

KDB+, ընկերության արտադրանք լայնորեն հայտնի է նեղ շրջանակներում, չափազանց արագ, սյունակային տվյալների բազա, որը նախատեսված է ժամանակային շարքերի և դրանց հիման վրա վերլուծական հաշվարկների պահպանման համար: Սկզբում այն շատ տարածված է եղել (և ունի) ֆինանսական ոլորտում. այն օգտագործվում է բոլոր լավագույն 10 ներդրումային բանկերի և շատ հայտնի հեջ-ֆոնդերի, բորսաների և այլ կազմակերպությունների կողմից: Վերջերս KX-ը որոշեց ընդլայնել իր հաճախորդների բազան և այժմ լուծումներ է առաջարկում այլ ոլորտներում, որտեղ կան մեծ քանակությամբ տվյալներ՝ կազմակերպված ըստ ժամանակի կամ այլ կերպ՝ հեռահաղորդակցության, բիոինֆորմատիկա, արտադրություն և այլն: Նրանք նաև դարձել են Aston Martin Red Bull Racing թիմի գործընկերը Formula 1-ում, որտեղ նրանք օգնում են հավաքել և մշակել տվյալներ մեքենաների սենսորներից և վերլուծել քամու թունելի թեստերը: Այս հոդվածում ես ուզում եմ ձեզ պատմել, թե KDB+-ի որ հատկանիշներն են դարձնում այն գերգործունակ, ինչու են ընկերությունները պատրաստ մեծ գումարներ ծախսել դրա վրա և վերջապես ինչու այն իրականում տվյալների բազա չէ:

Այս հոդվածում ես կփորձեմ ձեզ ընդհանուր առմամբ պատմել, թե ինչ է KDB+-ը, ինչ հնարավորություններ և սահմանափակումներ ունի այն և ինչ առավելություններ ունի այն ընկերությունների համար, որոնք ցանկանում են մշակել մեծ քանակությամբ տվյալներ: Ես չեմ խորանա KDB+-ի ներդրման մանրամասներին կամ նրա Q ծրագրավորման լեզվի մանրամասներին։Այս երկու թեմաներն էլ շատ լայն են և արժանի են առանձին հոդվածների։ Այս թեմաների վերաբերյալ շատ տեղեկություններ կարելի է գտնել code.kx.com կայքում, ներառյալ Q - Q For Mortals-ի մասին գիրքը (տես ստորև նշված հղումը):
Որոշ տերմիններ
- Հիշողության տվյալների բազա: Տվյալների բազա, որը պահում է տվյալները RAM-ում՝ ավելի արագ մուտք գործելու համար: Նման տվյալների բազայի առավելությունները պարզ են, սակայն թերությունները տվյալների կորստի հնարավորությունն են և սերվերի վրա մեծ հիշողություն ունենալու անհրաժեշտությունը:
- Սյունակային տվյալների բազա. Տվյալների բազա, որտեղ տվյալները պահվում են սյունակ առ սյունակ, այլ ոչ թե գրանցում առ գրառում: Նման տվյալների բազայի հիմնական առավելությունն այն է, որ մեկ սյունակի տվյալները միասին պահվում են սկավառակի վրա և հիշողության մեջ, ինչը զգալիորեն արագացնում է մուտքը դեպի այն: Հարցման մեջ չօգտագործված սյունակները բեռնելու կարիք չկա: Հիմնական թերությունն այն է, որ դժվար է փոփոխել և ջնջել գրառումները։
- Ժամանակային շարքեր. Տվյալներ ամսաթվի կամ ժամի սյունակով: Սովորաբար, ժամանակի պատվիրումը կարևոր է նման տվյալների համար, որպեսզի հեշտությամբ կարողանաք որոշել, թե որ գրառումն է նախորդում կամ հաջորդում ընթացիկին, կամ կիրառել գործառույթներ, որոնց արդյունքները կախված են գրառումների հերթականությունից: Դասական տվյալների շտեմարանները կառուցված են բոլորովին այլ սկզբունքով. ներկայացնում են գրառումների հավաքածուն որպես հավաքածու, որտեղ գրառումների հերթականությունը, սկզբունքորեն, սահմանված չէ:
- Վեկտոր. KDB+-ի համատեքստում սա նույն ատոմային տիպի տարրերի ցանկ է, օրինակ՝ թվեր։ Այլ կերպ ասած, տարրերի զանգված: Զանգվածները, ի տարբերություն ցուցակների, կարող են կոմպակտ կերպով պահպանվել և մշակվել՝ օգտագործելով վեկտորային պրոցեսորի հրահանգները:
Պատմական տեղեկատվություն
KX-ը հիմնադրվել է 1993 թվականին Արթուր Ուիթնիի կողմից, ով նախկինում աշխատել է Morgan Stanley Bank-ում A+ լեզվի վրա, որը APL-ի իրավահաջորդն է՝ ֆինանսական աշխարհում շատ օրիգինալ և երբեմնի հայտնի լեզու: Իհարկե, KX-ում Արթուրը շարունակեց նույն ոգով և ստեղծեց վեկտոր-ֆունկցիոնալ K լեզուն՝ առաջնորդվելով արմատական մինիմալիզմի գաղափարներով։ K ծրագրերը նման են կետադրական նշանների և հատուկ նիշերի խառնաշփոթի, նշանների և գործառույթների նշանակությունը կախված է համատեքստից, և յուրաքանչյուր գործողություն շատ ավելի մեծ նշանակություն ունի, քան սովորական ծրագրավորման լեզուներում: Դրա շնորհիվ K ծրագիրը զբաղեցնում է նվազագույն տարածք՝ մի քանի տող կարող է փոխարինել տեքստի էջերը այնպիսի բանավոր լեզվով, ինչպիսին Java-ն է, և հանդիսանում է ալգորիթմի գերկենտրոնացված իրականացում:
K-ում ֆունկցիա, որն իրականացնում է LL1 վերլուծիչի գեներատորի մեծ մասը՝ ըստ տվյալ քերականության.
1. pp:{q:{(x;p3(),y)};r:$[-11=@x;$x;11=@x;q[`N;$*x];10=abs@@x;q[`N;x]
2. ($)~*x;(`P;p3 x 1);(1=#x)&11=@*x;pp[{(1#x;$[2=#x;;,:]1_x)}@*x]
3. (?)~*x;(`Q;pp[x 1]);(*)~*x;(`M;pp[x 1]);(+)~*x;(`MP;pp[x 1]);(!)~*x;(`Y;p3 x 1)
4. (2=#x)&(@x 1)in 100 101 107 7 -7h;($[(@x 1)in 100 101 107h;`Ff;`Fi];p3 x 1;pp[*x])
5. (|)~*x;`S,(pp'1_x);2=#x;`C,{@[@[x;-1+#x;{x,")"}];0;"(",]}({$[".s.C"~4#x;6_-2_x;x]}'pp'x);'`pp];
6. $[@r;r;($[1<#r;".s.";""],$*r),$[1<#r;"[",(";"/:1_r),"]";""]]}
Արթուրը մարմնավորեց ծայրահեղ արդյունավետության այս փիլիսոփայությունը մարմնի նվազագույն շարժումներով KDB+-ում, որը հայտնվեց 2003 թվականին (կարծում եմ, հիմա պարզ է, թե որտեղից է գալիս անվան K տառը) և ոչ այլ ինչ է, քան K-ի չորրորդ տարբերակի թարգմանիչ: լեզու: K K-ի վերևում ավելացվել է ավելի հարմար տարբերակ, որը կոչվում է Q: Q-ն նաև ավելացրել է աջակցություն SQL-ի որոշակի բարբառի համար՝ QSQL, իսկ թարգմանիչը՝ աղյուսակների աջակցություն՝ որպես համակարգի տվյալների տեսակ, աղյուսակների հետ աշխատելու գործիքներ: հիշողության մեջ և սկավառակի վրա և այլն:
Այսպիսով, օգտագործողի տեսանկյունից KDB+-ը պարզապես Q լեզվի թարգմանիչ է, որն աջակցում է աղյուսակներին և SQL-ի նման LINQ ոճի արտահայտություններին C#-ից: Սա KDB+-ի և այլ տվյալների բազաների միջև ամենակարևոր տարբերությունն է և նրա հիմնական մրցակցային առավելությունը, որը հաճախ անտեսվում է: Սա տվյալների բազա չէ + անջատված օժանդակ լեզու, այլ լիարժեք հզոր ծրագրավորման լեզու + տվյալների բազայի գործառույթների ներկառուցված աջակցություն: Այս տարբերակումը որոշիչ դեր կխաղա KDB+-ի բոլոր առավելությունները թվարկելու համար: Օրինակ…
չափ
Ժամանակակից չափանիշներով KDB+-ն իր չափերով պարզապես մանրադիտակային է: Դա բառացիորեն մեկ ենթամեգաբայթանոց գործարկվող ֆայլ է և մեկ փոքր տեքստային ֆայլ՝ որոշ համակարգի գործառույթներով: Իրականում` մեկ մեգաբայթից պակաս, և այս ծրագրի համար ընկերությունները տարեկան տասնյակ հազարավոր դոլարներ են վճարում սերվերի մեկ պրոցեսորի համար:
- Այս չափը թույլ է տալիս KDB+-ին հիանալի զգալ ցանկացած սարքավորման վրա՝ Pi միկրոհամակարգիչից մինչև տերաբայթ հիշողությամբ սերվերներ: Սա ոչ մի կերպ չի ազդում ֆունկցիոնալության վրա, ավելին, Q-ն անմիջապես սկսվում է, ինչը թույլ է տալիս այն օգտագործել, ի թիվս այլ բաների, որպես սցենարային լեզու:
- Այս չափի դեպքում Q թարգմանիչը ամբողջությամբ տեղավորվում է պրոցեսորի քեշի մեջ, որն արագացնում է ծրագրի կատարումը:
- Գործարկվող ֆայլի այս չափի դեպքում Q պրոցեսը հիշողության մեջ աննշան տեղ է զբաղեցնում, դուք կարող եք գործարկել հարյուրավոր դրանցից: Ավելին, անհրաժեշտության դեպքում Q-ն կարող է գործել տասնյակ կամ հարյուրավոր գիգաբայթ հիշողությամբ մեկ գործընթացի ընթացքում:
բազմակողմանիություն
Q-ն հիանալի է կիրառությունների լայն շրջանակի համար: Գործընթացը Q-ն կարող է հանդես գալ որպես պատմական տվյալների բազա և ապահովել արագ մուտք դեպի տերաբայթ տեղեկատվություն: Օրինակ, մենք ունենք տասնյակ պատմական տվյալների շտեմարաններ, որոնցից մի քանիսում մեկ չսեղմված օրվա տվյալները զբաղեցնում են ավելի քան 100 գիգաբայթ: Այնուամենայնիվ, ողջամիտ սահմանափակումների դեպքում տվյալների բազայի հարցումը կավարտվի տասնյակից հարյուրավոր միլիվայրկյանների ընթացքում: Ընդհանուր առմամբ, մենք ունենք օգտատերերի հարցումների համընդհանուր ժամանակացույց՝ 30 վայրկյան, և այն շատ հազվադեպ է աշխատում:
Q-ն նույնքան հեշտությամբ կարող է լինել հիշողության տվյալների բազա: Նոր տվյալներ են ավելացվում հիշողության աղյուսակներում այնքան արագ, որ օգտատերերի հարցումները սահմանափակող գործոն են: Աղյուսակների տվյալները պահվում են սյունակներում, ինչը նշանակում է, որ սյունակի ցանկացած գործողություն կօգտագործի պրոցեսորի քեշը ամբողջ հզորությամբ: Բացի այդ, KX-ը փորձեց իրականացնել բոլոր հիմնական գործողությունները, ինչպիսիք են թվաբանությունը, պրոցեսորի վեկտորային հրահանգների միջոցով, առավելագույնի հասցնելով դրանց արագությունը: Q-ն կարող է նաև կատարել այնպիսի առաջադրանքներ, որոնք բնորոշ չեն տվյալների շտեմարաններին. օրինակ՝ մշակել հոսքային տվյալները և հաշվարկել «իրական ժամանակում» (տասնյակ միլիվայրկյանից մինչև մի քանի վայրկյան ուշացումով, կախված առաջադրանքից) տարբեր ժամանակի ֆինանսական գործիքների ագրեգացման գործառույթներ։ ընդմիջումներ կամ կառուցել շուկայի վրա կատարյալ գործարքների ազդեցության մոդել և իրականացնել դրա պրոֆիլավորումը դրա ավարտից գրեթե անմիջապես հետո: Նման առաջադրանքներում ամենից հաճախ հիմնական ժամանակի հետաձգումը ոչ թե Q-ն է, այլ տարբեր աղբյուրներից տվյալների համաժամացման անհրաժեշտությունը: Բարձր արագություն է ձեռք բերվում այն պատճառով, որ տվյալները և դրանք մշակող գործառույթները գտնվում են մեկ գործընթացում, և մշակումը կրճատվում է մինչև մի քանի QSQL արտահայտություններ և միացումներ, որոնք չեն մեկնաբանվում, այլ կատարվում են երկուական կոդով:
Վերջապես, դուք կարող եք գրել ցանկացած սպասարկման գործընթաց Q-ում: Օրինակ, Gateway-ը պրոցեսներ է անում, որոնք ավտոմատ կերպով բաշխում են օգտատերերի հարցումները անհրաժեշտ տվյալների բազաներին և սերվերներին: Ծրագրավորողը լիակատար ազատություն ունի հավասարակշռելու, առաջնահերթությունների, սխալների հանդուրժողականության, մուտքի իրավունքի, քվոտաների և հիմնականում ցանկացած այլ ալգորիթմ իրականացնելու համար, որն իր սրտում ցանկանում է: Այստեղ հիմնական խնդիրն այն է, որ դուք ստիպված կլինեք այս ամենը իրականացնել ինքներդ։
Որպես օրինակ՝ ես կթվարկեմ, թե ինչ տեսակի պրոցեսներ ունենք։ Դրանք բոլորն ակտիվորեն օգտագործվում և աշխատում են միասին՝ միավորելով տասնյակ տարբեր տվյալների բազաներ մեկում, մշակելով տվյալներ բազմաթիվ աղբյուրներից և սպասարկելով հարյուրավոր օգտատերերի և հավելվածներ:
- Միակցիչներ (feedhandler) տվյալների աղբյուրներին: Այս գործընթացները սովորաբար օգտագործում են արտաքին գրադարաններ, որոնք բեռնված են Q-ում: Q-ի C ինտերֆեյսը չափազանց պարզ է և թույլ է տալիս հեշտությամբ ստեղծել պրոքսի գործառույթներ ցանկացած C/C++ գրադարանի համար: Q-ն բավականաչափ արագ է, օրինակ, բոլոր եվրոպական ֆոնդային բորսաներից FIX հաղորդագրությունների հոսքը միաժամանակ մշակելու համար:
- Տվյալների դիստրիբյուտորներ (tickerplant), որոնք ծառայում են որպես միջանկյալ կապ միակցիչների և սպառողների միջև: Միևնույն ժամանակ, նրանք մուտքային տվյալները գրում են հատուկ երկուական մատյանում՝ ապահովելով սպառողների կայունությունը կապի կորստի կամ վերագործարկման դեմ:
- Հիշողության տվյալների բազա (rdb): Այս տվյալների շտեմարաններն ապահովում են ամենաարագ հասանելիությունը չմշակված, թարմ տվյալներին՝ դրանք պահելով հիշողության մեջ: Որպես կանոն, նրանք ցերեկային ժամերին տվյալները կուտակում են աղյուսակներում, իսկ գիշերը զրոյացնում դրանք:
- Մշտական տվյալների բազա (PDB): Այս տվյալների բազաները ապահովում են, որ այսօրվա տվյալները պահվեն պատմական տվյալների բազայում: Որպես կանոն, ի տարբերություն rdb-ի, նրանք տվյալներ չեն պահում հիշողության մեջ, այլ ցերեկը սկավառակի վրա օգտագործում են հատուկ քեշ, իսկ կեսգիշերին տվյալները պատճենում են պատմական տվյալների բազայում։
- Պատմական տվյալների բազաներ (hdb): Այս տվյալների բազաները հասանելի են դարձնում նախորդ օրերի, ամիսների և տարիների տվյալները: Նրանց չափը (օրերով) սահմանափակվում է միայն կոշտ սկավառակների չափերով։ Տվյալները կարող են տեղակայվել ցանկացած վայրում, մասնավորապես՝ տարբեր սկավառակների վրա՝ մուտքն արագացնելու համար: Հնարավոր է սեղմել տվյալները՝ օգտագործելով ընտրելու մի քանի ալգորիթմներ: Տվյալների բազայի կառուցվածքը լավ փաստագրված է և պարզ, տվյալները պահվում են սյունակ առ սյունակ սովորական ֆայլերում, որպեսզի դրանք հնարավոր լինի մշակել, այդ թվում՝ օպերացիոն համակարգի միջոցով:
- Տվյալների շտեմարաններ՝ համախմբված տեղեկություններով: Նրանք պահում են տարբեր ագրեգացիաներ, սովորաբար խմբավորված ըստ գործիքի անվանման և ժամանակային ընդմիջման: Հիշողության շտեմարանները թարմացնում են իրենց վիճակը յուրաքանչյուր մուտքային հաղորդագրության հետ, իսկ պատմական տվյալների բազաները պահում են նախապես հաշվարկված տվյալները՝ արագացնելու մուտքը դեպի պատմական տվյալներ:
- Վերջապես, դարպասային գործընթացներհավելվածների և օգտատերերի սպասարկում: Q-ն թույլ է տալիս իրականացնել մուտքային հաղորդագրությունների ամբողջովին ասինխրոն մշակում, դրանք բաշխելով տվյալների բազաներում, ստուգելով մուտքի իրավունքները և այլն: Նկատի ունեցեք, որ հաղորդագրությունները սահմանափակված չեն և ամենից հաճախ SQL արտահայտություններ չեն, ինչպես դա այլ տվյալների բազաներում է: Ամենից հաճախ SQL արտահայտությունը թաքնված է հատուկ ֆունկցիայի մեջ և կառուցվում է օգտագործողի պահանջած պարամետրերի հիման վրա՝ ժամանակը փոխակերպվում է, զտվում, տվյալները նորմալացվում են (օրինակ՝ բաժնետոմսերի գինը հավասարեցվում է, եթե դիվիդենտներ են վճարվել) և այլն։
Տիպիկ ճարտարապետություն մեկ տվյալների տեսակի համար.
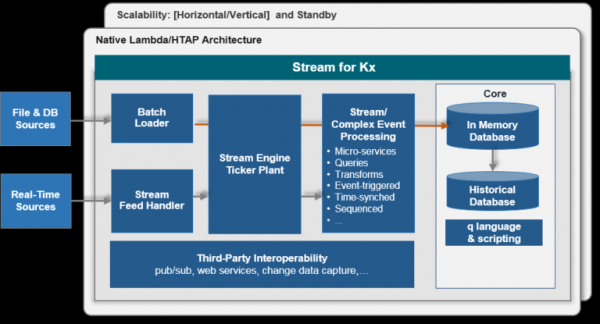
Բարեմաղթել
Չնայած Q-ն մեկնաբանվող լեզու է, այն նաև վեկտորային լեզու է: Սա նշանակում է, որ շատ ներկառուցված ֆունկցիաներ, հատկապես թվաբանականները, ընդունում են ցանկացած ձևի արգումենտներ՝ թվեր, վեկտորներ, մատրիցներ, ցուցակներ, և ծրագրավորողից ակնկալվում է, որ ծրագիրը կիրականացնի որպես զանգվածի գործողություններ: Նման լեզվով, եթե ավելացնեք միլիոն տարրերի երկու վեկտոր, այլևս նշանակություն չունի, որ լեզուն մեկնաբանվում է, հավելումը կկատարվի գերօպտիմիզացված երկուական ֆունկցիայի միջոցով: Քանի որ Q ծրագրերում ժամանակի առյուծի բաժինը ծախսվում է աղյուսակներով գործողությունների վրա, որոնք օգտագործում են այս հիմնական վեկտորացված գործառույթները, արդյունքը շատ պատշաճ գործառնական արագություն է, որը թույլ է տալիս մեզ մշակել հսկայական քանակությամբ տվյալներ նույնիսկ մեկ գործընթացում: Սա նման է Python-ի մաթեմատիկական գրադարաններին. չնայած Python-ն ինքնին շատ դանդաղ լեզու է, այն ունի բազմաթիվ հիանալի գրադարաններ, ինչպիսիք են numpy-ն, որոնք թույլ են տալիս մշակել թվային տվյալները կոմպիլացված լեզվի արագությամբ (ի դեպ, numpy-ն գաղափարապես մոտ է Q-ին: )
Բացի այդ, KX-ը շատ զգույշ մոտեցում է ցուցաբերել աղյուսակների նախագծման և դրանց հետ աշխատանքի օպտիմալացման հարցում: Նախ, աջակցվում են ինդեքսների մի քանի տեսակներ, որոնք աջակցվում են ներկառուցված գործառույթներով և կարող են կիրառվել ոչ միայն աղյուսակի սյունակների, այլև ցանկացած վեկտորի վրա՝ խմբավորում, տեսակավորում, եզակիության հատկանիշ և պատմական տվյալների բազաների հատուկ խմբավորում: Ցուցանիշը կիրառվում է պարզապես և ավտոմատ կերպով ճշգրտվում է սյունակում/վեկտորին տարրեր ավելացնելիս: Ցուցանիշները կարող են հավասարապես հաջողությամբ կիրառվել սեղանի սյունակների վրա ինչպես հիշողության, այնպես էլ սկավառակի վրա: QSQL հարցումը կատարելիս հնարավորության դեպքում ինդեքսներն օգտագործվում են ավտոմատ կերպով: Երկրորդ, պատմական տվյալների հետ աշխատանքը կատարվում է OS ֆայլերի ցուցադրման մեխանիզմի միջոցով (հիշողության քարտեզ): Մեծ աղյուսակները երբեք չեն բեռնվում հիշողության մեջ, փոխարենը, անհրաժեշտ սյունակները քարտեզագրվում են անմիջապես հիշողության մեջ, և դրանց միայն այն մասն է իրականում (այստեղ օգնում են նաև ինդեքսները), որոնք անհրաժեշտ են: Ծրագրավորողի համար տարբերություն չկա՝ տվյալները հիշողության մեջ են, թե ոչ, mmap-ի հետ աշխատելու մեխանիզմն ամբողջությամբ թաքնված է Q-ի խորքում։
KDB+-ը հարաբերական տվյալների բազա չէ, աղյուսակները կարող են պարունակել կամայական տվյալներ, մինչդեռ աղյուսակում տողերի հերթականությունը չի փոխվում, երբ ավելացվում են նոր տարրեր և կարող են և պետք է օգտագործվեն հարցումներ գրելիս: Այս հատկությունը շտապ անհրաժեշտ է ժամանակային շարքերի հետ աշխատելու համար (փոխանակման տվյալների, հեռաչափության, իրադարձությունների տեղեկամատյանների), քանի որ եթե տվյալները դասավորված են ըստ ժամանակի, ապա օգտագործողը կարիք չունի օգտագործել որևէ SQL հնարք՝ գտնելու առաջին կամ վերջին տողը կամ N-ը։ աղյուսակի տողերը, որոշեք, թե որ տողն է հաջորդում N-րդ տողին և այլն: Աղյուսակների միացումներն էլ ավելի պարզեցված են, օրինակ՝ 16000 միլիոն տարրերից բաղկացած աղյուսակում 500 VOD.L (Vodafone) գործարքների վերջին գնանշումը գտնելը տեւում է մոտ մեկ վայրկյան սկավառակի վրա, իսկ հիշողության մեջ՝ տասնյակ միլիվայրկյաններ:
Ժամկետային միացման օրինակ. մեջբերումների աղյուսակը քարտեզագրված է հիշողության մեջ, ուստի կարիք չկա նշելու VOD.L որտեղ, sym սյունակի ինդեքսը և տվյալների դասավորվածությունը ըստ ժամանակի անուղղակիորեն օգտագործվում են: Q-ի գրեթե բոլոր միացումները կանոնավոր ֆունկցիաներ են, ընտրված արտահայտության մաս չեն.
1. aj[`sym`time;select from trade where date=2019.03.26, sym=`VOD.L;select from quote where date=2019.03.26]
Վերջապես, հարկ է նշել, որ KX-ի ինժեներները, սկսած հենց Արթուր Ուիթնիից, իսկապես տարված են արդյունավետությամբ և ամեն ինչ անում են Q-ի ստանդարտ հնարավորություններից առավելագույնը ստանալու և օգտագործման ամենատարածված օրինաչափությունները օպտիմալացնելու համար:
Լրիվ
KDB+-ը հայտնի է բիզնեսների շրջանում հիմնականում իր բացառիկ բազմակողմանիության շնորհիվ. այն հավասարապես լավ է ծառայում որպես հիշողության տվյալների բազա, որպես տերաբայթ պատմական տվյալներ պահելու տվյալների բազա և տվյալների վերլուծության հարթակ: Շնորհիվ այն բանի, որ տվյալների մշակումը տեղի է ունենում անմիջապես տվյալների բազայում, ձեռք է բերվում աշխատանքի բարձր արագություն և ռեսուրսների խնայողություն: Լրիվ ծրագրավորման լեզուն, որը ինտեգրված է տվյալների բազայի գործառույթներին, թույլ է տալիս իրականացնել անհրաժեշտ գործընթացների ամբողջ փաթեթը մեկ հարթակի վրա՝ տվյալների ստացումից մինչև օգտագործողների հարցումների մշակում:
Լրացուցիչ տեղեկությունների համար,
Սահմանափակումները
KDB+/Q-ի զգալի թերությունը մուտքի բարձր շեմն է: Լեզուն ունի տարօրինակ շարահյուսություն, որոշ գործառույթներ խիստ ծանրաբեռնված են (արժեքը, օրինակ, ունի մոտ 11 օգտագործման դեպք): Ամենակարևորը, այն պահանջում է արմատապես այլ մոտեցում ծրագրեր գրելու համար: Վեկտորային լեզվով դուք պետք է միշտ մտածեք զանգվածի փոխակերպումների տեսանկյունից, բոլոր օղակները կատարեք քարտեզի մի քանի տարբերակների միջոցով (որոնք Q-ում կոչվում են մակդիրներ) և երբեք չփորձեք գումար խնայել՝ փոխարինելով վեկտորային գործողությունները ատոմայիններով: Օրինակ, զանգվածում տարրի N-րդ առաջացման ինդեքսը գտնելու համար պետք է գրել.
1. (where element=vector)[N]
չնայած դա ահավոր անարդյունավետ է թվում C/Java ստանդարտներով (= ստեղծում է բուլյան վեկտոր, որտեղ վերադարձնում է իր մեջ եղած տարրերի իրական ինդեքսները): Բայց այս նշումը ավելի պարզ է դարձնում արտահայտության իմաստը, և դուք օգտագործում եք արագ վեկտորային գործողություններ դանդաղ ատոմայինների փոխարեն: Վեկտորային լեզվի և մյուսների միջև հայեցակարգային տարբերությունը համեմատելի է ծրագրավորման հրամայական և ֆունկցիոնալ մոտեցումների տարբերության հետ, և դուք պետք է պատրաստ լինեք դրան:
Որոշ օգտվողներ նույնպես դժգոհ են QSQL-ից: Բանն այն է, որ այն միայն իրական SQL-ի տեսք ունի: Իրականում այն պարզապես SQL-ի նման արտահայտությունների թարգմանիչ է, որը չի աջակցում հարցումների օպտիմալացմանը: Օգտատերը պետք է ինքը գրի օպտիմալ հարցումներ, իսկ Q-ում, ինչին շատերը պատրաստ չեն։ Մյուս կողմից, իհարկե, դուք միշտ կարող եք ինքներդ գրել օպտիմալ հարցումը, այլ ոչ թե հենվելով սև արկղի օպտիմիզատորի վրա:
Որպես գումարած, Q - Q For Mortals-ի մասին գիրքը հասանելի է անվճար կայքում , այնտեղ հավաքված են նաեւ բազմաթիվ այլ օգտակար նյութեր։
Մեկ այլ մեծ թերություն լիցենզիայի արժեքն է: Դա տարեկան մեկ պրոցեսորի համար կազմում է տասնյակ հազարավոր դոլարներ: Նման ծախսեր կարող են իրենց թույլ տալ միայն խոշոր ընկերությունները։ Վերջերս KX-ն ավելի ճկուն է դարձրել իր արտոնագրման քաղաքականությունը և հնարավորություն է տալիս վճարել միայն օգտագործման ժամանակի համար կամ վարձել KDB+ Google-ի և Amazon-ի ամպերում: KX-ն առաջարկում է նաև ներբեռնում (32 բիթ տարբերակ կամ 64 բիթ ըստ պահանջի):
Մրցակիցներ
Նմանատիպ սկզբունքներով կառուցված բավականին շատ մասնագիտացված տվյալների բազաներ կան՝ սյունակային, հիշողության մեջ, կենտրոնացած շատ մեծ քանակությամբ տվյալների վրա: Խնդիրն այն է, որ դրանք մասնագիտացված տվյալների բազաներ են։ Վառ օրինակ է Clickhouse-ը: Այս տվյալների բազան շատ նման է KDB+-ին տվյալների սկավառակի վրա տվյալների պահպանման և ինդեքս ստեղծելու սկզբունքին, այն կատարում է որոշ հարցումներ ավելի արագ, քան KDB+-ը, թեև ոչ էականորեն: Բայց նույնիսկ որպես տվյալների բազա, Clickhouse-ն ավելի մասնագիտացված է, քան KDB+ - վեբ վերլուծություն ընդդեմ կամայական ժամանակային շարքերի (այս տարբերությունը շատ կարևոր է. դրա պատճառով, օրինակ, Clickhouse-ում հնարավոր չէ օգտագործել գրառումների պատվիրումը): Բայց, ամենակարևորը, Clickhouse-ը չունի KDB+-ի բազմակողմանիությունը, մի լեզու, որը թույլ կտա տվյալների մշակել անմիջապես տվյալների բազայում, այլ ոչ թե նախ բեռնել դրանք առանձին հավելվածում, կառուցել կամայական SQL արտահայտություններ, կիրառել կամայական գործառույթներ հարցումներում, ստեղծել գործընթացներ: կապված չէ պատմական տվյալների բազայի գործառույթների կատարման հետ: Հետևաբար, դժվար է KDB+-ը համեմատել այլ տվյալների բազաների հետ, դրանք կարող են ավելի լավ լինել որոշակի օգտագործման դեպքերում կամ պարզապես ավելի լավը, երբ խոսքը վերաբերում է տվյալների բազայի դասական առաջադրանքներին, բայց ես չգիտեմ ժամանակավոր տվյալների մշակման մեկ այլ նույնքան արդյունավետ և բազմակողմանի գործիք:
Python ինտեգրում
Որպեսզի KDB+-ն ավելի հեշտ օգտագործվի տեխնոլոգիային անծանոթ մարդկանց համար, KX-ը ստեղծեց գրադարաններ՝ սերտորեն ինտեգրվելու Python-ի հետ մեկ գործընթացում: Դուք կարող եք կամ զանգահարել Python-ի ցանկացած ֆունկցիա Q-ից, կամ հակառակը՝ զանգահարել Python-ից ցանկացած Q ֆունկցիա (մասնավորապես՝ QSQL արտահայտություններ): Գրադարանները, անհրաժեշտության դեպքում (ոչ միշտ հանուն արդյունավետության) փոխակերպում են տվյալներ մի լեզվի ձևաչափից մյուսի ձևաչափի: Արդյունքում Q-ն ու Python-ն ապրում են այնքան սերտ սիմբիոզում, որ նրանց միջև սահմանները մշուշոտ են: Արդյունքում, ծրագրավորողը, մի կողմից, լիովին հասանելի է Python-ի բազմաթիվ օգտակար գրադարաններին, մյուս կողմից՝ նա ստանում է Python-ում ինտեգրված մեծ տվյալների հետ աշխատելու արագ բազա, ինչը հատկապես օգտակար է մեքենայական ուսուցմամբ զբաղվողների համար: կամ մոդելավորում։
Q-ի հետ աշխատելը Python-ում.
1. >>> q()
2.q)trade:([]date:();sym:();qty:())
3. q)
4. >>> q.insert('trade', (date(2006,10,6), 'IBM', 200))
5. k(',0')
6. >>> q.insert('trade', (date(2006,10,6), 'MSFT', 100))
7. k(',1')
Սայլակ
Ընկերության կայքը -
Կայք մշակողների համար -
Գիրք Q մահկանացուների համար (անգլերեն) -
KDB+/Q հավելվածների վերաբերյալ հոդվածներ kx աշխատակիցներից -
Source: www.habr.com
