont replikaként van jelen, ugyanakkor nem volt normál replika. Most meglátod, miért. Ez az, amit elhallgattam a probléma elemzésétől.

És hogyan kezdődött az egész? Úgy indult, mint az előző probléma, tárcsafékekkel. Elköteleztük magunkat egy másodpercre, kettőre.

A kapcsolatokban megszakadtak, azaz elszakadtak az ügyfelek.

Különböző súlyosságú dugulások voltak.

És ennek megfelelően a lemez alrendszer nem nagyon érzékeny.

És számomra a legrejtélyesebb az azonnali leállítási kérelem, ami megérkezett. A Postgres három leállítási móddal rendelkezik:
- Kellemes, amikor megvárjuk, amíg minden ügyfél magától megszakad.
- Gyorsan kényszerítjük az ügyfeleket, hogy lekapcsolják, mert leállunk.
- És azonnal. Ebben az esetben az azonnali nem is mondja a klienseknek, hogy állítsák le, csak figyelmeztetés nélkül leáll. És minden kliensnek az operációs rendszer már küld egy RST-üzenetet (egy TCP-üzenetet arról, hogy a kapcsolat megszakadt, és a kliensnek nincs több fognivalója).
Ki küldte ezt a jelet? A Postgres háttérfolyamatok nem küldenek ilyen jeleket egymásnak, vagyis ez a kill-9. Ilyet nem küldenek egymásnak, csak reagálnak az ilyesmire, vagyis ez a Postgres vészhelyzeti újraindítása. Ki küldte, nem tudom.
Megnéztem az "utolsó" parancsot, és láttam egy embert, aki szintén bejelentkezett velünk erre a szerverre, de túl félénk voltam ahhoz, hogy kérdést tegyek fel. Talán ölés volt -9. Látnám kill -9-et a naplókban, mert Postgres azt mondja, kill -9 kellett, de nem láttam a naplókban.

Tovább nézve láttam, hogy Patroni elég sokáig nem írt a naplóba - 54 másodpercig. És ha összehasonlítunk két időbélyeget, körülbelül 54 másodpercig nem volt üzenet.
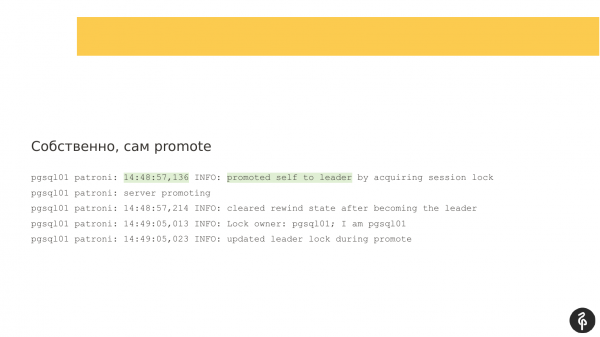
És ez idő alatt volt egy autofile. Patroni ismét remek munkát végzett itt. Öreg mesterünk nem volt elérhető, valami történt vele. És megkezdődött az új mester választása. Itt minden jól sikerült. A pgsql01-ünk lett az új vezető.

Van egy replikánk, amely mesterré vált. És van egy második válasz is. És voltak problémák a második replikával. Megpróbálta újrakonfigurálni. Ha jól értem, megpróbálta megváltoztatni a recovery.conf fájlt, újraindítani a Postgres-t, és csatlakozni az új mesterhez. 10 másodpercenként üzenetet ír, hogy próbálkozik, de nem jár sikerrel.

És ezen próbálkozások során azonnali leállási jelzés érkezik a régi mesterhez. A mester újraindul. És a helyreállítás is leáll, mert a régi mester újraindul. Vagyis a replika nem tud csatlakozni hozzá, mert leállítási módban van.

Valamikor működött, de a replikáció nem indult el.
Csak az a tippem, hogy a recovery.conf-ban volt egy régi főcím. És amikor megjelent egy új mester, a második replika még mindig megpróbált csatlakozni a régi mesterhez.
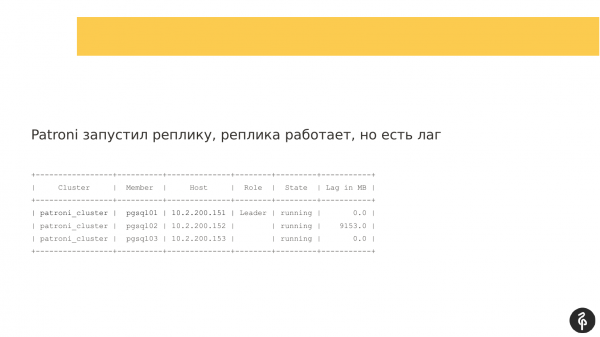
Amikor a Patroni elindult a második replikán, a csomópont elindult, de nem tudott replikálni. És létrejött egy replikációs késés, ami valahogy így nézett ki. Vagyis mindhárom csomópont a helyén volt, de a második csomópont lemaradt.
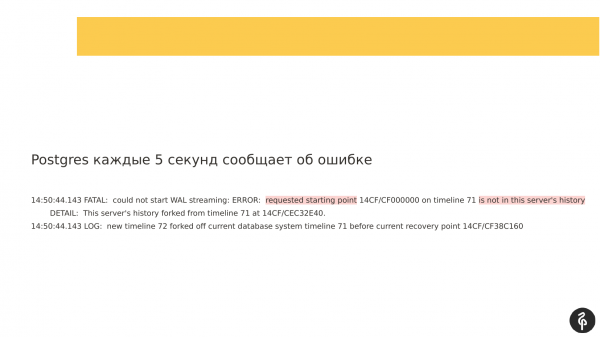
Ugyanakkor, ha megnézi az írt naplókat, láthatja, hogy a replikáció nem indulhat el, mert a tranzakciós naplók eltérőek voltak. És azok a tranzakciós naplók, amelyeket a master kínál, és amelyek a recovery.conf fájlban vannak megadva, egyszerűen nem illenek a jelenlegi csomópontunkhoz.

És itt elkövettem egy hibát. El kellett jönnöm, hogy megnézzem, mi van a recovery.conf-ban, hogy teszteljem azt a hipotézisemet, hogy rossz mesterhez kapcsolódtunk. De akkor még csak ezzel foglalkoztam és nem jutott eszembe, vagy láttam, hogy lemaradt a replika és újra kell tölteni, vagyis valahogy hanyagul dolgoztam. Ez volt az én közös.

30 perc múlva már jött is az admin, vagyis újraindítottam a Patronit a replikán. Már le is vetettem a végét, gondoltam, hogy utána kell tölteni. És arra gondoltam - újraindítom a Patronit, hátha valami jó is kiderül. A felépülés megkezdődött. És a bázis meg is nyílt, készen állt a kapcsolatok fogadására.
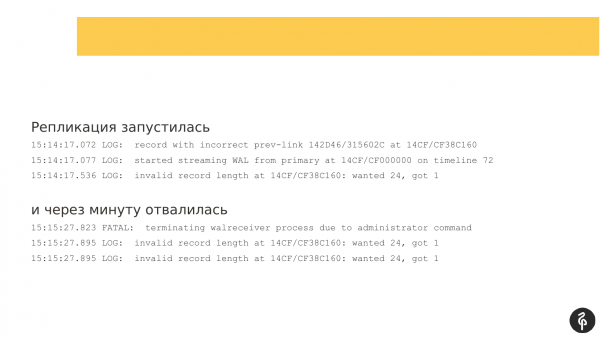
A replikáció elindult. De egy perccel később egy olyan hibával esett le, hogy a tranzakciós naplók nem megfelelőek számára.

Gondoltam újraindítom. Újraindítottam a Patronit, és nem a Postgrest, hanem a Patronit abban a reményben, hogy varázsütésre elindítja az adatbázist.

A replikáció újra elindult, de a tranzakciós naplóban eltértek a jelölések, nem egyeztek meg az előző indítási kísérlettel. A replikáció ismét leállt. És az üzenet már kissé más volt. És nem volt túl informatív számomra.

És akkor eszembe jut – mi van, ha újraindítom a Postgres-t, ekkor csinálok egy ellenőrzőpontot az aktuális mesteren, hogy egy kicsit előre mozgassam a pontot a tranzakciós naplóban, hogy a helyreállítás egy másik pillanattól kezdődjön? Ráadásul még mindig voltak WAL-készleteink.

Újraindítottam a Patronit, megcsináltam pár checkpointot a masteren, pár újraindítási pontot a replikán, amikor megnyílt. És segített. Sokáig gondolkodtam, miért segített és hogyan működik. És elkezdődött a replika. És a replikáció már nem szakadt.

Egy ilyen probléma számomra a rejtélyesebbek közé tartozik, amelyen még mindig azon jár a fejem, hogy mi is történt ott valójában.
Milyen következményekkel jár ez? A Patroni rendeltetésszerűen és hiba nélkül működhet. De ugyanakkor ez nem 100%-os garancia arra, hogy nálunk minden rendben van. A replika elindulhat, de lehet, hogy félig működő állapotban van, és az alkalmazás nem tud ilyen replikával dolgozni, mert régi adatok lesznek.
A filer után pedig mindig ellenőrizni kell, hogy minden rendben van-e a fürttel, vagyis megvan-e a szükséges számú replika, nincs replikációs késés.
És ahogy ezeken a kérdéseken megyünk keresztül, ajánlásokat fogok tenni. Megpróbáltam összevonni őket két diába. Valószínűleg az összes történetet össze lehetne vonni két diába, és csak elmondani.

A Patroni használatakor figyelni kell. Mindig tudnia kell, mikor történt automatikus fájlcsere, mert ha nem tudja, hogy volt automatikus fájlcseréje, akkor nincs befolyása a fürt felett. És ez rossz.
Minden reszelő után mindig manuálisan kell ellenőriznünk a klasztert. Arra kell ügyelnünk, hogy mindig naprakész számú replikával rendelkezzünk, ne legyen replikációs késés, ne legyen hiba a naplókban a streaming replikációval kapcsolatban, Patronival, DCS rendszerrel.
Az automatizálás sikeresen működhet, a Patroni nagyon jó eszköz. Működhet, de ez nem hozza a klasztert a kívánt állapotba. És ha nem tudunk róla, akkor bajban leszünk.
És Patroni nem egy ezüstgolyó. Továbbra is meg kell értenünk, hogyan működik a Postgres, hogyan működik a replikáció, és hogyan működik a Patroni a Postgres-szel, és hogyan történik a kommunikáció a csomópontok között. Erre azért van szükség, hogy meg tudja oldani a kezével kapcsolatos problémákat.

Hogyan közelítsem meg a diagnózis kérdését? Történt ugyanis, hogy különböző kliensekkel dolgozunk, és senkinek sincs ELK verem, és 6 konzol és 2 fül megnyitásával kell rendezni a naplókat. Az egyik lapon ezek az egyes csomópontokhoz tartozó Patroni naplók, a másik lapon ezek a Consul naplók, vagy ha szükséges, a Postgres. Ezt nagyon nehéz diagnosztizálni.
Milyen megközelítéseket alkalmaztam? Először is mindig megnézem, ha megérkezett a reszelő. És számomra ez egy vízválasztó. Megnézem, hogy mi történt a reszelő előtt, a reszelő alatt és a reszelő után. A fileovernek két jele van: ez a kezdési és a befejezési időpont.
Ezután megkeresem a naplókban az iktató előtti eseményeket, amelyek megelőzték a fájlt, azaz megkeresem az okokat, hogy miért történt a fájl.
Ez pedig képet ad arról, hogy megértjük, mi történt, és mit lehet tenni a jövőben, hogy ilyen körülmények ne forduljanak elő (és ennek eredményeként nincs adatkezelő).
És hol szoktunk nézni? Nézek:
- Először is a Patroni-naplókhoz.
- Ezután megnézem a Postgres naplókat vagy a DCS naplókat, attól függően, hogy mit találtunk a Patroni naplókban.
- És a rendszernaplók néha azt is megértik, hogy mi okozta a fájlt.

Mit érzek Patronival kapcsolatban? Nagyon jó a kapcsolatom Patronival. Véleményem szerint ma ez a legjobb. Sok más terméket ismerek. Ezek a Stolon, Repmgr, Pg_auto_failover, PAF. 4 szerszám. Mindegyiket kipróbáltam. Patroni a kedvencem.
Ha megkérdezik tőlem: "Ajánlom a Patronit?". Igent mondok, mert szeretem Patronit. És azt hiszem, megtanultam főzni.
Ha érdekel, hogy az általam említett problémákon kívül milyen problémák vannak még a Patroni-val, bármikor megtekintheti az oldalt a GitHubon. Sok különböző történet van, és sok érdekes kérdést tárgyalnak ott. Ennek eredményeként néhány hibát bevezettek és kijavítottak, vagyis ez egy érdekes olvasmány.
Vannak érdekes történetek arról, hogy az emberek lábon lövik magukat. Nagyon informatív. Elolvasod és megérted, hogy erre nincs szükség. kipipáltam magam.
És szeretnék köszönetet mondani Zalandónak a projekt kidolgozásáért, nevezetesen Alekszandr Kukushkinnak és Alekszej Klyukinnak. Aleksey Klyukin az egyik társszerző, már nem dolgozik a Zalandónál, de ők ketten kezdtek el ezzel a termékkel dolgozni.
És szerintem a Patroni nagyon klassz dolog. Örülök, hogy létezik, érdekes vele. És nagy köszönet minden közreműködőnek, aki patronokat ír a Patroninak. Remélem, hogy a Patroni érettebb, hűvösebb és hatékonyabb lesz a korral. Már működőképes, de remélem még jobb lesz. Ezért, ha a Patroni használatát tervezi, ne féljen. Ez egy jó megoldás, megvalósítható, használható.
Ez minden. Ha kérdése van, kérdezzen.

kérdések
Köszönöm a beszámolót! Ha egy reszelő után még nagyon oda kell nézni, akkor miért van szükségünk automatikus reszelőre?
Mert ez új cucc. Még csak egy éve vagyunk vele. Jobb biztonságban lenni. Szeretnénk bemenni, és látni, hogy tényleg minden úgy alakult, ahogy kell. Ez a felnőtt bizalmatlanság szintje – jobb, ha még egyszer ellenőrizzük és meglátjuk.
Például reggel elmentünk és megnéztük, nem?
Nem reggel, általában szinte azonnal értesülünk az autofile-ról. Értesítéseket kapunk, látjuk, hogy automatikus fájl történt. Szinte azonnal megyünk és megnézzük. De mindezeket az ellenőrzéseket a megfigyelési szintre kell vinni. Ha a REST API-n keresztül éri el a Patronit, akkor előzményei vannak. Az előzmények alapján láthatja az időbélyegeket, amikor a fájl megtörtént. Ez alapján lehet monitorozni. Láthatja az előzményeket, mennyi esemény volt. Ha több eseményünk van, akkor automatikus fájl történt. Elmehetsz és megnézheted. Vagy a felügyeleti automatizálásunk ellenőrizte, hogy minden replikánk a helyén van, nincs késés és minden rendben van.
Köszönöm!
Köszönöm szépen a remek történetet! Ha a DCS fürtöt valahova távolabb helyeztük a Postgres fürttől, akkor ezt a fürtöt is rendszeresen szervizelni kell? Melyek a legjobb gyakorlatok, amelyekkel a DCS-fürt egyes darabjait ki kell kapcsolni, valamit tenni kell velük stb.? Hogyan marad fenn ez az egész szerkezet? És hogyan csinálod ezeket a dolgokat?
Egy cégnél egy problémamátrixot kellett készíteni, hogy mi történik, ha valamelyik vagy több komponens meghibásodik. Ennek a mátrixnak megfelelően egymás után végigmegyünk az összes összetevőn, és forgatókönyveket készítünk ezen összetevők meghibásodása esetén. Ennek megfelelően minden meghibásodási forgatókönyvhöz rendelkezhet egy cselekvési tervvel a helyreállításhoz. A DCS esetében pedig a szabványos infrastruktúra része. És az adminisztrátor adminisztrálja, mi pedig már bízunk az adminisztrátorokban, akik ezt adminisztrálják, és abban, hogy baleset esetén meg tudják javítani. Ha egyáltalán nincs DCS, akkor telepítjük, ugyanakkor nem is figyeljük különösebben, mert nem mi vagyunk felelősek az infrastruktúráért, de adunk ajánlásokat, hogyan és mit kell figyelni.
Vagyis jól értettem, hogy le kell tiltanom a Patronit, le kell tiltani a filert, le kell tiltanom mindent, mielőtt bármit tennék a gazdagépekkel?
Attól függ, hogy hány csomópontunk van a DCS-fürtben. Ha sok csomópont van, és csak az egyik csomópontot (a replikát) tiltjuk le, akkor a fürt fenntartja a határozatképességet. A Patroni pedig továbbra is működőképes marad. És semmi sem vált ki. Ha vannak összetett műveleteink, amelyek több csomópontot érintenek, és ezek hiánya tönkreteheti a kvórumot, akkor - igen, érdemes lehet a Patronit szüneteltetni. Van egy megfelelő parancsa - patronictl pause, patronictl resume. Csak szünetet tartunk, és az autofiler ilyenkor nem működik. Karbantartást végzünk a DCS-fürtön, majd levesszük a szünetet és tovább élünk.
Szebb bővebben!
Nagyon szépen köszönöm a beszámolót! Hogyan vélekedik a termékcsapat az adatok elvesztéséről?
A termékcsoportokat nem érdekli, a csapatvezetők pedig aggódnak.
Milyen garanciák vannak?
A garanciák nagyon nehézek. Alexander Kukushkinnek van egy jelentése „Hogyan számítsuk ki az RPO-t és az RTO-t”, vagyis a helyreállítási időt és azt, hogy mennyi adatot veszíthetünk. Azt hiszem, meg kell találnunk ezeket a diákat és tanulmányoznunk kell őket. Ha jól emlékszem, ezeknek a kiszámításának konkrét lépései vannak. Hány tranzakciót veszíthetünk, mennyi adatot veszíthetünk el. Opcióként használhatunk szinkron replikációt Patroni szinten, de ez kétélű fegyver: vagy adatmegbízhatóságunk van, vagy veszítünk a sebességünkből. Létezik szinkron replikáció, de ez sem garantál 100%-os védelmet az adatvesztés ellen.
Alexey, köszönöm a nagyszerű beszámolót! Van tapasztalata a Patroni használatával a nulla szintű védelemhez? Vagyis szinkron készenléttel együtt? Ez az első kérdés. És a második kérdés. Különféle megoldásokat használtál. Repmgr-t használtunk, de autofiler nélkül, és most tervezzük az autofiler beépítését. A Patronit pedig alternatív megoldásnak tekintjük. Milyen előnyöket tud mondani a Repmgr-hez képest?
Az első kérdés a szinkron replikákra vonatkozott. Itt senki nem használ szinkron replikációt, mert mindenki fél (több ügyfél már használja, elvileg nem vettek észre teljesítményproblémákat - Az előadó megjegyzése). De kidolgoztunk magunknak egy szabályt, hogy egy szinkron replikációs fürtben legalább három csomópontnak kell lennie, mert ha két csomópontunk van, és ha a fő vagy a replika meghibásodik, akkor a Patroni ezt a csomópontot önálló módba kapcsolja, hogy az alkalmazás továbbra is munka. Ebben az esetben fennáll az adatvesztés veszélye.
Ami a második kérdést illeti, a Repmgr-t használtuk, és még mindig használjuk néhány ügyfélnél történelmi okokból. Mit lehet mondani? A Patroni a dobozból egy automatikus szűrőt tartalmaz, a Repmgr pedig az automatikus szűrőt, mint további funkciót, amelyet engedélyezni kell. Futtatnunk kell a Repmgr démont minden csomóponton, majd konfigurálhatjuk az autofilert.
A Repmgr ellenőrzi, hogy a Postgres csomópontok életben vannak-e. A repmgr folyamatok ellenőrzik egymás létezését, ez nem túl hatékony megközelítés. előfordulhatnak olyan összetett hálózati elszigetelési esetek, amikor egy nagy Repmgr-fürt több kisebbre széteshet, és tovább működhet. Régóta nem követem a Repmgr-t, lehet, hogy javították... vagy nem. De a fürt állapotára vonatkozó információk eltávolítása a DCS-ben, ahogy Stolon, Patroni teszi, a legjárhatóbb megoldás.
Alexey, lenne egy kérdésem, talán egy bénább. Az első példák egyikében áthelyezte a DCS-t a helyi gépről egy távoli gazdagépre. Megértjük, hogy a hálózat olyan dolog, amelynek megvannak a maga sajátosságai, önmagában él. És mi történik, ha valamilyen okból a DCS-fürt elérhetetlenné válik? Az okokat nem mondom meg, sok lehet: a hálózatépítők görbe kezétől a valódi problémákig.
Nem mondtam ki hangosan, de a DCS-fürtnek is failovernek kell lennie, azaz páratlan számú csomópontnak kell lennie, hogy teljesüljön a határozatképesség. Mi történik, ha a DCS-fürt elérhetetlenné válik, vagy a kvórum nem teljesül, azaz valamilyen hálózati felosztás vagy csomóponthiba lép fel? Ebben az esetben a Patroni-fürt csak olvasható módba lép. A Patroni-fürt nem tudja meghatározni a fürt állapotát és a teendőket. Nem tud kapcsolatba lépni a DCS-vel és ott tárolni az új fürtállapotot, így a teljes fürt csak olvasható állapotba kerül. És vagy a kezelő kézi beavatkozására vár, vagy a DCS helyreállására.
Nagyjából elmondható, hogy a DCS ugyanolyan fontos szolgáltatássá válik számunkra, mint maga a bázis?
Igen igen. Sok modern vállalatnál a Service Discovery az infrastruktúra szerves része. Még azelőtt kerül bevezetésre, hogy az infrastruktúrában még adatbázis is létezett volna. Viszonylagosan elmondható, hogy az infrastruktúrát elindították, telepítették a DC-ben, és azonnal megvan a Service Discovery. Ha Consul, akkor DNS-t lehet rá építeni. Ha ez az Etcd, akkor lehet, hogy a Kubernetes-fürtből van egy rész, amelyben minden más telepítve lesz. Számomra úgy tűnik, hogy a Service Discovery már a modern infrastruktúrák szerves része. És sokkal korábban gondolnak rá, mint az adatbázisokra.
Köszönöm!
Forrás: will.com
