

Հե՜յ Հաբր։
Հիշեցնենք, որ հետևելով գրքի մասին Գրադարանի մասին նույնքան հետաքրքիր աշխատանք ենք հրատարակել .

Առայժմ համայնքը նոր է սովորում այս հզոր գործիքի սահմանները: Այսպիսով, վերջերս հրապարակվեց մի հոդված, որի թարգմանությունը ցանկանում ենք ձեզ ներկայացնել։ Իր սեփական փորձից հեղինակը պատմում է, թե ինչպես կարելի է Kafka Streams-ը վերածել տվյալների բաշխված պահեստի: Վայելե՛ք կարդալը:
Apache գրադարան օգտագործվում է ամբողջ աշխարհում ձեռնարկություններում՝ Apache Kafka-ի վերևում բաշխված հոսքերի մշակման համար: Այս շրջանակի չգնահատված կողմերից մեկն այն է, որ այն թույլ է տալիս պահել թելերի մշակման հիման վրա արտադրված տեղական վիճակը:
Այս հոդվածում ես ձեզ կպատմեմ, թե ինչպես է մեր ընկերությանը հաջողվել շահավետ օգտագործել այս հնարավորությունը ամպային հավելվածների անվտանգության համար արտադրանք մշակելիս: Օգտագործելով Kafka Streams-ը, մենք ստեղծեցինք ընդհանուր պետական միկրոծառայություններ, որոնցից յուրաքանչյուրը ծառայում է որպես համակարգի օբյեկտների վիճակի մասին վստահելի տեղեկատվության աղբյուր՝ անսարքությունների նկատմամբ հանդուրժող և բարձր հասանելի աղբյուր: Մեզ համար սա մի քայլ առաջ է թե՛ հուսալիության, թե՛ աջակցության հեշտության առումով։
Եթե ձեզ հետաքրքրում է այլընտրանքային մոտեցում, որը թույլ է տալիս օգտագործել մեկ կենտրոնական տվյալների բազա՝ աջակցելու ձեր օբյեկտների պաշտոնական վիճակին, կարդացեք այն, հետաքրքիր կլինի...
Ինչու մենք մտածեցինք, որ ժամանակն է փոխել ընդհանուր պետության հետ մեր աշխատելու ձևը
Մենք պետք է պահպանեինք տարբեր օբյեկտների վիճակը՝ հիմնվելով գործակալների հաշվետվությունների վրա (օրինակ՝ կայքը հարձակման ենթարկվե՞լ է): Նախքան Kafka Streams տեղափոխվելը, մենք հաճախ ապավինում էինք մեկ կենտրոնական տվյալների բազայի (+ ծառայության API) պետական կառավարման համար: Այս մոտեցումն ունի իր թերությունները. Հետևողականության և համաժամացման պահպանումը դառնում է իրական մարտահրավեր: Տվյալների բազան կարող է դառնալ խցան կամ վերջանալ և տառապում են անկանխատեսելիությունից:
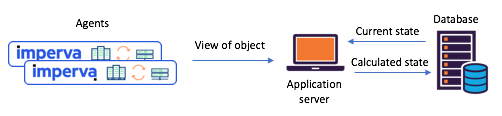
Գծապատկեր 1. Տիպիկ պառակտված վիճակի սցենար, որը դիտվել է նախքան դեպի անցումը
Կաֆկա և Կաֆկա հոսքեր. գործակալներն իրենց տեսակետները փոխանցում են API-ի միջոցով, թարմացված վիճակը հաշվարկվում է կենտրոնական տվյալների բազայի միջոցով
Հանդիպեք Kafka Streams-ին՝ հեշտացնելով ընդհանուր պետական միկրոծառայությունների ստեղծումը
Մոտ մեկ տարի առաջ մենք որոշեցինք մանրամասն դիտարկել մեր ընդհանուր պետական սցենարները՝ լուծելու այս խնդիրները: Մենք անմիջապես որոշեցինք փորձել Kafka Streams-ը. մենք գիտենք, թե որքանով է այն մասշտաբային, մատչելի և սխալ հանդուրժող, ինչ հարուստ հոսքային գործառույթ ունի (փոխակերպումներ, ներառյալ պետական): Հենց այն, ինչ մեզ պետք էր, էլ չասած, թե որքան հասուն և հուսալի է դարձել հաղորդագրությունների համակարգը Կաֆկայում:
Մեր ստեղծած պետական միկրոծառայություններից յուրաքանչյուրը կառուցվել է Kafka Streams-ի օրինակի վրա՝ բավականին պարզ տոպոլոգիայով: Այն բաղկացած էր 1) աղբյուրից 2) պրոցեսորից՝ մշտական բանալիների արժեքով 3) լվացարանից.
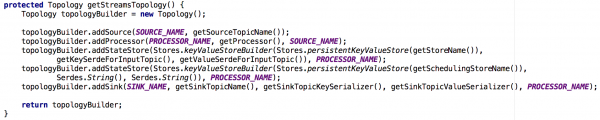
Նկար 2. Մեր հոսքային օրինակների լռելյայն տոպոլոգիան պետական միկրոծառայությունների համար: Նկատի ունեցեք, որ այստեղ կա նաև պահեստ, որը պարունակում է պլանավորման մետատվյալներ:
Այս նոր մոտեցման մեջ գործակալները կազմում են հաղորդագրություններ, որոնք սնվում են սկզբնաղբյուրի թեմայում, իսկ սպառողները, օրինակ՝ փոստի ծանուցման ծառայությունը, ստանում են հաշվարկված ընդհանուր վիճակը լվացարանի միջոցով (ելքային թեմա):
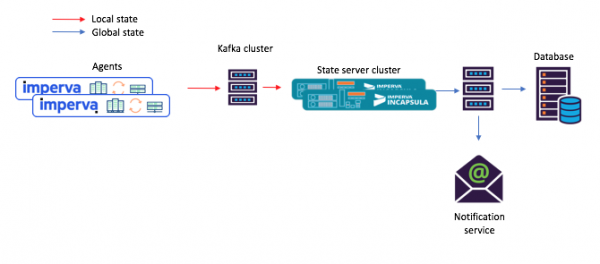
Նկար 3. Նոր օրինակ առաջադրանքների հոսք ընդհանուր միկրոծառայությունների հետ կապված սցենարի համար. 1) ընդհանուր վիճակով միկրոսերվիսը (օգտագործելով Kafka Streams) մշակում է այն և գրում է հաշվարկված վիճակը Կաֆկայի վերջնական թեմայում. որից հետո 2) սպառողները ընդունում են նոր վիճակը
Հե՜յ, այս ներկառուցված բանալիների արժեքով խանութն իրականում շատ օգտակար է:
Ինչպես նշվեց վերևում, մեր ընդհանուր վիճակի տոպոլոգիան պարունակում է բանալի-արժեքի պահեստ: Մենք գտանք դրա օգտագործման մի քանի տարբերակ, և դրանցից երկուսը նկարագրված են ստորև:
Տարբերակ թիվ 1. Հաշվարկների համար օգտագործեք բանալի-արժեքի պահեստ
Բանալին-արժեքի մեր առաջին խանութը պարունակում էր հաշվարկների համար մեզ անհրաժեշտ օժանդակ տվյալներ: Օրինակ՝ որոշ դեպքերում ընդհանուր վիճակը որոշվում էր «մեծամասնական ձայների» սկզբունքով։ Պահեստը կարող է պահել գործակալի բոլոր վերջին հաշվետվությունները որոշ օբյեկտի կարգավիճակի վերաբերյալ: Այնուհետև, երբ մենք ստանում էինք նոր հաշվետվություն այս կամ այն գործակալից, մենք կարող էինք պահպանել այն, պահեստից առբերել նույն օբյեկտի վիճակի մասին հաշվետվությունները բոլոր մյուս գործակալներից և կրկնել հաշվարկը:
Ստորև 4-րդ նկարը ցույց է տալիս, թե ինչպես ենք մենք ենթարկել բանալին/արժեքի պահեստը պրոցեսորի մշակման մեթոդին, որպեսզի նոր հաղորդագրությունը հնարավոր լինի մշակել:
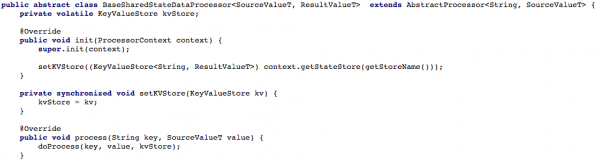
Նկար 4. Մենք բացում ենք մուտք դեպի բանալիների արժեքի պահեստ պրոցեսորի մշակման մեթոդի համար (այսուհետև յուրաքանչյուր սկրիպտ, որն աշխատում է ընդհանուր վիճակի հետ, պետք է իրականացնի մեթոդը doProcess)
Տարբերակ #2. CRUD API-ի ստեղծում Kafka Streams-ի վերևում
Ստեղծելով մեր հիմնական առաջադրանքների հոսքը՝ մենք սկսեցինք փորձել գրել RESTful CRUD API մեր ընդհանուր պետական միկրոծառայությունների համար: Մենք ցանկանում էինք, որ կարողանանք վերբերել որոշ կամ բոլոր օբյեկտների վիճակը, ինչպես նաև սահմանել կամ հեռացնել օբյեկտի վիճակը (օգտակար է հետին պլանի աջակցության համար):
Բոլոր Get State API-ներին աջակցելու համար, երբ մեզ անհրաժեշտ էր վերահաշվարկել վիճակը վերամշակման ընթացքում, մենք այն երկար ժամանակ պահում էինք ներկառուցված բանալիների արժեքի խանութում: Այս դեպքում բավականին պարզ է դառնում նման API-ի ներդրումը, օգտագործելով Kafka Streams-ի մեկ օրինակ, ինչպես ցույց է տրված ստորև բերված ցանկում.
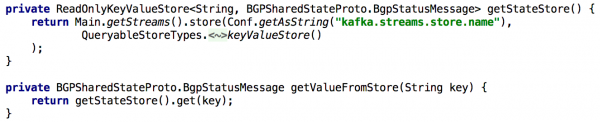
Նկար 5. Ներկառուցված բանալի-արժեքի պահեստի օգտագործումը օբյեկտի նախապես հաշվարկված վիճակը ստանալու համար
API-ի միջոցով օբյեկտի վիճակի թարմացումը նույնպես հեշտ է իրականացնել: Հիմնականում ձեզ հարկավոր է ընդամենը ստեղծել Կաֆկա պրոդյուսեր և օգտագործել այն ձայնագրություն ստեղծելու համար, որը պարունակում է նոր վիճակը: Սա երաշխավորում է, որ API-ի միջոցով գեներացված բոլոր հաղորդագրությունները կմշակվեն այնպես, ինչպես ստացվել են այլ արտադրողներից (օրինակ՝ գործակալներից):

Նկար 6. Դուք կարող եք սահմանել օբյեկտի վիճակը՝ օգտագործելով Kafka արտադրողը
Փոքր բարդություն. Կաֆկան ունի բազմաթիվ միջնորմներ
Հաջորդը, մենք ցանկանում էինք բաշխել մշակման բեռը և բարելավել հասանելիությունը՝ յուրաքանչյուր սցենարի համար տրամադրելով ընդհանուր պետական միկրոծառայությունների կլաստեր: Կարգավորումը հեշտ էր. երբ մենք կարգավորեցինք բոլոր օրինակները, որպեսզի գործարկվեն նույն հավելվածի ID-ի (և նույն bootstrap սերվերների) ներքո, գրեթե ամեն ինչ արվում էր ավտոմատ կերպով: Մենք նաև նշել ենք, որ սկզբնաղբյուրի յուրաքանչյուր թեմա բաղկացած կլինի մի քանի միջնորմներից, այնպես որ յուրաքանչյուր օրինակ կարող է վերագրվել այդպիսի բաժանումների ենթաբազմություն:
Նշեմ նաև, որ սովորական պրակտիկա է պետական խանութի կրկնօրինակը պատրաստելը, որպեսզի, օրինակ, ձախողումից հետո վերականգնման դեպքում այս պատճենը տեղափոխվի այլ օրինակ: Kafka Streams-ի յուրաքանչյուր պետական խանութի համար ստեղծվում է կրկնվող թեմա՝ փոփոխության մատյանով (որը հետևում է տեղական թարմացումներին): Այսպիսով, Կաֆկան մշտապես պաշտպանում է պետական խանութը։ Հետևաբար, Kafka Streams-ի այս կամ այն օրինակի ձախողման դեպքում պետական խանութը կարող է արագ վերականգնվել մեկ այլ ատյանի վրա, որտեղ կգնան համապատասխան միջնորմները: Մեր թեստերը ցույց են տվել, որ դա արվում է մի քանի վայրկյանում, նույնիսկ եթե խանութում կան միլիոնավոր ձայնագրություններ։
Ընդհանուր վիճակով մեկ միկրոծառայությունից անցնելով միկրոծառայությունների կլաստերի՝ Get State API-ի ներդրումը դառնում է ավելի քիչ անիմաստ: Նոր իրավիճակում յուրաքանչյուր միկրոսերվիսի պետական խանութը պարունակում է ընդհանուր պատկերի միայն մի մասը (այն օբյեկտները, որոնց բանալիները քարտեզագրվել են կոնկրետ բաժանման վրա): Մենք պետք է որոշեինք, թե որ օրինակն է պարունակում մեզ անհրաժեշտ օբյեկտի վիճակը, և մենք դա արեցինք թեմայի մետատվյալների հիման վրա, ինչպես ցույց է տրված ստորև.
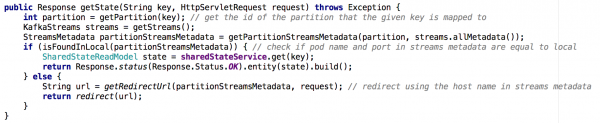
Նկար 7. Օգտագործելով հոսքի մետատվյալները, մենք որոշում ենք, թե որ օրինակից պետք է հարցումներ կատարենք ցանկալի օբյեկտի վիճակի վրա; նմանատիպ մոտեցում է օգտագործվել GET ALL API-ի հետ
Հիմնական արդյունքները
Պետական խանութները Kafka Streams-ում կարող են ծառայել որպես դե ֆակտո բաշխված տվյալների բազա,
- անընդհատ կրկնվում է Կաֆկայում
- CRUD API-ն կարող է հեշտությամբ կառուցվել նման համակարգի վրա
- Բազմաթիվ միջնապատերի կառավարումը մի փոքր ավելի բարդ է
- Հնարավոր է նաև ավելացնել մեկ կամ մի քանի վիճակային խանութներ հոսքային տոպոլոգիայում՝ օժանդակ տվյալներ պահելու համար։ Այս տարբերակը կարող է օգտագործվել հետևյալի համար.
- Հոսքի մշակման ընթացքում հաշվարկների համար անհրաժեշտ տվյալների երկարաժամկետ պահպանում
- Տվյալների երկարաժամկետ պահպանում, որը կարող է օգտակար լինել հաջորդ անգամ, երբ հոսքային օրինակը տրամադրվի
- շատ ավելի...
Այս և այլ առավելությունները դարձնում են Kafka Streams-ը լավ պիտանի՝ մեր նման բաշխված համակարգում գլոբալ պետություն պահպանելու համար: Kafka Streams-ը ապացուցել է, որ շատ հուսալի է արտադրության մեջ (մենք գործնականում չենք ունեցել հաղորդագրությունների կորուստ այն տեղակայելուց հետո), և մենք վստահ ենք, որ դրա հնարավորությունները չեն դադարի դրանով:
Source: www.habr.com
