

Մենք հաջողությամբ նախագծեցինք մեր PostgreSQL տվյալների բազայի կառուցվածքը նամակագրությունը պահելու համար, անցել է մեկ տարի, օգտվողները ակտիվորեն լրացնում են այն, և այն արդեն ունի միլիոնավոր գրառումներ, և... ինչ-որ բան սկսեց դանդաղել։
- Մաս 2. «Ուղիղ եթեր» բաժին

Փաստն այն է, որ քանի որ սեղանի չափը մեծանում է, աճում է նաև ինդեքսների «խորությունը»: - թեկուզ լոգարիթմական: Բայց ժամանակի ընթացքում դա ստիպում է սերվերին կատարել նույն ընթերցման/գրելու առաջադրանքները մշակել շատ անգամ ավելի շատ տվյալների էջեր, քան սկզբում։
Այստեղ է, որ օգնության է հասնում հատվածավորումը.
Նշեմ, որ խոսքը Sharding-ի, այսինքն՝ տվյալների տարբեր բազաների կամ սերվերների միջև տվյալների բաշխման մասին չէ։ Որովհետև եթե նույնիսկ տվյալները բաժանենք մոտ սերվերներ, դուք չեք ազատվի ժամանակի ընթացքում ինդեքսների «ուռչելու» խնդրից: Հասկանալի է, որ եթե դուք կարող եք ձեզ թույլ տալ ամեն օր նոր սերվեր գործարկել, ապա ձեր խնդիրներն այլևս չեն սահմանափակվելու կոնկրետ տվյալների բազայով։
Մենք չենք դիտարկի «ապարատային» բաժինն իրականացնելու կոնկրետ սցենարներ, այլ մոտեցումն ինքնին. ինչը և ինչպես պետք է «կտրվի կտորներով», և ինչի է հանգեցնում նման ցանկությունը:
Հայեցակարգ
Եկեք նորից սահմանենք մեր նպատակը. մենք ուզում ենք այնպես անել, որ այսօր, վաղը և մեկ տարի անց PostgreSQL-ի կողմից կարդացվող տվյալների քանակը ցանկացած կարդալու/գրելու գործողության համար մնա մոտավորապես նույնը:
Ցանկացածի համար ժամանակագրականորեն կուտակված տվյալներ (հաղորդագրություններ, փաստաթղթեր, տեղեկամատյաններ, արխիվներ,…) բնական ընտրությունը որպես բաժանման բանալի է միջոցառման ամսաթիվ/ժամ. Մեր դեպքում նման իրադարձություն է հաղորդագրությունն ուղարկելու պահին.
Նշենք, որ օգտվողները գրեթե միշտ աշխատել միայն «վերջինների» հետ նման տվյալներ. նրանք կարդում են վերջին հաղորդագրությունները, վերլուծում են վերջին տեղեկամատյանները,... Ոչ, իհարկե, նրանք կարող են ժամանակի ընթացքում ավելի հետ պտտվել, բայց դա անում են շատ հազվադեպ:
Այս սահմանափակումներից պարզ է դառնում, որ հաղորդագրությունների օպտիմալ լուծումը կլինի «ամենօրյա» բաժինները — չէ՞ որ մեր օգտատերը գրեթե միշտ կկարդա, թե ինչ է իրեն ուղարկվել «այսօր» կամ «երեկ»։
Եթե օրվա ընթացքում գրում ու կարդում ենք գործնականում միայն մեկ հատվածում, ապա սա էլ է մեզ տալիս հիշողության և սկավառակի ավելի արդյունավետ օգտագործում - քանի որ բոլոր բաժինների ինդեքսները հեշտությամբ տեղավորվում են RAM-ում, ի տարբերություն «մեծ և համարձակ» ամբողջ աղյուսակի:
քայլ առ քայլ
Ընդհանուր առմամբ, վերը նշված ամեն ինչ հնչում է որպես մեկ մեծ շահույթ: Եվ դա հասանելի է, բայց մենք պետք է շատ ջանք գործադրենք դրա համար, քանի որ Սուբյեկտներից մեկը բաժանելու որոշումը հանգեցնում է հարակիցներին «տեսնելու» անհրաժեշտությանը.
Հաղորդագրություն, դրա հատկությունները և կանխատեսումները
Քանի որ մենք որոշեցինք կտրել հաղորդագրությունները ըստ ամսաթվերի, իմաստ ունի նաև բաժանել դրանցից կախված սուբյեկտները-հատկությունները (կցված ֆայլեր, հասցեատերերի ցուցակ) և նաև ըստ հաղորդագրության ամսաթվի.
Քանի որ մեր բնորոշ առաջադրանքներից մեկը հաղորդագրությունների գրանցամատյանների դիտումն է (չընթերցված, մուտքային, բոլորը), տրամաբանական է նաև դրանք «նկարել» բաժինների՝ ըստ հաղորդագրությունների ամսաթվերի:
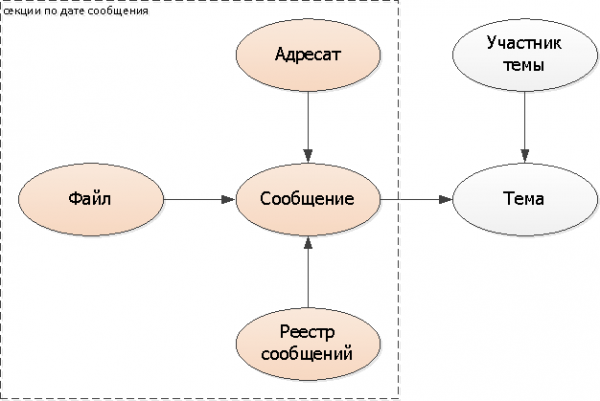
Մենք ավելացնում ենք բաժանման բանալին (հաղորդագրության ամսաթիվը) բոլոր աղյուսակներում՝ հասցեատերեր, ֆայլեր, գրանցամատյաններ: Պարտադիր չէ, որ այն ավելացնեք հաղորդագրության մեջ, այլ օգտագործեք առկա DateTime-ը:
Темы
Քանի որ թեման մեկն է մի քանի հաղորդագրությունների համար, այն այլևս հնարավոր չէ «կտրել» նույն մոդելով. մենք պետք է հենվենք այլ բանի վրա: Մեր դեպքում դա կատարյալ է նամակագրության առաջին հաղորդագրության ամսաթիվը — այսինքն հենց թեմայի ստեղծման պահը։
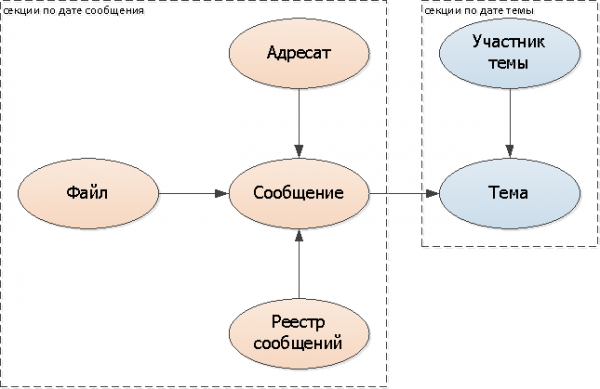
Ավելացնել բաժանման բանալի (թեմայի ամսաթիվ) բոլոր աղյուսակներում՝ թեմա, մասնակից:
Բայց հիմա մենք միանգամից երկու խնդիր ունենք.
- Ո՞ր բաժնում պետք է որոնեմ թեմայի վերաբերյալ հաղորդագրություններ:
- ո՞ր բաժնում փնտրեմ հաղորդագրության թեման:
Իհարկե, մենք կարող ենք շարունակել որոնումը բոլոր բաժիններում, բայց դա շատ տխուր կլինի և կչեղարկի մեր բոլոր շահումները: Հետևաբար, իմանալու համար, թե կոնկրետ որտեղ փնտրել, եկեք տրամաբանական հղումներ/ցուցիչներ կազմենք բաժիններին.
- մենք այն կավելացնենք հաղորդագրության մեջ թեմայի ամսաթվի դաշտ
- ավելացնենք թեմային հաղորդագրությունների ամսաթվերի հավաքածու այս նամակագրությունը (դա կարող է լինել առանձին աղյուսակ կամ ամսաթվերի զանգված)
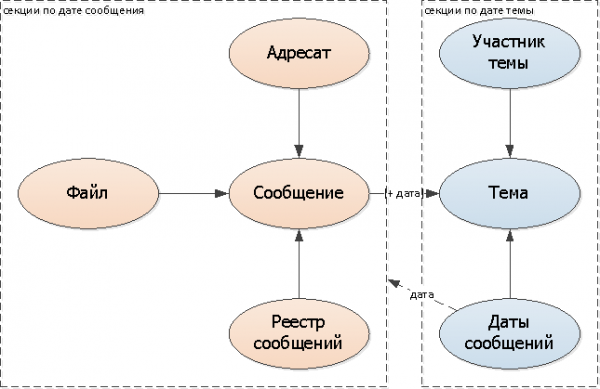
Քանի որ յուրաքանչյուր առանձին նամակագրության համար հաղորդագրությունների ամսաթվերի ցանկում քիչ փոփոխություններ կլինեն (ի վերջո, գրեթե բոլոր հաղորդագրությունները ընկնում են հարակից 1-2 օրվա ընթացքում), ես կկենտրոնանամ այս տարբերակի վրա:
Արդյունքում մեր տվյալների բազայի կառուցվածքը ստացավ հետևյալ ձևը՝ հաշվի առնելով բաժանումը.
Աղյուսակներ. RU, եթե դուք դեմ եք կիրիլիցային աղյուսակների/դաշտերի անուններում, ավելի լավ է չնայեք
-- секции по дате сообщения
CREATE TABLE "Сообщение_YYYYMMDD"(
"Сообщение"
uuid
PRIMARY KEY
, "Тема"
uuid
, "ДатаТемы"
date
, "Автор"
uuid
, "ДатаВремя" -- используем как дату
timestamp
, "Текст"
text
);
CREATE TABLE "Адресат_YYYYMMDD"(
"ДатаСообщения"
date
, "Сообщение"
uuid
, "Персона"
uuid
, PRIMARY KEY("Сообщение", "Персона")
);
CREATE TABLE "Файл_YYYYMMDD"(
"ДатаСообщения"
date
, "Файл"
uuid
PRIMARY KEY
, "Сообщение"
uuid
, "BLOB"
uuid
, "Имя"
text
);
CREATE TABLE "РеестрСообщений_YYYYMMDD"(
"ДатаСообщения"
date
, "Владелец"
uuid
, "ТипРеестра"
smallint
, "ДатаВремя"
timestamp
, "Сообщение"
uuid
, PRIMARY KEY("Владелец", "ТипРеестра", "Сообщение")
);
CREATE INDEX ON "РеестрСообщений_YYYYMMDD"("Владелец", "ТипРеестра", "ДатаВремя" DESC);
-- секции по дате темы
CREATE TABLE "Тема_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
PRIMARY KEY
, "Документ"
uuid
, "Название"
text
);
CREATE TABLE "УчастникТемы_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
, "Персона"
uuid
, PRIMARY KEY("Тема", "Персона")
);
CREATE TABLE "ДатыСообщенийТемы_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
PRIMARY KEY
, "Дата"
date
);
Մի կոպեկ խնայողություն
Դե, իսկ եթե չօգտագործենք հիմնվելով դաշտի արժեքների բաշխման վրա (գործարկիչների և ժառանգության կամ PARTITION BY-ի միջոցով) և «ձեռքով» հավելվածի մակարդակում, դուք կարող եք տեսնել, որ բաժանման բանալի արժեքն արդեն պահված է հենց աղյուսակի անունով:
Այսպիսով, եթե դուք այդպիսին եք շատ մտահոգված են պահվող տվյալների քանակով, ապա դուք կարող եք ազատվել այս «լրացուցիչ» դաշտերից և մուտք գործել հատուկ աղյուսակներ: Ճիշտ է, այս դեպքում մի քանի բաժիններից բոլոր ընտրվածները պետք է տեղափոխվեն հավելվածի կողմ:
Source: www.habr.com
