

Բարև բոլորին, իմ անունը Ալեքսանդր է, ես աշխատում եմ CIAN-ում որպես ինժեներ և զբաղվում եմ համակարգերի կառավարմամբ և ենթակառուցվածքային գործընթացների ավտոմատացմամբ։ Մեր նախորդ հոդվածներից մեկի մեկնաբանություններում մեզ խնդրեցին պատմել, թե որտեղից ենք օրական ստանում 4 ՏԲ գրանցամատյան և ինչ ենք անում դրանցով։ Այո, մենք ունենք շատ գրանցամատյաններ, և դրանք մշակելու համար ստեղծվել է առանձին ենթակառուցվածքային կլաստեր, որը թույլ է տալիս մեզ արագ լուծել խնդիրները։ Այս հոդվածում ես ձեզ կպատմեմ, թե ինչպես ենք այն մեկ տարվա ընթացքում հարմարեցրել՝ անընդհատ աճող տվյալների հոսքի հետ աշխատելու համար։
Որտեղի՞ց սկսեցինք:
Վերջին մի քանի տարիների ընթացքում cian.ru կայքի ծանրաբեռնվածությունը շատ արագ է աճել, և 2018 թվականի երրորդ եռամսյակում ռեսուրսի այցելությունների թիվը հասել է ամսական 11.2 միլիոն եզակի օգտատիրոջ։ Այդ ժամանակ, կրիտիկական պահերին մենք կորցնում էինք գրանցամատյանների մինչև 40%-ը, այդ իսկ պատճառով չէինք կարողանում արագորեն հաղթահարել միջադեպերը և շատ ժամանակ ու ջանքեր էինք ծախսում դրանք լուծելու վրա։ Մենք նաև հաճախ չէինք կարողանում գտնել խնդրի պատճառը, և այն որոշ ժամանակ անց կրկին ի հայտ էր գալիս։ Դա դժոխք էր, որի հետ պետք էր գլուխ հանել։
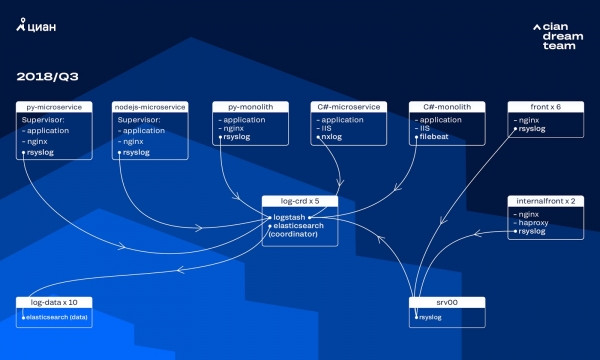
Այդ ժամանակ մենք օգտագործում էինք 10 տվյալների հանգույցներից բաղկացած կլաստեր՝ ElasticSearch 5.5.2 տարբերակով և ստանդարտ ինդեքսի կարգավորումներով՝ գրանցամատյանները պահելու համար։ Այն ներդրվել է ավելի քան մեկ տարի առաջ որպես հանրաճանաչ և մատչելի լուծում. այն ժամանակ գրանցամատյանների հոսքը այդքան էլ մեծ չէր, և իմաստ չկար ոչ ստանդարտ կոնֆիգուրացիաներ մտածել։
Մուտքային գրանցամատյանների մշակումը ապահովվել է Logstash-ի կողմից՝ հինգ ElasticSearch համակարգողների տարբեր պորտերի վրա։ Մեկ ինդեքսը, անկախ չափից, բաղկացած էր հինգ բեկորներից։ Կազմակերպվեց ժամային և օրական ռոտացիա, որի արդյունքում ամեն ժամ կլաստերում հայտնվում էր մոտ 100 նոր բեկոր։ Չնայած շատ գրանցամատյաններ չկային, կլաստերը հաղթահարեց խնդիրը, և ոչ ոք չկենտրոնացավ դրա կարգավորումների վրա։
Արագ աճի խնդիրներ
Ստեղծված գրանցամատյանների ծավալը շատ արագ աճեց, քանի որ երկու գործընթացներ համընկնում էին միմյանց հետ։ Մի կողմից, ծառայությունը ավելի ու ավելի շատ օգտատերեր էր ձեռք բերում։ Մյուս կողմից, մենք սկսեցինք ակտիվորեն անցնել միկրոսերվիսային ճարտարապետության՝ սղոցելով մեր հին մոնոլիտները C#-ում և Python-ում։ Մոնոլիտի մասերը փոխարինող մի քանի տասնյակ նոր միկրոսերվիսներ զգալիորեն ավելի շատ գրանցամատյաններ ստեղծեցին ենթակառուցվածքային կլաստերի համար։
Հենց մասշտաբավորումն էր, որ հանգեցրեց նրան, որ կլաստերը դարձավ գործնականում անկառավարելի։ Երբ գրանցամատյանները սկսեցին ստանալ վայրկյանում 20 հաղորդագրություն, հաճախակի անօգուտ պտույտները բեկորների քանակը հասցրին 6-ի, և յուրաքանչյուր հանգույցում կար ավելի քան 600 բեկոր։
Սա հանգեցրեց RAM-ի բաշխման հետ կապված խնդիրների, և երբ որևէ հանգույց խափանվում էր, բոլոր բեկորները միաժամանակ տեղափոխվում էին՝ մեծացնելով երթևեկությունը և բեռնելով մնացած հանգույցները, ինչը գործնականում անհնար էր դարձնում տվյալների կլաստերում գրառումը։ Եվ այս ընթացքում մենք մնացինք առանց գրանցամատյանների։ Եվ եթե խնդիր կար սերվեր Մենք կորցնում էինք կլաստերի ընդհանուր թվի 1/10-ը։ Փոքր ինդեքսների մեծ թիվը բարդացնում էր իրավիճակը։
Առանց գրանցամատյանների մենք չէինք հասկանում միջադեպի պատճառները և կարող էինք վաղ թե ուշ նորից նույն փոցխի վրա կանգնել, և մեր թիմի գաղափարախոսության մեջ դա անընդունելի էր, քանի որ մեր բոլոր աշխատանքային մեխանիզմները նախատեսված են հակառակը անելու համար՝ երբեք չկրկնել նույն խնդիրները։ Դրա համար մեզ անհրաժեշտ էր գրանցամատյանների ամբողջ ծավալը և դրանց առաքումը գրեթե իրական ժամանակում, քանի որ հերթապահ ինժեներների թիմը վերահսկում էր ոչ միայն չափանիշներից, այլև գրանցամատյաններից ստացված ահազանգերը։ Խնդրի մասշտաբները հասկանալու համար, այդ ժամանակ գրանցամատյանների ընդհանուր ծավալը կազմում էր օրական մոտ 2 ՏԲ։
Մենք նպատակ դրեցինք ամբողջությամբ վերացնել գրանցամատյանների կորուստը և անհաղթահարելի ուժի դեպքում ELK կլաստերին դրանց առաքման ժամանակը կրճատել մինչև առավելագույնը 15 րոպե (հետագայում մենք այս ցուցանիշին հիմնվեցինք որպես ներքին KPI):
Նոր պտտման մեխանիզմ և տաք-տաք հանգույցներ
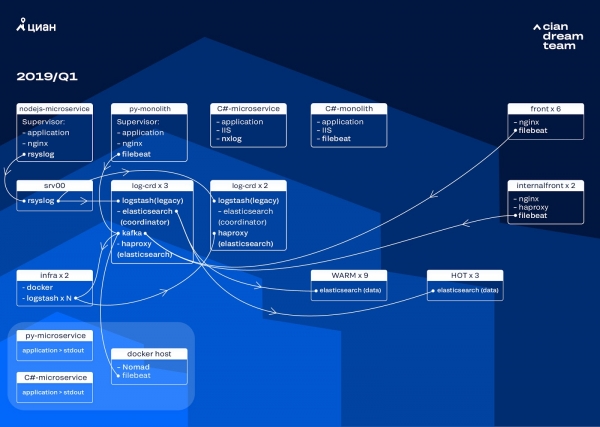
Մենք սկսեցինք կլաստերի փոխակերպումը՝ ElasticSearch տարբերակը 5.5.2-ից բարձրացնելով 6.4.3-ի։ Մեր 5-րդ տարբերակի կլաստերը կրկին խափանվեց, և մենք որոշեցինք այն անջատել և ամբողջությամբ թարմացնել. միևնույն է, ոչ մի գրանցամատյան չկային։ Այսպիսով, մենք այս անցումն ավարտեցինք ընդամենը մի քանի ժամվա ընթացքում։
Այս փուլում ամենակարևոր փոխակերպումը Apache Kafka-ի ներդրումն էր երեք հանգույցների վրա՝ որպես միջանկյալ բուֆեր համակարգողով։ Հաղորդագրությունների բրոքերը մեզ փրկեց ElasticSearch-ի հետ կապված խնդիրների ժամանակ գրանցամատյանների կորստից։ Միաժամանակ, մենք կլաստերին ավելացրինք 2 հանգույց և անցանք տաք-տաք ճարտարապետության՝ տվյալների կենտրոնի տարբեր դարակներում տեղադրված երեք «տաք» հանգույցներով։ Մենք գրանցամատյանները վերահղեցինք դրանց՝ օգտագործելով դիմակ, որը ոչ մի դեպքում չպետք է կորչի՝ nginx, ինչպես նաև ծրագրի սխալների գրանցամատյանները։ Աննշան գրանցամատյանները՝ վրիպազերծումը, նախազգուշացումը և այլն, ուղարկվել են մնացած հանգույցներին, իսկ 24 ժամ անց «կարևոր» գրանցամատյանները տեղափոխվել են «տաք» հանգույցներից։
Փոքր ինդեքսների թվի ավելացումից խուսափելու համար մենք ժամանակի վրա հիմնված ռոտացիայից անցանք rollover մեխանիզմի։ Ֆորումներում շատ տեղեկություններ կար այն մասին, որ ինդեքսի չափի ռոտացիան շատ անվստահելի է, ուստի մենք որոշեցինք օգտագործել ինդեքսում փաստաթղթերի քանակի ռոտացիան։ Մենք վերլուծեցինք յուրաքանչյուր ինդեքս և գրանցեցինք փաստաթղթերի քանակը, որից հետո պետք է ակտիվացվի ռոտացիան։ Այսպիսով, մենք հասել ենք բեկորի օպտիմալ չափի՝ ոչ ավելի, քան 50 ԳԲ:
Կլաստերի օպտիմալացում
Սակայն մենք լիովին չազատվեցինք խնդիրներից։ Դժբախտաբար, փոքր ինդեքսները դեռ ի հայտ եկան. դրանք չէին հասնում նշված ծավալին, չէին պտտվում և հեռացվում էին երեք օրից ավելի հին ինդեքսների գլոբալ մաքրման միջոցով, քանի որ մենք հեռացրինք ամսաթվով ռոտացիան։ Սա հանգեցրեց տվյալների կորստի՝ ինդեքսի կլաստերից ամբողջությամբ անհետացման պատճառով, իսկ գոյություն չունեցող ինդեքսում գրելու փորձը խախտեց կառավարման համար օգտագործվող կուրատորի տրամաբանությունը։ Ձայնագրման համար նախատեսված կեղծանունը վերածվեց ինդեքսի և խախտեց rollover տրամաբանությունը, ինչի հետևանքով որոշ ինդեքսներ անվերահսկելիորեն աճեցին մինչև 600 ԳԲ։
Օրինակ, ռոտացիայի կարգավորման համար՝
сurator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
Եթե rollover կեղծանունը բացակայում էր, տեղի էր ունենում հետևյալ սխալը՝
ERROR alias "nginx_write" not found.
ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Այս խնդրի լուծումը մենք թողեցինք հաջորդ իտերացիայի համար և կենտրոնացանք մեկ այլ հարցի վրա. մենք անցանք Logstash-ի pull տրամաբանությանը, որը մշակում է մուտքային գրանցամատյանները (հեռացնելով ավելորդ տեղեկատվությունը և հարստացնելով դրանք): Մենք այն տեղադրեցինք docker-ում, որը գործարկում ենք docker-compose-ի միջոցով, ինչպես նաև այնտեղ տեղադրեցինք logstash-exporter-ը, որը չափանիշներ է ուղարկում Prometheus-ին՝ log հոսքի գործառնական մոնիթորինգի համար։ Սա մեզ հնարավորություն տվեց սահուն կերպով փոխել logstash ինստանսների քանակը, որոնք պատասխանատու են յուրաքանչյուր տեսակի գրանցամատյանի մշակման համար։
Մինչ մենք կատարելագործում էինք կլաստերը, cian.ru կայքի այցելությունների թիվն աճեց՝ հասնելով ամսական 12,8 միլիոն եզակի օգտատիրոջ։ Արդյունքում պարզվեց, որ մեր վերափոխումները մի փոքր հետ էին մնում արտադրության փոփոխություններից, և մենք բախվեցինք այն փաստին, որ «տաք» հանգույցները չկարողացան հաղթահարել բեռը և դանդաղեցրին գերանների ամբողջ մատակարարումը: Մենք «տաք» տվյալներ էինք ստանում առանց ընդհատումների, բայց մնացածի համար ստիպված էինք միջամտել և ձեռքով փոխանցել տվյալները՝ ինդեքսները հավասարաչափ բաշխելու համար։
Միևնույն ժամանակ, կլաստերում logstash ինստանսների մասշտաբավորումը և կարգավորումների փոփոխությունը բարդանում էր նրանով, որ այն տեղական docker-compose էր, և բոլոր գործողությունները կատարվում էին ձեռքով (նոր ծայրեր ավելացնելու համար անհրաժեշտ էր ձեռքով անցնել բոլոր սերվերների միջով և ամենուրեք կատարել docker-compose up -d հրամանը):
Գրանցամատյանի վերաբաշխում
Այս տարվա սեպտեմբերին մենք դեռ սղոցում էինք մոնոլիտը, կլաստերի վրա ծանրաբեռնվածությունը մեծանում էր, իսկ գրանցամատյանների հոսքը մոտենում էր վայրկյանում 30 հազար հաղորդագրության։
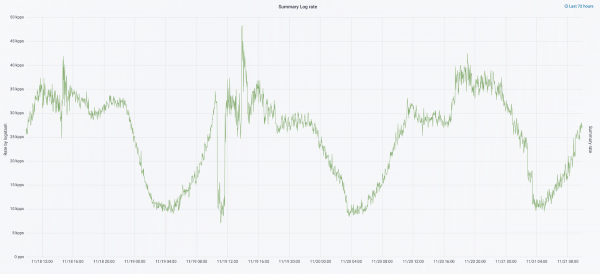
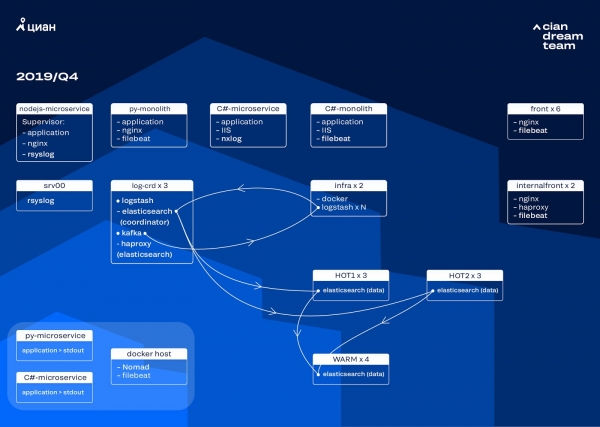
Մենք հաջորդ տարբերակը սկսեցինք սարքային թարմացմամբ։ Մենք հինգ համակարգողներից անցանք երեքի, փոխարինեցինք տվյալների հանգույցները և հաղթեցինք գումարի և պահեստային տարածքի առումով։ Հանգույցների համար մենք օգտագործում ենք երկու կոնֆիգուրացիա՝
- «Տաք» հանգույցների համար՝ E3-1270 v6 / 960Gb SSD / 32 Gb x 3 x 2 (3-ը Hot1-ի և 3-ը Hot2-ի համար):
- «Տաք» հանգույցների համար՝ E3-1230 v6 / 4Tb SSD / 32 Gb x 4:
Այս իտերացիայում մենք միկրոսերվիսների մուտքի գրանցամատյաններով ինդեքսը, որը զբաղեցնում է նույնքան տարածք, որքան nginx-ի առջևի գրանցամատյանները, տեղափոխեցինք երեք «տաք» հանգույցների երկրորդ խումբ։ Այժմ մենք տվյալները պահում ենք «տաք» հանգույցների վրա 20 ժամ, ապա փոխանցում ենք դրանք «տաք» հանգույցներին՝ մնացած գրանցամատյաններում։
Մենք լուծեցինք փոքր ինդեքսների անհետացման խնդիրը՝ վերակազմավորելով դրանց պտույտը։ Այժմ ինդեքսները փոխվում են յուրաքանչյուր 23 ժամը մեկ, նույնիսկ եթե այնտեղ քիչ տվյալներ կան։ Սա փոքր-ինչ մեծացրեց բեկորների քանակը (այժմ դրանցից մոտ 800-ը կա), բայց կլաստերի աշխատանքի տեսանկյունից սա տանելի է։
Արդյունքում, կլաստերն ուներ վեց «տաք» և միայն չորս «տաք» հանգույց։ Սա երկար ժամանակահատվածներում հարցումների փոքր ուշացում է առաջացնում, բայց ապագայում հանգույցների թվի ավելացումը կլուծի այս խնդիրը։
Այս տարբերակը նաև լուծեց կիսաավտոմատ մասշտաբավորման բացակայության խնդիրը։ Դա անելու համար մենք տեղակայեցինք ենթակառուցվածքային Nomad կլաստեր, նման այն կլաստերին, որն արդեն տեղակայել ենք արտադրության մեջ։ Առայժմ Logstash-ի քանակը ավտոմատ կերպով չի փոխվում՝ կախված բեռից, բայց դրան կանդրադառնանք։
Պլանները ապագայի համար
Ներդրված կոնֆիգուրացիան լավ է մասշտաբավորվում, և այժմ մենք պահպանում ենք 13,3 ՏԲ տվյալներ՝ բոլոր գրանցամատյանները 4 օրվա ընթացքում, ինչը անհրաժեշտ է ահազանգերի արտակարգ վերլուծության համար։ Մենք որոշ գրանցամատյաններ վերածում ենք մետրիկների, որոնք պահում ենք Graphite-ում։ Ինժեներների աշխատանքը հեշտացնելու համար մենք ունենք ենթակառուցվածքների կլաստերի համար չափանիշներ և սկրիպտներ տարածված խնդիրների կիսաավտոմատ վերանորոգման համար։ Տվյալների հանգույցների թվի ավելացումից հետո, որը նախատեսված է հաջորդ տարի, մենք կանցնենք տվյալների պահպանման 4 օրվաց մինչև 7 օր։ Սա բավարար կլինի օպերատիվ աշխատանքների համար, քանի որ մենք միշտ ձգտում ենք միջադեպերը հետաքննել որքան հնարավոր է արագ, իսկ երկարաժամկետ հետաքննությունների համար կան հեռաչափման տվյալներ։
2019 թվականի հոկտեմբերին cian.ru կայքի այցելությունների թիվը ամսական աճել է մինչև 15,3 միլիոն եզակի օգտատեր։ Սա գերանների մատակարարման ճարտարապետական լուծման լուրջ փորձություն էր։
Մենք ներկայումս պատրաստվում ենք ElasticSearch-ը թարմացնել մինչև 7-րդ տարբերակը։ Սակայն դա կպահանջի ElasticSearch-ում շատ ինդեքսների քարտեզագրման թարմացում, քանի որ դրանք տեղափոխվել են 5.5 տարբերակից և 6-րդ տարբերակում հայտարարվել են հնացած (դրանք պարզապես գոյություն չունեն 7-րդ տարբերակում)։ Սա նշանակում է, որ թարմացման գործընթացի ընթացքում անպայման կլինի որոշակի անհաղթահարելի ուժ, որի պատճառով մենք կզրկվենք գրանցամատյաններից, մինչ խնդիրը լուծվում է։ 7-րդ տարբերակից մենք ամենաշատը սպասում ենք Kibana-ին՝ իր բարելավված ինտերֆեյսով և նոր ֆիլտրերով։
Մենք հասանք գլխավոր նպատակին. դադարեցինք գրանցամատյանների կորուստը և ենթակառուցվածքների կլաստերի անգործունեության ժամանակը կրճատեցինք շաբաթական 2-3 վթարից մինչև ամսական մի քանի ժամ սպասարկման աշխատանքներ։ Այս ամբողջ աշխատանքը գրեթե անտեսանելի է արտադրության մեջ։ Այնուամենայնիվ, հիմա մենք կարող ենք ճշգրիտ որոշել, թե ինչ է կատարվում մեր ծառայության հետ, կարող ենք դա անել արագ՝ հանգիստ ռեժիմով և չանհանգստանալ գրանցամատյանների կորստի մասին։ Ընդհանուր առմամբ, մենք գոհ ենք, ուրախ և պատրաստվում ենք նոր սխրանքների, որոնց մասին ձեզ կպատմենք ավելի ուշ։
Source: www.habr.com
