

Ես կցանկանայի ձեզ հետ կիսվել Postgres տվյալների բազայի լիարժեք ֆունկցիոնալությունը վերականգնելու իմ առաջին հաջող փորձով։ Ես Postgres տվյալների բազայի կառավարման հետ ծանոթացա կես տարի առաջ, մինչ այդ ես ընդհանրապես չունեի տվյալների բազայի կառավարման փորձ։

Ես աշխատում եմ որպես կիսա-DevOps ինժեներ խոշոր IT ընկերությունում: Մեր ընկերությունը մշակում է բարձր ծանրաբեռնվածության ծառայությունների համար նախատեսված ծրագրային ապահովում, և ես պատասխանատու եմ աշխատանքի, սպասարկման և տեղակայման համար: Ինձ տրվել է ստանդարտ առաջադրանք՝ թարմացնել մեկ սերվերի վրա գտնվող ծրագիրը: Ծրագիրը գրված է Django լեզվով, միգրացիաները կատարվում են թարմացման ընթացքում (տվյալների բազայի կառուցվածքի փոփոխություններ), և այս գործընթացից առաջ մենք վերցնում ենք տվյալների բազայի ամբողջական դամփ՝ օգտագործելով ստանդարտ pg_dump ծրագիրը՝ ամեն դեպքում:
Անսպասելի սխալ տեղի ունեցավ դատարկման ժամանակ (Postgres տարբերակ 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [...]
pg_dunp: [parallel archtver] a worker process dled unexpectedly Սխալ "բլոկում անվավեր էջ է" խոսում է ֆայլային համակարգի մակարդակի խնդիրների մասին, ինչը շատ վատ է: Տարբեր ֆորումներում առաջարկվում է անել ԼԻԱՐԺԵՔ ՎԱԿՈՒՈՒՄ տարբերակով zero_damaged_pages այս խնդիրը լուծելու համար։ Դե, պոպրոբեում…
Պատրաստվելով վերականգնմանը
Նախազգուշացում Համոզվեք, որ պահուստավորել եք Postgres-ը, նախքան տվյալների բազան վերականգնելու փորձ կատարելը: Եթե ունեք վիրտուալ մեքենա, կանգնեցրեք տվյալների բազան և արեք սքենթ: Եթե չեք կարողանում սքենթ անել, կանգնեցրեք տվյալների բազան և պատճենեք Postgres պանակի պարունակությունը (ներառյալ wal ֆայլերը) անվտանգ տեղ: Մեր գործում գլխավորը իրավիճակը չվատացնելն է: Կարդացեք: .
Քանի որ իմ տվյալների բազան ընդհանուր առմամբ աշխատում էր, ես սահմանափակվեցի սովորական տվյալների բազայի աղբարկղով, բայց բացառեցի վնասված տվյալներով աղյուսակը (տարբերակ -T, --բացառել-աղյուսակը=ԱՂՅՈՒՍԱԿ pg_dump-ում):
Սերվերը ֆիզիկական էր, անհնար էր լուսանկար անել։ Պահուստային պատճենը արված է, անցնենք առաջ։
Ֆայլային համակարգի ստուգում
Մինչև տվյալների բազան վերականգնելու փորձը, մենք պետք է համոզվենք, որ ֆայլային համակարգի հետ ամեն ինչ կարգին է։ Եվ եթե կան որևէ սխալներ, մենք պետք է դրանք շտկենք, քանի որ հակառակ դեպքում մենք կարող ենք միայն վատթարացնել իրավիճակը։
Իմ դեպքում, տվյալների բազայի ֆայլային համակարգը տեղադրվել է "/srv" և տեսակը ext4 էր։
Դադարեցրեք տվյալների բազան. systemctl-ը դադարեցնում է postgresql@9.5-main.service-ը և ստուգեք, որ ֆայլային համակարգը չի օգտագործվում ոչ մեկի կողմից և կարող է ապամոնտաժվել հրամանի միջոցով lsof:
lsof +D /srv
Ես նաև ստիպված էի կանգնեցնել redis տվյալների բազան, քանի որ այն նույնպես օգտագործում էր "/srv". Ապա ես իջա / սվվ (անջատել):
Ֆայլային համակարգի ստուգումը կատարվել է կոմունալ ծրագրի միջոցով e2fsck -f ստեղնով (Հարկադիր ստուգում, նույնիսկ եթե ֆայլային համակարգը նշված է մաքուր):
Հաջորդը, օգտագործելով կոմունալը dumpe2fs (sudo dumpe2fs /dev/mapper/gu2—sys-srv | grep-ը ստուգված է) կարող եք ստուգել, որ ստուգումն իրականում կատարվել է.

e2fsck ասում է, որ ext4 ֆայլային համակարգի մակարդակում խնդիրներ չեն հայտնաբերվել, ինչը նշանակում է, որ դուք կարող եք շարունակել փորձել վերականգնել տվյալների բազան, կամ ավելի ճիշտ՝ վերադառնալ վակուում լիքը (իհարկե, դուք պետք է նորից միացնեք ֆայլային համակարգը և գործարկեք տվյալների բազան):
Եթե ունեք ֆիզիկական սերվեր, անպայման ստուգեք սկավառակների կարգավիճակը (միջոցով) smartctl -a /dev/XXX) կամ RAID կառավարիչ՝ համոզվելու համար, որ խնդիրը սարքային մակարդակում չէ։ Իմ դեպքում RAID-ը «ապարատային» էր, ուստի ես խնդրեցի տեղական ադմինիստրատորին ստուգել RAID կարգավիճակը (սերվերը ինձանից մի քանի հարյուր կիլոմետր հեռավորության վրա էր)։ Նա ասաց, որ սխալներ չկան, ինչը նշանակում է, որ մենք անպայման կարող ենք սկսել վերականգնումը։
Փորձ 1՝ զրո_վնասված_էջեր
Մենք միանում ենք տվյալների բազային psql-ի միջոցով՝ օգտագործելով սուպերօգտատիրոջ իրավունքներ ունեցող հաշիվ։ Մեզ անհրաժեշտ է սուպերօգտատեր, քանի որ տարբերակը zero_damaged_pages Միայն նա կարող է փոխել այն։ Իմ դեպքում դա postgres-ն է։
psql -h 127.0.0.1 -U postgres -s [տվյալների բազայի_անուն]
Տարբերակ zero_damaged_pages անհրաժեշտ էր անտեսել ընթերցման սխալները (postgrespro կայքից):
Երբ հայտնաբերվում է վնասված էջի վերնագիր, PostgreSQL-ը սովորաբար հաղորդում է սխալի մասին և դադարեցնում է ընթացիկ գործարքը: Եթե zero_damaged_pages-ը միացված է, համակարգը փոխարենը տալիս է նախազգուշացում, զրոյացնում է վնասված էջը հիշողության մեջ և շարունակում է մշակումը: Այս վարքագիծը ոչնչացնում է տվյալները, մասնավորապես՝ վնասված էջի բոլոր տողերը:
Մենք միացնում ենք տարբերակը և փորձում ենք սեղանը լրիվ վակուումով մաքրել։
VACUUM FULL VERBOSE 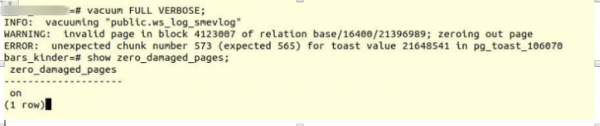
Դժբախտաբար, ձախողում։
Մենք նմանատիպ սխալի հանդիպեցինք՝
INFO: vacuuming "“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070– Poetgres-ում «երկար տվյալներ» պահելու մեխանիզմ, եթե դրանք չեն տեղավորվում մեկ էջում (նախնական չափը՝ 8 կբ):
Փորձ 2. վերինդեքսավորում
Google-ի առաջին խորհուրդը չօգնեց։ Մի քանի րոպե որոնումներից հետո գտա երկրորդ խորհուրդը՝ անել վերստին ինդեքսավորում վնասված սեղան։ Ես այս խորհուրդը տեսել եմ շատ տեղերում, բայց այն վստահություն չի ներշնչել։ Եկեք վերաինդեքսավորենք։
reindex table ws_log_smevlog 
վերստին ինդեքսավորում ավարտվել է առանց որևէ խնդրի։
Սակայն, դա չօգնեց, ՎԱԿՈՒՈՒՄԸ ԼՐԱՑՎԱԾ է նմանատիպ սխալով վթարի ենթարկվեցի։ Քանի որ ես սովոր եմ ձախողումներին, սկսեցի ավելի շատ խորհուրդներ փնտրել ինտերնետում և հանդիպեցի բավականին հետաքրքիր մի բանի .
Փորձ 3. ԸՆՏՐԵԼ, ՍԱՀՄԱՆԵԼ, ՇԵՂԵԼ
Վերոնշյալ հոդվածում առաջարկվում էր տող առ տող նայել աղյուսակին և ջնջել խնդրահարույց տվյալները։ Նախ անհրաժեշտ էր նայել բոլոր տողերին։
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; doneԻմ դեպքում աղյուսակը պարունակում էր 1 628 991 գծեր։ Անհրաժեշտ էր հոգ տանել , բայց դա արդեն այլ քննարկման թեմա է։ Շաբաթ օր էր, ես tmux-ում կատարեցի այս հրամանը և գնացի քնելու։
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; doneԱռավոտյան որոշեցի ստուգել, թե ինչպես են գործերը ընթանում։ Ի զարմանս ինձ, պարզվեց, որ 20 ժամվա ընթացքում տվյալների միայն 2%-ն էր սկանավորվել։ Ես չէի ուզում 50 օր սպասել։ Եվս մեկ լիակատար ձախողում։
Բայց ես չհանձնվեցի։ Ես զարմանում էի, թե ինչու է սկանավորումն այդքան երկար տևում։ Փաստաթղթերից (կրկին postgrespro-ում) ես իմացա.
OFFSET ֆունկցիան հրահանգում է այն բաց թողնել տողերի նշված քանակը՝ տողեր արտածելը սկսելուց առաջ։
Եթե նշված են և՛ OFFSET-ը, և՛ LIMIT-ը, համակարգը նախ բաց է թողնում OFFSET տողերը, ապա սկսում է հաշվել LIMIT-ի տողերը։LIMIT-ն օգտագործելիս կարևոր է նաև օգտագործել ORDER BY կետը՝ ապահովելու համար, որ արդյունքի տողերը վերադարձվեն որոշակի հերթականությամբ: Հակառակ դեպքում, կվերադարձվեն տողերի անկանխատեսելի ենթաբազմություններ:
Ակնհայտ է, որ վերը նշված հրամանը սխալ էր. նախ, չկար պատվիրել ըստ, արդյունքը կարող է սխալ լինել։ Երկրորդ, Postgres-ը նախ պետք է սկանավորեր և բաց թողներ OFFSET տողերը, և աճող OFFSET արտադրողականությունն էլ ավելի կնվազեր։
Փորձ 4. Վերցրեք դամփ տեքստային տեսքով
Ապա ինձ մոտ ծագեց մի թվացյալ հանճարեղ միտք՝ վերցնել տեքստային ֆայլ և վերլուծել վերջին ձայնագրված տողը։
Բայց նախ, եկեք ծանոթանանք աղյուսակի կառուցվածքին։ ws_log_smevlog:
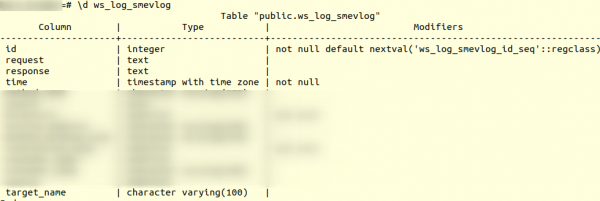
Մեր դեպքում մենք ունենք սյունակ "Id", որը պարունակում էր տողի համար եզակի նույնականացուցիչ (հաշվիչ): Պլանը հետևյալն էր՝
- Մենք սկսում ենք տեքստային տեսքով դամփ վերցնել (SQL հրամանների տեսքով):
- Որոշակի պահի, ֆայլի արտածումը կընդհատվեր սխալի պատճառով, բայց տեքստային ֆայլը կպահպանվեր սկավառակի վրա։
- Մենք նայում ենք տեքստային ֆայլի վերջում, այդպիսով գտնում ենք վերջին տողի նույնականացուցիչը (id), որը հաջողությամբ հեռացվել է։
Ես սկսեցի տեքստային տեսքով ներկայացնել.
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dumpԻնչպես և սպասվում էր, աղբարկղը ընդհատվեց նույն սխալով.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 Ավելի հեռու պոչ Ես նայեցի աղբանոցից այն կողմ (պոչ -5 ./my_dump.dump) պարզվեց, որ աղբահանությունը ընդհատվել է id-ով գծում 186 525«Այսպիսով, խնդիրը 186 526 id տողում է, այն կոտրված է և պետք է ջնջվի», - մտածեցի ես։ Բայց տվյալների բազային հարցում կատարելով՝
«ընտրեք * ws_log_smevlog-ից, որտեղ id=186529 է«Պարզվեց, որ այս տողի հետ ամեն ինչ կարգին էր... 186 530 - 186 540 ինդեքսներով տողերը նույնպես առանց խնդիրների աշխատեցին։ Մեկ այլ «հանճարեղ գաղափար» ձախողվեց։ Հետագայում ես հասկացա, թե ինչու է դա տեղի ունենում. աղյուսակից տվյալները ջնջելիս/փոփոխելիս դրանք ֆիզիկապես չեն ջնջվում, այլ նշվում են որպես «մեռած զույգեր», ապա գալիս է ավտովակուում և նշում է այս տողերը որպես ջնջված և թույլ է տալիս վերօգտագործել դրանք։ Հասկանալու համար, եթե աղյուսակի տվյալները փոխվում են և ավտոմատ վակուումը միացված է, ապա դրանք հաջորդաբար չեն պահվում։
Փորձ 5։ SELECT, FROM, WHERE id=
Անհաջողությունները մեզ ավելի ուժեղ են դարձնում։ Դուք երբեք չպետք է հանձնվեք, դուք պետք է գնաք մինչև վերջ և հավատաք ինքներդ ձեզ և ձեր կարողություններին։ Այսպիսով, ես որոշեցի փորձել մեկ այլ տարբերակ. պարզապես մեկ առ մեկ զննեք տվյալների բազայի բոլոր գրառումները։ Իմանալով իմ աղյուսակի կառուցվածքը (տե՛ս վերևում), մենք ունենք id դաշտ, որը եզակի է (հիմնական բանալին)։ Աղյուսակում մենք ունենք 1 տող և id դասավորված են, ինչը նշանակում է, որ մենք կարող ենք պարզապես մեկ առ մեկ անցնել դրանց միջով՝
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneԵթե որևէ մեկը չի հասկանում, հրամանը գործում է հետևյալ կերպ. այն սկանավորում է աղյուսակը տող առ տող և ուղարկում է stdout-ը / dev / null, բայց եթե SELECT հրամանը ձախողվի, ապա տպագրվում է սխալի տեքստը (stderr-ը ուղարկվում է կոնսոլ) և տպագրվում է սխալը պարունակող տողը (շնորհիվ ||-ի, ինչը նշանակում է, որ select-ը խնդիրներ ուներ (հրամանի վերադարձի կոդը 0 չէ)):
Ես բախտավոր էի, դաշտում ինդեքսներ էի ստեղծել id:

Սա նշանակում է, որ անհրաժեշտ id-ով տող գտնելը շատ ժամանակ չպետք է պահանջի։ Տեսականորեն, այն պետք է աշխատի։ Լավ, եկեք հրամանը գործարկենք tmux և եկեք գնանք քնելու։
Առավոտյան ես պարզեցի, որ դիտվել էր մոտ 90 գրառում, ինչը մի փոքր ավելի քան 000% է։ Գերազանց արդյունք՝ համեմատած նախորդ մեթոդի հետ (5%)։ Բայց ես չէի ուզում 2 օր սպասել...
Փորձ 6։ SELECT, FROM, WHERE id >= և id
Հաճախորդը տվյալների բազայի համար հատկացրել էր գերազանց սերվեր՝ երկպրոցեսորային Intel Xeon E5-2697 v2, մենք մեր տրամադրության տակ ունեինք մինչև 48 թել։ Սերվերի ծանրաբեռնվածությունը միջին էր, մենք կարող էինք հեշտությամբ ընդունել մոտ 20 թել։ Կար նաև բավարար օպերատիվ հիշողություն՝ մինչև 384 գիգաբայթ։
Հետևաբար, հրամանը պետք է զուգահեռացվեր.
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneԱյստեղ հնարավոր կլիներ գրել գեղեցիկ և նրբագեղ սկրիպտ, բայց ես ընտրեցի զուգահեռացման ամենաարագ ճանապարհը՝ ձեռքով բաժանել 0-1628991 միջակայքը 100 գրառումների միջակայքերի և առանձին-առանձին կատարել հետևյալ տիպի 000 հրամաններ՝
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneԲայց սա դեռ ամենը չէ։ Տեսականորեն, տվյալների բազային միանալը նույնպես պահանջում է որոշ ժամանակ և համակարգային ռեսուրսներ։ 1 միացնելը շատ խելացի չէր, կհամաձայնեք։ Այսպիսով, եկեք մեկ կապով մեկի փոխարեն արդյունահանենք 628 տող։ Արդյունքում, հրամանը վերափոխվեց հետևյալի՝
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; doneԲացեք 16 պատուհան tmux սեսիայի ընթացքում և գործարկեք հետևյալ հրամանները.
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Մեկ օր անց ես ստացա առաջին արդյունքները։ Մասնավորապես (XXX և ZZZ արժեքները այլևս չեն պահպանվել).
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000Սա նշանակում է, որ մենք ունենք սխալով երեք տող։ Առաջին և երկրորդ խնդրահարույց գրառումների id-ները 829-ից 000 միջակայքում էին, երրորդի id-ն՝ 830-ից 000 միջակայքում։ Հաջորդը, մենք պարզապես պետք է գտնեինք խնդրահարույց գրառումների id-ի ճշգրիտ արժեքը։ Դա անելու համար մենք զննում ենք մեր խնդրահարույց գրառումներով մեր միջակայքը՝ 146 քայլով և նույնականացնում id-ն։
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
Լավ ավարտ
Մենք գտանք խնդրահարույց տողերը։ Մենք մտանք տվյալների բազա psql-ի միջոցով և փորձեցինք ջնջել դրանք։
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1Իմ զարմանքին, գրառումները ջնջվեցին առանց որևէ խնդրի, նույնիսկ առանց այդ տարբերակի zero_damaged_pages.
Այնուհետև ես միացա տվյալների բազային, ՎԱԿՈՒՈՒՄԸ ԼՐԱՑՎԱԾ է (Կարծում եմ՝ դա անհրաժեշտ չէր անել), և վերջապես հաջողությամբ պահուստային պատճենահանում արեցի՝ օգտագործելով pg_dump։ Աղբարկղը վերցվեց առանց որևէ սխալի։ Խնդիրը լուծվեց այնքան հիմար ձևով։ Ուրախությանը սահման չկար, այդքան շատ անհաջողություններից հետո լուծումը գտնվեց։
Շնորհակալություններ և եզրակացություն
Սա Postgres-ի իրական տվյալների բազայի վերականգնման իմ առաջին փորձն էր։ Ես այս փորձը երկար ժամանակ կհիշեմ։
Եվ վերջապես, ես կցանկանայի շնորհակալություն հայտնել PostgresPro ընկերությանը փաստաթղթերը ռուսերեն թարգմանելու և , որը շատ օգնեց խնդրի վերլուծության ընթացքում։
Source: www.habr.com
