


Ismét az objektumészlelés feladatával szembesülsz. A prioritás a sebesség elfogadható pontossággal. Fogod a YOLOv3 architektúrát és újratanítod. A pontosság (mAp75) nagyobb, mint 0.95. De a futási idő még mindig alacsony. A francba.
Ma kihagyjuk a kvantálást. De alább megnézzük Modellmetszés — a hálózat redundáns részeinek levágása a következtetés felgyorsítása érdekében a pontosság feláldozása nélkül. Ez világosan mutatja, hogy hol, mennyit és hogyan kell levágni. Megvizsgáljuk, hogyan lehet ezt manuálisan és hol automatizálni. A Keras repository a végén érhető el.
Bevezetés
Az előző munkahelyemen, a permi Macroscopnál kialakult egy szokásom: mindig figyelni az algoritmusok végrehajtási idejét. A hálózati futási időket mindig egy megfelelőségi szűrőn keresztül ellenőrzik. A legmodernebb éles környezetben lévő adatok jellemzően nem mennek át ezen a szűrőn, ami vezetett a metszéshez.
A metszés egy régi téma, amelyet már többször is megvitattak 2017-ben. Az alapötlet az, hogy a különböző csomópontok eltávolításával csökkentsék a betanított hálózat méretét a pontosság feláldozása nélkül. Jól hangzik, de ritkán hallok a használatáról. Talán nincs elég implementáció, nincsenek orosz nyelvű cikkek, vagy mindenki egyszerűen csak egy know-how metszését fontolgatja, és hallgat.
De nehéz kitalálni.
Pillantás a biológiába
Imádom, amikor a biológiai ötletek beépülnek a mélytanulásba. Ezekben, akárcsak az evolúcióban, meg lehet bízni (tudtad, hogy a ReLU nagyon hasonlít a ...-hoz/-höz)? ?)
A modell metszésének folyamata szintén közel áll a biológiához. A hálózat itt mutatott válasza az agy plaszticitásához hasonlítható. A könyv néhány érdekes példát tartalmaz. :
- Egy nő agya, akinek csak az egyik agyféltekéje született, átprogramozta magát, hogy ellássa a hiányzó fél funkcióit.
- A fickó agyának a látásért felelős részét lőtte ki. Idővel az agy más részei vették át ezeket a funkciókat. (Ezt nem fogjuk megismételni.)
Hasonlóképpen kivághatsz néhány gyengébb köteget a modelledből. Szükség esetén a megmaradt kötegekkel pótolhatod a kivágottakat.
Szereted a transzfertanulást, vagy a nulláról tanulsz?
Első számú lehetőség. Transfer Learninget használsz Yolov3, Retina, Mask-RCNN vagy U-Net alapú rendszereken. De leggyakrabban nincs szükségünk 80 objektumosztály felismerésére, mint a COCO-ban. Tapasztalataim szerint ez 1-2 osztályra korlátozódik. Csábító lehet azt feltételezni, hogy egy 80 osztályos architektúra túlzás. Ez azt sugallja, hogy az architektúrát csökkenteni kell. Ráadásul ezt a meglévő előre betanított súlyok elvesztése nélkül szeretnénk megtenni.
Kettős számú lehetőség. Lehet, hogy rengeteg adatod és számítási erőforrásod van, vagy csak egy szuper-egyedi architektúrára van szükséged. Nem számít. De a hálózatot a nulláról tanítod. A szokásos eljárás az, hogy megnézed az adatstruktúrát, kiválasztasz egy NAGYON erős architektúrát, és a túlillesztés elkerülése érdekében kiiktatod a kihagyásokat. Láttam már 0.6-os kihagyásokat, Karl.
Mindkét esetben a hálózat csökkenthető. Motiváltál. Most pedig derítsük ki, mi is az a metszés.
Általános algoritmus
Úgy döntöttünk, hogy eltávolítjuk a redőket. Elég egyszerűnek tűnik:
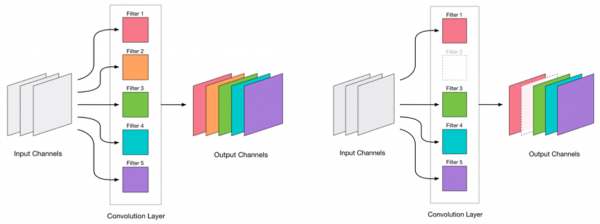
Bármely konvolúció eltávolítása terheli a hálózatot, ami általában némi hibaszázalékkal jár. Egyrészt ez a hibaszázalékkal való növekedés jelzi, hogy mennyire jól távolítjuk el a konvolúciókat (például egy nagy növekedés azt jelzi, hogy valamit rosszul csinálunk). Azonban egy kis hibaszázalékkal való növekedés tökéletesen elfogadható, és gyakran korrigálható egy későbbi, kis LR-rel végzett könnyű újratanítással. Adjunk hozzá egy újratanítási lépést:
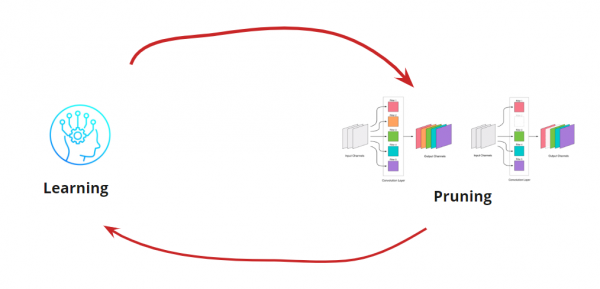
Most ki kell találnunk, hogy mikor akarjuk leállítani a Tanulás<->Metszés ciklust. Előfordulhatnak itt szokatlan helyzetek, például amikor a hálózatot egy adott méretre és futási sebességre kell skáláznunk (például mobileszközök esetén). A leggyakoribb forgatókönyv azonban az, hogy a ciklust addig folytatjuk, amíg a hiba meghaladja az elfogadható értéket. Adjuk hozzá a feltételt:
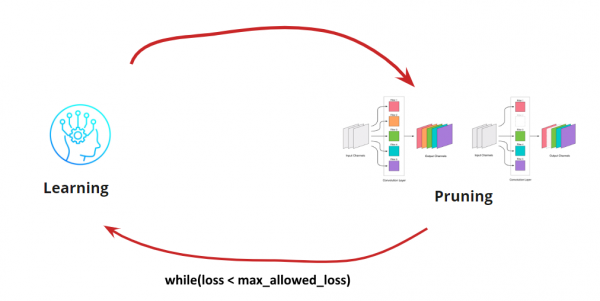
Tehát az algoritmus világos. Most nézzük meg, hogyan határozzuk meg, mely konvolúciókat kell eltávolítani.
Törölhető hajtások keresése
Törölnünk kell néhány csomagot. Rohanva belevágni és mindegyiket „lelőni” rossz ötlet, még akkor is, ha működni fog. De ha van egy kis eszed, elgondolkodhatsz rajta, és megpróbálhatod azonosítani a törlendő „gyenge” csomagokat. Több lehetőség is van:
- Az az elképzelés, hogy a kis súlyértékekkel rendelkező konvolúciók kevéssé járulnak hozzá a végső döntéshez
- A legkisebb L1-pontszám az átlag és a szórás alapján. Kiegészítve az eloszlás jellegének becslésével.
- A jelentéktelen gyűrődések pontosabb észlelése, de nagyon idő- és erőforrásigényes.
- Egyéb
Minden opciónak megvannak a saját megvalósíthatósági és megvalósítási szempontjai. Itt a legalacsonyabb L1 pontszámmal rendelkező opciót vesszük figyelembe.
Manuális folyamat a YOLOv3-hoz
Az eredeti architektúra tartalmaz maradék blokkokat. De bármennyire is menők a mély hálózatok számára, némileg hátráltatják a működést. A nehézség az, hogy nem tudjuk eltávolítani az összehasonlításokat a különböző indexekkel ezekben a rétegekben:
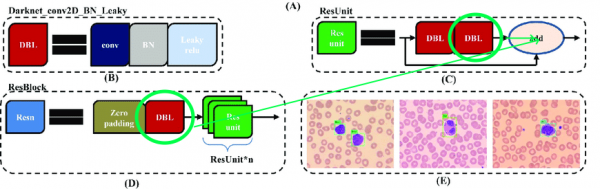
Ezért válasszuk ki azokat a rétegeket, amelyekről szabadon eltávolíthatunk egyeztetéseket:

Most építsünk fel egy munkaciklust:
- Aktiválások eltávolítása
- Találjuk ki, mennyit kell kivágni
- Kivágtuk
- 10 epochot vizsgálunk, ahol LR=1e-4
- Tesztelés
A redők kirakodása hasznos annak felmérésére, hogy mennyi anyag távolítható el egy adott lépésben. A kirakodás példái:
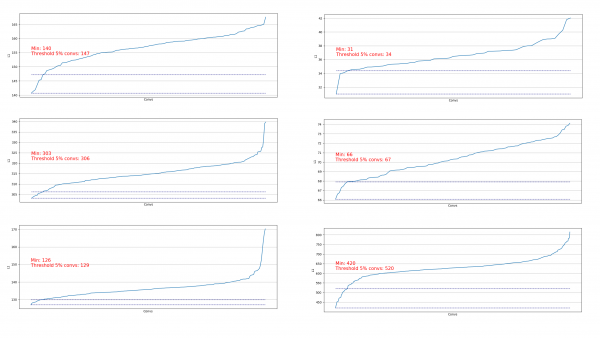
Azt látjuk, hogy szinte mindenhol a konvolúciók 5%-a nagyon alacsony L1 normával rendelkezik, és ezeket el tudjuk távolítani. Minden lépésben megismételtük ezt a tehermentesítést, és felmértük, hogy mely rétegek és hány réteg távolítható el.
A teljes folyamat négy lépésből állt (az itt és mindenhol máshol szereplő számok az RTX 2060 Super-re vonatkoznak):
| Lépés | mAp75 | Paraméterek száma, millió | Hálózat mérete, MB | Az eredetihez képest, % | Futási idő, ms | Körülmetélési állapot |
|---|---|---|---|---|---|---|
| 0 | 0.9656 | 60 | 241 | 100 | 180 | - |
| 1 | 0.9622 | 55 | 218 | 91 | 175 | az összes 5%-a |
| 2 | 0.9625 | 50 | 197 | 83 | 168 | az összes 5%-a |
| 3 | 0.9633 | 39 | 155 | 64 | 155 | 15% 400+ konvolúciójú rétegek esetén |
| 4 | 0.9555 | 31 | 124 | 51 | 146 | 10% 100+ konvolúciójú rétegek esetén |
A 2. lépés egy pozitív hatást adott hozzá: a 4-es méretű kötegek illeszkedtek a memóriába, ami jelentősen felgyorsította az újratanítási folyamatot.
A 4. lépésnél a folyamatot leállították, mivel még a hosszú távú kiegészítő képzés sem emelte az mAp75-öt a régi értékekre.
Ennek eredményeként sikerült felgyorsítanunk a következtetés levonását 15%, csökkentse a méretet ennyivel: 35% és ne veszítse el a pontosságát.
Automatizálás egyszerűbb architektúrákhoz
Egyszerűbb hálózati architektúrák esetén (feltételes összeadás, összefűzés és maradék blokkok nélkül) teljesen lehetséges az összes konvolúciós réteg feldolgozására összpontosítani, és automatizálni a konvolúciók kivágásának folyamatát.
Ezt a lehetőséget implementáltam. .
Egyszerű: csak egy veszteségfüggvényre, egy optimalizálóra és köteggenerátorokra van szükséged:
import pruning
from keras.optimizers import Adam
from keras.utils import Sequence
train_batch_generator = BatchGenerator...
score_batch_generator = BatchGenerator...
opt = Adam(lr=1e-4)
pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt)
pruner.prune(train_batch, valid_batch)Szükség esetén módosíthatja a konfigurációs paramétereket:
{
"input_model_path": "model.h5",
"output_model_path": "model_pruned.h5",
"finetuning_epochs": 10, # the number of epochs for train between pruning steps
"stop_loss": 0.1, # loss for stopping process
"pruning_percent_step": 0.05, # part of convs for delete on every pruning step
"pruning_standart_deviation_part": 0.2 # shift for limit pruning part
}Ezenkívül egy szóráson alapuló korlátozást is implementáltak. A cél az eltávolítandó adatok részének korlátozása, kizárva azokat a konvolúciókat, amelyek már "elegendő" L1 mértékekkel rendelkeznek:
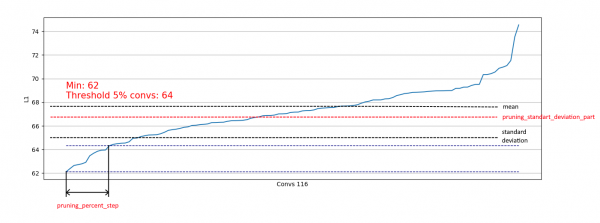
Így csak a jobb oldalihoz hasonló eloszlásokból távolítjuk el a gyenge konvolúciókat, és nem befolyásoljuk a bal oldalihoz hasonló eloszlásokból való eltávolítást:

Amikor az eloszlás megközelíti a normalitás határát, a metszési_standard_szórás_rész együttható a következők közül választható:
2 szigmás toleranciát javaslok. Alternatív megoldásként figyelmen kívül hagyhatja ezt a funkciót, és az értéket < 1.0-n hagyhatja.
A kimenet egy grafikon, amely a teljes teszt hálózati méretét, veszteségét és hálózati futásidejét mutatja, 1.0-re normalizálva. Például itt a hálózat méretét majdnem a kétszeresére csökkentettük a minőség romlása nélkül (egy kis konvolúciós hálózat 100 2 súllyal):
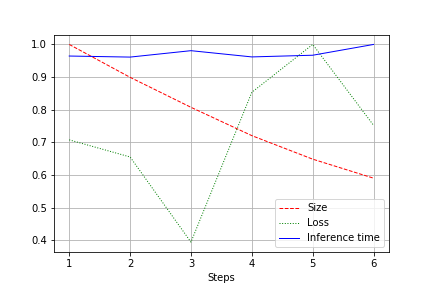
A futási sebesség a szokásos ingadozásoknak van kitéve, és gyakorlatilag változatlan maradt. Ennek van egy magyarázata:
- A konvolúciók száma a kényelmestől (32, 64, 128) a videokártyák számára kevésbé kényelmesig - 27, 51 stb. - változik. Tévedhetek, de valószínűleg ennek van hatása.
- Az architektúra nem széles, de következetes. A szélesség csökkentésével a mélységet nem változtatjuk. Ez csökkenti a terhelést a sebesség befolyásolása nélkül.
A javulás tehát a CUDA terhelésének 20-30%-os csökkenését eredményezte futás közben, de a futási idő csökkenését nem.
Eredményei
Gondolkodjunk el rajta. Két metszési lehetőséget vettünk figyelembe: egyet a YOLOv3-hoz (ami manuális feldolgozást igényel), és egyet az egyszerűbb architektúrájú hálózatokhoz. Nyilvánvaló, hogy mindkét esetben a hálózat mérete csökkenthető és a sebességnövelés elérhető a pontosság feláldozása nélkül. Eredmények:
- Méretének csökkentése
- Gyorsulási futás
- CUDA terhelés csökkentése
- Ennek eredményeként a környezetbarátság (Optimalizáljuk a számítástechnikai erőforrások jövőbeli felhasználását. Valahol boldog az ember )
Függelék
- A metszési lépés után a kvantálást is finomhangolhatja (például a TensorRT segítségével).
- A Tensorflow olyan képességeket kínál, mint a Működik.
- Fejlődésre vágyom, és örömmel fogadok segítséget.
Forrás: will.com
