


Մի քանի տարի առաջ Kubernetes-ը պաշտոնական GitHub բլոգում։ Այդ ժամանակվանից ի վեր այն դարձել է ծառայությունների տեղակայման ստանդարտ տեխնոլոգիա։ Kubernetes-ը այժմ սնուցում է մեր ներքին և հանրային ծառայությունների զգալի մասը։ Քանի որ մեր կլաստերները մեծացել են, և մեր կատարողականի պահանջները դարձել են ավելի խիստ, մենք նկատել ենք, որ Kubernetes-ի վրա աշխատող որոշ ծառայություններ պարբերաբար ունենում են ուշացումներ, որոնք չեն կարող բացատրվել հենց ծրագրի ծանրաբեռնվածությամբ։
Ըստ էության, հավելվածները բախվում են թվացյալ պատահական ցանցային լատենտության՝ մինչև 100 մվ կամ ավելի, ինչը հանգեցնում է ժամանակի ընդհատման կամ կրկնակի փորձերի: Ակնկալվում է, որ ծառայությունները կկարողանան պատասխանել հարցումներին շատ ավելի արագ, քան 100 մվ: Սակայն դա հնարավոր չէ, եթե կապն ինքնին այդքան երկար է տևում: Մասնավորապես, մենք տեսել ենք շատ արագ MySQL հարցումներ, որոնք պետք է տևեն միլիվայրկյաններ, և MySQL-ը իսկապես պատասխանում է միլիվայրկյաններում, բայց հարցում կատարող հավելվածի տեսանկյունից պատասխանը տևում է 100 մվ կամ ավելի:
Անմիջապես պարզ դարձավ, որ խնդիրը առաջանում էր միայն Kubernetes հանգույցին միանալու ժամանակ, նույնիսկ եթե զանգը գալիս էր Kubernetes-ից դուրս։ Խնդիրը վերարտադրելու ամենահեշտ ձևը թեստային տարբերակն է։ , որը գործարկվում է ցանկացած ներքին հոսթից, ստուգում է Kubernetes ծառայությունը որոշակի պորտի վրա և պարբերաբար գրանցում է բարձր լատենտություն: Այս հոդվածում մենք կանդրադառնանք, թե ինչպես կարողացանք գտնել այս խնդրի պատճառը:
Անհաջողությունների շղթայից ավելորդ բարդության վերացում
Նույն օրինակը վերարտադրելով՝ մենք ցանկանում էինք նեղացնել խնդրի կիզակետը և վերացնել բարդության ավելորդ շերտերը: Սկզբում Vegeta-ի և Kubernetes-ի pods-ի միջև հոսքում չափազանց շատ տարրեր կային: Ավելի խորը ցանցային խնդիր բացահայտելու համար մենք պետք է վերացնեինք դրանցից մի քանիսը:
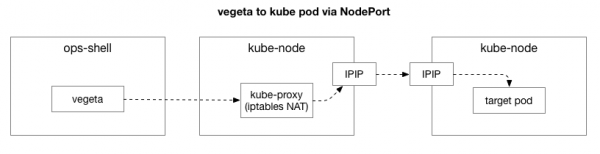
Հաճախորդը (Vegeta) ստեղծում է TCP կապ կլաստերի ցանկացած հանգույցի հետ։ Kubernetes-ը գործում է որպես վերադրվող ցանց (գոյություն ունեցող տվյալների կենտրոնի ցանցի վերևում), որն օգտագործում է , այսինքն՝ այն ներառում է տվյալների կենտրոնի IP փաթեթների ներսում տեղադրված ցանցային IP փաթեթները։ Առաջին հանգույցին միանալիս կատարվում է ցանցային հասցեի թարգմանություն։ (NAT) վիճակային թարգմանությամբ՝ Kubernetes հանգույցի IP հասցեն և պորտը վերադիր ցանցի IP հասցեի և պորտի թարգմանելու համար (մասնավորապես՝ հավելվածի հետ կապված պոդում): Մուտքային փաթեթների համար կատարվում է գործողությունների հակառակ հաջորդականությունը: Այն բարդ համակարգ է՝ բազմաթիվ վիճակներով և բազմաթիվ տարրերով, որոնք անընդհատ թարմացվում և փոխվում են՝ ծառայությունների տեղակայման և տեղափոխման հետ մեկտեղ:
Օգտակար tcpdump Vegeta թեստում TCP ձեռքսեղմման ժամանակ (SYN-ի և SYN-ACK-ի միջև) կա ուշացում։ Այս ավելորդ բարդությունը վերացնելու համար կարող եք օգտագործել hping3 SYN փաթեթներով պարզ «փինգերի» համար: Ստուգեք, թե արդյոք պատասխանի փաթեթում ուշացում կա, ապա ընդհատեք կապը: Մենք կարող ենք զտել տվյալները՝ ներառելով միայն 100 մվ-ից երկար փաթեթները, և ստանալ խնդիրը վերարտադրելու ավելի հեշտ միջոց, քան Vegeta-ում 7-րդ մակարդակի ամբողջական ցանցային թեստը: Ահա Kubernetes հանգույցի «փինգերը», որոնք օգտագործում են TCP SYN/SYN-ACK-ը ծառայության «հանգույցի պորտի» (30927) վրա 10 մվ ինտերվալներով, զտված ամենադանդաղ պատասխաններով.
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 մվ
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 մվ
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 մվ
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 մվ
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 մվ
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 մվ
Առաջին դիտարկումը կարելի է անել անմիջապես։ Սերիական համարները և ժամանակային կարգավորումները ցույց են տալիս, որ սրանք միանգամյա խցանումներ չեն։ Ուշացումը հաճախ կուտակվում է և ի վերջո մշակվում։
Հաջորդը, մենք ուզում ենք պարզել, թե որ բաղադրիչները կարող են խոչընդոտի պատճառ դառնալ։ Արդյո՞ք դա NAT-ի հարյուրավոր iptables կանոններից մեկն է։ Կամ ցանցում IPIP թունելավորման հետ կապված որևէ խնդիր կա՞։ Սա ստուգելու միջոցներից մեկը համակարգի յուրաքանչյուր քայլը ստուգելն է՝ այն հեռացնելով։ Ի՞նչ է պատահում, եթե հեռացնեք NAT-ը և firewall-ի տրամաբանությունը՝ թողնելով միայն IPIP մասը։
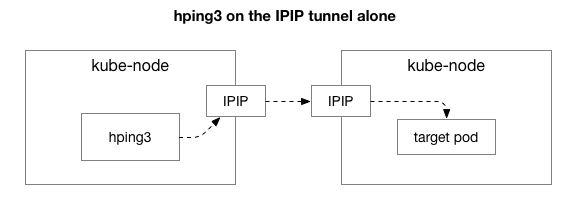
Բարեբախտաբար Linux թույլ է տալիս հեշտությամբ մուտք գործել IP ծածկույթի շերտ անմիջապես, եթե մեքենան գտնվում է նույն ցանցում։
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 մվ
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 մվ
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 մվ
Դատելով արդյունքներից՝ խնդիրը դեռևս մնում է։ Սա բացառում է iptables-ը և NAT-ը։ Այսպիսով, խնդիրը TCP-ում է՞։ Եկեք տեսնենք, թե ինչպես է ընթանում սովորական ICMP պինգը։
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 մվ
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 մվ
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 մվ
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 մվ
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 մվ
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 մվ
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 մվ
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 մվ
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 մվ
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 մվ
Արդյունքները ցույց են տալիս, որ խնդիրը դեռևս առկա է։ Գուցե խնդիրը IPIP թունելն է՞։ Եկեք ավելի պարզեցնենք թեստը։
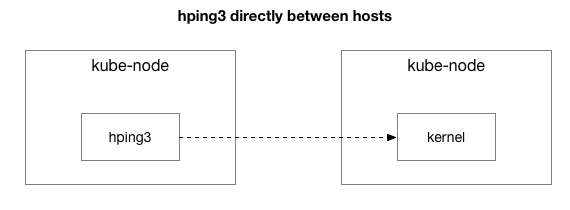
Արդյո՞ք բոլոր փաթեթներն ուղարկվում են այս երկու հոսթերի միջև։
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 մվ
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 մվ
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 մվ
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 մվ
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 մվ
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 մվ
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 մվ
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 մվ
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 մվ
Մենք իրավիճակը պարզեցրինք՝ երկու Kubernetes հանգույցներ միմյանց ուղարկում են ցանկացած փաթեթ, նույնիսկ ICMP ping: Նրանք դեռևս տեսնում են լատենտություն, եթե թիրախային հոսթը «վատ» է (որոշները ավելի վատն են, քան մյուսները):
Հիմա վերջին հարցը. ինչո՞ւ է ուշացումը տեղի ունենում միայն kube-node սերվերների վրա: Եվ արդյո՞ք դա տեղի է ունենում, երբ kube-node-ը ուղարկողն է, թե՞ ստացողը: Բարեբախտաբար, սա նույնպես բավականին հեշտ է պարզել՝ Kubernetes-ից դուրս գտնվող հոսթից փաթեթ ուղարկելով, բայց նույն «հայտնի վատ» ստացողի միջոցով: Ինչպես տեսնում եք, խնդիրը շարունակվում է.
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 մվ
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 մվ
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 մվ
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 մվ
Այնուհետև մենք նույն հարցումներն ենք կատարում նախորդ kube-node-ի սկզբնական հանգույցից դեպի արտաքին հոսթ (որը բացառում է սկզբնական հոսթը, քանի որ ping-ը ներառում է և՛ RX, և՛ TX բաղադրիչները):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 ms
Ուշացած փաթեթների գրավումը ուսումնասիրելով՝ մենք ստանում ենք որոշ լրացուցիչ տեղեկություններ։ Մասնավորապես, որ ուղարկողը (ներքևում) տեսնում է այս ժամանակի ավարտը, բայց ստացողը (վերևում)՝ ոչ. տե՛ս Դելտա սյունակը (վայրկյաններով):
Բացի այդ, եթե նայեք TCP և ICMP փաթեթների հերթականության տարբերությանը (հաջորդական համարներով) ստացողի կողմից, ICMP փաթեթները միշտ ժամանում են նույն հաջորդականությամբ, որով ուղարկվել են, բայց տարբեր ժամանակացույցով։ Միևնույն ժամանակ, TCP փաթեթները երբեմն հերթագայում են, և դրանցից մի քանիսը կպչում են։ Մասնավորապես, եթե ուսումնասիրեք SYN փաթեթների պորտերը, դրանք հերթականությամբ են դասավորվում ուղարկողի կողմից, բայց ոչ ստացողի կողմից։
Կա նուրբ տարբերություն նրանում, թե ինչպես Ժամանակակից սերվերները (ինչպես մեր տվյալների կենտրոնում գտնվողը) մշակում են TCP կամ ICMP պարունակող փաթեթներ: Երբ փաթեթը հասնում է, ցանցային ադապտերը «հեշավորում է այն միացման միջոցով», այսինքն՝ փորձում է բաժանել միացումները հերթերի և յուրաքանչյուր հերթն ուղարկել առանձին պրոցեսորի միջուկի: TCP-ի դեպքում այս հեշը ներառում է ինչպես աղբյուրի, այնպես էլ նպատակակետի IP հասցեն և միացքը: Այլ կերպ ասած, յուրաքանչյուր միացում հեշվում է (հնարավոր է) տարբեր կերպ: ICMP-ի դեպքում հեշվում են միայն IP հասցեները, քանի որ միացքներ չկան:
Եվս մեկ նոր դիտարկում. այս ժամանակահատվածում մենք տեսնում ենք ICMP ուշացումներ երկու հոսթերի միջև բոլոր հաղորդակցություններում, մինչդեռ TCP-ն՝ ոչ։ Սա մեզ ասում է, որ պատճառը, հավանաբար, կապված է RX հերթերի հեշավորման հետ. գերբեռնվածությունը գրեթե անկասկած RX փաթեթների մշակման մեջ է, այլ ոչ թե պատասխանների ուղարկման։
Սա վերացնում է փաթեթներ ուղարկելու հնարավոր պատճառը։ Այժմ մենք գիտենք, որ փաթեթների մշակման խնդիրը որոշ kube-node սերվերների ընդունող կողմում է։
Հասկանալով փաթեթների մշակումը միջուկում Linux
Որպեսզի հասկանանք, թե ինչու է խնդիրը առաջանում որոշ kube-node սերվերների ընդունիչի վրա, եկեք նայենք, թե ինչպես է միջուկը Linux մշակում է փաթեթները։
Վերադառնալով ամենապարզ ավանդական իրականացմանը՝ ցանցային քարտը ստանում է փաթեթը և ուղարկում այն։ միջուկ Linuxոր կա մի փաթեթ, որը պետք է մշակվի։ Միջուկը դադարեցնում է մյուս աշխատանքները, համատեքստը փոխում է ընդհատման մշակիչի վրա, մշակում է փաթեթը, ապա վերադառնում է ընթացիկ առաջադրանքներին։
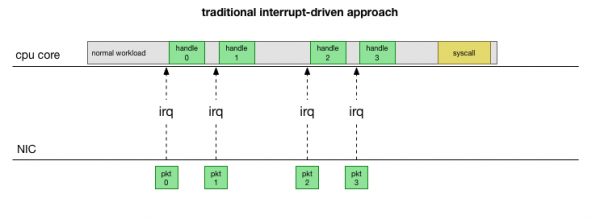
Այս համատեքստի փոխարկումը դանդաղ է. 10-ականներին 90 Մբ/վ արագությամբ ցանցային քարտերի վրա լատենտությունը կարող էր աննկատ լինել, սակայն այսօրվա 10G քարտերի վրա, որոնք ունեն վայրկյանում 15 միլիոն փաթեթի առավելագույն թողունակություն, փոքր, ութ միջուկանի սերվերի յուրաքանչյուր միջուկ կարող է ընդհատվել վայրկյանում միլիոնավոր անգամներ։
Որպեսզի չանհանգստանանք անընդհատ ընդհատումներից, շատ տարիներ առաջ Linux ավելացվել է : ցանցային API-ն, որն օգտագործում են բոլոր ժամանակակից դրայվերները՝ բարձր արագությամբ կատարողականությունը բարելավելու համար: Ցածր արագությունների դեպքում միջուկը դեռևս ստանում է ընդհատումներ ցանցային քարտից՝ հին ձևով: Երբ բավարար քանակությամբ փաթեթներ են հասնում, որոնք գերազանցում են շեմը, միջուկը անջատում է ընդհատումները և փոխարենը սկսում է հարցումներ ուղարկել ցանցային ադապտերին և վերցնել փաթեթները մաս-մաս: Մշակումը կատարվում է softirq-ում, այսինքն՝ համակարգային կանչերից և սարքային ընդհատումներից հետո, երբ միջուկը (ի տարբերություն օգտագործողի տարածքի) արդեն աշխատում է։
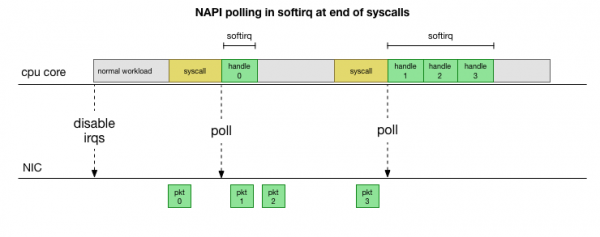
Սա շատ ավելի արագ է, բայց այն առաջացնում է մեկ այլ խնդիր։ Եթե չափազանց շատ փաթեթներ կան, ամբողջ ժամանակը ծախսվում է ցանցային քարտից փաթեթներ մշակելու վրա, և օգտագործողի տարածքի գործընթացները ժամանակ չունեն իրականում դատարկելու այդ հերթերը (ընթերցում TCP կապերից և այլն)։ Ի վերջո հերթերը լցվում են, և մենք սկսում ենք փաթեթներ թողնել։ Հավասարակշռություն գտնելու փորձի ժամանակ միջուկը սահմանում է բյուջե softirq համատեքստում մշակվող փաթեթների առավելագույն քանակի համար։ Երբ այս բյուջեն գերազանցվում է, առանձին թել է արթնանում։ ksoftirqd (դուք կտեսնեք դրանցից մեկը ps մեկ միջուկի համար), որը մշակում է այս ծրագրային պահանջները սովորական համակարգային կանչի/ընդհատման ուղուց դուրս: Այս թելը պլանավորվում է ստանդարտ գործընթացների ժամանակացույցի միջոցով, որը փորձում է արդարացիորեն բաշխել ռեսուրսները:
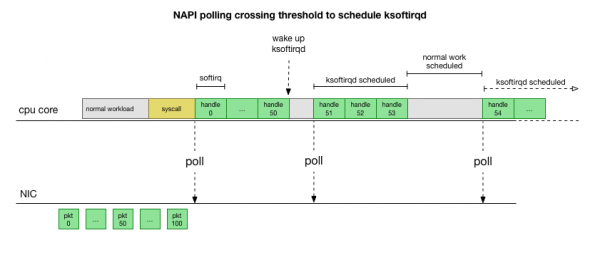
Ուսումնասիրելով, թե ինչպես է միջուկը մշակում փաթեթները, կարող եք տեսնել, որ կա որոշակի գերբեռնվածության հավանականություն: Եթե softirq կանչերը ավելի քիչ հաճախական են, փաթեթները ստիպված կլինեն որոշ ժամանակ սպասել ցանցային քարտի RX հերթում՝ մշակման համար: Սա կարող է պայմանավորված լինել պրոցեսորի միջուկը արգելափակող որևէ առաջադրանքով կամ ինչ-որ այլ բանով, որը խանգարում է միջուկին softirq-ները գործարկելուն:
Մշակման նեղացումը մինչև միջուկ կամ մեթոդ
Սոֆտիրքի ուշացումները այս պահին միայն ենթադրություն են։ Բայց դա տրամաբանական է, և մենք գիտենք, որ մենք ունենք շատ նման մի բան։ Այսպիսով, հաջորդ քայլը այս տեսությունը հաստատելն է։ Եվ եթե այն հաստատվի, ապա գտեք ուշացումների պատճառը։
Եկեք վերադառնանք մեր դանդաղ փաթեթներին.
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 մվ
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 մվ
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 մվ
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 մվ
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 մվ
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 մվ
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 մվ
Ինչպես ավելի վաղ քննարկվեց, այս ICMP փաթեթները հեշվում են մեկ NIC RX հերթում և մշակվում են մեկ CPU միջուկի կողմից։ Եթե մենք ուզում ենք հասկանալ գործողությունը Linux, օգտակար է իմանալ, թե որտեղ (որ CPU միջուկի վրա) և ինչպես (softirq, ksoftirqd) են մշակվում այս փաթեթները՝ գործընթացը հետևելու համար։
Հիմա ժամանակն է օգտագործել գործիքներ, որոնք թույլ են տալիս իրական ժամանակում վերահսկել միջուկի աշխատանքը։ LinuxԱյստեղ մենք օգտագործեցինք Այս գործիքակազմը թույլ է տալիս գրել փոքր C ծրագրեր, որոնք միջուկում գտնվող կամայական ֆունկցիաները կցում են բուֆերային եղանակով և իրադարձությունները կբուֆերացնում են Python-ի օգտագործողի տարածքի ծրագրի մեջ, որը կարող է մշակել դրանք և արդյունքը վերադարձնել ձեզ: Միջուկում կամայական ֆունկցիաները կցելը բարդ է, բայց գործիքը նախագծված է հնարավորինս անվտանգ լինելու համար և նախատեսված է հենց այն տեսակի արտադրական խնդիրները հայտնաբերելու համար, որոնք դժվար է վերարտադրել փորձարկման կամ մշակման միջավայրում:
Այստեղ պլանը պարզ է. մենք գիտենք, որ միջուկը մշակում է այս ICMP պինգերը, ուստի մենք միանում ենք միջուկի ֆունկցիային։ , որը ստանում է մուտքային ICMP արձագանքի հարցման փաթեթ և սկսում է ուղարկել ICMP արձագանքի պատասխան։ Մենք կարող ենք նույնականացնել փաթեթը icmp_seq աճող թվով, որը ցույց է տալիս hping3 վերևում:
Code բարդ է թվում, բայց այնքան էլ սարսափելի չէ, որքան թվում է։ Ֆունկցիա icmp_echo փոխանցում է struct sk_buff *skbսա «արձագանքի հարցում» պարունակող փաթեթ է։ Մենք կարող ենք հետևել դրան, արդյունահանել հաջորդականությունը։ echo.sequence (որը համեմատվում է icmp_seq hping3-ից выше), և ուղարկել այն օգտատիրոջ տարածք։ Հարմար է նաև գրանցել ընթացիկ գործընթացի անունը/ID-ն։ Ստորև ներկայացված են արդյունքները, որոնք մենք տեսնում ենք անմիջապես, երբ միջուկը մշակում է փաթեթները.
TGID PID ԳՈՐԾԸՆԹԱՑԻ ԱՆՈՒՆ ICMP_SEQ 0 0 փոխանակիչ/11 770 0 0 փոխանակիչ/11 771 0 0 փոխանակիչ/11 772 0 0 փոխանակիչ/11 773 0 0 փոխանակիչ/11 774 20041 20086 Պրոմեթևս 775 0 0 փոխանակիչ/11 776 0 0 փոխանակիչ/11 777 0 0 փոխանակիչ/11 778 4512 4542 խոսնակների զեկույցներ 779
Այստեղ պետք է նշել, որ համատեքստում softirq Համակարգային կանչեր կատարած պրոցեսները կհայտնվեն որպես «պրոցեսներ», չնայած իրականում միջուկն է, որը անվտանգ կերպով մշակում է փաթեթները միջուկի համատեքստում։
Այս գործիքի միջոցով մենք կարող ենք որոշակի գործընթացներ կապել որոշակի փաթեթների հետ, որոնք ցույց են տալիս լատենտություն hping3Եկեք պարզեցնենք grep որոշակի արժեքների այս գրավման վրա icmp_seqՎերը նշված icmp_seq արժեքներին համապատասխանող փաթեթները նշվել են վերևում դիտարկված իրենց RTT-ների հետ միասին (փակագծերում նշված են այն փաթեթների սպասվող RTT-ները, որոնք մենք զտել ենք 50 մվ-ից պակաս RTT արժեքների պատճառով):
TGID PID ԳՈՐԾԸՆԹԱՑԻ ԱՆՎԱՆՈՒՄԸ ICMP_SEQ ** RTT -- 10137 10436 cadvisor 1951 10137 10436 cadvisor 1952 76 76 ksoftirqd/11 1953 ** 99ms 76 76 ms 11 1954 ksoftirqd ksoftirqd/89 76 ** 76ms 11 1955 ksoftirqd/79 76 ** 76ms 11 1956 ksoftirqd/69 76 ** 76ms 11 1957 ksoftirqd/59 76 ** (76ms) 11 softirqd (1958ms) 49q76 76 11 ksoftirqd/1959 39 ** (76ms) 76 11 ksoftirqd/1960 29 ** (76ms) 76 11 ksoftirqd/1961 19 ** (76ms) -- 76 11 cadvisor 1962 9d 10137 10436 ksoftirqd/2068 10137 ** 10436ms 2069 76 ksoftirqd/76 11 ** 2070ms 75 76 ksoftirqd/76 11 ** 2071ms 65 76 ksoftirqd/76 11 ** (2072ms) 55q76 76 11 2073 ksoftirqd/45 76 ** (76ms) 11 2074 ksoftirqd/35 76 ** (76ms) 11 2075 ksoftirqd/25 76 ** (76ms)
Արդյունքները մեզ մի քանի բան են ասում։ Նախ, այս բոլոր փաթեթները մշակվում են համատեքստի միջոցով։ ksoftirqd/11Սա նշանակում է, որ այս մեքենաների զույգի համար ICMP փաթեթները հեշվել են ընդունող կողմի միջուկ 11-ին։ Մենք նաև տեսնում ենք, որ յուրաքանչյուր գերբեռնվածության համար կան փաթեթներ, որոնք մշակվում են համակարգային կանչի համատեքստում։ cadvisor. Հետո ksoftirqd ստանձնում է առաջադրանքը և մշակում կուտակված հերթը՝ ճիշտ այնքան փաթեթներ, որոնք կուտակվել են դրանից հետո cadvisor.
Այն փաստը, որ նախքան սա միշտ կաշխատի cadvisor, ենթադրում է նրա ներգրավվածությունը խնդրի մեջ։ Հեգնական է, որ նպատակը - «վերլուծել աշխատող կոնտեյներների ռեսուրսների օգտագործումը և կատարողականի բնութագրերը», այլ ոչ թե առաջացնել այս կատարողականի խնդիրը։
Ինչպես կոնտեյներների շահագործման այլ ասպեկտների դեպքում, սա նույնպես շատ առաջադեմ գործիքակազմ է, և որոշակի անկանխատեսելի հանգամանքներում լիովին հնարավոր է ակնկալել կատարողականության հետ կապված խնդիրներ։
Ի՞նչ է անում cadvisor-ը, որը դանդաղեցնում է փաթեթների հերթը։
Հիմա մենք բավականին լավ պատկերացում ունենք, թե ինչպես է տեղի ունենում վթարը, որ պրոցեսն է այն առաջացնում և որ պրոցեսորի վրա է։ Մենք տեսնում ենք, որ կոշտ կողպեքի պատճառով միջուկը Linux ժամանակ չունի ժամանակ պլանավորելու ksoftirqdԵվ մենք տեսնում ենք, որ փաթեթները մշակվում են համատեքստում։ cadvisorՏրամաբանական է ենթադրել, որ cadvisor մեկնարկում է դանդաղ համակարգային կանչ, որից հետո մշակվում են այդ պահին կուտակված բոլոր փաթեթները։
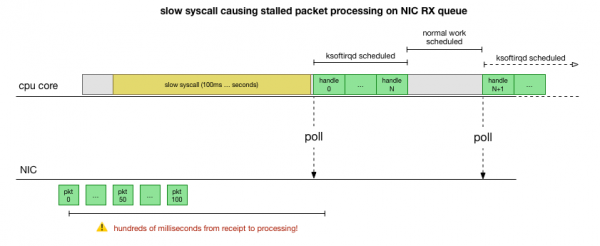
Սա է տեսությունը, բայց ինչպե՞ս ենք մենք այն ստուգում։ Մենք կարող ենք դիտարկել պրոցեսորի միջուկը այս ամբողջ գործընթացի ընթացքում, գտնել այն կետը, որտեղ փաթեթների բյուջեն գերազանցվում է և ksoftirqd-ն կանչվում է, ապա մի փոքր ավելի վաղ նայել՝ տեսնելու համար, թե ինչ էր աշխատում պրոցեսորի միջուկի վրա այդ կետից անմիջապես առաջ։ Դա նման է պրոցեսորի ռենտգենյան նկարահանմանը յուրաքանչյուր մի քանի միլիվայրկյանները մեկ։ Այն կունենա մոտավորապես այսպիսի տեսք.
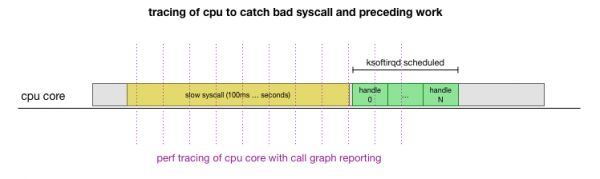
Հարմար է, որ այս ամենը կարելի է անել արդեն իսկ առկա գործիքներով։ Օրինակ՝ Ստուգում է տվյալ պրոցեսորի միջուկը որոշակի հաճախականությամբ և կարող է ստեղծել աշխատող համակարգի կանչի գրաֆիկ, ներառյալ և՛ օգտագործողի տարածքը, և՛ միջուկը։ LinuxԴուք կարող եք վերցնել այս գրառումը և մշակել այն՝ օգտագործելով ծրագրի փոքր ճյուղավորումը։ Բրենդան Գրեգի կողմից, որը պահպանում է ստեկի հետագծի հերթականությունը։ Մենք կարող ենք պահպանել մեկ տողանի ստեկի հետագծերը յուրաքանչյուր 1 մվ-ով, ապա արդյունահանել և պահպանել նմուշը հետագծի հասնելուց 100 մվ-ով առաջ։ ksoftirqd:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100
Ահա արդյունքները.
(сотни следов, которые выглядят похожими)
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_run
Այստեղ շատ բան է կատարվում, բայց գլխավորն այն է, որ մենք գտնում ենք «cadvisor before ksoftirqd» օրինաչափությունը, որը մենք տեսել էինք ավելի վաղ ICMP tracer-ում։ Ի՞նչ է դա նշանակում։
Յուրաքանչյուր տող պրոցեսորի հետքն է որոշակի ժամանակահատվածում։ Տողի յուրաքանչյուր կանչը բաժանված է կետ-ստորակետով։ Տողերի կենտրոնում մենք տեսնում ենք, թե ինչպես է կանչվում համակարգային կանչը։ read(): .... ;do_syscall_64;sys_read; ...Այսպիսով, cadvisor-ը շատ ժամանակ է ծախսում համակարգային կանչի վրա։ read(), կապված գործառույթների հետ mem_cgroup_* (կանչի կույտի վերև/գծի վերջ):
Հարմար չէ տեսնել, թե կոնկրետ ինչ է կարդացվում կանչի հետքում, ուստի եկեք գործարկենք strace և եկեք տեսնենք, թե ինչ է անում cadvisor-ը և գտնենք 100 մվ-ից երկար համակարգային կանչեր։
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 576 <0.154442>
Ինչպես կարող եք ակնկալել, մենք այստեղ տեսնում ենք դանդաղ զանգեր։ read()Կարդալու գործողությունների բովանդակությունից և համատեքստից mem_cgroup ակնհայտ է, որ այս մարտահրավերները read() կապվել ֆայլի հետ memory.stat, որը ցույց է տալիս հիշողության օգտագործումը և cgroup-ի (Docker-ում ռեսուրսների մեկուսացման տեխնոլոգիա) սահմանները: Cadvisor գործիքը հարցում է ուղարկում այս ֆայլին՝ կոնտեյներների համար ռեսուրսների օգտագործման մասին տեղեկատվություն ստանալու համար: Եկեք ստուգենք, թե արդյոք միջուկն է, թե՞ cadvisor-ը անսպասելի բան անում:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
իրական 0մ0.153վ
օգտատեր 0մ0.000վ
համակարգ 0մ0.152վ
theojulienne@kube-node-bad ~ $
Հիմա մենք կարող ենք վերարտադրել սխալը և հասկանալ, որ միջուկը Linux հանդիպում է պաթոլոգիայի։
Ինչո՞ւ է ընթերցման գործողությունն այդքան դանդաղ։
Այս պահին շատ ավելի հեշտ է գտնել նմանատիպ խնդիրներ հաղորդող այլ օգտատերերի։ Պարզվում է, որ այս սխալը cadvisor tracker-ում հաղորդվել է որպես , պարզապես ոչ ոք չնկատեց, որ լատենտությունը նույնպես պատահականորեն արտացոլվում է ցանցային սթեքում։ Իսկապես նկատվեց, որ cadvisor-ը սպառում էր ավելի շատ CPU ժամանակ, քան սպասվում էր, բայց դրան մեծ նշանակություն չտրվեց, քանի որ մեր սերվերներն ունեն շատ CPU ռեսուրսներ, ուստի խնդիրը մանրակրկիտ չի ուսումնասիրվել։
Խնդիրն այն է, որ cgroup-երը հաշվի են առնում հիշողության օգտագործումը անվանատարածքի (կոնտեյների) ներսում։ Երբ այդ cgroup-ի բոլոր պրոցեսները դուրս են գալիս, Docker-ը ազատում է հիշողության cgroup-ը։ Սակայն «հիշողությունը» միայն պրոցեսի հիշողություն չէ։ Չնայած պրոցեսի հիշողությունն ինքնին այլևս չի օգտագործվում, պարզվում է, որ միջուկը նաև հատկացնում է քեշավորված բովանդակություն, ինչպիսիք են dentry-ները և inodes-ները (տեղեկատուի և ֆայլի մետատվյալներ), որոնք քեշավորված են հիշողության cgroup-ում։ Խնդրի նկարագրությունից՝
Zombie cgroups. cgroups, որոնք չունեն պրոցեսներ և հեռացվել են, բայց դեռևս ունեն հիշողություն հատկացված (իմ դեպքում՝ dentry քեշից, բայց այն կարող է նաև հատկացվել էջի քեշից կամ tmpfs-ից):
Cgroup-ը ազատելիս քեշի բոլոր էջերը ստուգող միջուկը կարող է շատ դանդաղ լինել, ուստի ընտրվում է դանդաղ գործընթաց. սպասեք, մինչև այս էջերը կրկին խնդրվեն, ապա, երբ հիշողությունն իրականում անհրաժեշտ լինի, վերջապես մաքրեք cgroup-ը: Մինչ այդ, cgroup-ը դեռևս հաշվի է առնվում վիճակագրություն հավաքելիս:
Արդյունավետության առումով, նրանք հիշողությունը փոխարինեցին արդյունավետությամբ՝ արագացնելով սկզբնական մաքրումը՝ քեշավորված հիշողության մի մասը թողնելու հաշվին։ Սա նորմալ է։ Երբ միջուկը օգտագործում է քեշավորված հիշողության վերջին մասը, cgroup-ը ի վերջո մաքրվում է, ուստի այն իրականում չի կարող անվանվել «արտահոսք»։ Դժբախտաբար, որոնման մեխանիզմի կոնկրետ իրականացումը memory.stat Այս միջուկի տարբերակում (4.9), մեր սերվերների վրա առկա հիշողության մեծ ծավալի հետ մեկտեղ, վերջին քեշավորված տվյալները վերականգնելու և զոմբի cgroup-երը մաքրելու համար շատ ավելի երկար ժամանակ է պահանջվում։
Պարզվում է, որ մեր որոշ հանգույցներ ունեին այնքան շատ cgroup զոմբիներ, որոնք կարդացվում էին, իսկ լատենտությունը՝ մեկ վայրկյանից ավելի։
Cadvisor-ի խնդրի լուծումը dentries/inode քեշերի անհապաղ ազատումն է ամբողջ համակարգով, ինչը անմիջապես վերացնում է ընթերցման լատենտությունը, ինչպես նաև հոսթի ցանցային լատենտությունը, քանի որ քեշի մաքրումը ներառում է քեշավորված Zombie cgroup էջերը, որոնք նույնպես ազատվում են: Սա լուծում չէ, բայց հաստատում է խնդրի պատճառը:
Պարզվում է, որ ավելի նոր kernel տարբերակներում (4.19+) զանգերի արդյունավետությունը բարելավվել է։ memory.stat, այսպիսով, այդ միջուկին անցնելը լուծեց խնդիրը։ Միևնույն ժամանակ, մենք ունեինք գործիքներ՝ Kubernetes կլաստերներում խնդրահարույց հանգույցները հայտնաբերելու, դրանք արագորեն դատարկելու և վերագործարկելու համար։ Մենք մանրակրկիտ ուսումնասիրեցինք բոլոր կլաստերները, գտանք բավականաչափ բարձր լատենտությամբ հանգույցներ և վերագործարկեցինք դրանք։ Սա մեզ ժամանակ տվեց մնացած սերվերների օպերացիոն համակարգը թարմացնելու համար։
Ամփոփելով
Քանի որ այս սխալը հարյուրավոր միլիվայրկյաններով կանգնեցնում էր NIC RX հերթի մշակումը, այն առաջացնում էր ինչպես բարձր լատենտություն կարճ միացումների դեպքում, այնպես էլ լատենտություն կապի կեսին, օրինակ՝ MySQL հարցումների և պատասխանի փաթեթների միջև։
Kubernetes-ի նման ամենահիմնարար համակարգերի աշխատանքի հասկացումը և պահպանումը կարևոր է դրա վրա աշխատող բոլոր ծառայությունների հուսալիության և արագության համար: Kubernetes-ի վրա աշխատող բոլոր համակարգերը օգտվում են աշխատանքի բարելավումներից:
Source: www.habr.com
