

Időről időre a fejlesztőnek szüksége van rá paraméterkészletet vagy akár egy teljes kijelölést is átad a kérésnek "a bejáratnál". Néha nagyon furcsa megoldások vannak erre a problémára.
Menjünk "az ellenkezőjéről", és nézzük meg, hogyan ne tegyük, miért, és hogyan lehet jobban csinálni.
Az értékek közvetlen "beillesztése" a kérés törzsébe
Általában valahogy így néz ki:
query = "SELECT * FROM tbl WHERE id = " + value...vagy így:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)Erről a módszerről azt mondják, írják és elég:

Szinte mindig az közvetlen elérési út az SQL injekcióhoz és extra terhelést jelent az üzleti logikára, amely kénytelen „összeragasztani” a lekérdezési karakterláncot.
Ez a megközelítés csak részben indokolható, ha szükséges. partícionálás használata a PostgreSQL 10-es és korábbi verzióiban a hatékonyabb terv érdekében. Ezekben a verziókban a szkennelt szakaszok listája a továbbított paraméterek figyelembevétele nélkül, csak a kérés törzse alapján kerül meghatározásra.
$n argumentum
Használat paraméterei jók, lehetővé teszi a használatát , csökkentve mind az üzleti logika (a lekérdezési karakterlánc létrehozása és továbbítása csak egyszer), mind az adatbázis-kiszolgáló terhelése (nem szükséges újraelemzés és tervezés a kérés minden példányánál).
Változó számú argumentum
Problémák várnak ránk, ha ismeretlen számú argumentumot akarunk előre átadni:
... id IN ($1, $2, $3, ...) -- $1 : 2, $2 : 3, $3 : 5, ...Ha a kérelmet ezen az űrlapon hagyja, akkor bár megkímél minket az esetleges injekcióktól, akkor is szükség lesz a kérés ragasztására / elemzésére. minden opciónál az argumentumok számából. Már jobb, mint minden alkalommal megtenni, de meg lehet csinálni nélküle is.
Elég csak egy paramétert átadni, amely tartalmazza egy tömb szerializált ábrázolása:
... id = ANY($1::integer[]) -- $1 : '{2,3,5,8,13}'Az egyetlen különbség az, hogy az argumentumot kifejezetten a kívánt tömbtípusra kell konvertálni. De ez nem okoz gondot, hiszen már előre tudjuk, hogy hol fogunk foglalkozni.
Mintaátvitel (mátrix)
Általában ezek mindenféle lehetőség az adatkészletek átvitelére az adatbázisba való beillesztéshez „egy kéréssel”:
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...A kérés "újraragasztásával" kapcsolatos fent leírt problémákon túl ez is elvezethet bennünket elfogyott a memória és a szerver összeomlik. Az ok egyszerű – a PG további memóriát tart fenn az argumentumok számára, és a készletben lévő rekordok számát csak az üzleti logikai alkalmazás Wishlist korlátozza. Különösen klinikai esetekben volt szükséges látni 9000 dollárnál nagyobb "számozott" argumentumok - ne így csináld.
Írjuk át a lekérdezést, már jelentkezve "kétszintű" szerializálás:
INSERT INTO tbl
SELECT
unnest[1]::text k
, unnest[2]::integer v
FROM (
SELECT
unnest($1::text[])::text[] -- $1 : '{"{a,1}","{b,2}","{c,3}","{d,4}"}'
) T;
Igen, egy tömbön belüli "összetett" értékek esetén azokat idézőjelekkel kell keretezni.
Jól látható, hogy így tetszőleges számú mezővel lehet "bővíteni" a kijelölést.
unnest, unnest,…
Időről időre lehetőség van arra, hogy a „tömbök tömbje” helyett több „oszloptömb” átadására is sor kerüljön, amelyeket már említettem. :
SELECT
unnest($1::text[]) k
, unnest($2::integer[]) v;Ezzel a módszerrel, ha hibát követ el a különböző oszlopok értéklistáinak generálásakor, nagyon könnyű a teljes váratlan eredményeket, amelyek a szerver verziójától is függenek:
-- $1 : '{a,b,c}', $2 : '{1,2}'
-- PostgreSQL 9.4
k | v
-----
a | 1
b | 2
c | 1
a | 2
b | 1
c | 2
-- PostgreSQL 11
k | v
-----
a | 1
b | 2
c |JSON
A 9.3-as verziótól kezdve a PostgreSQL teljes értékű funkciókkal rendelkezik a json típussal való együttműködéshez. Ezért, ha a beviteli paraméterek meg vannak határozva a böngészőben, akkor közvetlenül ott tud formálni json objektum SQL lekérdezéshez:
SELECT
key k
, value v
FROM
json_each($1::json); -- '{"a":1,"b":2,"c":3,"d":4}'A korábbi verziókhoz ugyanez a módszer használható mindegyik (hstore), de a hstore-ban lévő összetett objektumokkal való helyes "hajtogatás" problémákat okozhat.
json_populate_recordset
Ha előre tudja, hogy az „input” json tömbből származó adatok valamilyen tábla kitöltésére fognak menni, sokat spórolhatunk a „hivatkozás megszüntetése” mezőkben és a kívánt típusokba történő átküldésben a json_populate_recordset függvény segítségével:
SELECT
*
FROM
json_populate_recordset(
NULL::pg_class
, $1::json -- $1 : '[{"relname":"pg_class","oid":1262},{"relname":"pg_namespace","oid":2615}]'
);json_to_recordset
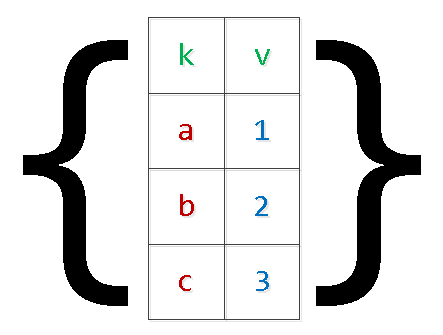
Ez a funkció pedig egyszerűen „kibővíti” az átadott objektumok tömbjét egy kijelöléssé, anélkül, hogy a táblázatformátumra hagyatkozna:
SELECT
*
FROM
json_to_recordset($1::json) T(k text, v integer);
-- $1 : '[{"k":"a","v":1},{"k":"b","v":2}]'
k | v
-----
a | 1
b | 2IDEIGLENES ASZTAL
De ha az átvitt mintában nagyon nagy az adatmennyiség, akkor egy soros paraméterbe dobni nehéz, és néha lehetetlen, mivel egyszeri nagy memóriafoglalás. Például egy nagy köteg eseményadatot kell gyűjteni egy külső rendszerről hosszú-hosszú ideig, majd egyszer szeretné feldolgozni az adatbázis oldalon.
Ebben az esetben a legjobb megoldás a használata lenne :
CREATE TEMPORARY TABLE tbl(k text, v integer);
...
INSERT INTO tbl(k, v) VALUES($1, $2); -- повторить много-много раз
...
-- тут делаем что-то полезное со всей этой таблицей целиком
A módszer jó nagy mennyiségek ritka átviteléhez adat.
Adatai szerkezetének leírása szempontjából az ideiglenes tábla egyetlen jellemzőben különbözik a „szokásos” táblától. a pg_class rendszertáblázatban, és be pg_type, pg_depend, pg_attribute, pg_attrdef, ... - és egyáltalán semmi.
Ezért azokban a webes rendszerekben, amelyek mindegyikéhez nagyszámú rövid élettartamú kapcsolat kapcsolódik, egy ilyen tábla minden alkalommal új rendszerrekordokat generál, amelyek törlődnek, amikor az adatbázishoz való kapcsolat megszakad. Végül is, A TEMP TABLE ellenőrizetlen használata a pg_catalog tábláinak "megduzzadásához" vezet és lelassítja az ezeket használó számos műveletet.
Ez ellen persze lehet küzdeni periodic pass VÁKUUM MEGTELT a rendszerkatalógus táblázatai szerint.
Munkamenet-változók
Tegyük fel, hogy az előző esetből származó adatok feldolgozása elég bonyolult egyetlen SQL lekérdezés esetén, de ezt elég gyakran szeretné megtenni. Vagyis procedurális feldolgozást szeretnénk használni , de az ideiglenes táblákon keresztüli adatátvitel túl drága lesz.
$n-paramétert sem használhatunk névtelen blokkhoz való átvitelre. A munkamenet-változók és a függvény segít kilábalni a helyzetből. aktuális beállítás.
A 9.2-es verzió előtt előre be kellett állítani egyéni_változó_osztályok a "saját" munkamenet-változókhoz. A jelenlegi verziókban ilyesmit írhat:
SET my.val = '{1,2,3}';
DO $$
DECLARE
id integer;
BEGIN
FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP
RAISE NOTICE 'id : %', id;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- NOTICE: id : 1
-- NOTICE: id : 2
-- NOTICE: id : 3Más támogatott eljárási nyelveken más megoldások is elérhetők.
Tudsz több módot? Oszd meg kommentben!
Forrás: will.com
