

Emlékezzünk vissza, hogy az Elastic Stack a nem relációs Elasticsearch adatbázison, a Kibana webes felületen és adatgyűjtőkön és feldolgozókon (a leghíresebb Logstash, különféle Beats, APM és mások) alapul. Az egyik szép kiegészítés a teljes felsorolt termékkészlethez az adatelemzés gépi tanulási algoritmusokkal. A cikkből megértjük, mik ezek az algoritmusok. Kérem a kat.
A gépi tanulás a shareware Elastic Stack fizetős funkciója, és az X-Pack része. A használat megkezdéséhez csak aktiválja a 30 napos próbaverziót a telepítés után. A próbaidőszak lejárta után támogatást kérhet a próbaidőszak meghosszabbításához, vagy előfizetést vásárolhat. Az előfizetés költségét nem az adatok mennyisége, hanem a használt csomópontok száma alapján számítják ki. Nem, az adatok mennyisége természetesen befolyásolja a szükséges csomópontok számát, de ez a licencelési megközelítés mégis humánusabb a vállalat költségvetéséhez képest. Ha nincs szükség magas termelékenységre, pénzt takaríthat meg.
Az Elastic Stackben lévő ML C++ nyelven íródott, és a JVM-en kívül fut, amelyben maga az Elasticsearch fut. Vagyis a folyamat (mellesleg autodetect-nek hívják) mindent elfogyaszt, amit a JVM nem nyel le. Demó állványon ez nem annyira kritikus, de éles környezetben fontos külön csomópontokat kijelölni az ML feladatokhoz.
A gépi tanulási algoritmusok két kategóriába sorolhatók − и . Az Elastic Stackben az algoritmus a „nem felügyelt” kategóriába tartozik. Által Láthatja a gépi tanulási algoritmusok matematikai apparátusát.
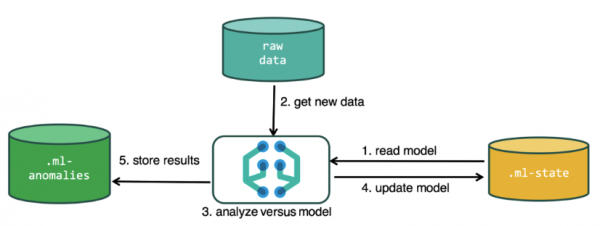
Az elemzés elvégzéséhez a gépi tanulási algoritmus az Elasticsearch indexekben tárolt adatokat használja. A Kibana felületéről és az API-n keresztül is készíthet elemzési feladatokat. Ha ezt a Kibanán keresztül teszi, akkor néhány dolgot nem kell tudnia. Például további indexek, amelyeket az algoritmus a működése során használ.
Az elemzési folyamatban használt további indexek.ml-state — információ a statisztikai modellekről (elemzési beállítások);
.ml-anomalies-* — ML algoritmusok eredményei;
.ml-notifications — az elemzési eredményeken alapuló értesítések beállításai.
Az Elasticsearch adatbázis adatstruktúrája indexekből és az azokban tárolt dokumentumokból áll. Ha összehasonlítjuk egy relációs adatbázissal, az index összehasonlítható egy adatbázissémával, a dokumentum pedig egy tábla rekordjával. Ez az összehasonlítás feltételes, és a további anyagok könnyebb megértését szolgálja azok számára, akik csak hallottak az Elasticsearchról.
Ugyanazok a funkciók érhetők el az API-n keresztül, mint a webes felületen keresztül, ezért az egyértelműség és a fogalmak megértése érdekében megmutatjuk, hogyan kell konfigurálni a Kibanán keresztül. A bal oldali menüben található a Machine Learning rész, ahol új feladatot hozhat létre. A Kibana felületén úgy néz ki, mint az alábbi képen. Most elemezzük az egyes feladattípusokat, és bemutatjuk az itt összeállítható elemzési típusokat.
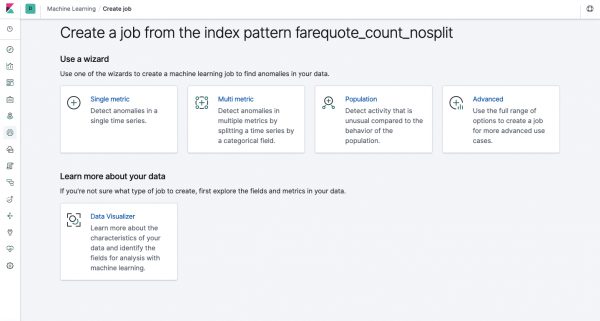
Single Metric – egy metrika elemzése, Multi Metric – két vagy több metrika elemzése. Mindkét esetben az egyes mérőszámokat elszigetelt környezetben elemezzük, pl. az algoritmus nem veszi figyelembe a párhuzamosan elemzett metrikák viselkedését, ahogy az a Multi Metric esetében tűnhet. A különböző mutatók korrelációját figyelembe vevő számítások elvégzéséhez használhatja a Népességelemzést. Az Advanced pedig bizonyos feladatokhoz további opciókkal finomítja az algoritmusokat.
Egyetlen metrika
A változtatások egyetlen mérőszámban történő elemzése a legegyszerűbb, amit itt meg lehet tenni. A Munka létrehozása gombra kattintás után az algoritmus anomáliákat keres.
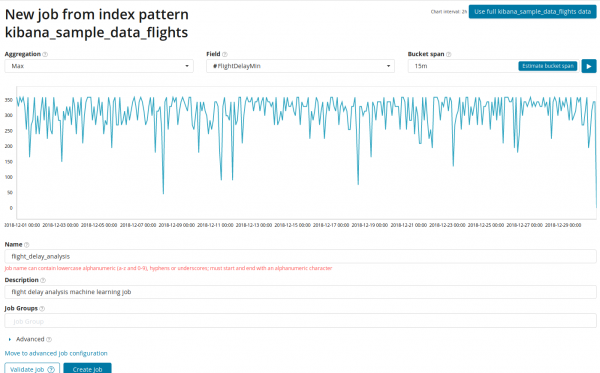
A területen összesítése választhat egy megközelítést az anomáliák kereséséhez. Például mikor Min a tipikus értékek alatti értékek anomálisnak minősülnek. Eszik Max, Magas Átlag, Alacsony, Közepes, Különleges és mások. Az összes funkció leírása megtalálható .
A területen Mező azt a numerikus mezőt jelzi a dokumentumban, amelyen az elemzést elvégezzük.
A területen — az idővonalon lévő intervallumok részletessége, amely mentén az elemzést elvégzik. Bízhat az automatizálásban, vagy manuálisan választhat. Az alábbi képen látható a túl alacsony részletesség – előfordulhat, hogy figyelmen kívül hagyja az anomáliát. Ezzel a beállítással módosíthatja az algoritmus anomáliákra való érzékenységét.
Az adatgyűjtés időtartama kulcsfontosságú tényező, amely befolyásolja az elemzés hatékonyságát. Az elemzés során az algoritmus azonosítja az ismétlődő intervallumokat, kiszámítja a konfidencia intervallumokat (alapvonalakat), és azonosítja az anomáliákat – a metrika normál viselkedésétől való atipikus eltéréseket. Csak például:
Alapvonalak egy kis adattal:
Ha az algoritmusnak van miből tanulnia, az alapvonal így néz ki:
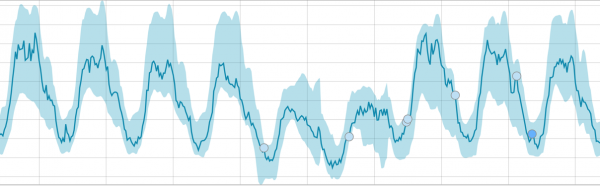
A feladat megkezdése után az algoritmus meghatározza a rendellenes eltéréseket a normától, és rangsorolja azokat az anomália valószínűsége szerint (zárójelben a megfelelő címke színe látható):
Figyelmeztetés (kék): kevesebb, mint 25
Kisebb (sárga): 25-50
Major (narancs): 50-75
Kritikus (piros): 75-100
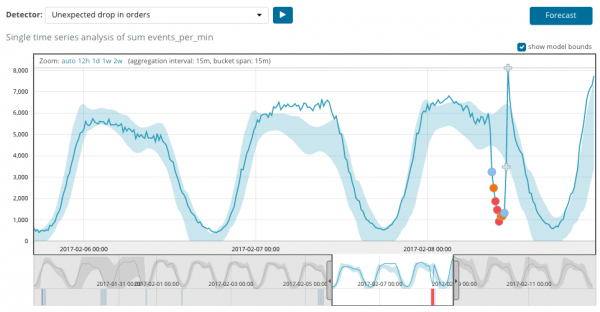
Az alábbi grafikon a talált rendellenességekre mutat példát.
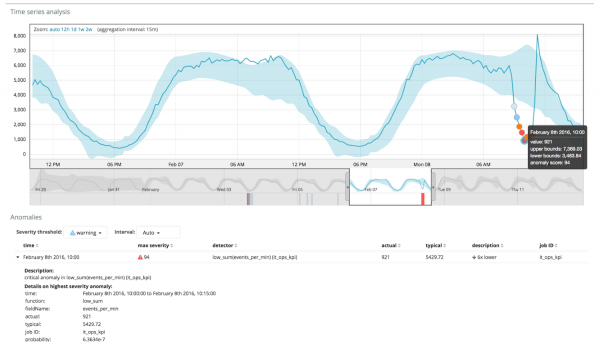
Itt a 94-es szám látható, amely az anomália valószínűségét jelzi. Nyilvánvaló, hogy mivel az érték közel 100, ez azt jelenti, hogy anomáliánk van. A grafikon alatti oszlop az ott megjelenő metrikaérték pejoratívan kicsi, 0.000063634%-os valószínűségét mutatja.
Az anomáliák keresése mellett előrejelzést is futtathat a Kibanában. Ez egyszerűen és ugyanabból a nézetből történik az anomáliákkal - gomb Előrejelzés a jobb felső sarokban.
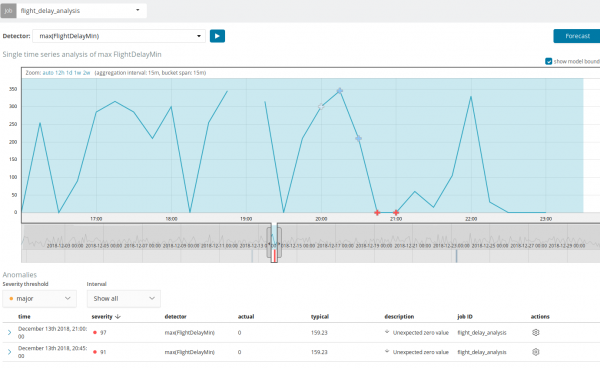
Az előrejelzés maximum 8 hétre előre készül. Még ha nagyon akarod is, ez már nem lehetséges a tervezéssel.
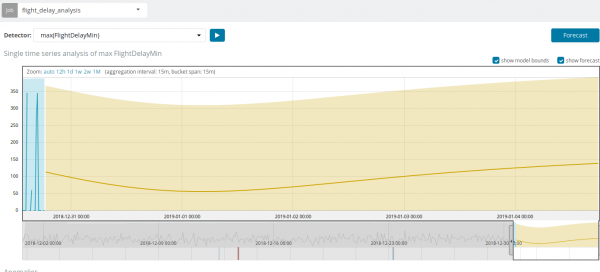
Bizonyos helyzetekben az előrejelzés nagyon hasznos lehet, például az infrastruktúra felhasználói terhelésének figyelésekor.
Több metrikus
Térjünk át az Elastic Stack következő ML funkciójára – több mérőszám elemzésére egy kötegben. Ez azonban nem jelenti azt, hogy az egyik mérőszám egy másiktól való függését elemzik. Ez ugyanaz, mint az Egy metrika, de több mérőszámmal egy képernyőn, hogy könnyen összehasonlíthassák az egyik metrikát a másikra. Az egyik mérőszám egy másiktól való függésének elemzéséről a Népesség részben fogunk beszélni.
Miután rákattintott a négyzetre a Multi Metric funkcióval, megjelenik egy ablak a beállításokkal. Nézzük meg őket részletesebben.
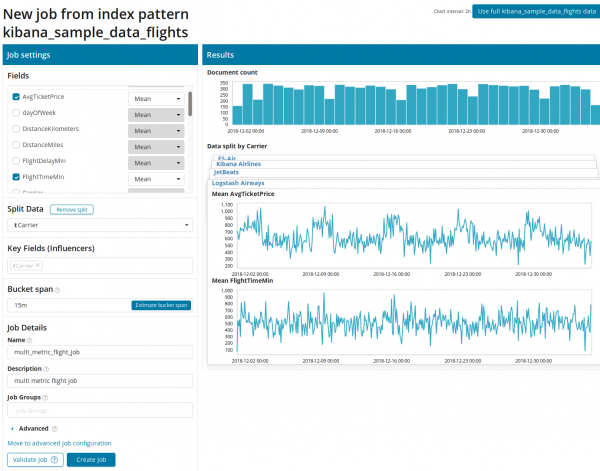
Először ki kell választani az elemzéshez és az adatok összesítéséhez szükséges mezőket. Az összesítési lehetőségek itt ugyanazok, mint az Egy metrika esetén (Max, Magas Átlag, Alacsony, Közepes, Különleges és mások). Továbbá, ha szükséges, az adatokat az egyik mezőre osztják (mező Osztott adatok). A példában ezt mezőnként tettük meg OriginAirportID. Figyelje meg, hogy a jobb oldali metrikák grafikonja most több grafikonként jelenik meg.
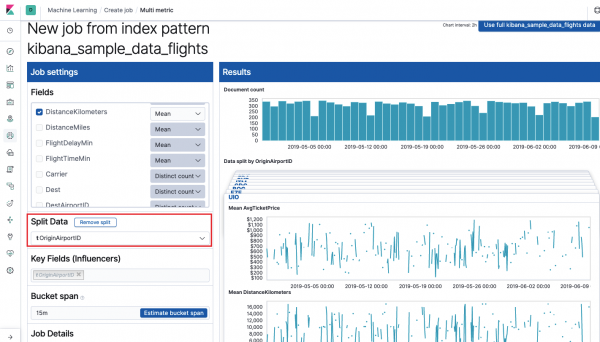
Mező Kulcsmezők (befolyásolók) közvetlenül befolyásolja az észlelt anomáliákat. Alapértelmezés szerint itt mindig lesz legalább egy érték, és továbbiakat is hozzáadhat. Az algoritmus figyelembe veszi ezeknek a mezőknek a hatását az elemzés során, és megmutatja a „legbefolyásosabb” értékeket.
Indítás után valami ilyesmi fog megjelenni a Kibana felületén.
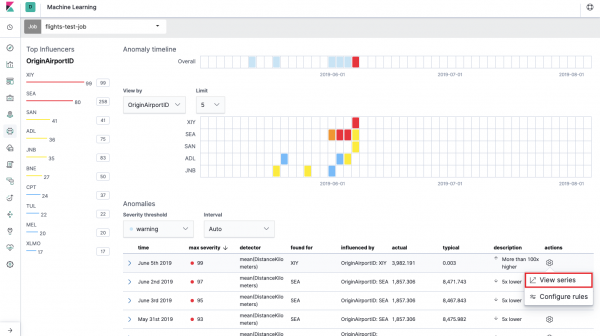
Ez az ún az anomáliák hőtérképe minden mezőértékhez OriginAirportIDban jeleztük Osztott adatok. Az egymetrikushoz hasonlóan a szín a kóros eltérés mértékét jelzi. Kényelmes hasonló elemzést végezni például munkaállomásokon, hogy nyomon követhessük azokat, amelyek gyanúsan sok jogosultsággal rendelkeznek stb. Már írtunk , amely itt is összegyűjthető és elemezhető.
A hőtérkép alatt az anomáliák listája látható, mindegyikből átválthat az Egymetrikus nézetre a részletes elemzéshez.
Lakosság
A különböző mutatók közötti összefüggések anomáliáinak kereséséhez az Elastic Stack speciális népességelemzéssel rendelkezik. Segítségével kereshet rendellenes értékeket egy szerver teljesítményében a többihez képest, amikor például nő a célrendszerhez intézett kérések száma.
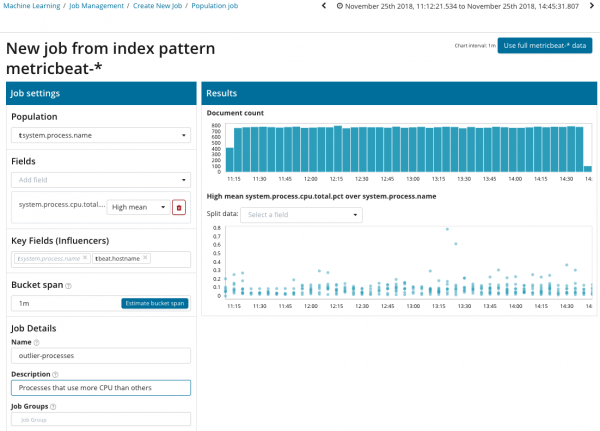
Ezen az ábrán a Népesség mező azt az értéket jelzi, amelyre az elemzett mérőszámok vonatkozni fognak. Ebben az esetben ez a folyamat neve. Ennek eredményeként látni fogjuk, hogy az egyes folyamatok processzorterhelése hogyan befolyásolta egymást.
Kérjük, vegye figyelembe, hogy az elemzett adatok grafikonja eltér a Single Metric és Multi Metric eseteitől. Ezt a Kibanában úgy tervezték, hogy jobban érzékeljék az elemzett adatok értékeinek eloszlását.
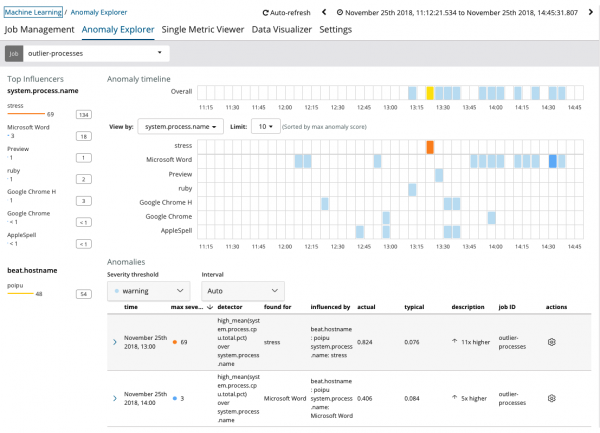
A grafikon azt mutatja, hogy a folyamat rendellenesen működött feszültség (egyébként egy speciális segédprogram által generált) a szerveren poipu, aki befolyásolta (vagy befolyásolónak bizonyult) ennek az anomáliának a fellépését.
Részletes
Analitika finomhangolással. A Speciális elemzéssel további beállítások jelennek meg a Kibanában. Miután a létrehozás menüben a Speciális csempére kattintott, megjelenik ez az ablak a fülekkel. Tab munka részletei Szándékosan kihagytuk, vannak alapvető beállítások, amelyek nem kapcsolódnak közvetlenül az elemzés beállításához.
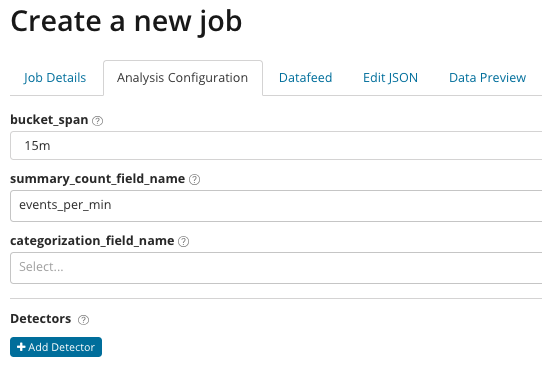
В összegzés_szám_mező_neve Opcionálisan megadhatja egy mező nevét az összesített értékeket tartalmazó dokumentumokból. Ebben a példában a percenkénti események száma. BAN BEN egy olyan mező nevét és értékét jelzi a dokumentumból, amely valamilyen változó értéket tartalmaz. Az ezen a mezőn lévő maszk használatával az elemzett adatokat részhalmazokra bonthatja. Ügyeljen a gombra Adjon hozzá detektort az előző ábrán. Az alábbiakban látható a gombra kattintás eredménye.
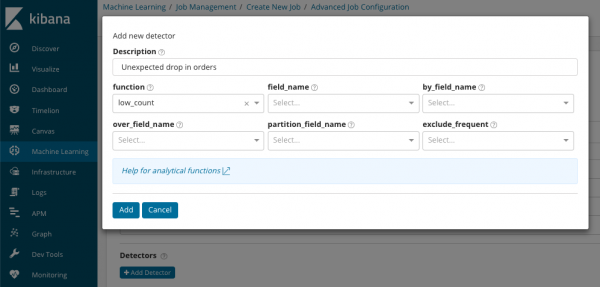
Itt található egy további beállítási blokk az anomália-érzékelő konfigurálásához egy adott feladathoz. A következő cikkekben a konkrét használati eseteket (különösen a biztonságiakat) szeretnénk tárgyalni. Például, az egyik szétszedett tok. A ritkán megjelenő értékek kereséséhez kapcsolódik, és megvalósul .
A területen funkció Kiválaszthat egy adott funkciót az anomáliák kereséséhez. Kivéve ritka, van még néhány érdekes funkció - . Azonosítják a metrikák viselkedésének anomáliáit a nap, illetve a hét folyamán. Egyéb elemzési funkciók .
В mező neve jelzi a dokumentum azon mezőjét, amelyen az elemzést el kell végezni. A_mező_neve alapján használható az itt megadott bizonylatmező minden egyes értékére vonatkozó elemzési eredmények elkülönítésére. Ha kitöltöd over_field_name megkapja a fentebb tárgyalt populációs elemzést. Ha értéket ad meg a partíciómező_neve, akkor a dokumentum ezen mezőjéhez minden egyes értékhez külön alapvonal kerül kiszámításra (az érték lehet például a szerver vagy a szerveren lévő folyamat neve). BAN BEN kizár_gyakori választhat minden vagy egyik sem, ami a gyakran előforduló dokumentummezőértékek kizárását (vagy belefoglalását) jelenti.
Ebben a cikkben igyekeztünk minél tömörebb képet adni az Elastic Stack gépi tanulási képességeiről, sok részlet még hátra van a színfalak mögött. Írd meg kommentben, hogy milyen eseteket sikerült megoldanod az Elastic Stack segítségével, és milyen feladatokra használod. Ha kapcsolatba szeretne lépni velünk, használja személyes üzeneteit a Habré ill .
Forrás: will.com
