

Շատերը, ովքեր արդեն օգտագործում են - Մեր PostgreSQL պլանի վիզուալիզացիայի ծառայությունը կարող է տեղյակ չլինել իր գերհզոր ուժերից մեկի մասին՝ սերվերի մատյանից դժվար ընթեռնելի հատվածի վերածելը...
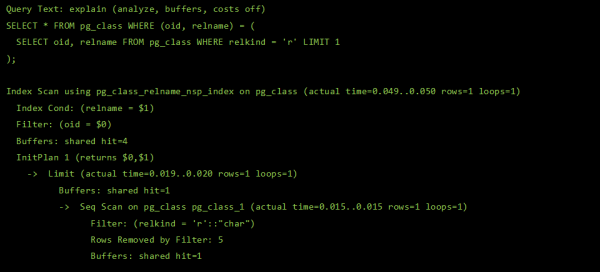
... գեղեցիկ ձևավորված հարցման մեջ՝ համատեքստային ակնարկներով համապատասխան պլանի հանգույցների համար.
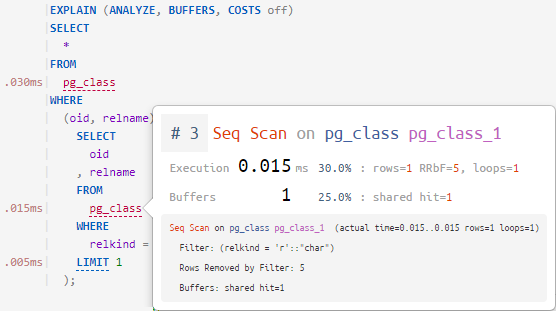
Նրա երկրորդ մասի այս սղագրության մեջ Ես ձեզ կասեմ, թե ինչպես մեզ հաջողվեց դա անել:
Առաջին մասի սղագրությունը, որը նվիրված է հարցումների կատարման բնորոշ խնդիրներին և դրանց լուծումներին, կարող եք գտնել հոդվածում .

Նախ, եկեք սկսենք գունավորել - և մենք այլևս չենք գունավորելու հատակագիծը, մենք արդեն գունավորել ենք այն, մենք արդեն ունենք այն գեղեցիկ և հասկանալի, բայց խնդրանք:
Մեզ թվում էր, որ նման չձևաչափված «թերթով» մատյանից հանված հարցումը շատ տգեղ և, հետևաբար, անհարմար է թվում:

Հատկապես, երբ մշակողները «սոսնձում» են հարցման մարմինը կոդի մեջ (սա, իհարկե, հակապատկեր է, բայց դա տեղի է ունենում) մեկ տողով: Սարսափելի!
Սա ինչ-որ կերպ ավելի գեղեցիկ նկարենք։
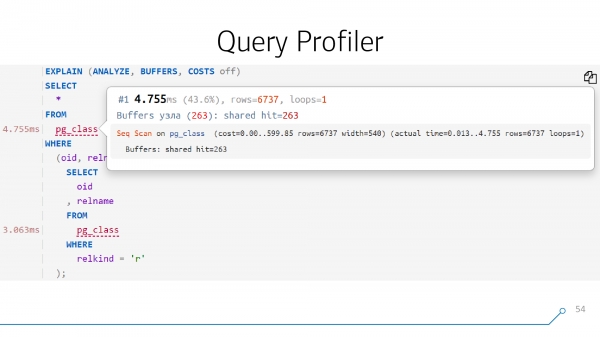
Եվ եթե մենք կարողանանք սա գեղեցիկ նկարել, այսինքն՝ ապամոնտաժել և նորից հավաքել խնդրանքի մարմինը, ապա մենք կարող ենք այնուհետև «կցել» ակնարկ այս խնդրանքի յուրաքանչյուր օբյեկտին. այն, ինչ տեղի ունեցավ պլանի համապատասխան կետում:
Հարցման շարահյուսական ծառ
Դա անելու համար հարցումը նախ պետք է վերլուծվի:
Քանի որ մենք ունենք , հետո դրա համար մոդուլ ենք պատրաստել, կարող ես . Փաստորեն, դրանք ընդլայնված «կապումներ» են հենց PostgreSQL վերլուծիչի ներքին մասերի համար: Այսինքն, քերականությունը պարզապես երկուական է կոմպիլացվում, և դրա հետ կապվում են NodeJS-ից։ Մենք հիմք ենք ընդունել ուրիշների մոդուլները՝ այստեղ մեծ գաղտնիք չկա։
Մենք սնուցում ենք հարցումի մարմինը որպես մուտքագրում մեր ֆունկցիային. ելքում մենք ստանում ենք վերլուծված շարահյուսական ծառ՝ JSON օբյեկտի տեսքով:

Այժմ մենք կարող ենք անցնել այս ծառի միջով հակառակ ուղղությամբ և հավաքել հարցումը մեր ուզած անցքերով, գունավորմամբ և ձևաչափով: Ոչ, սա հարմարեցված չէ, բայց մեզ թվում էր, որ դա հարմար կլինի:

Հարցման և պլանի հանգույցների քարտեզագրում
Հիմա տեսնենք, թե ինչպես կարող ենք համատեղել առաջին քայլում վերլուծած պլանը և երկրորդում վերլուծած հարցումը:
Եկեք մի պարզ օրինակ բերենք. մենք ունենք հարցում, որը ստեղծում է CTE և կարդում է դրանից երկու անգամ: Նա ստեղծում է նման ծրագիր.

CTE- ն
Եթե ուշադիր նայեք, մինչև 12-րդ տարբերակը (կամ դրանից սկսած բանալի բառով MATERIALIZED) կազմում .

Սա նշանակում է, որ եթե մենք տեսնում ենք CTE սերունդ ինչ-որ տեղ հարցումում և հանգույց ինչ-որ տեղ պլանում CTE, ապա այս հանգույցները անպայման «կռվում են» միմյանց հետ, մենք կարող ենք անմիջապես համատեղել դրանք։
Աստղանիշի հետ կապված խնդիրCTE-ները կարող են լինել բնադրված:

Կան շատ վատ բնադրվածներ և նույնիսկ համանուններ։ Օրինակ, դուք կարող եք ներսում CTE A դարձնել CTE X, և նույն մակարդակի վրա ներսում CTE B անել այն կրկին CTE X:
WITH A AS (
WITH X AS (...)
SELECT ...
)
, B AS (
WITH X AS (...)
SELECT ...
)
...Համեմատելիս սա պետք է հասկանալ. Սա «աչքերով» հասկանալը` նույնիսկ պլանը տեսնելը, նույնիսկ խնդրանքի մարմինը տեսնելը, շատ դժվար է: Եթե ձեր CTE սերունդը բարդ է, բնադրված, և հարցումները մեծ են, ապա այն ամբողջովին անգիտակից է:
UNION
Եթե հարցման մեջ ունենք հիմնաբառ UNION [ALL] (երկու նմուշների միացման օպերատոր), ապա պլանում այն համապատասխանում է կամ հանգույցի Append, կամ որոշ Recursive Union.
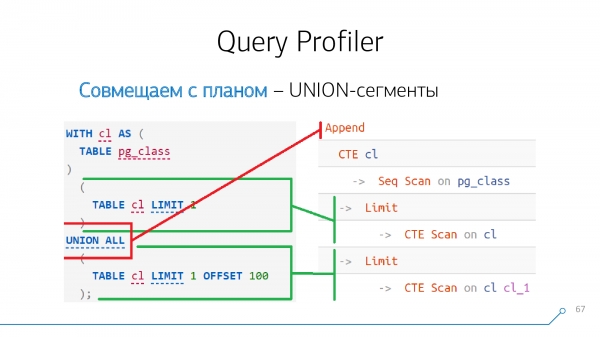
Այն, ինչ «վերևում» է վերևում UNION - սա մեր հանգույցի առաջին ժառանգն է, որը «ներքևում» է, երկրորդը: Եթե միջոցով UNION մենք միանգամից մի քանի բլոկ ունենք «սոսնձված», ապա Append- Դեռևս կլինի միայն մեկ հանգույց, բայց այն կունենա ոչ թե երկու, այլ շատ երեխաներ, համապատասխանաբար, ըստ նրանց գնալու.
(...) -- #1
UNION ALL
(...) -- #2
UNION ALL
(...) -- #3Append
-> ... #1
-> ... #2
-> ... #3
Աստղանիշի հետ կապված խնդիրռեկուրսիվ նմուշառման գեներացիայի ներսում (WITH RECURSIVE) կարող է նաև լինել մեկից ավելի UNION. Բայց միայն վերջին բլոկը վերջինից հետո միշտ ռեկուրսիվ է UNION. Վերևում ամեն ինչ մեկն է, բայց տարբեր UNION:
WITH RECURSIVE T AS(
(...) -- #1
UNION ALL
(...) -- #2, тут кончается генерация стартового состояния рекурсии
UNION ALL
(...) -- #3, только этот блок рекурсивный и может содержать обращение к T
)
...
Դուք նաև պետք է կարողանաք «առանձնացնել» նման օրինակները։ Այս օրինակում մենք տեսնում ենք, որ UNION-Մեր խնդրանքում կար 3 հատված. Ըստ այդմ, մեկ UNION համապատասխանում Append- հանգույց, իսկ մյուսին - Recursive Union.

Կարդալ-գրել տվյալներ
Ամեն ինչ դրված է, հիմա մենք գիտենք, թե խնդրանքի որ հատվածն է պլանի որ հատվածին է համապատասխանում։ Եվ այս կտորների մեջ մենք հեշտությամբ և բնականաբար կարող ենք գտնել այն առարկաները, որոնք «ընթեռնելի են»:
Հարցման տեսանկյունից մենք չգիտենք՝ դա աղյուսակ է, թե CTE, բայց դրանք նշանակված են նույն հանգույցով։ RangeVar. Եվ «ընթեռնելիության» առումով սա նաև հանգույցների բավականին սահմանափակ շարք է.
Seq Scan on [tbl]Bitmap Heap Scan on [tbl]Index [Only] Scan [Backward] using [idx] on [tbl]CTE Scan on [cte]Insert/Update/Delete on [tbl]
Մենք գիտենք պլանի և հարցման կառուցվածքը, գիտենք բլոկների համապատասխանությունը, գիտենք օբյեկտների անունները. մենք կատարում ենք մեկ առ մեկ համեմատություն:

Կրկին առաջադրանք «աստղանիշով». Մենք ընդունում ենք հարցումը, կատարում ենք այն, մենք չունենք որևէ այլանուն. մենք պարզապես այն երկու անգամ կարդում ենք նույն CTE-ից:

Մենք նայում ենք պլանին. ո՞րն է խնդիրը: Ինչու՞ մենք ունեցանք կեղծանուն: Մենք չենք պատվիրել: Որտեղի՞ց նրան նման «համար»:
PostgreSQL-ն ինքն է ավելացնում: Պարզապես պետք է դա հասկանալ հենց այդպիսի այլանուն մեզ համար, պլանի հետ համեմատելու նպատակով, դա ոչ մի իմաստ չունի, ուղղակի ավելացվում է այստեղ։ Եկեք ուշադրություն չդարձնենք նրա վրա։
Երկրորդ առաջադրանք «աստղանիշով»Եթե մենք կարդում ենք բաժանված աղյուսակից, ապա կստանանք հանգույց Append կամ Merge Append, որը բաղկացած կլինի մեծ թվով «երեխաներից», և որոնցից յուրաքանչյուրը ինչ-որ կերպ կլինի Scanom աղյուսակի բաժնից. Seq Scan, Bitmap Heap Scan կամ Index Scan. Բայց, ամեն դեպքում, այս «երեխաները» բարդ հարցումներ չեն լինի. այսպես կարելի է տարբերակել այս հանգույցները. Append ի UNION.

Մենք նույնպես հասկանում ենք նման հանգույցները, հավաքում դրանք «մեկ կույտում» և ասում.այն ամենը, ինչ դուք կարդում եք megatable-ից, այստեղ և ծառի ներքև է".
«Պարզ» տվյալների ընդունման հանգույցներ

Values Scan համապատասխանում է պլանին VALUES խնդրանքի մեջ։
Result խնդրանք է առանց FROM նման SELECT 1. Կամ երբ դուք դիտավորյալ կեղծ արտահայտություն ունեք WHERE-block (այնուհետև հայտնվում է հատկանիշը One-Time Filter):
EXPLAIN ANALYZE
SELECT * FROM pg_class WHERE FALSE; -- или 0 = 1Result (cost=0.00..0.00 rows=0 width=230) (actual time=0.000..0.000 rows=0 loops=1)
One-Time Filter: false
Function Scan «քարտեզ» համանուն SRF-ներին:
Բայց ներկառուցված հարցումներով ամեն ինչ ավելի բարդ է, ցավոք, դրանք միշտ չէ, որ վերածվում են InitPlan/SubPlan. Երբեմն դրանք վերածվում են ... Join կամ ... Anti Join, հատկապես, երբ գրում ես նման բան WHERE NOT EXISTS .... Եվ այստեղ միշտ չէ, որ հնարավոր է դրանք համատեղել՝ պլանի տեքստում պլանի հանգույցներին համապատասխան օպերատորներ չկան։
Կրկին առաջադրանք «աստղանիշով»: մի քանի VALUES խնդրանքի մեջ։ Այս դեպքում և պլանում դուք կստանաք մի քանի հանգույց Values Scan.

«Համարակալված» վերջածանցները կօգնեն դրանք տարբերել միմյանցից. դրանք ավելացվում են հենց այն հաջորդականությամբ, որով գտնվում են համապատասխանները: VALUES- արգելափակում է հարցման երկայնքով վերևից ներքև:
Տվյալների մշակում
Կարծես թե մեր խնդրանքում ամեն ինչ կարգավորված է. մնում է միայն Limit.

Բայց այստեղ ամեն ինչ պարզ է `նման հանգույցներ, ինչպիսիք են Limit, Sort, Aggregate, WindowAgg, Unique «Քարտեզագրել» մեկ առ մեկ հարցումի համապատասխան օպերատորներին, եթե նրանք այնտեղ են: Այստեղ «աստղեր» կամ դժվարություններ չկան։

ՄԻԱՑԵՔ
Դժվարություններ են առաջանում, երբ ուզում ենք համատեղել JOIN իրենց միջև։ Սա միշտ չէ, որ հնարավոր է, բայց հնարավոր է:

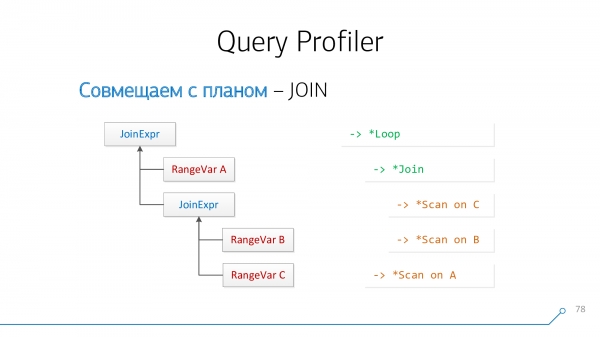
Հարցման վերլուծիչի տեսանկյունից մենք ունենք հանգույց JoinExpr, որն ունի ուղիղ երկու երեխա՝ աջ ու ձախ։ Սա, համապատասխանաբար, այն է, ինչ կա «վերևում» ձեր JOIN-ը և ինչ է գրված «ներքևում» հարցումում:
Իսկ պլանի տեսակետից սրանք ոմանց երկու ժառանգներն են * Loop/* Join- հանգույց. Nested Loop, Hash Anti Join,... - նման մի բան.
Եկեք օգտագործենք պարզ տրամաբանություն. եթե մենք ունենք A և B աղյուսակներ, որոնք «միանում» են միմյանց պլանում, ապա հարցումում դրանք կարող են տեղակայվել կամ A-JOIN-BԿամ B-JOIN-A. Փորձենք համատեղել այսպես, փորձենք համատեղել հակառակը, և այդպես շարունակ, մինչև մեզ սպառեն նման զույգերը:
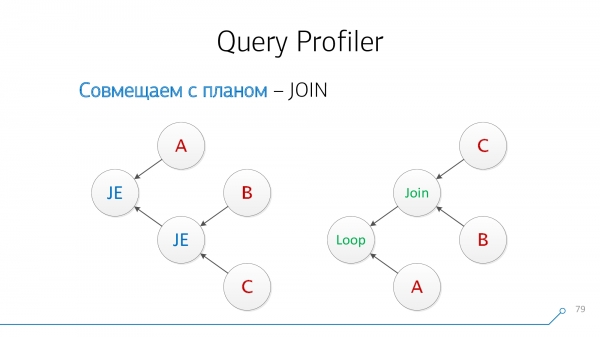
Վերցնենք մեր շարահյուսական ծառը, վերցնենք մեր պլանը, նայենք նրանց... ոչ նման:
Եկեք վերագծենք այն գրաֆիկների տեսքով. օհ, դա արդեն նման է ինչ-որ բանի:
Նկատենք, որ մենք ունենք հանգույցներ, որոնք միաժամանակ ունեն B և C երեխաներ, մեզ չի հետաքրքրում, թե ինչ հերթականությամբ: Եկեք դրանք համատեղենք և շրջենք հանգույցի նկարը։
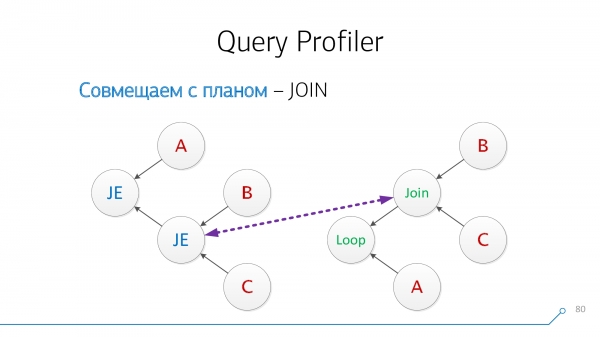
Եկեք նորից նայենք։ Այժմ մենք ունենք A երեխաների հետ հանգույցներ և զույգեր (B + C), որոնք նույնպես համատեղելի են նրանց հետ:
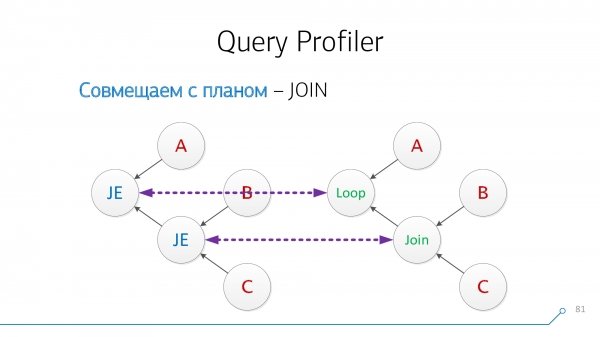
Հիանալի Ստացվում է, որ մենք այս երկուսն ենք JOIN խնդրանքից պլանի հետ հանգույցները հաջողությամբ համակցվեցին:
Ավաղ, այս խնդիրը միշտ չէ, որ լուծվում է։
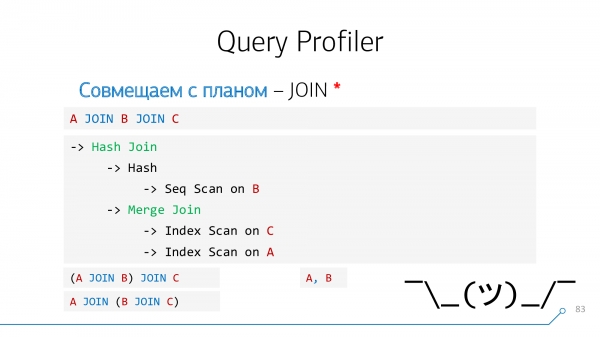
Օրինակ, եթե խնդրանքով A JOIN B JOIN C, իսկ պլանում առաջին հերթին միացված էին «արտաքին» հանգույցները A և C։ Բայց հարցումում չկա այդպիսի օպերատոր, մենք առանձնացնելու բան չունենք, որևէ ակնարկ կցելու։ Նույնը «ստորակետի» դեպքում է, երբ գրում ես A, B.
Բայց, շատ դեպքերում, գրեթե բոլոր հանգույցները կարող են «բացվել», և դուք կարող եք ժամանակին ստանալ այս տեսակի պրոֆիլավորում ձախ կողմում, բառացիորեն, ինչպես Google Chrome-ում, երբ վերլուծում եք JavaScript ծածկագիրը: Դուք կարող եք տեսնել, թե որքան ժամանակ է պահանջվել յուրաքանչյուր տողի և յուրաքանչյուր հայտարարության «կատարման» համար:

Եվ այս ամենից օգտվելն ավելի հարմար դարձնելու համար մենք պահեստավորում ենք պատրաստել , որտեղ դուք կարող եք պահպանել և հետագայում գտնել ձեր պլանները կապված հարցումների հետ միասին կամ կիսվել հղումով որևէ մեկի հետ:
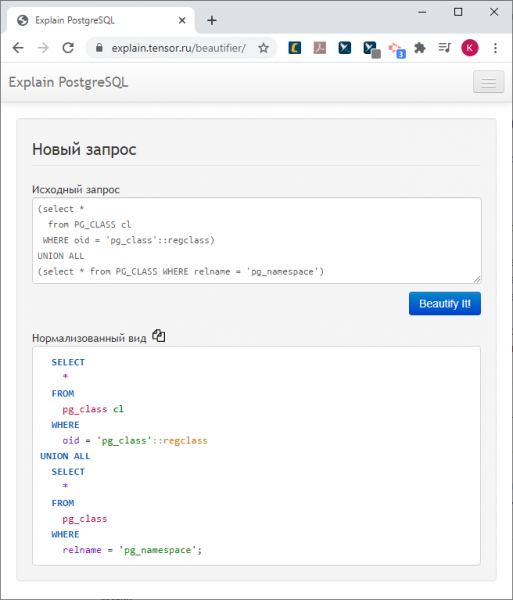
Եթե պարզապես անհրաժեշտ է անընթեռնելի հարցումը համապատասխան ձևի բերել, օգտագործեք .
Source: www.habr.com
