

Մտածեք Kubernetes-ի մոնիտորինգի հայեցակարգը, ծանոթացեք Prometheus գործիքին և խոսեք ահազանգման մասին:
Մոնիտորինգի թեման ծավալուն է, այն չի կարելի ապամոնտաժել մեկ հոդվածում։ Այս տեքստի նպատակը գործիքների, հասկացությունների և մոտեցումների ընդհանուր պատկերացումն է:
Հոդվածի նյութը սեղմում է . Եթե ցանկանում եք մասնակցել ամբողջական դասընթացին, ապա գրանցվեք դասընթացի համար .

Ինչ է վերահսկվում Kubernetes կլաստերում
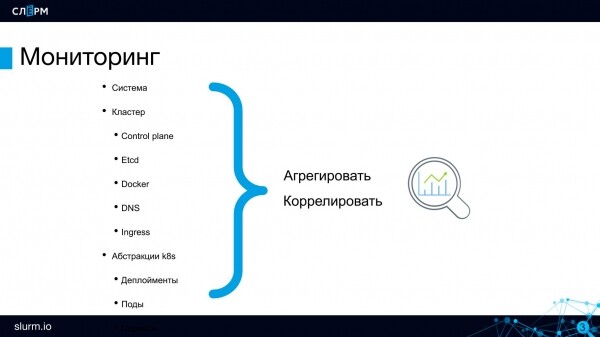
ֆիզիկական սերվերներ. Եթե Kubernetes կլաստերը տեղակայված է իր սերվերների վրա, դուք պետք է վերահսկեք նրանց առողջությունը: Zabbix-ը կատարում է այս խնդիրը. եթե նրա հետ աշխատեք, ուրեմն պետք չէ հրաժարվել, կոնֆլիկտներ չեն լինի։ Դա Zabbix-ն է, որը վերահսկում է մեր սերվերների վիճակը:
Անցնենք կլաստերի մակարդակով մոնիտորինգին:
Կառավարման ինքնաթիռի բաղադրիչներ. API, Scheduler և այլն: Առնվազն, դուք պետք է համոզվեք, որ սերվերների կամ etcd-ի API-ն 0-ից մեծ է: Etcd-ն կարող է վերադարձնել բազմաթիվ չափումներ՝ ըստ սկավառակների, որոնց վրա այն պտտվում է, իր etcd կլաստերի առողջությամբ և այլն:
դոկեր հայտնվել է շատ վաղուց, և բոլորը քաջատեղյակ են դրա խնդիրներին. շատ տարաներ առաջացնում են սառցակալումներ և այլ խնդիրներ։ Հետևաբար, ինքը՝ Docker-ը, որպես համակարգ, նույնպես պետք է վերահսկվի՝ գոնե հասանելիության համար։
DNS Եթե DNS-ն ընկնում է կլաստերում, ապա ամբողջ Discovery ծառայությունը կփլվի դրանից հետո, զանգերը pods-ից դեպի pods կդադարեն աշխատել: Իմ պրակտիկայում նման խնդիրներ չեն եղել, բայց դա չի նշանակում, որ DNS-ի վիճակը մոնիտորինգի կարիք չունի։ Հարցման հետաձգման և որոշ այլ չափումների կարող են հետևել CoreDNS-ում:
Ներխուժում. Անհրաժեշտ է վերահսկել մուտքերի առկայությունը (ներառյալ ներխուժման վերահսկիչը) որպես նախագծի մուտքի կետեր:
Կլաստերի հիմնական բաղադրիչները ապամոնտաժվել են՝ հիմա իջնենք վերացականության մակարդակին։
Թվում է, թե հավելվածները աշխատում են pods-ով, ինչը նշանակում է, որ դրանք պետք է վերահսկվեն, բայց իրականում դա այդպես չէ: Պոդները ժամանակավոր են. այսօր դրանք աշխատում են մի սերվերի վրա, վաղը մյուսի վրա; այսօր դրանք 10-ն են, վաղը՝ 2: Հետևաբար, ոչ ոք չի վերահսկում պատիճները: Միկրոծառայությունների ճարտարապետության շրջանակներում ավելի կարևոր է վերահսկել հավելվածի հասանելիությունը որպես ամբողջություն: Մասնավորապես, ստուգեք ծառայության վերջնակետերի առկայությունը. Եթե հավելվածը հասանելի է, ապա ի՞նչ է տեղի ունենում դրա հետևում, քանի՞ կրկնօրինակ կա հիմա՝ սրանք երկրորդ կարգի հարցեր են։ Առանձին ատյաններին վերահսկելու կարիք չկա։
Վերջին մակարդակում դուք պետք է վերահսկեք հենց հավելվածի աշխատանքը, ձեռնարկեք բիզնեսի չափումներ՝ պատվերների քանակը, օգտագործողի վարքագիծը և այլն:
Պրոմեթեւս
Կլաստերի մոնիտորինգի լավագույն համակարգն է . Ես չգիտեմ որևէ գործիք, որը կարող է համընկնել Պրոմեթևսի որակի և օգտագործման հեշտության հետ: Այն հիանալի է ճկուն ենթակառուցվածքի համար, ուստի երբ ասում են «Kubernetes monitoring», նրանք սովորաբար նկատի ունեն Պրոմեթևսը:
Prometheus-ի հետ սկսելու մի քանի տարբերակ կա. Helm-ի միջոցով կարող եք տեղադրել սովորական Prometheus կամ Prometheus օպերատոր:
- Սովորական Պրոմեթևս. Նրա հետ ամեն ինչ կարգին է, բայց դուք պետք է կարգավորեք ConfigMap-ը. իրականում գրեք տեքստի վրա հիմնված կազմաձևման ֆայլեր, ինչպես մենք արեցինք նախկինում, մինչև միկրոսերվիսային ճարտարապետությունը:
- Պրոմեթևս օպերատորը մի փոքր ավելի տարածված է, ներքին տրամաբանության առումով մի փոքր ավելի բարդ, բայց դրա հետ աշխատելն ավելի հեշտ է. կան առանձին օբյեկտներ, կլաստերին ավելացվում են աբստրակցիաներ, ուստի դրանք շատ ավելի հարմար են կառավարելու և կազմաձևելու համար:
Ապրանքը հասկանալու համար խորհուրդ եմ տալիս նախ տեղադրել սովորական Prometheus-ը: Դուք ստիպված կլինեք ամեն ինչ կարգավորել կոնֆիգուրացիայի միջոցով, բայց դա ձեռնտու կլինի. դուք կպարզեք, թե ինչին է պատկանում և ինչպես է այն կազմաձևված: Prometheus Operator-ում դուք անմիջապես բարձրանում եք աբստրակցիա ավելի բարձր, չնայած ցանկության դեպքում կարող եք նաև խորանալ խորքերը:
Պրոմեթևսը լավ ինտեգրված է Kubernetes-ի հետ. այն կարող է մուտք գործել և փոխազդել API սերվերի հետ:
Պրոմեթևսը հանրաճանաչ է, այդ իսկ պատճառով մեծ թվով հավելվածներ և ծրագրավորման լեզուներ աջակցում են դրան: Աջակցությունն անհրաժեշտ է, քանի որ Պրոմեթևսն ունի իր չափման ձևաչափը, և այն փոխանցելու համար անհրաժեշտ է կա՛մ հավելվածի ներսում գտնվող գրադարան, կա՛մ պատրաստի արտահանող։ Իսկ այդպիսի արտահանողները բավականին քիչ են։ Օրինակ, կա PostgreSQL Exporter. այն վերցնում է տվյալները PostgreSQL-ից և փոխակերպում Prometheus ձևաչափի, որպեսզի Պրոմեթևսը կարողանա աշխատել դրա հետ:
Պրոմեթևսի ճարտարապետություն
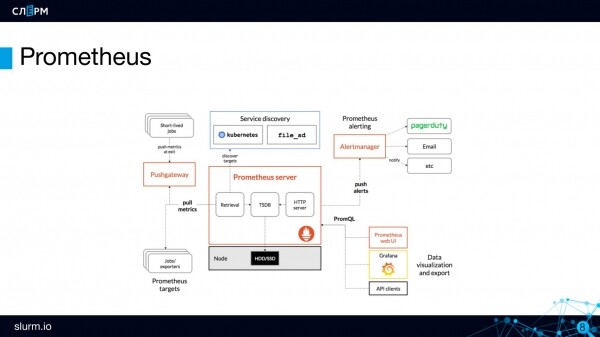
Պրոմեթևսի սերվեր հետին վերջն է՝ Պրոմեթևսի ուղեղը։ Չափիչները պահվում և մշակվում են այստեղ:
Չափիչները պահվում են ժամանակային շարքերի տվյալների բազայում (TSDB): TSDB-ն առանձին տվյալների բազա չէ, այլ Go լեզվով փաթեթ, որը ներդրված է Պրոմեթևսում: Կոպիտ ասած՝ ամեն ինչ մեկ երկուականի մեջ է։
Մի պահեք տվյալները TSDB-ում երկար ժամանակ
Պրոմեթևսի ենթակառուցվածքը հարմար չէ չափումների երկարաժամկետ պահպանման համար: Լռելյայն պահպանման ժամկետը 15 օր է: Դուք կարող եք գերազանցել այս սահմանը, բայց հիշեք. որքան շատ տվյալներ պահեք TSDB-ում և որքան երկար անեք դա, այնքան ավելի շատ ռեսուրսներ կծախսվեն: Պրոմեթևսում պատմական տվյալների պահպանումը համարվում է վատ պրակտիկա:
Եթե դուք ունեք հսկայական տրաֆիկ, չափումների թիվը վայրկյանում հարյուր հազարավոր է, ապա ավելի լավ է սահմանափակել դրանց պահպանումը սկավառակի տարածությամբ կամ ըստ ժամանակաշրջանի: Սովորաբար «թեժ տվյալները» պահվում են TSDB-ում, չափումները ընդամենը մի քանի ժամում: Ավելի երկար պահեստավորման համար արտաքին պահեստավորումն օգտագործվում է այն տվյալների բազաներում, որոնք իսկապես հարմար են դրա համար, օրինակ՝ InfluxDB, ClickHouse և այլն։ Ես տեսա ավելի լավ ակնարկներ ClickHouse-ի մասին:
Prometheus Server-ը աշխատում է մոդելի վրա քաշելՆա դիմում է չափումների այն վերջնակետերին, որոնք մենք տվել ենք նրան: Նրանք ասացին. «գնալ դեպի API սերվեր», և նա գնում է այնտեղ ամեն n-րդ վայրկյանը և վերցնում է չափումները:
Կարճ ժամկետ ունեցող օբյեկտների համար (աշխատանք կամ cron աշխատանք), որոնք կարող են հայտնվել քերման ժամանակաշրջանների միջև, կա Pushgateway բաղադրիչ: Կարճաժամկետ օբյեկտների չափումները դրվում են դրա մեջ. աշխատանքը բարձրացել է, գործողություն կատարել, չափումներ ուղարկել Pushgateway և ավարտվել: Որոշ ժամանակ անց Պրոմեթևսը կիջնի իր տեմպերով և կվերցնի այս ցուցանիշները Pushgateway-ից:
Պրոմեթևսում ծանուցումները կարգավորելու համար կա առանձին բաղադրիչ. Alertmanager. Եվ զգուշացման կանոնները. Օրինակ, դուք պետք է ստեղծեք ծանուցում, եթե սերվերի API-ն 0 է: Երբ իրադարձությունը բացվում է, ահազանգը փոխանցվում է ազդանշանների կառավարչին՝ հետագա ուղարկման համար: Ահազանգերի կառավարիչը բավականին ճկուն երթուղային կարգավորումներ ունի. ահազանգերի մի խումբ կարող է ուղարկվել ադմինների հեռագրային չաթին, մյուսը՝ ծրագրավորողների չաթին, երրորդը՝ ենթակառուցվածքի աշխատողների չաթին: Ծանուցումները կարող են ուղարկվել Slack, Telegram, email և այլ ալիքներին:
Եվ վերջապես, ես ձեզ կասեմ Պրոմեթևսի մարդասպանի հատկանիշի մասին. Հայտնաբերելուց. Պրոմեթևսի հետ աշխատելիս պետք չէ մոնիտորինգի համար օբյեկտների կոնկրետ հասցեներ նշել, բավական է սահմանել դրանց տեսակը։ Այսինքն, ձեզ հարկավոր չէ գրել «այստեղ IP հասցեն, ահա նավահանգիստը - մոնիտորը», փոխարենը, դուք պետք է որոշեք, թե ինչ սկզբունքներով գտնել այդ օբյեկտները (թիրախները - նպատակներ): Ինքը՝ Պրոմեթևսը, կախված նրանից, թե որ օբյեկտներն են ներկայումս ակտիվ, վեր է հանում անհրաժեշտները և ավելացնում մոնիտորինգին:
Այս մոտեցումը լավ տեղավորվում է Kubernetes կառուցվածքի հետ, որտեղ ամեն ինչ նույնպես լողում է. այսօր կա 10 սերվեր, վաղը 3: Որպեսզի ամեն անգամ չնշեն սերվերի IP հասցեն, նրանք մեկ անգամ գրել են, թե ինչպես գտնել այն, և Discovering-ը կանի դա: .
Պրոմեթևսի լեզուն կոչվում է PromQL. Օգտագործելով այս լեզուն՝ դուք կարող եք ստանալ որոշակի չափումների արժեքներ, այնուհետև դրանք փոխարկել, դրանց հիման վրա կառուցել վերլուծական հաշվարկներ:
https://prometheus.io/docs/prometheus/latest/querying/basics/
Простой запрос
container_memory_usage_bytes
Математические операции
container_memory_usage_bytes / 1024 / 1024
Встроенные функции
sum(container_memory_usage_bytes) / 1024 / 1024
Уточнение запроса
100 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]) * 100)Պրոմեթևսի վեբ ինտերֆեյս
Պրոմեթևսն ունի իր սեփական, բավականին մինիմալիստական վեբ ինտերֆեյսը: Հարմար է միայն վրիպազերծման կամ ցուցադրման համար:
Expression տողում կարող եք հարցում գրել PromQL լեզվով։
Զգուշացումների ներդիրը պարունակում է ահազանգման կանոններ, և դրանք ունեն երեք կարգավիճակ.
- ոչ ակտիվ - եթե ահազանգն այս պահին ակտիվ չէ, այսինքն, դրա հետ ամեն ինչ կարգին է, և այն չի աշխատել.
- սպասող - սա այն դեպքում, եթե ահազանգն աշխատել է, բայց ուղարկումը դեռ չի անցել: Ուշացումը նախատեսված է փոխհատուցելու ցանցի թարթումը. եթե նշված ծառայությունը բարձրացել է մեկ րոպեի ընթացքում, ապա ահազանգը դեռ չպետք է հնչի.
- կրակելը երրորդ կարգավիճակն է, երբ ահազանգը լուսավորվում է և հաղորդագրություններ ուղարկում:
Կարգավիճակի ընտրացանկում դուք կգտնեք տեղեկատվություն այն մասին, թե ինչ է Պրոմեթևսը: Կատարվում է նաև անցում դեպի թիրախներ (թիրախներ), որոնց մասին խոսեցինք վերևում։
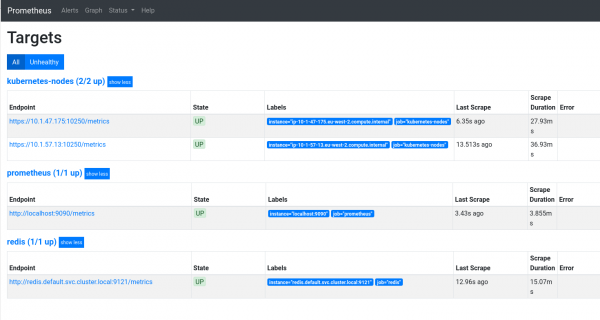
Պրոմեթևսի ինտերֆեյսի ավելի մանրամասն ակնարկի համար տե՛ս .
Ինտեգրում Grafana-ի հետ
Պրոմեթևսի վեբ ինտերֆեյսում դուք չեք գտնի գեղեցիկ և հասկանալի գրաֆիկներ, որոնցից կարող եք եզրակացություն անել կլաստերի վիճակի մասին։ Դրանք կառուցելու համար Պրոմեթևսը ինտեգրված է Grafana-ի հետ: Մենք ստանում ենք նման վահանակներ:
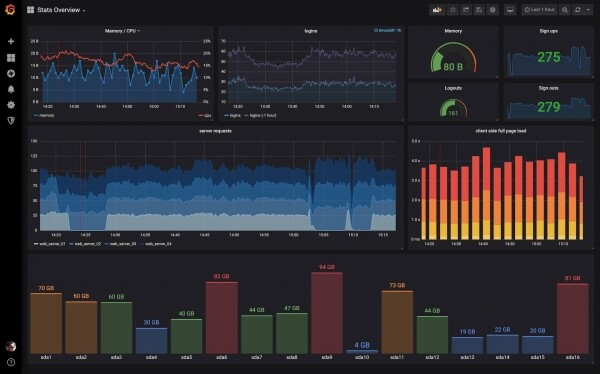
Պրոմեթևսի և Գրաֆանայի ինտեգրման կարգավորումն ամենևին էլ դժվար չէ, դուք կարող եք հրահանգներ գտնել փաստաթղթերում. Դե, ավարտեմ այսքանով.
Հետևյալ հոդվածներում մենք կշարունակենք մոնիտորինգի թեման՝ կխոսենք Grafana Loki-ի և այլընտրանքային գործիքների միջոցով լոգերի հավաքման և վերլուծության մասին:
Հեղինակ՝ Մարսել Իբրաև, հավաստագրված Kubernetes ադմինիստրատոր, ընկերությունում գործող ինժեներ , խոսնակ և դասընթացի մշակող Slurm.
Source: www.habr.com
