

Դասընթացի մեկնարկից առաջ ձեզ համար պատրաստել է մեկ այլ օգտակար նյութի թարգմանություն:
Huffman կոդավորումը տվյալների սեղմման ալգորիթմ է, որը ձևակերպում է ֆայլերի սեղմման հիմնական գաղափարը: Այս հոդվածում մենք կխոսենք ֆիքսված և փոփոխական երկարության կոդավորման, եզակի ապակոդավորվող կոդերի, նախածանցի կանոնների և Հաֆման ծառ կառուցելու մասին։
Մենք գիտենք, որ յուրաքանչյուր նիշ պահվում է որպես 0-ի և 1-ի հաջորդականություն և զբաղեցնում է 8 բիթ: Սա կոչվում է ֆիքսված երկարության կոդավորում, քանի որ յուրաքանչյուր նիշ պահելու համար օգտագործում է նույն ֆիքսված թվով բիթ:
Ենթադրենք, մեզ տեքստ է տրված: Ինչպե՞ս կարող ենք նվազեցնել մեկ նիշ պահելու համար պահանջվող տարածքը:
Հիմնական գաղափարը փոփոխական երկարության կոդավորումն է: Մենք կարող ենք օգտագործել այն փաստը, որ տեքստի որոշ նիշեր ավելի հաճախ են հանդիպում, քան մյուսները () մշակել ալգորիթմ, որը կներկայացնի նիշերի նույն հաջորդականությունը ավելի քիչ բիթերով: Փոփոխական երկարության կոդավորման դեպքում մենք նիշերին հատկացնում ենք բիթերի փոփոխական քանակ՝ կախված նրանից, թե որքան հաճախ են դրանք հայտնվում տվյալ տեքստում: Ի վերջո, որոշ նիշերի կարող է պահանջվել ընդամենը 1 բիթ, մինչդեռ մյուսները կարող են տևել 2 բիթ, 3 կամ ավելի: Փոփոխական երկարության կոդավորման խնդիրը միայն հաջորդականության հետագա վերծանումն է:
Ինչպե՞ս, իմանալով բիթերի հաջորդականությունը, այն միանշանակ վերծանել:
Հաշվի առեք գիծը «աբադաբ». Այն ունի 8 նիշ, և ֆիքսված երկարություն կոդավորելիս այն պահելու համար անհրաժեշտ կլինի 64 բիթ: Նշենք, որ խորհրդանիշի հաճախականությունը «ա», «բ», «գ» и «Դ» հավասար է համապատասխանաբար 4, 2, 1, 1: Փորձենք պատկերացնել «աբադաբ» ավելի քիչ բիթ, օգտագործելով այն փաստը, որ «դեպի» տեղի է ունենում ավելի հաճախ, քան «Բ»Իսկ «Բ» տեղի է ունենում ավելի հաճախ, քան «գ» и «Դ». Սկսենք կոդավորումից «դեպի» մեկ բիթով, որը հավասար է 0-ի, «Բ» մենք կնշանակենք երկու բիթանոց ծածկագիր 11, իսկ օգտագործելով երեք բիթ 100 և 011 մենք կոդավորում ենք «գ» и «Դ».
Արդյունքում մենք կստանանք.
a
0
b
11
c
100
d
011
Այսպիսով, գիծը «աբադաբ» մենք կոդավորենք որպես 00110100011011 (0|0|11|0|100|011|0|11)օգտագործելով վերը նշված ծածկագրերը: Այնուամենայնիվ, հիմնական խնդիրը լինելու է վերծանման մեջ: Երբ փորձում ենք վերծանել տողը 00110100011011, մենք կստանանք երկիմաստ արդյունք, քանի որ այն կարող է ներկայացվել հետևյալ կերպ.
0|011|0|100|011|0|11 adacdab
0|0|11|0|100|0|11|011 aabacabd
0|011|0|100|0|11|0|11 adacabab
...
եւ այլն:
Այս երկիմաստությունից խուսափելու համար մենք պետք է ապահովենք, որ մեր կոդավորումը բավարարում է այնպիսի հայեցակարգին, ինչպիսին է նախածանցի կանոն, որն իր հերթին ենթադրում է, որ կոդերը կարող են վերծանվել միայն մեկ յուրահատուկ ձևով։ Նախածանցի կանոնը երաշխավորում է, որ ոչ մի ծածկագիր մյուսի նախածանց չէ: Կոդ ասելով մենք հասկանում ենք բիթերը, որոնք օգտագործվում են որոշակի նիշ ներկայացնելու համար: Վերոնշյալ օրինակում 0 նախածանց է 011, որը խախտում է նախածանցի կանոնը։ Այսպիսով, եթե մեր ծածկագրերը բավարարում են նախածանցի կանոնը, ապա մենք կարող ենք եզակի կերպով վերծանել (և հակառակը):
Եկեք վերանայենք վերը նշված օրինակը: Այս անգամ մենք կնշանակենք նշաններ «ա», «բ», «գ» и «Դ» ծածկագրեր, որոնք բավարարում են նախածանցի կանոնը:
a
0
b
10
c
110
d
111
Այս կոդավորմամբ՝ տողը «աբադաբ» կոդավորված կլինի որպես 00100100011010 (0|0|10|0|100|011|0|10): Բայց 00100100011010 մենք արդեն կկարողանանք միանշանակ վերծանել և վերադառնալ մեր սկզբնական տողին «աբադաբ».
Հաֆմանի կոդավորում
Այժմ, երբ մենք գործ ունենք փոփոխական երկարության կոդավորման և նախածանցի կանոնի հետ, եկեք խոսենք Հաֆմանի կոդավորման մասին:
Մեթոդը հիմնված է երկուական ծառերի ստեղծման վրա։ Դրանում հանգույցը կարող է լինել կամ վերջնական կամ ներքին։ Սկզբում բոլոր հանգույցները համարվում են տերևներ (տերմինալներ), որոնք ներկայացնում են ինքնին խորհրդանիշը և նրա քաշը (այսինքն՝ առաջացման հաճախականությունը): Ներքին հանգույցները պարունակում են նիշի կշիռը և վերաբերում են երկու հետնորդ հանգույցներին: Ընդհանուր համաձայնությամբ, քիչ «0» ներկայացնում է ձախ ճյուղին հետևելը և «1» - աջ կողմում. լրիվ ծառի մեջ N թողնում և N-1 ներքին հանգույցներ. Խորհուրդ է տրվում, որ Huffman ծառ կառուցելիս չօգտագործված նշանները հանվեն՝ օպտիմալ երկարության ծածկագրեր ստանալու համար:
Մենք կօգտագործենք առաջնահերթ հերթ՝ Huffman ծառ կառուցելու համար, որտեղ ամենացածր հաճախականությամբ հանգույցին կտրվի ամենաբարձր առաջնահերթությունը։ Շինարարության քայլերը նկարագրված են ստորև.
- Ստեղծեք տերևային հանգույց յուրաքանչյուր նիշի համար և ավելացրեք դրանք առաջնահերթ հերթում:
- Մինչ հերթում մեկից ավելի թերթ կա, արեք հետևյալը.
- Հեռացրեք ամենաբարձր առաջնահերթությամբ (նվազագույն հաճախականությամբ) երկու հանգույցները հերթից.
- Ստեղծեք նոր ներքին հանգույց, որտեղ այս երկու հանգույցները կլինեն երեխաներ, և առաջացման հաճախականությունը հավասար կլինի այս երկու հանգույցների հաճախականությունների գումարին:
- Ավելացրեք նոր հանգույց առաջնահերթ հերթում:
- Միակ մնացած հանգույցը կլինի արմատը, և դա կավարտի ծառի կառուցումը:
Պատկերացրեք, որ մենք ունենք ինչ-որ տեքստ, որը բաղկացած է միայն նիշերից "Ա Բ Գ Դ" и «և», և դրանց առաջացման հաճախականությունը համապատասխանաբար 15, 7, 6, 6 և 5 է։ Ստորև բերված են նկարազարդումներ, որոնք արտացոլում են ալգորիթմի քայլերը:
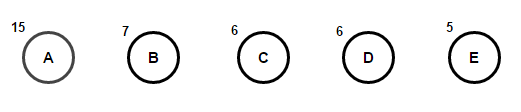
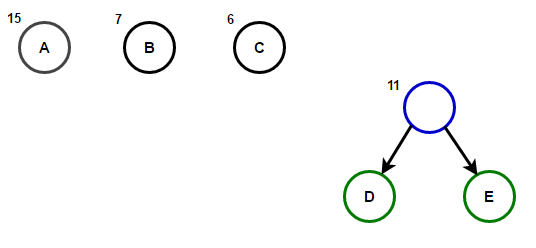
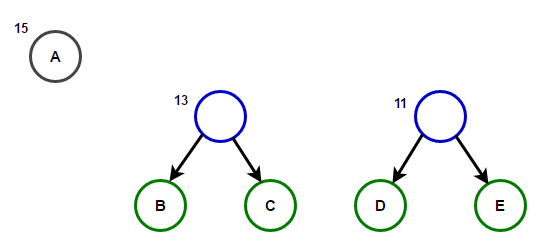
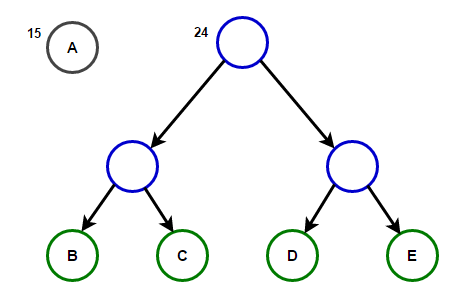
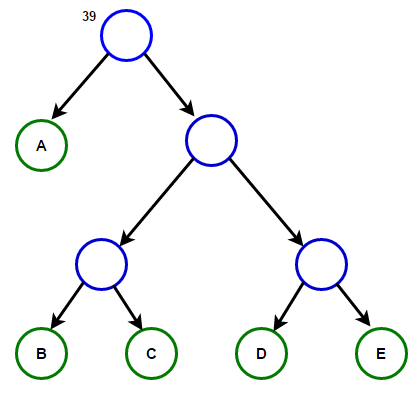
Արմատից մինչև ցանկացած վերջի հանգույց տանող ճանապարհը կպահի օպտիմալ նախածանցային ծածկագիրը (նաև հայտնի է որպես Հաֆմանի կոդ), որը համապատասխանում է այդ վերջնական հանգույցի հետ կապված նիշին:
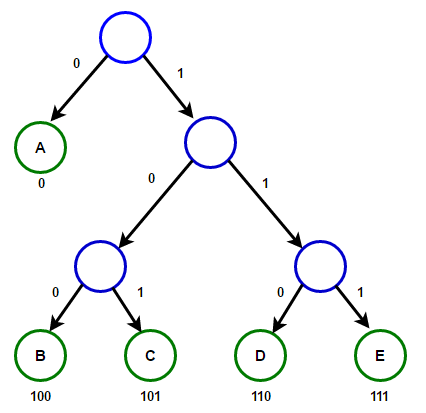
Հաֆմանի ծառ
Ստորև դուք կգտնեք Huffman սեղմման ալգորիթմի իրականացումը C++-ում և Java-ում.
#include <iostream>
#include <string>
#include <queue>
#include <unordered_map>
using namespace std;
// A Tree node
struct Node
{
char ch;
int freq;
Node *left, *right;
};
// Function to allocate a new tree node
Node* getNode(char ch, int freq, Node* left, Node* right)
{
Node* node = new Node();
node->ch = ch;
node->freq = freq;
node->left = left;
node->right = right;
return node;
}
// Comparison object to be used to order the heap
struct comp
{
bool operator()(Node* l, Node* r)
{
// highest priority item has lowest frequency
return l->freq > r->freq;
}
};
// traverse the Huffman Tree and store Huffman Codes
// in a map.
void encode(Node* root, string str,
unordered_map<char, string> &huffmanCode)
{
if (root == nullptr)
return;
// found a leaf node
if (!root->left && !root->right) {
huffmanCode[root->ch] = str;
}
encode(root->left, str + "0", huffmanCode);
encode(root->right, str + "1", huffmanCode);
}
// traverse the Huffman Tree and decode the encoded string
void decode(Node* root, int &index, string str)
{
if (root == nullptr) {
return;
}
// found a leaf node
if (!root->left && !root->right)
{
cout << root->ch;
return;
}
index++;
if (str[index] =='0')
decode(root->left, index, str);
else
decode(root->right, index, str);
}
// Builds Huffman Tree and decode given input text
void buildHuffmanTree(string text)
{
// count frequency of appearance of each character
// and store it in a map
unordered_map<char, int> freq;
for (char ch: text) {
freq[ch]++;
}
// Create a priority queue to store live nodes of
// Huffman tree;
priority_queue<Node*, vector<Node*>, comp> pq;
// Create a leaf node for each character and add it
// to the priority queue.
for (auto pair: freq) {
pq.push(getNode(pair.first, pair.second, nullptr, nullptr));
}
// do till there is more than one node in the queue
while (pq.size() != 1)
{
// Remove the two nodes of highest priority
// (lowest frequency) from the queue
Node *left = pq.top(); pq.pop();
Node *right = pq.top(); pq.pop();
// Create a new internal node with these two nodes
// as children and with frequency equal to the sum
// of the two nodes' frequencies. Add the new node
// to the priority queue.
int sum = left->freq + right->freq;
pq.push(getNode(' ', sum, left, right));
}
// root stores pointer to root of Huffman Tree
Node* root = pq.top();
// traverse the Huffman Tree and store Huffman Codes
// in a map. Also prints them
unordered_map<char, string> huffmanCode;
encode(root, "", huffmanCode);
cout << "Huffman Codes are :n" << 'n';
for (auto pair: huffmanCode) {
cout << pair.first << " " << pair.second << 'n';
}
cout << "nOriginal string was :n" << text << 'n';
// print encoded string
string str = "";
for (char ch: text) {
str += huffmanCode[ch];
}
cout << "nEncoded string is :n" << str << 'n';
// traverse the Huffman Tree again and this time
// decode the encoded string
int index = -1;
cout << "nDecoded string is: n";
while (index < (int)str.size() - 2) {
decode(root, index, str);
}
}
// Huffman coding algorithm
int main()
{
string text = "Huffman coding is a data compression algorithm.";
buildHuffmanTree(text);
return 0;
}import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;
// A Tree node
class Node
{
char ch;
int freq;
Node left = null, right = null;
Node(char ch, int freq)
{
this.ch = ch;
this.freq = freq;
}
public Node(char ch, int freq, Node left, Node right) {
this.ch = ch;
this.freq = freq;
this.left = left;
this.right = right;
}
};
class Huffman
{
// traverse the Huffman Tree and store Huffman Codes
// in a map.
public static void encode(Node root, String str,
Map<Character, String> huffmanCode)
{
if (root == null)
return;
// found a leaf node
if (root.left == null && root.right == null) {
huffmanCode.put(root.ch, str);
}
encode(root.left, str + "0", huffmanCode);
encode(root.right, str + "1", huffmanCode);
}
// traverse the Huffman Tree and decode the encoded string
public static int decode(Node root, int index, StringBuilder sb)
{
if (root == null)
return index;
// found a leaf node
if (root.left == null && root.right == null)
{
System.out.print(root.ch);
return index;
}
index++;
if (sb.charAt(index) == '0')
index = decode(root.left, index, sb);
else
index = decode(root.right, index, sb);
return index;
}
// Builds Huffman Tree and huffmanCode and decode given input text
public static void buildHuffmanTree(String text)
{
// count frequency of appearance of each character
// and store it in a map
Map<Character, Integer> freq = new HashMap<>();
for (int i = 0 ; i < text.length(); i++) {
if (!freq.containsKey(text.charAt(i))) {
freq.put(text.charAt(i), 0);
}
freq.put(text.charAt(i), freq.get(text.charAt(i)) + 1);
}
// Create a priority queue to store live nodes of Huffman tree
// Notice that highest priority item has lowest frequency
PriorityQueue<Node> pq = new PriorityQueue<>(
(l, r) -> l.freq - r.freq);
// Create a leaf node for each character and add it
// to the priority queue.
for (Map.Entry<Character, Integer> entry : freq.entrySet()) {
pq.add(new Node(entry.getKey(), entry.getValue()));
}
// do till there is more than one node in the queue
while (pq.size() != 1)
{
// Remove the two nodes of highest priority
// (lowest frequency) from the queue
Node left = pq.poll();
Node right = pq.poll();
// Create a new internal node with these two nodes as children
// and with frequency equal to the sum of the two nodes
// frequencies. Add the new node to the priority queue.
int sum = left.freq + right.freq;
pq.add(new Node(' ', sum, left, right));
}
// root stores pointer to root of Huffman Tree
Node root = pq.peek();
// traverse the Huffman tree and store the Huffman codes in a map
Map<Character, String> huffmanCode = new HashMap<>();
encode(root, "", huffmanCode);
// print the Huffman codes
System.out.println("Huffman Codes are :n");
for (Map.Entry<Character, String> entry : huffmanCode.entrySet()) {
System.out.println(entry.getKey() + " " + entry.getValue());
}
System.out.println("nOriginal string was :n" + text);
// print encoded string
StringBuilder sb = new StringBuilder();
for (int i = 0 ; i < text.length(); i++) {
sb.append(huffmanCode.get(text.charAt(i)));
}
System.out.println("nEncoded string is :n" + sb);
// traverse the Huffman Tree again and this time
// decode the encoded string
int index = -1;
System.out.println("nDecoded string is: n");
while (index < sb.length() - 2) {
index = decode(root, index, sb);
}
}
public static void main(String[] args)
{
String text = "Huffman coding is a data compression algorithm.";
buildHuffmanTree(text);
}
}Նշում: մուտքային տողի կողմից օգտագործվող հիշողությունը 47 * 8 = 376 բիթ է, իսկ կոդավորված տողը ընդամենը 194 բիթ, այսինքն. տվյալները սեղմված են մոտ 48%-ով։ Վերևի C++ ծրագրում մենք օգտագործում ենք տողերի դասը՝ կոդավորված տողը պահելու համար՝ ծրագիրը ընթեռնելի դարձնելու համար։
Քանի որ արդյունավետ առաջնահերթ հերթի տվյալների կառուցվածքները պահանջում են մեկ ներդիրում O(log(N)) ժամանակ, բայց ամբողջական երկուական ծառի հետ N թողնում է ներկա 2N-1 հանգույցներ, իսկ Huffman ծառը ամբողջական երկուական ծառ է, այնուհետև ալգորիթմը գործում է O(Nlog(N)) ժամանակը, որտեղ N - Կերպարներ.
Աղբյուրները
Source: www.habr.com
