


Ի՞նչ սկզբունքներով է կառուցված տվյալների իդեալական պահեստը:
Կենտրոնացեք բիզնեսի արժեքի և վերլուծության վրա՝ կաթսայատան կոդի բացակայության դեպքում: DWH-ի կառավարում որպես կոդերի բազա՝ տարբերակավորում, վերանայում, ավտոմատացված թեստավորում և CI: Մոդուլյարություն, ընդարձակելիություն, բաց կոդով և համայնք: Օգտագործողի համար հարմար փաստաթղթեր և կախվածության վիզուալիզացիա (Data Lineage):
Ավելին այս ամենի և DBT-ի դերի մասին Big Data & Analytics էկոհամակարգում. բարի գալուստ cat:
Բարեւ բոլորին
Արտեմի Կոզիրը կապի մեջ է. Ավելի քան 5 տարի ես աշխատում եմ տվյալների պահեստների հետ, կառուցելով ETL/ELT, ինչպես նաև տվյալների վերլուծություն և վիզուալիզացիա: Ես այժմ աշխատում եմ , դասավանդում եմ OTUS-ում դասընթացի վրա , իսկ այսօր ուզում եմ ձեզ հետ կիսվել մի հոդվածով, որը գրել եմ մեկնարկի ակնկալիքով դասընթացի նոր գրանցում.
Կարճ ակնարկ
DBT շրջանակը T-ի մասին է ELT (Extract - Transform - Load) հապավումը:
Նման արդյունավետ և մասշտաբային վերլուծական տվյալների բազաների հայտնվելով, ինչպիսիք են BigQuery, Redshift, Snowflake, իմաստ չկար Տվյալների պահեստից դուրս փոխակերպումներ անել:
DBT-ն չի ներբեռնում տվյալներ աղբյուրներից, բայց մեծ հնարավորություններ է տալիս աշխատելու տվյալների հետ, որոնք արդեն բեռնված են Պահեստում (ներքին կամ արտաքին պահեստում):
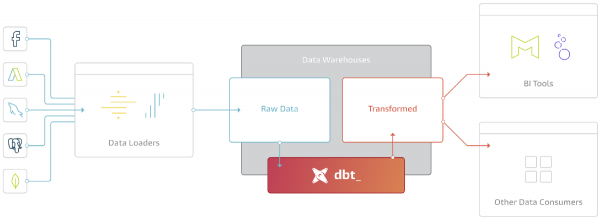
DBT-ի հիմնական նպատակն է վերցնել կոդը, այն կազմել SQL, հրամանները կատարել ճիշտ հաջորդականությամբ Repository-ում:
DBT Ծրագրի կառուցվածքը
Նախագիծը բաղկացած է ընդամենը 2 տեսակի դիրեկտորիաներից և ֆայլերից.
- Model (.sql) - փոխակերպման միավոր, որն արտահայտվում է SELECT հարցումով
- Կազմաձևման ֆայլ (.yml) - պարամետրեր, կարգավորումներ, թեստեր, փաստաթղթեր
Հիմնական մակարդակում աշխատանքը կառուցված է հետևյալ կերպ.
- Օգտագործողը պատրաստում է մոդելի կոդը ցանկացած հարմար IDE-ում
- Օգտագործելով CLI-ը, մոդելները գործարկվում են, DBT-ն մոդելի կոդը կազմում է SQL
- Կազմված SQL կոդը կատարվում է Storage-ում տվյալ հաջորդականությամբ (գրաֆիկ)
Ահա թե ինչպիսին կարող է լինել CLI-ից վազելը.
Ամեն ինչ SELECT է
Սա Data Build Tool շրջանակի սպանիչ հատկանիշն է: Այլ կերպ ասած, DBT-ն վերացում է ձեր հարցումները Խանութում նյութականացնելու հետ կապված բոլոր ծածկագրերը (CREATE, INSERT, UPDATE, DELETE ALTER, GRANT, ... հրամանների տատանումները):
Ցանկացած մոդել ներառում է մեկ SELECT հարցում գրել, որը սահմանում է ստացված տվյալների հավաքածուն:
Այս դեպքում փոխակերպման տրամաբանությունը կարող է լինել բազմամակարդակ և համախմբել մի քանի այլ մոդելների տվյալները: Մոդելի օրինակ, որը կկառուցի պատվերի ցուցափեղկ (f_orders):
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Ի՞նչ հետաքրքիր բաներ կարող ենք տեսնել այստեղ:
Առաջին. Օգտագործված CTE (ընդհանուր աղյուսակի արտահայտություններ) - կազմակերպելու և հասկանալու համար, որը պարունակում է բազմաթիվ փոխակերպումներ և բիզնես տրամաբանություն
Երկրորդ. մոդելի կոդը SQL-ի և լեզվի խառնուրդ է (կաղապարման լեզու):
Օրինակը օգտագործում է հանգույց համար արտահայտության մեջ նշված յուրաքանչյուր վճարման եղանակի համար գումար ստեղծելու համար սահմանել. Ֆունկցիան նույնպես օգտագործվում է Սայլակ — կոդի մեջ այլ մոդելներին հղում կատարելու հնարավորություն.
- Կազմման ժամանակ Սայլակ կվերածվի թիրախային ցուցիչի աղյուսակի կամ տեսքի Storage-ում
- Սայլակ թույլ է տալիս կառուցել մոդելի կախվածության գրաֆիկ
Ճիշտ DBT-ին ավելացնում է գրեթե անսահմանափակ հնարավորություններ: Առավել հաճախ օգտագործվողներն են.
- If / else հայտարարություններ - մասնաճյուղի հայտարարություններ
- Օղակների համար
- Փոփոխականներ
- Մակրո - մակրոների ստեղծում
Նյութականացում՝ աղյուսակ, տեսարան, աստիճանական
Նյութականացման ռազմավարությունը մոտեցում է, համաձայն որի արդյունքում ստացված մոդելային տվյալների հավաքածուն կպահվի Պահեստում:
Հիմնական առումով դա հետևյալն է.
- Աղյուսակ - ֆիզիկական աղյուսակ Պահպանման մեջ
- Դիտել - դիտել, վիրտուալ աղյուսակը Storage-ում
Կան նաև ավելի բարդ նյութականացման ռազմավարություններ.
- Աճող - աճող բեռնում (փաստերի խոշոր աղյուսակների); նոր տողեր են ավելացվում, փոխված տողերը թարմացվում են, ջնջված տողերը մաքրվում են
- Էֆեմերալ - մոդելը չի իրականանում ուղղակիորեն, այլ մասնակցում է որպես CTE այլ մոդելներում
- Ցանկացած այլ ռազմավարություն, որը դուք կարող եք ավելացնել ինքներդ
Ի հավելումն նյութականացման ռազմավարությունների, կան որոշակի պահեստների օպտիմալացման հնարավորություններ, օրինակ.
- Ձյան փաթիլԱնցումային աղյուսակներ, Միաձուլման վարքագիծ, Աղյուսակների խմբավորում, Պատճենման դրամաշնորհներ, Անվտանգ դիտումներ
- Redshift- ըDistkey, Sortkey (interleaved, բաղադրյալ), Late Binding Views
- մեծ հարցումԱղյուսակների բաժանում և խմբավորում, Միաձուլման վարքագիծ, KMS կոդավորում, պիտակներ և պիտակներ
- ԿայծՖայլի ձևաչափ (մանրահատակ, csv, json, orc, delta), partition_by, clustered_by, buckets, incremental_strategy
Հետևյալ Պահոցները ներկայումս աջակցվում են.
- Փոստգրես
- Redshift- ը
- մեծ հարցում
- Ձյան փաթիլ
- Պրեստո (մասնակի)
- կայծ (մասամբ)
- Microsoft SQL Server (համայնքային ադապտեր)
Եկեք բարելավենք մեր մոդելը.
- Եկեք դրա լցոնումը դարձնենք աստիճանական (Incremental)
- Եկեք Redshift-ի համար ավելացնենք հատվածավորման և տեսակավորման ստեղներ
-- Конфигурация модели:
-- Инкрементальное наполнение, уникальный ключ для обновления записей (unique_key)
-- Ключ сегментации (dist), ключ сортировки (sort)
{{
config(
materialized='incremental',
unique_key='order_id',
dist="customer_id",
sort="order_date"
)
}}
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
where 1=1
{% if is_incremental() -%}
-- Этот фильтр будет применен только для инкрементального запуска
and order_date >= (select max(order_date) from {{ this }})
{%- endif %}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Մոդելի կախվածության գրաֆիկ
Դա նաև կախվածության ծառ է: Այն նաև հայտնի է որպես DAG (Directed Acyclic Graph):
DBT-ն կառուցում է գրաֆիկ՝ հիմնված բոլոր նախագծերի մոդելների կազմաձևման վրա, ավելի ճիշտ՝ ref() կապերը մոդելների մեջ այլ մոդելների հետ: Գրաֆիկ ունենալը թույլ է տալիս անել հետևյալը.
- Գործող մոդելները ճիշտ հաջորդականությամբ
- Խանութի ցուցափեղկի ձևավորման զուգահեռացում
- Կամայական ենթագրաֆի վարում
Գրաֆիկի վիզուալիզացիայի օրինակ.
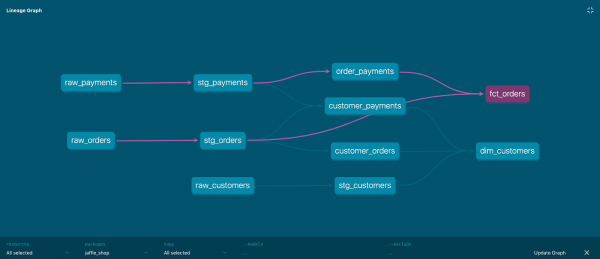
Գրաֆիկի յուրաքանչյուր հանգույց մոդել է, գրաֆիկի եզրերը նշված են ref արտահայտությամբ:
Տվյալների որակ և փաստաթղթավորում
Ի հավելումն ինքնին մոդելների ստեղծմանը, DBT-ն թույլ է տալիս ստուգել մի շարք ենթադրություններ ստացված տվյալների հավաքածուի վերաբերյալ, ինչպիսիք են.
- Ոչ զրոյական
- Եզակի
- Հղման ամբողջականություն - հղման ամբողջականություն (օրինակ՝ պատվերների աղյուսակում customer_id-ը համապատասխանում է հաճախորդների աղյուսակի id-ին)
- Ընդունելի արժեքների ցանկի համապատասխանեցում
Հնարավոր է ավելացնել ձեր սեփական թեստերը (պատվերով տվյալների թեստեր), ինչպիսիք են, օրինակ, եկամտի տոկոսային շեղումը մեկ օրվա, մեկ շաբաթվա, մեկ ամիս առաջվա ցուցանիշներով: Ցանկացած ենթադրություն, որը ձևակերպված է որպես SQL հարցում, կարող է դառնալ թեստ։
Այս կերպ Դուք կարող եք որսալ Պահեստի պատուհանների տվյալների անցանկալի շեղումները և սխալները:
Փաստաթղթերի առումով DBT-ն ապահովում է մոդելի և նույնիսկ հատկանիշի մակարդակներում մետատվյալների և մեկնաբանությունների ավելացման, տարբերակման և բաշխման մեխանիզմներ:
Ահա թե ինչ տեսք ունի թեստեր և փաստաթղթեր ավելացնելը կազմաձևման ֆայլի մակարդակում.
- name: fct_orders
description: This table has basic information about orders, as well as some derived facts based on payments
columns:
- name: order_id
tests:
- unique # проверка на уникальность значений
- not_null # проверка на наличие null
description: This is a unique identifier for an order
- name: customer_id
description: Foreign key to the customers table
tests:
- not_null
- relationships: # проверка ссылочной целостности
to: ref('dim_customers')
field: customer_id
- name: order_date
description: Date (UTC) that the order was placed
- name: status
description: '{{ doc("orders_status") }}'
tests:
- accepted_values: # проверка на допустимые значения
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
Եվ ահա թե ինչ տեսք ունի այս փաստաթուղթը ստեղծված կայքում.
Մակրոներ և մոդուլներ
DBT-ի նպատակը ոչ այնքան SQL սկրիպտների մի շարք դառնալն է, որքան օգտատերերին սեփական փոխակերպումները կառուցելու և այդ մոդուլները բաշխելու հզոր և հնարավորություններով հարուստ միջոցներ տրամադրելը:
Մակրոները կոնստրուկտների և արտահայտությունների հավաքածուներ են, որոնք կարելի է անվանել որպես ֆունկցիաներ մոդելներում: Մակրոները թույլ են տալիս նորից օգտագործել SQL մոդելների և նախագծերի միջև՝ համաձայն DRY (Don't Repeat Yourself) ինժեներական սկզբունքի:
Մակրո օրինակ.
{% macro rename_category(column_name) %}
case
when {{ column_name }} ilike '%osx%' then 'osx'
when {{ column_name }} ilike '%android%' then 'android'
when {{ column_name }} ilike '%ios%' then 'ios'
else 'other'
end as renamed_product
{% endmacro %}
Եվ դրա օգտագործումը.
{% set column_name = 'product' %}
select
product,
{{ rename_category(column_name) }} -- вызов макроса
from my_table
DBT-ն ունի փաթեթի կառավարիչ, որը թույլ է տալիս օգտվողներին հրապարակել և վերօգտագործել առանձին մոդուլներ և մակրոներ:
Սա նշանակում է, որ կարող եք բեռնել և օգտագործել այնպիսի գրադարաններ, ինչպիսիք են՝
- աշխատել ամսաթվի/ժամանակի, փոխնակ ստեղների, սխեմաների թեստերի, առանցքային/չեղարկելու և այլնի հետ
- Պատրաստի ցուցափեղկերի ձևանմուշներ այնպիսի ծառայությունների համար, ինչպիսիք են и
- Գրադարաններ հատուկ տվյալների խանութների համար, օրինակ.
- — DBT գործառնությունների գրանցման մոդուլ
Փաթեթների ամբողջական ցանկը կարող եք գտնել այստեղ .
Նույնիսկ ավելի շատ առանձնահատկություններ
Այստեղ ես նկարագրելու եմ մի քանի այլ հետաքրքիր առանձնահատկություններ և իրականացումներ, որոնք ես և թիմը օգտագործում ենք տվյալների պահեստ կառուցելու համար: .
Գործարկման միջավայրերի տարանջատում DEV - TEST - PROD
Նույնիսկ նույն DWH կլաստերի ներսում (տարբեր սխեմաների շրջանակներում): Օրինակ՝ օգտագործելով հետևյալ արտահայտությունը.
with source as (
select * from {{ source('salesforce', 'users') }}
where 1=1
{%- if target.name in ['dev', 'test', 'ci'] -%}
where timestamp >= dateadd(day, -3, current_date)
{%- endif -%}
)
Այս կոդը բառացիորեն ասում է՝ միջավայրերի համար dev, test, ci վերցնել տվյալները միայն վերջին 3 օրվա համար և ոչ ավելին: Այսինքն՝ այս միջավայրերում վազելը շատ ավելի արագ կլինի և ավելի քիչ ռեսուրսներ կպահանջի։ Երբ աշխատում է շրջակա միջավայրի վրա արտադրել ֆիլտրի վիճակը անտեսվելու է:
Նյութականացում այլընտրանքային սյունակի կոդավորման միջոցով
Redshift-ը սյունակային DBMS է, որը թույլ է տալիս սահմանել տվյալների սեղմման ալգորիթմներ յուրաքանչյուր առանձին սյունակի համար: Օպտիմալ ալգորիթմների ընտրությունը կարող է նվազեցնել սկավառակի տարածությունը 20-50%-ով:
Մակրո կկատարի ANALYZE COMPRESSION հրամանը, կստեղծի նոր աղյուսակ՝ առաջարկվող սյունակային կոդավորման ալգորիթմներով, նշված հատվածավորման ստեղներով (dist_key) և տեսակավորման ստեղներով (sort_key), տվյալները կփոխանցի դրան և, անհրաժեշտության դեպքում, կջնջի հին պատճենը:
Մակրո ստորագրություն.
{{ compress_table(schema, table,
drop_backup=False,
comprows=none|Integer,
sort_style=none|compound|interleaved,
sort_keys=none|List<String>,
dist_style=none|all|even,
dist_key=none|String) }}
Գործում է անտառահատման մոդելը
Մոդելի յուրաքանչյուր կատարման վրա կարող եք կեռիկներ կցել, որոնք կկատարվեն մինչև գործարկումը կամ մոդելի ստեղծման ավարտից անմիջապես հետո.
pre-hook: "{{ logging.log_model_start_event() }}"
post-hook: "{{ logging.log_model_end_event() }}"
Լոգինգի մոդուլը թույլ կտա ձեզ գրանցել բոլոր անհրաժեշտ մետատվյալները առանձին աղյուսակում, որը հետագայում կարող է օգտագործվել խցանումների աուդիտի և վերլուծության համար:
Ահա, թե ինչ տեսք ունի վահանակը, որը հիմնված է Looker-ի գրանցման տվյալների վրա.
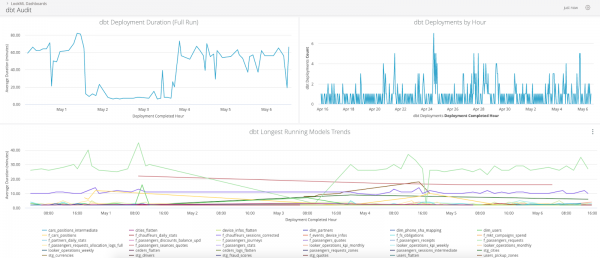
Պահեստների պահպանման ավտոմատացում
Եթե դուք օգտագործում եք օգտագործված պահեստի ֆունկցիոնալության որոշ ընդլայնումներ, ինչպիսիք են UDF-ը (User Defined Functions), ապա այս գործառույթների տարբերակումը, մուտքի վերահսկումը և նոր թողարկումների ավտոմատ դուրսբերումը շատ հարմար է DBT-ում:
Մենք օգտագործում ենք UDF-ը Python-ում՝ հեշերը, էլփոստի տիրույթները և բիտդիմակների վերծանումը հաշվարկելու համար:
Մակրոյի օրինակ, որը ստեղծում է UDF ցանկացած կատարման միջավայրում (dev, test, prod).
{% macro create_udf() -%}
{% set sql %}
CREATE OR REPLACE FUNCTION {{ target.schema }}.f_sha256(mes "varchar")
RETURNS varchar
LANGUAGE plpythonu
STABLE
AS $$
import hashlib
return hashlib.sha256(mes).hexdigest()
$$
;
{% endset %}
{% set table = run_query(sql) %}
{%- endmacro %}
Wheely-ում մենք օգտագործում ենք Amazon Redshift-ը, որը հիմնված է PostgreSQL-ի վրա: Redshift-ի համար կարևոր է պարբերաբար վիճակագրություն հավաքել աղյուսակների վրա և ազատել սկավառակի տարածքը՝ համապատասխանաբար ANALYZE և VACUUM հրամանները:
Դա անելու համար redshift_maintenance մակրոյից հրամանները կատարվում են ամեն գիշեր.
{% macro redshift_maintenance() %}
{% set vacuumable_tables=run_query(vacuumable_tables_sql) %}
{% for row in vacuumable_tables %}
{% set message_prefix=loop.index ~ " of " ~ loop.length %}
{%- set relation_to_vacuum = adapter.get_relation(
database=row['table_database'],
schema=row['table_schema'],
identifier=row['table_name']
) -%}
{% do run_query("commit") %}
{% if relation_to_vacuum %}
{% set start=modules.datetime.datetime.now() %}
{{ dbt_utils.log_info(message_prefix ~ " Vacuuming " ~ relation_to_vacuum) }}
{% do run_query("VACUUM " ~ relation_to_vacuum ~ " BOOST") %}
{{ dbt_utils.log_info(message_prefix ~ " Analyzing " ~ relation_to_vacuum) }}
{% do run_query("ANALYZE " ~ relation_to_vacuum) %}
{% set end=modules.datetime.datetime.now() %}
{% set total_seconds = (end - start).total_seconds() | round(2) %}
{{ dbt_utils.log_info(message_prefix ~ " Finished " ~ relation_to_vacuum ~ " in " ~ total_seconds ~ "s") }}
{% else %}
{{ dbt_utils.log_info(message_prefix ~ ' Skipping relation "' ~ row.values() | join ('"."') ~ '" as it does not exist') }}
{% endif %}
{% endfor %}
{% endmacro %}
DBT Cloud
Հնարավոր է DBT-ն օգտագործել որպես ծառայություն (Managed Service): Ներառված է՝
- Web IDE նախագծերի և մոդելների մշակման համար
- Աշխատանքի կազմաձևում և պլանավորում
- Պարզ և հարմար մուտք դեպի տեղեկամատյաններ
- Կայք ձեր նախագծի փաստաթղթերով
- Միացում CI (շարունակական ինտեգրում)
Ամփոփում
DWH-ի պատրաստումը և օգտագործումը դառնում է նույնքան հաճելի և օգտակար, որքան սմուզի խմելը: DBT-ն բաղկացած է Jinja-ից, օգտվողների ընդլայնումներից (մոդուլներից), կոմպիլյատորից, կատարողից և փաթեթի կառավարիչից: Այս տարրերը միասին հավաքելով՝ դուք ստանում եք ամբողջական աշխատանքային միջավայր ձեր տվյալների պահեստի համար: Այսօր DWH-ում փոխակերպումը կառավարելու ավելի լավ միջոց հազիվ թե գտնվի:

DBT-ի մշակողների համոզմունքները ձևակերպված են հետևյալ կերպ.
- Կոդը, ոչ թե GUI-ն, լավագույն աբստրակցիան է բարդ վերլուծական տրամաբանություն արտահայտելու համար
- Տվյալների հետ աշխատելը պետք է հարմարեցնի ծրագրային ապահովման ճարտարագիտության լավագույն փորձը (Ծրագրային ճարտարագիտություն)
- Տվյալների կարևոր ենթակառուցվածքը պետք է վերահսկվի օգտվողների համայնքի կողմից՝ որպես բաց կոդով ծրագրակազմ
- Ոչ միայն վերլուծական գործիքները, այլև ծածկագիրը գնալով կդառնա բաց կոդով համայնքի սեփականությունը
Այս հիմնական համոզմունքները ստեղծել են արտադրանք, որն այսօր օգտագործվում է ավելի քան 850 ընկերությունների կողմից, և դրանք հիմք են հանդիսանում ապագայում ստեղծվող բազմաթիվ հետաքրքիր ընդլայնումների համար:
Հետաքրքրվողների համար կա մի բաց դասի տեսանյութ, որը ես տվել եմ մի քանի ամիս առաջ OTUS-ում բաց դասի շրջանակներում - .
Բացի DBT-ից և Data Warehousing-ից, որպես Data Engineer դասընթացի մաս OTUS հարթակում, ես և իմ գործընկերները դասեր ենք անցկացնում մի շարք այլ համապատասխան և ժամանակակից թեմաներով.
- Ճարտարապետական հայեցակարգեր մեծ տվյալների կիրառման համար
- Պարապեք Spark-ի և Spark Streaming-ի հետ
- Տվյալների աղբյուրները բեռնելու մեթոդների և գործիքների ուսումնասիրություն
- DWH-ում վերլուծական ցուցափեղկերի կառուցում
- NoSQL հասկացություններ՝ HBase, Cassandra, ElasticSearch
- Մոնիտորինգի և նվագախմբի սկզբունքները
- Եզրափակիչ նախագիծ. բոլոր հմտությունները միավորել մենթորական աջակցության ներքո
Հղումներ.
- - Պաշտոնական փաստաթղթեր
- — Վերանայեք DBT-ի հեղինակներից մեկի հոդվածը
- — YouTube, OTUS բաց դասի ձայնագրում
- — Հաջորդ բաց դասը՝ 15 մայիսի 2020թ
- - OTUS
- - Հայացք տվյալների և վերլուծությունների ապագայի վրա
- — Վերլուծության էվոլյուցիան և Open Source-ի ազդեցությունը
- — DBT-ի օգտագործմամբ CI կառուցելու սկզբունքները
- — Պրակտիկա, քայլ առ քայլ հրահանգներ անկախ աշխատանքի համար
- — Github, ուսումնական նախագծի կոդը
Source: www.habr.com
