

В idősoros előrejelzésről beszéltünk. A logikus folytatás az anomáliák azonosításáról szóló cikk lenne.
Alkalmazás
Az anomáliák észlelését olyan területeken használják, mint:
1) A berendezés meghibásodásának előrejelzése
Így 2010-ben az iráni centrifugákat megtámadta a Stuxnet vírus, amely a berendezést nem optimális működésre állította, és a felgyorsult kopás miatt letiltotta a berendezések egy részét.
Ha anomáliát észlelő algoritmusokat alkalmaztak volna a berendezésen, elkerülhető lett volna a meghibásodás.

A berendezések működésében fellelhető anomáliák keresését nemcsak az atomiparban, hanem a kohászatban és a repülőgép-turbinák üzemeltetésében is alkalmazzák. És más területeken, ahol a prediktív diagnosztika alkalmazása olcsóbb, mint az előre nem látható meghibásodás miatti esetleges veszteségek.
2) Csalás előrejelzése
Ha pénzt vonnak le az albániai Podolszkban használt kártyáról, a tranzakciókat további ellenőrzésre lehet szükség.
3) Rendellenes fogyasztói minták azonosítása
Ha egyes ügyfelek rendellenesen viselkednek, előfordulhat, hogy olyan probléma áll fenn, amelyről Ön nem is tud.
4) Rendellenes kereslet és terhelés azonosítása
Ha egy FMCG üzletben az eladások az előrejelzés konfidenciaintervalluma alá estek, érdemes megkeresni a történtek okát.
Az anomáliák azonosításának megközelítései
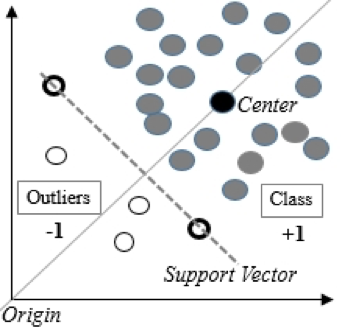
1) Támogatja a Vector gépet egy osztályú, egyosztályú SVM-mel
Alkalmas, ha a betanítási halmaz adatai normál eloszlást követnek, de a tesztkészlet anomáliákat tartalmaz.
Az egyosztályú támaszvektor gép egy nemlineáris felületet konstruál az origó köré. Beállítható egy határérték, amelynél az adatok anomálisnak minősülnek.
DATA4 csapatunk tapasztalatai alapján a One-Class SVM a leggyakrabban használt algoritmus az anomáliák megtalálásának problémáinak megoldására.
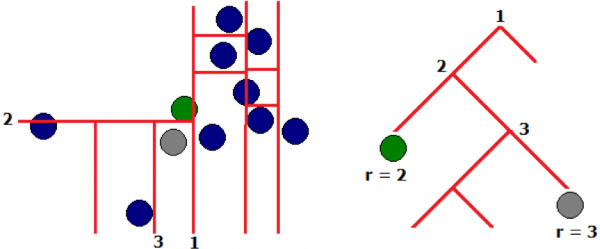
2) Erdő elkülönítése módszer
A faépítés „véletlenszerű” módszerével a kibocsátások már korai stádiumban (a fa sekély mélységében) kerülnek a levelekbe, pl. a kibocsátásokat könnyebb „elszigetelni”. Az anomális értékek elkülönítése az algoritmus első iterációiban történik.
3) Elliptikus burkológörbe és statisztikai módszerek
Akkor használatos, ha az adatok normál eloszlásúak. Minél közelebb van a mérés az eloszlások keverékének végéhez, annál anomálisabb az érték.
Más statisztikai módszerek is ebbe az osztályba sorolhatók.
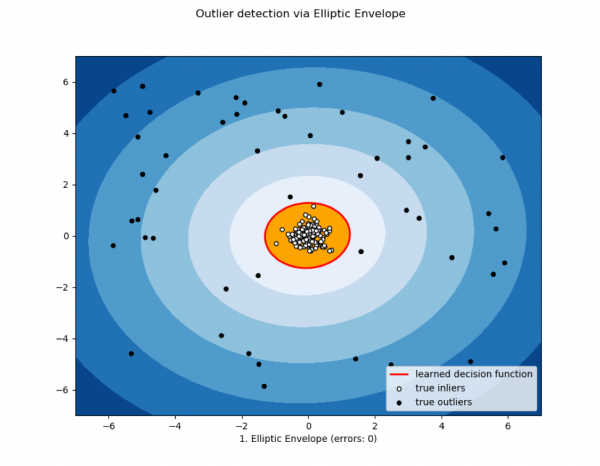
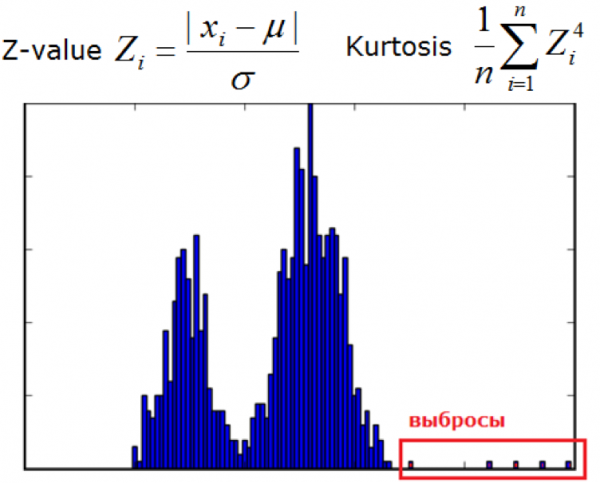
Kép a dyakonov.org webhelyről
4) Metrikus módszerek
A módszerek közé tartoznak az olyan algoritmusok, mint a k-legközelebbi szomszédok, a k-közelebbi szomszédok, az ABOD (szögalapú kiugró értékek észlelése) vagy a LOF (local outlier factor).
Alkalmas, ha a karakterisztikában szereplő értékek közötti távolság egyenértékű vagy normalizált (hogy ne mérjünk boa-összehúzót papagájoknál).
A k-legközelebbi szomszédok algoritmusa feltételezi, hogy a normál értékek a többdimenziós tér egy bizonyos tartományában helyezkednek el, és az anomáliáktól való távolság nagyobb lesz, mint az elválasztó hipersíktól.
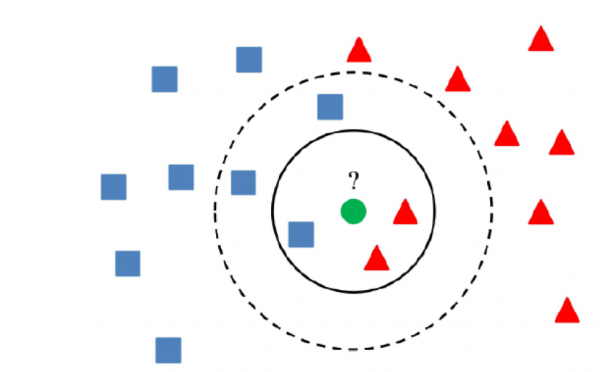
5) Klaszter módszerek
A klasztermódszerek lényege, hogy ha egy érték egy bizonyos mennyiségnél nagyobb távolságra van a klaszterközpontoktól, akkor az érték anomáliának tekinthető.
A lényeg az, hogy olyan algoritmust használjunk, amely megfelelően fürtözi az adatokat, ami az adott feladattól függ.
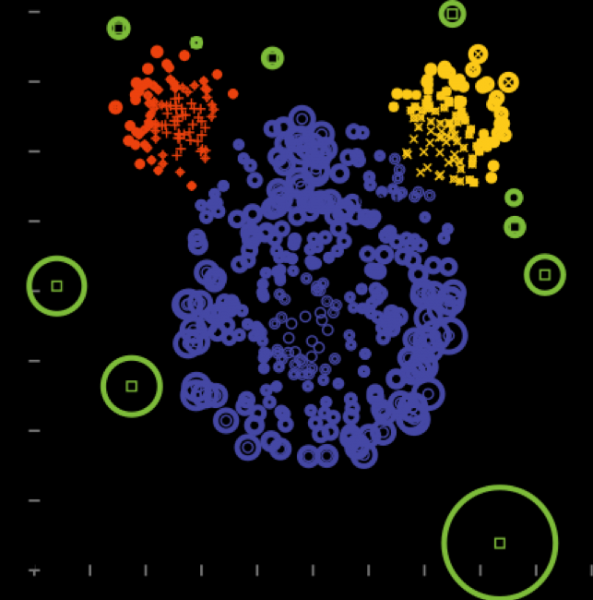
6) Főkomponens módszer
Alkalmas ott, ahol a szóródás legnagyobb változásának irányai vannak kiemelve.
7) Idősoros előrejelzésen alapuló algoritmusok
Az ötlet az, hogy ha egy érték kívül esik az előrejelzési konfidenciaintervallumon, az értéket anomálisnak tekintik. Egy idősor előrejelzéséhez olyan algoritmusokat használnak, mint a tripla simítás, az S(ARIMA), a boosting stb.
Az idősoros előrejelzési algoritmusokról az előző cikkben volt szó.
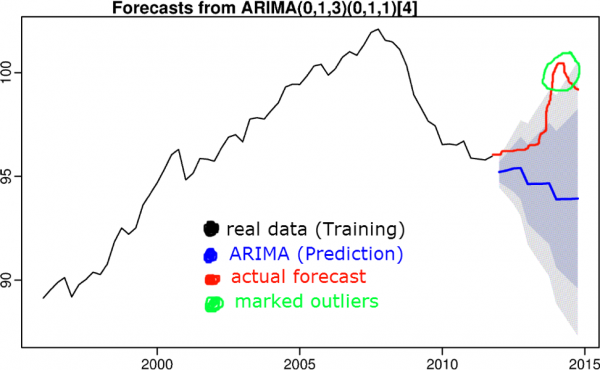
8) Felügyelt tanulás (regresszió, osztályozás)
Ha az adatok megengedik, a lineáris regressziótól a visszatérő hálózatokig terjedő algoritmusokat alkalmazunk. Mérjük meg az előrejelzés és a tényleges érték különbségét, és vonjuk le a következtetést, hogy az adatok mennyire térnek el a normától. Fontos, hogy az algoritmus kellő általánosító képességgel rendelkezzen, és a tanítókészlet ne tartalmazzon rendellenes értékeket.
9) Modelltesztek
Közelítsük meg az anomáliák keresésének problémáját az ajánlások keresésének problémájaként. Bontsuk fel a jellemzőmátrixunkat SVD vagy faktorizációs gépekkel, és vegyük anomáliának az új mátrixban az eredetitől jelentősen eltérő értékeket.
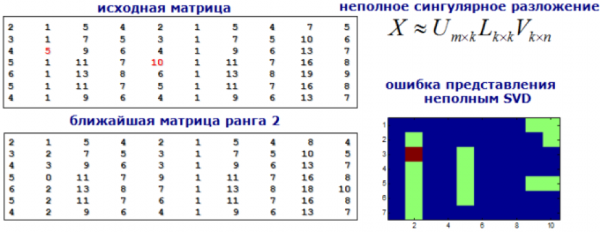
Kép a dyakonov.org webhelyről
Következtetés
Ebben a cikkben áttekintettük az anomáliák észlelésének főbb megközelítéseit.
Az anomáliák megtalálása sok szempontból nevezhető művészetnek. Nincs olyan ideális algoritmus vagy megközelítés, amelynek használata minden problémát megold. Gyakrabban egy adott eset megoldására módszereket alkalmaznak. Az anomáliák felderítése egyosztályú támaszvektor gépekkel, erdők elkülönítésével, metrikus és klaszteres módszerekkel, valamint főkomponensek és idősoros előrejelzések alkalmazásával történik.
Ha ismer más módszereket, írjon róluk a cikk megjegyzéseiben.
Forrás: will.com
