

Canonical-ի ճարտարագիտական տնօրեն Ժան-Բատիստ Լալմենը ներկայացրեց Myna նախագիծը, որը մշակում է խոսքի ճանաչման հավելված, որը նախատեսված է ձայնային մուտքագրումը կազմակերպելու և բնական լեզվով հրամաններ ճանաչելու համար։ Ubuntu Աշխատասեղան։ Նախագիծը տարածվում է GPLv3 լիցենզիայի ներքո, սակայն պահոցը ներկայումս պարունակում է միայն նախագծի մոդուլային ճարտարապետությունը և դրա ինտեգրումը նկարագրող ուրվագծեր։ Ubuntu.
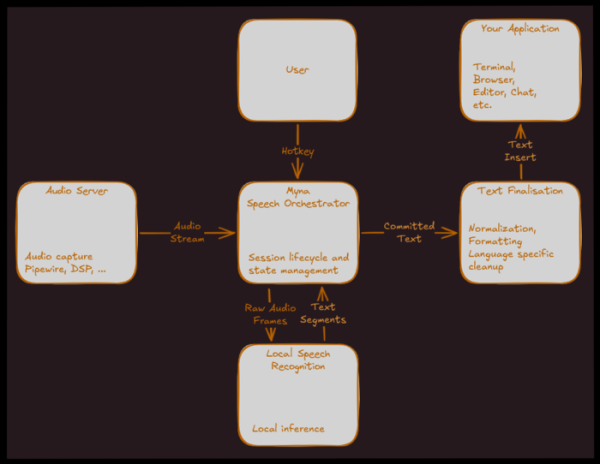
Թողարկման համար Ubuntu Հոկտեմբերի 26.10-ին նախատեսված է, որ հավելվածը համատեղելի լինի ձայնային մուտքագրման հետ։ Օգտատիրոջ սեսիան ներառում է հավելվածի ակտիվացում ստեղնաշարի կարճ հրամանի միջոցով, բարձրաձայն թելադրում և ճանաչված տեքստը մուտքագրում ընթացիկ հավելված՝ խոսելու ընթացքում սիմուլյացված ստեղնաշարային մուտքագրման միջոցով։ Միկրոֆոնը ակտիվացնելիս վահանակում կհայտնվի հատուկ ցուցիչ։
Հիմնական թեստավորման միջավայրը նշվում է որպես Wayland-ի վրա հիմնված GNOME, բայց ծրագիրը նախագծված է սկզբից այնպես, որ հարմարեցվի տարբեր աշխատասեղանային միջավայրերին։
Myna-ն խոսքի ճանաչման համար կօգտագործի տեղական մակարդակով աշխատող արհեստական բանականության մոդել: Հավելվածի պահանջները ներառում են՝ անցանց ռեժիմով աշխատելու հնարավորություն, միկրոֆոնի միացում միայն թելադրման ռեժիմը կարճ ստեղնով հստակորեն ակտիվացնելուց հետո, աուդիոյի մշակում հիշողության մեջ, որը մաքրվում է յուրաքանչյուր օգտագործումից հետո, և աուդիո ձայնագրությունների արտաքին ծառայություններ փոխանցման արգելում:
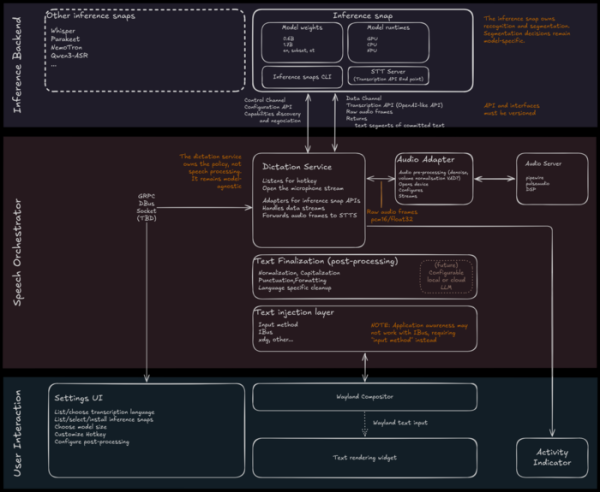
Խոսքի ճանաչման, օգտատիրոջ հետ փոխազդեցության, թելադրման կառավարման և տեքստի փոխարինման բաղադրիչները մշակվել են մոդուլների տեսքով։
Արհեստական բանականության մոդելի կատարման միջավայրը կներկայացվի որպես snapshot: Whisper-ը, Parakeet-ը, NemoTron-ը և Qwen3-ASR-ը նշվում են որպես հնարավոր ճանաչման մոդելներ:
Թելադրման կառավարման ծառայությունը վերահսկում է ստեղների սեղմումները, ակտիվացնում է միկրոֆոնը, API-ի միջոցով մուտք է գործում Snap փաթեթի արհեստական բանականության մոդելին, աուդիո ծառայությունից աուդիո հոսքը փոխանցում է դրան և համակարգում տվյալների հոսքերը:
Աուդիո ծառայությունը մուտք է գործում աուդիո սարքին կամ ուղղակիորեն, կամ PulseAudio կամ PipeWire աուդիո սերվերների միջոցով, ճնշում է աղմուկը և հավասարեցնում ձայնը: Մոդելի կողմից ստեղծված տեքստը փոխանցվում է հետմշակման մոդուլին՝ մաքրման, նորմալացման, ձևաչափման և կետադրության համար: Վերջնական տեքստը մուտքագրվում է ծրագրում մուտքագրման փոխարինման միջոցով, օրինակ՝ Wayland մուտքագրման մեթոդի արձանագրության կամ IBus-ի միջոցով:
Սկզբնական ֆունկցիոնալությունը կայունացնելուց հետո չի կարելի բացառել այնպիսի հնարավորությունների ներդրումը, ինչպիսիք են ձայնային օգնականի դեր կատարելը, ձայնային հրամաններ կատարելը, աշխատասեղանի ձայնային կառավարումը և թելադրված տեքստի թարգմանությունը՝ ավտոմատ լեզվի ճանաչմամբ։
Source: opennet.ru
